Да приемем, че искате да намерите всички пациенти, които никога не са били ваксинирани срещу грип. Или в AdventureWorks2012 , подобен въпрос може да бъде "покажи ми всички клиенти, които никога не са направили поръчка." Изразено с помощта на NOT IN , модел, който виждам твърде често, който би изглеждал нещо подобно (използвам увеличените таблици за заглавки и подробности от този скрипт от Джонатан Кехайас (@SQLPoolBoy)):
SELECT CustomerID FROM Sales.Customer WHERE CustomerID NOT IN ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged );
Когато видя този модел, настръхвам. Но не от съображения за производителност – в края на краищата той създава достатъчно приличен план в този случай:
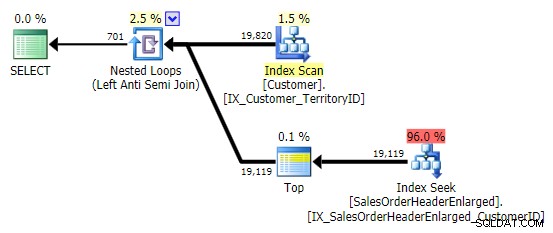
Основният проблем е, че резултатите могат да бъдат изненадващи, ако целевата колона е NULL (SQL Server обработва това като ляво анти полусъединяване, но не може надеждно да ви каже дали NULL от дясната страна е равно на – или не е равно на – препратката от лявата страна). Освен това оптимизацията може да се държи по различен начин, ако колоната е NULL, дори ако всъщност не съдържа никакви NULL стойности (Гейл Шоу говори за това още през 2010 г.).
В този случай целевата колона не може да бъде нула, но исках да спомена тези потенциални проблеми с NOT IN – Може да проуча тези въпроси по-задълбочено в бъдеща публикация.
TL;DR версия
Вместо NOT IN , използвайте свързан NOT EXISTS за този модел на заявка. Винаги. Други методи могат да му съперничат по отношение на производителността, когато всички други променливи са едни и същи, но всички други методи въвеждат или проблеми с производителността, или други предизвикателства.
Алтернативи
И така, какви други начини можем да напишем тази заявка?
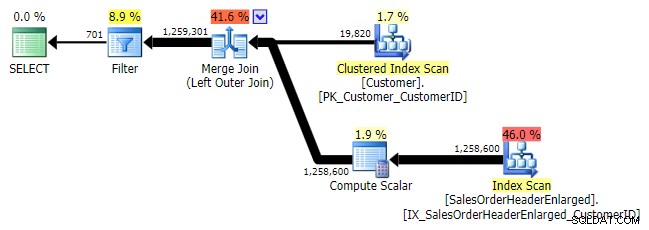
ВЪНШНО ПРИЛАГАНЕ
Един от начините, по които можем да изразим този резултат, е да използваме свързано OUTER APPLY .
SELECT c.CustomerID FROM Sales.Customer AS c OUTER APPLY ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged WHERE CustomerID = c.CustomerID ) AS h WHERE h.CustomerID IS NULL;
Логично, това също е ляво анти полуприсъединяване, но в резултатния план липсва операторът за ляво анти полуприсъединяване и изглежда е доста по-скъп от NOT IN еквивалентен. Това е така, защото вече не е ляво анти полусъединяване; всъщност се обработва по различен начин:външно свързване въвежда всички съвпадащи и несъвпадащи редове и *след това* се прилага филтър за елиминиране на съвпаденията:
ЛЯВО ВЪНШНО ПРИЕДИНЕНИЕ
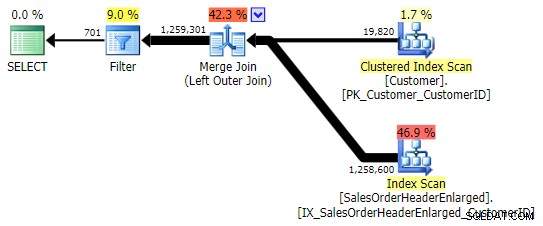
По-типична алтернатива е LEFT OUTER JOIN където дясната страна е NULL . В този случай заявката ще бъде:
SELECT c.CustomerID FROM Sales.Customer AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS h ON c.CustomerID = h.CustomerID WHERE h.CustomerID IS NULL;
Това връща същите резултати; обаче, подобно на OUTER APPLY, той използва същата техника за свързване на всички редове и едва след това елиминиране на съвпаденията:
