Най-общо казано, най-добрият вид сортиране е този, който се избягва напълно. С внимателно индексиране и понякога творческо писане на заявки често можем да премахнем необходимостта от оператор за сортиране от плановете за изпълнение. Когато данните за сортиране са големи, избягването на този вид сортиране може да доведе до много значителни подобрения в производителността.
Вторият най-добър вид сортиране е този, който не можем да избегнем, но който запазва подходящо количество памет и използва цялата или по-голямата част от нея, за да направи нещо, което си заслужава. Да си полезен може да приеме много форми. Понякога сортирането може повече от само себе си, като активира по-късна операция, която работи много по-ефективно при сортирани входни данни. Друг път сортирането е просто необходимо и ние просто трябва да го направим възможно най-ефективен.
След това идват сортовете, които обикновено искаме да избягваме:тези, които запазват много повече памет, отколкото им е необходимо, и тези, които резервират твърде малко. Последният случай е този, върху който повечето хора се фокусират. При недостатъчно запазена (или налична) памет за завършване на необходимата операция по сортиране в паметта, операторът за сортиране, с малки изключения, ще разпръсне редове с данни в tempdb . В действителност това почти винаги означава записване на страници за сортиране във физическото хранилище (и четенето им по-късно, разбира се).
В съвременните версии на SQL Server разлятото сортиране води до икона за предупреждение в плановете след изпълнение, която може да включва подробности относно това колко данни са били разпръснати, колко нишки са били включени и нивото на разливане.
Фон:Нива на разлив
Помислете за задачата да сортирате 4000MB данни, когато имаме само 500MB налична памет. Очевидно не можем да сортираме целия набор в паметта наведнъж, но можем да разбием задачата:
Първо четем 500MB данни, сортираме набора в паметта, след което записваме резултата на диска. Извършването на това общо 8 пъти консумира целия вход от 4000MB, което води до 8 комплекта сортирани данни с размер 500MB. Втората стъпка е да извършите 8-посочно сливане на сортираните набори от данни. Имайте предвид, че сливане се изисква, а не просто обединяване на наборите, тъй като гарантирано е, че данните ще бъдат сортирани само според изискванията в рамките на конкретен набор от 500 MB на междинния етап.
По принцип бихме могли да четем и обединяваме един ред наведнъж от всеки от осемте сортирания, но това не би било много ефективно. Вместо това, ние четем първата част от всеки вид, който се изпълнява обратно в паметта, да речем 60MB. Това консумира 8 x 60MB =480MB от наличните 500MB. След това можем ефективно да извършим 8-посочното сливане в паметта за известно време, като буферираме окончателния сортиран изход с все още наличните 20MB памет. Тъй като всеки от буферите на паметта за сортиране се изпразва, ние четем нова секция от този сорт, изпълнявана в паметта. След като всички цикли за сортиране бъдат изконсумирани, сортирането е завършено.
Има някои допълнителни подробности и оптимизации, които можем да включим, но това е основното очертание на разлив от ниво 1, известен също като разлив с едно преминаване. Изисква се едно допълнително преминаване върху данните, за да се получи окончателния сортиран изход.
Сега n-посоченото сливане теоретично може да побере вид от всякакъв размер, във всякакво количество памет, просто чрез увеличаване на броя на междинните локално сортирани набори. Проблемът е, че с увеличаването на 'n' в крайна сметка четем и пишем по-малки парчета данни. Например, сортирането на 400GB данни в 500MB памет би означавало нещо като 800-посочно сливане, като само около 0,6MB от всеки междинно сортиран набор в паметта по всяко време (800 x 0,6MB =480MB, оставяйки малко място за изходен буфер).
Множество пасове за сливане могат да се използват за заобикаляне на това. Общата идея е постепенно да се сливат малки парчета в по-големи, докато не можем ефективно да произведем окончателния сортиран изходен поток. В примера това може да означава сливане на 40 от 800-те сортирани при първо преминаване набора наведнъж, което води до 20 по-големи парчета, които след това могат да бъдат обединени отново, за да образуват изхода. С общо две допълнителни преминавания над данните, това би било разлив на ниво 2 и т.н. За щастие, линейното увеличение на нивото на разлива позволява експоненциално увеличаване на размера на сортирането, така че нивата на дълбоко сортиране рядко са необходими.
