Вашите отговорности като DBA (или <вмъкнете роля тук>) вероятно включват неща като настройка на производителността, планиране на капацитет и възстановяване при бедствия. Това, което много хора са склонни да забравят или отлагат, е да гарантират целостта на структурата на техните бази данни (както логическа, така и физическа); най-важната стъпка е DBCC CHECKDB . Можете да стигнете дотам, като създадете прост план за поддръжка със „Задача за проверка на целостта на базата данни“ – но според мен това е просто поставяне на отметка в квадратче.
Ако погледнете по-отблизо, можете да направите много малко, за да контролирате как работи задачата. Дори доста обширният панел Properties разкрива много настройки за подплана за поддръжка, но почти нищо за DBCC команди, които ще изпълни. Лично аз мисля, че трябва да предприемете много по-проактивен и контролиран подход към това как изпълнявате своя CHECKDB операции в производствена среда, като създавате свои собствени работни места и ръчно изработвате своя DBCC команди. Можете да приспособите своя график или самите команди към различни бази данни – например базата данни за членство в ASP.NET вероятно не е толкова важна, колкото вашата база данни за продажби, и може да толерира по-рядко и/или по-малко задълбочени проверки.
Но за вашите важни бази данни реших да събера публикация, в която да обясня подробно някои от нещата, които бих проучил, за да сведа до минимум смущенията DBCC командите могат да причинят – и от какви митове и маркетингов шум трябва да внимавате. И искам да благодаря на Пол „г-н DBCC“ Рандал (@PaulRandal) за предоставянето на ценен принос – не само за тази конкретна публикация, но и за безкрайните съвети, които предоставя в своя блог, #sqlhelp и в обучението за потапяне на SQLskills.
Моля, приемете всички тези идеи с недоверие и направете всичко възможно, за да извършите адекватно тестване във вашата среда – не всички тези предложения ще доведат до по-добра производителност във всички среди. Но вие дължите на себе си, на вашите потребители и заинтересованите страни поне да обмислите въздействието, което вашият CHECKDB операциите могат да имат и предприемете стъпки за смекчаване на тези ефекти, където е възможно – без да въвеждате ненужен риск, като не проверявате правилните неща.
Намалете шума и консумирайте всички грешки
Без значение къде изпълнявате CHECKDB , винаги използвайте WITH NO_INFOMSGS опция. Това просто потиска целия ирелевантен изход, който просто ви казва колко реда има във всяка таблица; ако се интересувате от тази информация, можете да я получите от прости заявки към DMV, а не докато DBCC бяга. Потискането на изхода прави много по-малко вероятно да пропуснете критично съобщение, заровено в целия този щастлив изход.
По същия начин винаги трябва да използвате WITH ALL_ERRORMSGS опция, но особено ако използвате SQL Server 2008 RTM или SQL Server 2005 (в тези случаи може да видите списъка с грешки за всеки обект, съкратен до 200). За всеки CHECKDB операции, различни от бързи ad-hoc проверки, трябва да помислите за насочване на изхода към файл. Management Studio е ограничен до 1000 реда изход от DBCC CHECKDB , така че може да пропуснете някои грешки, ако надвишите тази цифра.
Въпреки че не е строго проблем с производителността, използването на тези опции ще ви попречи да стартирате процеса отново. Това е особено важно, ако сте в средата на възстановяване след бедствие.
Разтоварване на логически проверки, където е възможно
В повечето случаи CHECKDB прекарва по-голямата част от времето си в извършване на логически проверки на данните. Ако имате възможност да извършвате тези проверки на вярно копие от данните, можете да съсредоточите усилията си върху физическата структура на вашите производствени системи и да използвате вторичния сървър, за да обработвате всички логически проверки и да облекчите това натоварване от първичния. От вторичен сървър , имам предвид само следното:
- Мястото, където тествате пълните си възстановявания – защото тествате своите възстановявания, нали?
Други хора (най-вече гигантската маркетингова сила, която е Microsoft) може да са ви убедили, че други форми на вторични сървъри са подходящи за DBCC чекове. Например:
- вторично четене на AlwaysOn Availability Group;
- моментна снимка на огледална база данни;
- вторичен дневник, изпратен;
- SAN дублиране;
- или други варианти...