Трябва обаче да внимавате коя колона проверявате за NULL . В този случай CustomerID е логичният избор, защото е свързващата колона; също така се случва да бъде индексиран. Бих могъл да избера SalesOrderID , който е ключът за клъстериране, така че е и в индекса на CustomerID . Но можех да избера друга колона, която не е в (или която по-късно ще бъде премахната от) индекса, използван за присъединяването, което води до различен план. Или дори колона с NULL, което води до неправилни (или поне неочаквани) резултати, тъй като няма начин да се направи разлика между ред, който не съществува, и ред, който съществува, но където тази колона е NULL . И може да не е очевидно за читателя/разработчика/инструмента за отстраняване на неизправности, че това е така. Така че ще тествам и тези три WHERE клаузи:
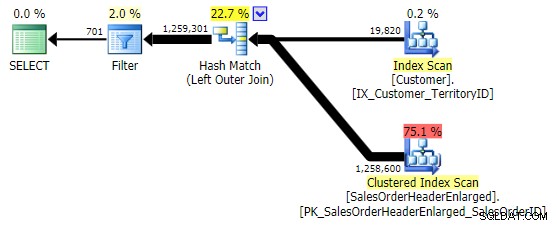
WHERE h.SalesOrderID IS NULL; -- clustered, so part of index WHERE h.SubTotal IS NULL; -- not nullable, not part of the index WHERE h.Comment IS NULL; -- nullable, not part of the index
Първият вариант произвежда същия план като по-горе. Другите двама избират хеш присъединяване вместо обединяване за сливане и по-тесен индекс в Customer таблица, въпреки че в крайна сметка заявката чете точно същия брой страници и количество данни. Въпреки това, докато h.SubTotal вариацията дава правилните резултати:
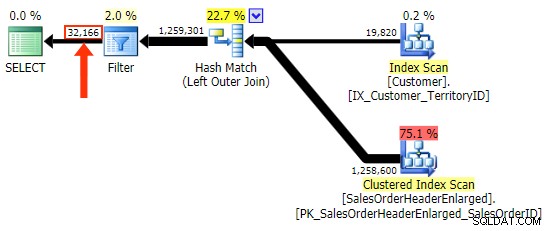
h.Comment вариацията не, тъй като включва всички редове, където h.Comment IS NULL , както и всички редове, които не съществуват за нито един клиент. Подчертах фината разлика в броя на редовете в изхода след прилагане на филтъра:
Освен че трябва да внимавам за избора на колони във филтъра, другият проблем, който имам с LEFT OUTER JOIN формата е, че не се самодокументира, по същия начин, по който вътрешното присъединяване във формата "стар стил" на FROM dbo.table_a, dbo.table_b WHERE ... не се самодокументира. С това имам предвид, че е лесно да забравите критериите за присъединяване, когато се премести в WHERE клауза, или за да се смеси с други критерии за филтриране. Разбирам, че това е доста субективно, но това е така.
ОСВЕН
Ако всичко, от което се интересуваме, е колоната за присъединяване (която по дефиниция е и в двете таблици), можем да използваме EXCEPT – алтернатива, която изглежда не се появява много в тези разговори (вероятно защото – обикновено – трябва да разширите заявката, за да включите колони, които не сравнявате):
SELECT CustomerID FROM Sales.Customer AS c EXCEPT SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged;
Това идва с абсолютно същия план като NOT IN вариант по-горе:
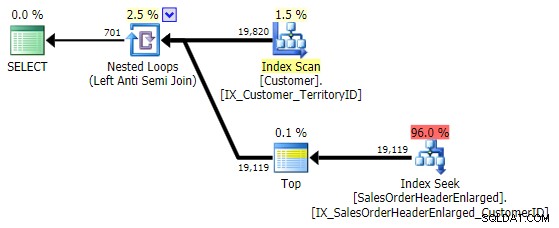
Едно нещо, което трябва да имате предвид е, че EXCEPT включва неявно DISTINCT – така че ако имате случаи, в които искате няколко реда с една и съща стойност в „лявата“ таблица, този формуляр ще премахне тези дубликати. Не е проблем в този конкретен случай, просто нещо, което трябва да имате предвид – точно като UNION срещу UNION ALL .
НЕ СЪЩЕСТВУВА
Моето предпочитание за този модел определено е NOT EXISTS :
SELECT CustomerID
FROM Sales.Customer AS c
WHERE NOT EXISTS
(
SELECT 1
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
);
(И да, използвам SELECT 1 вместо SELECT * … не поради съображения за производителност, тъй като SQL Server не се интересува коя колона(и) използвате в EXISTS и ги оптимизира, но просто за да изясня намерението:това ми напомня, че тази „подзаявка“ всъщност не връща никакви данни.)