Разливът на „ниво 15 000“
В този момент може да се чудите каква комбинация от малка памет и огромен размер на данни може да доведе до разлив на сортиране на ниво 15 000. Опитвате се да сортирате целия интернет в 1MB памет? Възможно е, но това е твърде трудно за демонстрация. Честно казано, нямам представа дали такова наистина високо ниво на разлив е възможно дори в SQL Server. Целта тук (със сигурност измама) е да накарате SQL Server да докладва разлив на ниво 15 000.
Основната съставка е разделянето. От SQL Server 2012 ни е разрешено (удобно) максимум 15 000 дяла на обект (поддръжката за 15 000 дяла е налична и в 2008 SP2 и 2008 R2 SP1, но трябва да го активирате ръчно за база данни и да сте наясно с всички предупрежденията).
Първото нещо, от което ще се нуждаем, е функция за дял от 15 000 елемента и свързана схема на дялове. За да избегнете наистина огромен вграден кодов блок, следният скрипт използва динамичен SQL за генериране на необходимите изрази:
DECLARE
@sql nvarchar(max) =
N'
CREATE PARTITION FUNCTION PF (integer)
AS RANGE LEFT
FOR VALUES
(1';
DECLARE @i integer = 2;
WHILE @i < 15000
BEGIN
SET @sql += N',' + CONVERT(nvarchar(5), @i);
SET @i += 1;
END;
SET @sql = @sql + N');';
EXECUTE (@sql);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]); Скриптът е достатъчно лесен за промяна на по-нисък брой, в случай че вашата настройка се бори с 15 000 дяла (особено от гледна точка на паметта, както ще видим скоро). Следващите стъпки са да създадете нормална (неразделена) таблица с колона с една цяло число и след това да я попълните с цели числа от 1 до 15 000 включително:
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test1 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Това трябва да завърши за 100 ms или така. Ако имате налична таблица с числа, не се колебайте да я използвате за по-базирано изживяване. Начинът на попълване на базовата таблица не е важен. За да получим нашите 15 000 нива, всичко, което трябва да направим сега, е да създадем разделен клъстериран индекс на таблицата:
CREATE UNIQUE CLUSTERED INDEX CUQ ON dbo.Test1 (c1) WITH (MAXDOP = 1) ON PS (c1);
Времето за изпълнение зависи много от използваната система за съхранение. На моя лаптоп, използвайки доста типичен потребителски SSD от преди няколко години, отнема около 20 секунди, което е доста важно, като се има предвид, че имаме работа само с 15 000 реда общо. На Azure VM с доста ниска спецификация с доста ужасна I/O производителност, същият тест отне близо 20 минути.
Анализ
Планът за изпълнение за изграждането на индекса е:
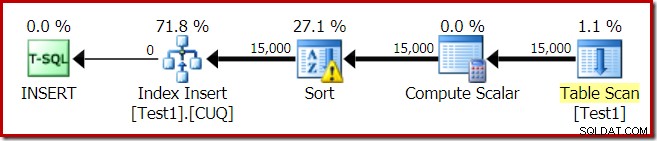
Сканирането на таблицата чете 15 000 реда от нашата таблица на heap. Скаларът за изчисляване изчислява номера на дестинацията на индексния дял за всеки ред, използвайки вътрешната функция RangePartitionNew() . Сортирането е най-интересната част от плана, така че ще го разгледаме по-подробно.
Първо, предупреждението за сортиране, както е показано в Plan Explorer:

Подобно предупреждение от SSMS (взето от различно изпълнение на скрипта):
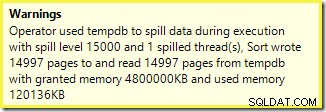
Първото нещо, което трябва да се отбележи, е докладът за ниво на разлив от 15 000 вида, както беше обещано. Това не е съвсем точно, но подробностите са доста интересни. Сортирането в този план има Partition ID свойство, което обикновено не присъства:
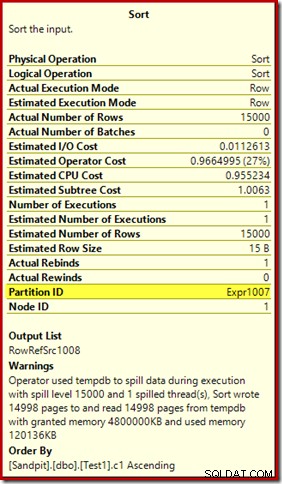
Това свойство се задава равно на дефиницията на функцията за вътрешно разделяне в Compute Scalar.