За съжаление, това не е така и нито едно от тези вторични услуги не е валидно, надеждно място за извършване на вашите проверки като алтернатива на основното. Само резервно копие едно към едно може да служи като вярно копие; всичко друго, което разчита на неща като прилагането на архивни копия на регистрационни файлове за достигане до последователно състояние, няма да отразява надеждно проблемите с целостта на първичния.
Така че вместо да се опитвате да разтоварите логическите си проверки на вторичен и никога да не ги извършвате на първичния, ето какво предлагам:
- Уверете се, че често тествате възстановяването на пълните си резервни копия. И не, това не включва
COPY_ONLYрезервни копия от вторичен AG по същите причини като по-горе – това би било валидно само в случай, когато току-що сте стартирали вторичния с пълно възстановяване. - Изпълнете
DBCC CHECKDBчесто срещу пълния възстановите, преди да направите нещо друго. Отново възпроизвеждането на регистрационни записи в този момент ще обезсили тази база данни като истинско копие на източника. - Изпълнете
DBCC CHECKDBсрещу основното ви, може би разделено по начини, които Пол Рандал предлага, и/или по по-рядък график и/или използване наPHYSICAL_ONLYпо-често, отколкото не. Това може да зависи от това колко често и надеждно изпълнявате (2). - Никога не приемайте, че проверките срещу вторичния елемент са достатъчни. Дори и с точно копие на основната ви база данни, все още има физически проблеми, които могат да възникнат в I/O подсистемата на вашата основна, които никога няма да се разпространят до вторичната.
- Винаги анализирайте
DBCCизход. Просто да го стартирате и да го игнорирате, за да го отметнете от някакъв списък, е също толкова полезно, колкото стартирането на архивиране и заявяването на успех, без изобщо да тествате, че всъщност можете да възстановите този архив, когато е необходимо.
Експериментирайте с флагове за проследяване 2549, 2562 и 2566
Направих задълбочено тестване на два флага за проследяване (2549 и 2562) и открих, че те могат да доведат до значителни подобрения в производителността, но Lonny съобщава, че вече не са необходими или полезни. Ако сте на 2016 или по-нова, пропуснете цялата тази секция . Ако сте на по-стара версия, тези два флага за проследяване са описани много по-подробно в KB #2634571, но основно:
- Флаг за проследяване 2549
- Това оптимизира процеса на checkdb, като третира всеки отделен файл на база данни като намиращ се на уникален подлежащ диск. Това е добре да използвате, ако вашата база данни има един файл с данни или ако знаете, че всеки файл с база данни всъщност е на отделно устройство. Ако вашата база данни има множество файлове и те споделят един, директно свързан шпиндел, трябва да внимавате с този флаг за проследяване, тъй като може да причини повече вреда, отколкото полза.
ВАЖНО :sql.sasquatch отчита регресия в поведението на този флаг за проследяване в SQL Server 2014.
- Това оптимизира процеса на checkdb, като третира всеки отделен файл на база данни като намиращ се на уникален подлежащ диск. Това е добре да използвате, ако вашата база данни има един файл с данни или ако знаете, че всеки файл с база данни всъщност е на отделно устройство. Ако вашата база данни има множество файлове и те споделят един, директно свързан шпиндел, трябва да внимавате с този флаг за проследяване, тъй като може да причини повече вреда, отколкото полза.
- Флаг за проследяване 2562
- Този флаг третира целия процес на checkdb като единична партида, с цената на по-високо използване на tempdb (до 5% от размера на базата данни).
- Използва по-добър алгоритъм, за да определи как да чете страници от базата данни, намалявайки конкуренцията за заключване (особено за
DBCC_MULTIOBJECT_SCANNER). Имайте предвид, че това специфично подобрение е в кодовия път на SQL Server 2012, така че ще се възползвате от него дори без флага за проследяване. Това може да избегне грешки като:
Възникна изчакване при изчакване на заключване:клас „DBCC_MULTIOBJECT_SCANNER“.