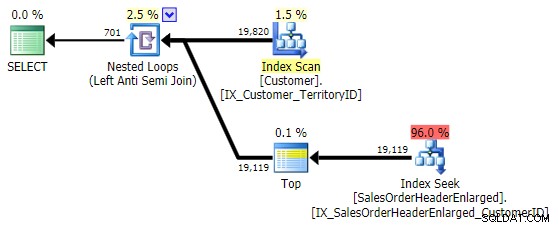
Изпълнението му е подобно на NOT IN и EXCEPT , и създава идентичен план, но не е склонен към потенциални проблеми, причинени от NULL или дубликати:
Тестове за производителност
Проведох множество тестове, както със студен, така и с топъл кеш, за да потвърдя, че моето дългогодишно възприятие за NOT EXISTS да бъде правилният избор остана вярно. Типичният изход изглеждаше така:
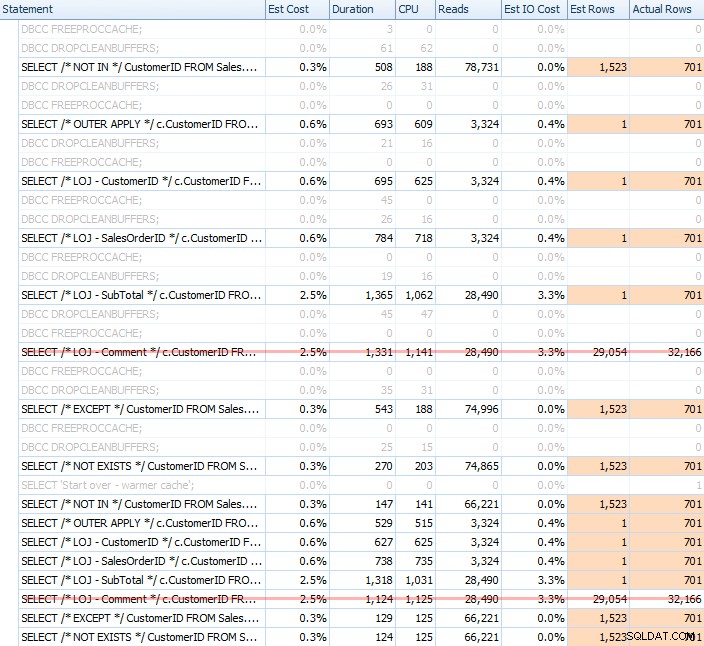
Ще извадя грешния резултат от микса, когато показвам средната производителност от 20 цикъла на графика (включих го само, за да демонстрирам колко грешни са резултатите) и изпълних заявките в различен ред в тестовете, за да се уверя че една заявка не е имала постоянна полза от работата на предишна заявка. Фокусирайки се върху продължителността, ето резултатите:
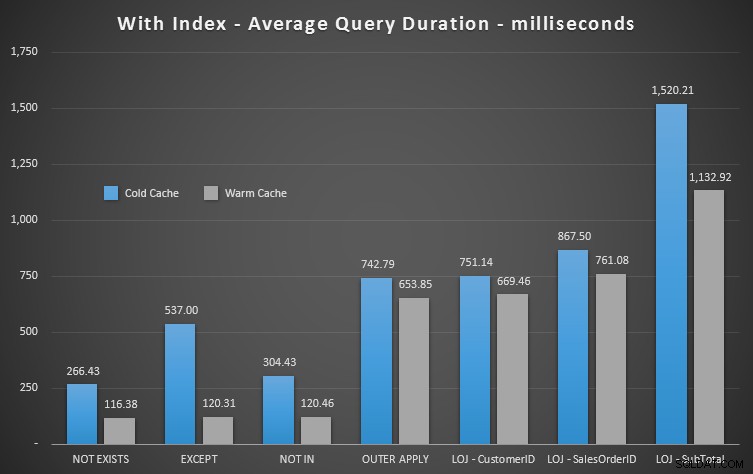
Ако погледнем продължителността и игнорираме четенията, NOT EXISTS е вашият победител, но не много. EXCEPT и NOT IN не изостават, но отново трябва да погледнете не само производителността, за да определите дали тези опции са валидни, и да тествате във вашия сценарий.
Ами ако няма поддържащ индекс?