Това е неподравнено изграждане на индекс , тъй като източникът и местоназначението имат различни договорености за разделяне. В този случай тази разлика възниква, защото таблицата на изходната купчина не е разделена, но индексът на дестинацията е. В резултат на това по време на изпълнение се създават 15 000 отделни сорта:по един на непразен целеви дял. Всеки от тези сортове се разлива до ниво 1 и SQL Server сумира всички тези разливания, за да даде крайното ниво на разлив на сортиране от 15 000.
15 000 отделни сорта обясняват големия размер на паметта. Всеки екземпляр за сортиране има минимален размер от 40 страници, което е 40 x 8KB =320KB. Следователно 15 000 сорта изискват 15 000 x 320 KB =4 800 000 KB памет като минимум. Това е малко по-малко от 4,6 GB RAM, запазени изключително за заявка, която сортира 15 000 реда, съдържащи една колона с цяло число. И всеки сорт се разлива на диск, въпреки че получава само един ред! Ако се използва паралелизъм за изграждането на индекса, предоставянето на памет може да бъде допълнително увеличено с броя на нишките. Имайте предвид също, че единичният ред е написан на страница, което обяснява броя на страниците, записани и прочетени от tempdb. Изглежда има състояние на състезание, което означава, че отчетеният брой страници често е малко по-малко от 15 000.
Този пример отразява крайния случай, разбира се, но все още е трудно да се разбере защо всеки сорт разлива своя единичен ред, вместо да сортира в паметта, която му е дадена. Може би това е проектирано по някаква причина или може би е просто грешка. Какъвто и да е случаят, все още е доста забавно да видите нещо като няколкостотин KB данни, които отнемат толкова време с 4,6 GB памет и 15 000 нива. Освен ако не го срещнете в производствена среда, може би. Както и да е, това е нещо, което трябва да сте наясно.
Подвеждащият доклад за разливане на нива от 15 000 се свежда до голяма степен до ограничения на представянето в изходния план на шоуто. Основният проблем е нещо, което възниква на много места, където се извършват повтарящи се действия, например от вътрешната страна на вложените цикли се присъединяват. Със сигурност би било полезно да можете да видите по-точна разбивка вместо обща сума в тези случаи. С течение на времето тази област се подобри малко, така че вече имаме повече информация за план за нишка или за дял за някои операции. Все пак има още дълъг път.
Все още е по-малко полезно, че 15 000 отделни разлива от ниво 1 се отчитат тук като единичен разлив на ниво 15 000.
Тестови варианти
Тази статия е по-скоро за подчертаване на ограниченията на информацията за плана и потенциала за лоша производителност, когато се използват огромен брой дялове, отколкото за това да направим конкретната примерна операция по-ефективна, но има няколко интересни варианта, които също искам да разгледам .
Онлайн, сортиране в tempdb
Извършване на същата операция за създаване на разделен индекс с ONLINE = ON, SORT_IN_TEMPDB = ON не страда от същото огромно предоставяне на памет и разливане:
CREATE TABLE dbo.Test2
(
c1 integer NOT NULL
);
-- Copy the sample data
INSERT dbo.Test2 WITH (TABLOCKX)
(c1)
SELECT
T1.c1
FROM dbo.Test1 AS T1
OPTION (MAXDOP 1);
-- Partitioned clustered index build
CREATE CLUSTERED INDEX CUQ
ON dbo.Test2 (c1)
WITH (MAXDOP = 1, ONLINE = ON, SORT_IN_TEMPDB = ON)
ON PS (c1);
Имайте предвид, че използвате ONLINE само по себе си не е достатъчно. Всъщност това води до същия план като преди с всички същите проблеми, плюс допълнителни разходи за изграждане на всеки индексен дял онлайн. За мен това води до време за изпълнение над минута. Бог знае колко време ще отнеме екземпляр на Azure с ниска спецификация с ужасна I/O производителност.