- Горещите два флага за проследяване са налични в следните версии:
- SQL Server 2008 Service Pack 2 Кумулативна актуализация 9+
(10.00.4330 -> 10.00.5499)SQL Server 2008 Service Pack 3 Кумулативна актуализация 4+
(10.00.5775+)SQL Server 2008 R2 RTM сборна актуализация 11+
(10.50.1809 -> 10.50.2424)SQL Server 2008 R2 Service Pack 1 Кумулативна актуализация 4+
(10.50.2796 -> 10.50.3999)SQL Server 2008 R2 Service Pack 2
(10.50.4000+)SQL Server 2012, всички версии
(11.00.2100+) - Флаг за проследяване 2566
- Ако все още използвате SQL Server 2005, този флаг за проследяване, въведен в 2005 SP2 CU#9 (9.00.3282) (въпреки че не е документиран в статията от базата знания на тази кумулативна актуализация, KB #953752), се опитва да коригира лошата производителност от
DATA_PURITYпроверки на x64-базирани системи. В един момент можете да видите повече подробности в KB #945770, но изглежда, че статията е изтрита както от сайта за поддръжка на Microsoft, така и от машината WayBack. Този флаг за проследяване не трябва да е необходим в по-модерни версии на SQL Server, тъй като проблемът в процесора на заявки е отстранен.
- Ако все още използвате SQL Server 2005, този флаг за проследяване, въведен в 2005 SP2 CU#9 (9.00.3282) (въпреки че не е документиран в статията от базата знания на тази кумулативна актуализация, KB #953752), се опитва да коригира лошата производителност от
Ако ще използвате някой от тези флагове за проследяване, силно препоръчвам да ги зададете на ниво сесия с помощта на DBCC TRACEON вместо като флаг за проследяване при стартиране. Не само ви позволява да ги изключите, без да се налага да циклирате SQL Server, но също така ви позволява да ги внедрявате само при извършване на определени CHECKDB команди, за разлика от операции, използващи всякакъв вид ремонт.
Намалете въздействието на I/O:оптимизирайте tempdb
DBCC CHECKDB може да използва силно tempdb, така че не забравяйте да планирате използването на ресурсите там. Това обикновено е добре да се направи във всеки случай. За CHECKDB ще искате да разпределите правилно място за tempdb; последното нещо, което искате, е CHECKDB прогрес (и всякакви други едновременни операции), за да трябва да изчакате автоматично нарастване. Можете да получите представа за изискванията, като използвате WITH ESTIMATEONLY , както Павел обяснява тук. Само имайте предвид, че оценката може да бъде доста ниска поради грешка в SQL Server 2008 R2. Също така, ако използвате флаг за проследяване 2562, не забравяйте да се съобразите с допълнителните изисквания за пространство.
И разбира се, всички типични съвети за оптимизиране на tempdb на почти всяка система са подходящи и тук:уверете се, че tempdb е в собствен набор от бързи шпиндели, уверете се, че е оразмерен така, че да побира всички други едновременни дейности, без да се налага да нараства, уверете се, че използвате оптимален брой файлове с данни и т.н. Няколко други ресурси, които може да обмислите:
- Оптимизиране на производителността на tempdb (MSDN)
- Планиране на капацитет за tempdb (MSDN)
- Мит за SQL Server DBA на ден:(12/30) tempdb винаги трябва да има един файл с данни на процесорно ядро
Намалете въздействието на I/O:контролирайте моментната снимка
За да стартирате CHECKDB , съвременните версии на SQL Server ще се опитат да създадат скрита моментна снимка на вашата база данни на едно и също устройство (или на всички устройства, ако вашите файлове с данни обхващат няколко устройства). Не можете да контролирате този механизъм, но ако искате да контролирате къде CHECKDB работи, първо създайте своя собствена моментна снимка (изисква се Enterprise Edition) на каквото устройство желаете и стартирайте DBCC команда срещу моментната снимка. И в двата случая ще искате да изпълните тази операция по време на относителен престой, за да сведете до минимум дейността по копиране при запис, която ще премине през моментната снимка. И няма да искате този график да е в конфликт с тежки операции по запис, като поддръжка на индекс или ETL.