Заявките по-горе, разбира се, се възползват от индекса на Sales.SalesOrderHeaderEnlarged.CustomerID . Как се променят тези резултати, ако изпуснем този индекс? Проведох отново същия набор от тестове, след като пуснах индекса:
DROP INDEX [IX_SalesOrderHeaderEnlarged_CustomerID] ON [Sales].[SalesOrderHeaderEnlarged];
Този път имаше много по-малко отклонения по отношение на производителността между различните методи. Първо ще покажа плановете за всеки метод (повечето от които, не е изненадващо, показват полезността на липсващия индекс, който току-що изпуснахме). След това ще покажа нова графика, изобразяваща профила на производителност както със студен, така и с топъл кеш.
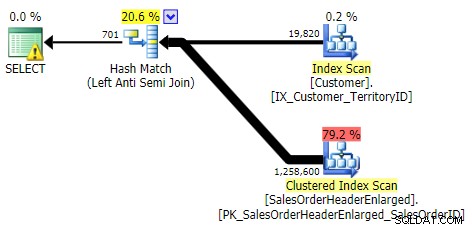
НЕ ВЪВ, ОСВЕН, НЕ СЪЩЕСТВУВА (и трите бяха идентични)
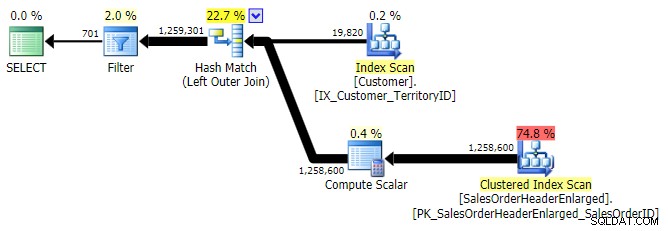
ВЪНШНО ПРИЛАГАНЕ
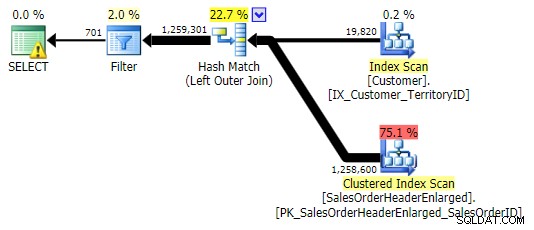
LEFT OUTER JOIN (и трите бяха идентични с изключение на броя на редовете)
Резултати от производителността
Веднага можем да видим колко полезен е индексът, когато погледнем тези нови резултати. Във всички случаи освен в един (лявото външно съединение, което така или иначе излиза извън индекса), резултатите са очевидно по-лоши, когато сме изпуснали индекса:
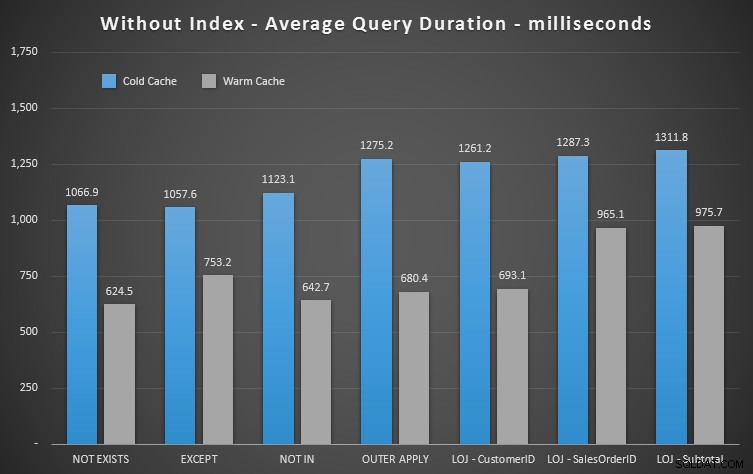
Така че можем да видим, че макар да има по-малко забележимо въздействие, NOT EXISTS все още е вашият краен победител по отношение на продължителността. И в ситуации, в които другите подходи са податливи на нестабилност на схемата, това също е най-сигурният ви избор.
Заключение
Това беше просто един наистина дълъг начин да ви кажа, че за модела на намиране на всички редове в таблица А, където някакво условие не съществува в таблица Б, NOT EXISTS обикновено ще бъде най-добрият ви избор. Но, както винаги, трябва да тествате тези модели във вашата собствена среда, като използвате вашата схема, данни и хардуер и смесете с вашите собствени работни натоварвания.