Както и да е, планът за изпълнение с ONLINE = ON, SORT_IN_TEMPDB = ON е:

Сортирането се извършва преди да бъде изчислен номерът на целевия дял. Той няма свойството Partition ID, така че е просто нормален сорт. Цялата операция се изпълнява за около десет секунди (все още има много дялове за създаване). Той запазва по-малко от 3MB памет и използва максимум 816KB. Доста подобрение в сравнение с 4,6 GB и 15 000 разливания.
Първо индексирайте, след това данни
Подобни резултати могат да бъдат получени, като първо се запишат данните в heap таблица:
-- Heap source
CREATE TABLE dbo.SourceData
(
c1 integer NOT NULL
);
-- Add data
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.SourceData (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; След това създайте празна разделена клъстерирана таблица и вмъкнете данните от хийпа:
-- Destination table
CREATE TABLE dbo.Test3
(
c1 integer NOT NULL
)
ON PS (c1); -- Optional
-- Partitioned Clustered Index
CREATE CLUSTERED INDEX CUQ
ON dbo.Test3 (c1)
ON PS (c1);
-- Add data
INSERT dbo.Test3 WITH (TABLOCKX)
(c1)
SELECT
SD.c1
FROM dbo.SourceData AS SD
OPTION (MAXDOP 1);
-- Clean up
DROP TABLE dbo.SourceData; Това отнема около десет секунди, с 2MB памет и без разливане:
Разбира се, сортирането може да бъде избегнато напълно чрез индексиране на (неразделената) изходна таблица и вмъкване на данните в индексен ред (най-доброто сортиране е изобщо без сортиране, запомнете).
Разпределена купчина, след това данни, след това индекс
За тази последна вариация първо създаваме разделена купчина и зареждаме 15 000 тестови реда:
CREATE TABLE dbo.Test4
(
c1 integer NOT NULL
)
ON PS (c1);
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test4 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Този скрипт работи за секунда или две, което е доста добре. Последната стъпка е да създадете разделения клъстериран индекс:
CREATE CLUSTERED INDEX CUQ ON dbo.Test4 (c1) WITH (MAXDOP = 1) ON PS (c1);
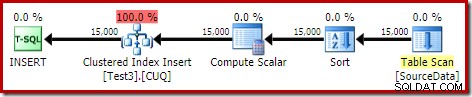
Това е пълна катастрофа, както от гледна точка на производителността, така и от гледна точка на информацията за плана на шоуто. Самата операция се изпълнява за малко под минута, със следния план за изпълнение:

Това е разпределен план за вмъкване. Постоянното сканиране съдържа ред за всеки идентификатор на дял. Вътрешната страна на цикъла търси текущото разделяне на хийпа (да, търсене в купчина). Сортирането има свойство идентификатор на дял (въпреки че това е константа за итерация на цикъл), така че има сортиране за дял и нежелано поведение при разливане. Предупреждението за статистиката в таблицата на heap е фалшиво.
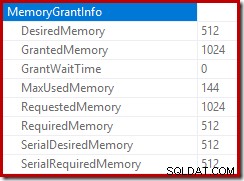
Коренът на плана за вмъкване показва, че е запазено предоставяне на памет от 1MB, с използвани максимум 144KB:
Операторът за сортиране не отчита разлив на ниво 15 000, но в противен случай прави пълна бъркотия в математиката на итерацията на цикъл:

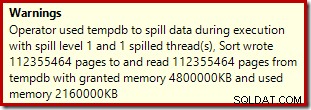
Наблюдението на паметта, предоставяща DMV по време на изпълнение, показва, че тази заявка всъщност резервира само 1MB, с максимум 144KB, използвани за всяка итерация на цикъла. (За разлика от това, резервацията от 4,6 GB памет в първия тест е абсолютно истинска.) Това, разбира се, е объркващо.
Проблемът (както беше споменато по-рано) е, че SQL Server се обърква как най-добре да докладва за случилото се при много итерации. Вероятно не е практично да се включва информация за ефективността на плана за дял на итерация, но няма как да се отървем от факта, че текущото подреждане дава объркващи резултати на моменти. Можем само да се надяваме, че един ден ще бъде намерен по-добър начин за докладване на този тип информация в по-последователен формат.