Може да сте виждали предложения за принудително CHECKDB за да работите в офлайн режим с помощта на WITH TABLOCK опция. Силно не препоръчвам този подход. Ако вашата база данни се използва активно, изборът на тази опция просто ще направи потребителите разочаровани. И ако базата данни не се използва активно, вие не спестявате дисково пространство, като избягвате моментна снимка, тъй като няма да има активност по копиране при запис за съхраняване.
Намалете въздействието на I/O:избягвайте грешки 665/1450/1452
В някои случаи може да видите една от следните грешки:
Операционната система върна грешка 1450 (Съществуват недостатъчни системни ресурси за завършване на заявената услуга.) на SQL Server по време на запис при отместване 0x[…] във файл с манипулатор 0x[…]. Това обикновено е временно състояние и SQL Server ще продължи да опитва отново операцията. Ако състоянието продължава, трябва да се предприемат незабавни действия за коригирането му.
Операционната система върна грешка 665 (Исканата операция не може да бъде завършена поради ограничение на файловата система) към SQL Server по време на запис при отместване 0x[…] във файл „[файл]“
Тук има някои съвети за намаляване на риска от тези грешки по време на CHECKDB операции и намаляване на тяхното въздействие като цяло – с няколко налични корекции, в зависимост от вашата операционна система и версия на SQL Server:
- Грешки с редки файлове:1450 или 665 поради фрагментация на файла:Поправки и заобиколни решения
- SQL Server отчита грешка в операционната система 1450 или 1452 или 665 (повторни опити)
Намалете въздействието върху процесора
DBCC CHECKDB е многонишков по подразбиране (но само в Enterprise Edition). Ако вашата система е свързана с процесора или просто искате CHECKDB за да използвате по-малко CPU с цената на по-дълго време, можете да помислите за намаляване на паралелизма по няколко различни начина:
- Използвайте Resource Governor на 2008 и по-нова версия, стига да използвате Enterprise Edition. За да се насочите само към DBCC команди за конкретен пул от ресурси или група от работно натоварване, ще трябва да напишете функция за класификатор, която може да идентифицира сесиите, които ще извършват тази работа (например конкретно влизане или job_id).
- Използвайте флаг за проследяване 2528, за да изключите паралелизма за
DBCC CHECKDB(както иCHECKFILEGROUPиCHECKTABLE). Тук е описан флаг за проследяване 2528. Разбира се, това е валидно само в Enterprise Edition, защото въпреки това, което Books Online казва в момента, истината е, чеCHECKDBне върви паралелно в стандартното издание. - Докато
DBCCсамата команда не поддържаMAXDOP(поне преди SQL Server 2014 SP2), той спазва глобалната настройкаmax degree of parallelism. Вероятно не бих направил в производството, освен ако нямах други опции, но това е един всеобхватен начин за контрол на определениDBCCкоманди, ако не можете да ги насочите по-ясно.
Искахме по-добър контрол върху броя на процесорите, които DBCC CHECKDB използва, но те са били многократно отказвани до SQL Server 2014 SP2. Така че вече можете да добавите WITH MAXDOP = n към командата.
Моите констатации
Исках да демонстрирам няколко от тези техники в среда, която мога да контролирам. Инсталирах AdventureWorks2012, след което го разширих с помощта на скрипта за уголемяване на AW, написан от Джонатан Кехайас (блог | @SQLPoolBoy), който увеличи базата данни до около 7 GB. След това пуснах серия от CHECKDB команди срещу него и ги определи времето. Използвах обикновен ванилов DBCC CHECKDB самостоятелно, след това всички други команди се използват WITH NO_INFOMSGS, ALL_ERRORMSGS . След това четири теста с (a) без флагове за следи, (b) 2549, (c) 2562 и (d) и двата 2549 и 2562. След това повторих тези четири теста, но добавих PHYSICAL_ONLY опция, която заобикаля всички логически проверки. Резултатите (средно за 10 теста) са показателни:
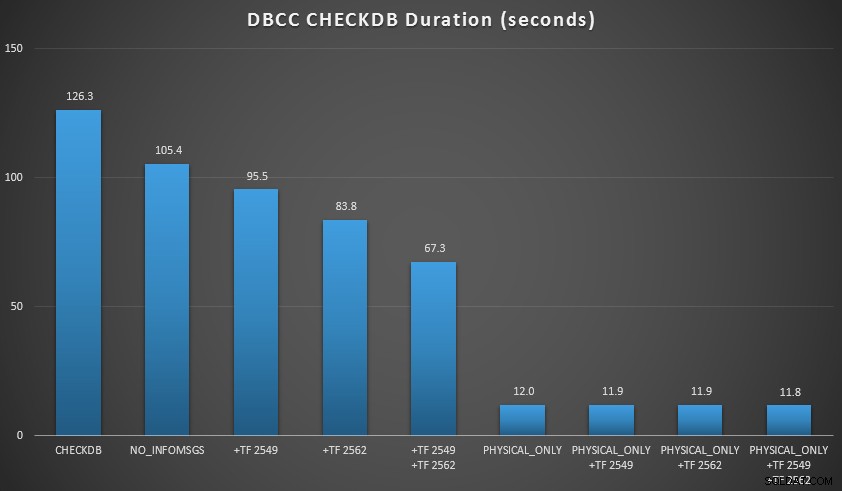
ПРОВЕРЕТЕ резултати от база данни от 7 GB
След това разширих още малко базата данни, като направих много копия на двете увеличени таблици, което доведе до размер на базата данни точно на север от 70 GB, и проведох тестовете отново. Резултатите, отново осреднени за 10 теста:
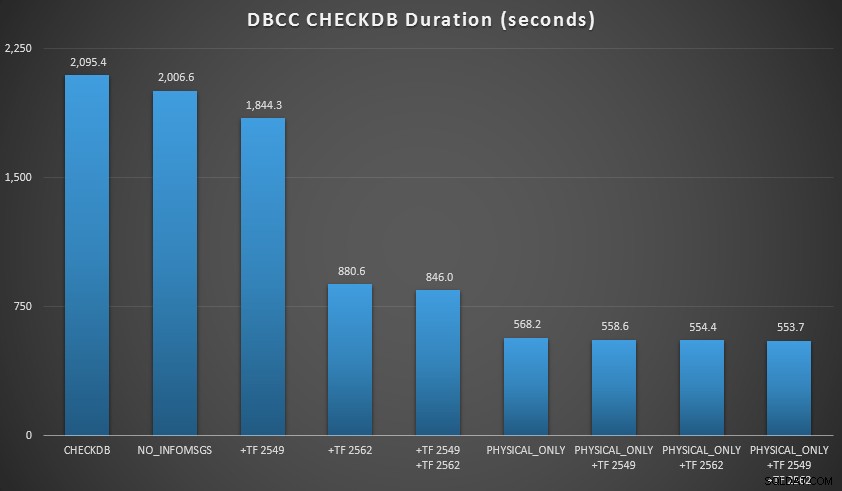
ПРОВЕРЕТЕ резултати от база данни от 70 GB
В тези два сценария научих следното (отново имайки предвид, че вашият пробег може да варира и че ще трябва да извършите свои собствени тестове, за да направите някакви значими заключения):
- Когато трябва да извърша логически проверки:
- При малки размери на базата данни,
NO_INFOMSGSопцията може да съкрати значително времето за обработка, когато проверките се изпълняват в SSMS. При по-големите бази данни обаче тази полза намалява, тъй като времето и работата, изразходвани за предаване на информацията, стават толкова незначителна част от общата продължителност. 21 секунди от 2 минути са значителни; 88 секунди от 35 минути, не толкова. - Двете флага за проследяване, които тествах, оказаха значително влияние върху производителността – представляващо намаляване на времето на изпълнение от 40-60%, когато и двата бяха използвани заедно.
- При малки размери на базата данни,
- Когато мога да изпратя логически проверки към вторичен сървър (отново, ако приемем, че извършвам логически проверки на друго място срещу вярно копие ):
- Мога да намаля времето за обработка на моя първичен екземпляр със 70-90% в сравнение със стандартен
CHECKDBобаждане без опции. - В моя сценарий флаговете за проследяване имаха много малко влияние върху продължителността при изпълнение на
PHYSICAL_ONLYчекове.
- Мога да намаля времето за обработка на моя първичен екземпляр със 70-90% в сравнение със стандартен
Разбира се, и не мога да подчертая това достатъчно, това са сравнително малки бази данни и се използват само за да мога да извършвам повтарящи се, измерени тестове за разумен период от време. Този сървър имаше 80 логически процесора и 128 GB RAM и аз бях единственият потребител. Продължителността и взаимодействието с други натоварвания на системата може доста да изкривят тези резултати. Ето бърз поглед към типичното използване на процесора, използвайки SQL Sentry, по време на едно от CHECKDB операции (и нито една от опциите наистина не промени цялостното въздействие върху процесора, само продължителността):
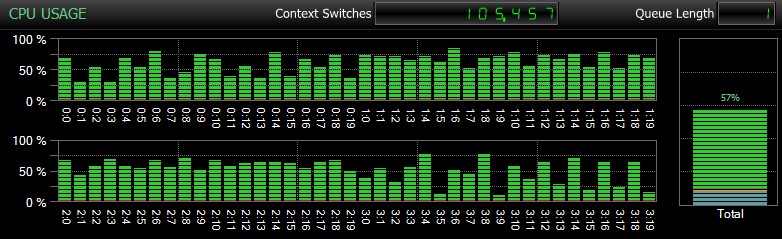
Удар на процесора по време на CHECKDB – примерен режим
И ето друг изглед, показващ подобни профили на процесора за три различни примерни CHECKDB операции в исторически режим (заложих описание на трите теста, включени в този диапазон):
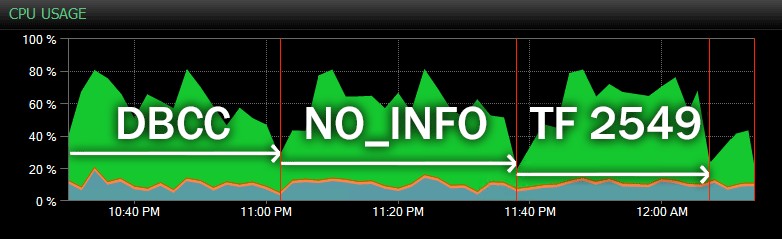
Влияние на процесора по време на CHECKDB – исторически режим
В още по-големи бази данни, хоствани на по-натоварени сървъри, може да видите различни ефекти и е доста вероятно пробегът ви да варира. Затова, моля, извършете надлежната си проверка и тествайте тези опции и проследете флагове по време на типично едновременно натоварване, преди да решите как искате да подходите към CHECKDB .
Заключение
DBCC CHECKDB е много важна, но често подценявана част от вашата отговорност като администратор на база данни или архитект и е от решаващо значение за защитата на данните на вашата компания. Не приемайте тази отговорност лекомислено и направете всичко възможно, за да гарантирате, че няма да жертвате нищо в интерес на намаляване на въздействието върху вашите производствени инстанции. Най-важното:погледнете отвъд листовете с маркетингови данни, за да сте сигурни, че напълно разбирате колко валидни са тези обещания и дали сте готови да заложите данните на вашата компания за тях. Спестяването на някои проверки или прехвърлянето им на невалидни вторични местоположения може да бъде бедствие, което чака да се случи.
Трябва също да помислите за четене на тези статии в PSS:
- По-бърз CHECKDB – част I
- По-бърз CHECKDB – част II
- По-бърз CHECKDB – част III
- По-бърза CHECKDB – част IV (SQL CLR UDT)
И тази публикация от Брент Озар:
- 3 начина за по-бързо изпълнение на DBCC CHECKDB
И накрая, ако имате неразрешен въпрос относно DBCC CHECKDB , публикувайте го в хеш маркера #sqlhelp в Twitter. Пол проверява този маркер често и тъй като снимката му трябва да се появи в основната статия на Books Online, вероятно ако някой може да отговори, той може. Ако е твърде сложно за 140 знака, можете да попитате тук (и аз ще се уверя, че Пол го вижда в даден момент) или да публикувате във форумен сайт, като например Database Administrators Stack Exchange.