Най-бързият начин за изчисляване на медиана използва SQL Server 2012 OFFSET разширение към ORDER BY клауза. Следващото най-бързо решение използва (евентуално вложен) динамичен курсор, който работи във всички версии. Тази статия разглежда често срещан отпреди 2012 г. ROW_NUMBER решение на проблема с изчислението на медианата, за да видите защо се представя по-малко и какво може да се направи, за да върви по-бързо.
Единичен среден тест
Примерните данни за този тест се състоят от една таблица от десет милиона реда (възпроизвеждана от оригиналната статия на Aaron Bertrand):
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); Решение OFFSET
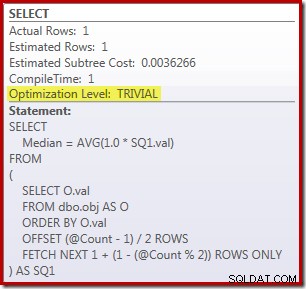
За да зададете еталон, ето решението OFFSET за SQL Server 2012 (или по-нова версия), създадено от Peter Larsson:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - (@Count % 2)) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Заявката за преброяване на редовете в таблицата се коментира и заменя с твърдо кодирана стойност, така че да се концентрира върху производителността на основния код. С изключен топъл кеш и планове за изпълнение, тази заявка се изпълнява за 910 ms средно на моята тестова машина. Планът за изпълнение е показан по-долу:

Като странична бележка е интересно, че тази умерено сложна заявка отговаря на изискванията за тривиален план:
Решението ROW_NUMBER
За системи, работещи със SQL Server 2008 R2 или по-стара версия, най-ефективното от алтернативните решения използва динамичен курсор, както беше споменато по-горе. Ако не сте в състояние (или не желаете) да обмислите това като опция, естествено е да помислите за емулиране на 2012 OFFSET план за изпълнение с помощта на ROW_NUMBER .
Основната идея е да номерирате редовете в подходящия ред, след което да филтрирате само за един или два реда, необходими за изчисляване на медианата. Има няколко начина да напишете това в Transact SQL; компактна версия, която улавя всички ключови елементи, е както следва:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
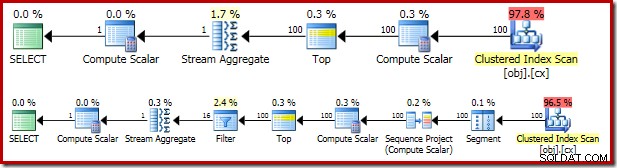
Полученият план за изпълнение е доста подобен на OFFSET версия:

Струва си да разгледате всеки от операторите на плана на свой ред, за да ги разберете напълно:
- Операторът „Сегмент“ е излишен в този план. Ще се изисква, ако
ROW_NUMBERфункцията за класиране имашеPARTITION BYклауза, но не. Въпреки това остава в крайния план. - Проектът Sequence добавя изчислен номер на ред към потока от редове.
- Скаларът за изчисляване дефинира израз, свързан с необходимостта от имплицитно преобразуване на
valколона към число, така че да може да се умножи по константния литерал1.0в заявката. Това изчисление се отлага, докато не се наложи от по-късен оператор (който се оказва Stream Aggregate). Тази оптимизация по време на изпълнение означава, че имплицитното преобразуване се извършва само за двата реда, обработени от Stream Aggregate, а не за 5 000 001 реда, посочени за Compute Scalar. - Операторът Top се въвежда от оптимизатора на заявки. Той разпознава най-много само първия
(@Count + 2) / 2редовете са необходими на заявката. Можехме да добавимTOP ... ORDER BYв подзаявката, за да направи това изрично, но тази оптимизация прави това до голяма степен ненужно. - Филтърът изпълнява условието в
WHEREклауза, филтрираща всички, освен двата „средни“ реда, необходими за изчисляване на медианата (въведеният Top също се основава на това условие). - Агрегатът на потока изчислява
SUMиCOUNTот двата средни реда. - Окончателният скалар за изчисляване изчислява средната стойност от сумата и броя.
Необработена производителност
В сравнение с OFFSET план, може да очакваме, че допълнителните оператори за сегмент, проект за последователност и филтър ще имат някакъв неблагоприятен ефект върху производителността. Струва си да отделите малко време, за да сравните приблизителните разходи за двата плана:
OFFSET планът има прогнозна цена от 0,0036266 единици, докато ROW_NUMBER планът се оценява на 0,0036744 единици. Това са много малки числа и има малка разлика между двете.
Така че може би е изненадващо, че ROW_NUMBER заявката всъщност работи за 4000 ms средно в сравнение с 910 ms средно за OFFSET решение. Част от това увеличение със сигурност може да се обясни с режийните разходи на операторите на допълнителния план, но коефициент четири изглежда прекомерен. Трябва да има още.
Вероятно сте забелязали също така, че оценките за мощността и за двата прогнозни плана по-горе са доста безнадеждно погрешни. Това се дължи на ефекта на операторите Top, които имат израз, препращащ променлива като граници на броя на редовете. Оптимизаторът на заявки не може да види съдържанието на променливите по време на компилация, така че прибягва до предположението си по подразбиране от 100 реда. И двата плана всъщност срещат 5 000 001 реда по време на изпълнение.
Всичко това е много интересно, но не обяснява директно защо ROW_NUMBER заявката е повече от четири пъти по-бавна от OFFSET версия. В края на краищата оценката за 100 реда е също толкова погрешна и в двата случая.
Подобряване на производителността на решението ROW_NUMBER
В предишната ми статия видяхме как се представя представянето на групираната медиана OFFSET тестът може да бъде почти удвоен чрез просто добавяне на PAGLOCK намек. Този намек отменя нормалното решение на механизма за съхранение да придобие и освободи споделени ключалки при детайлност на реда (поради ниската очаквана мощност).
Като допълнително напомняне, PAGLOCK намекът беше ненужен в единичната медиана OFFSET тест поради отделна вътрешна оптимизация, която може да пропусне споделените заключване на ниво ред, което води до само малък брой заключвания със споделени намерения, които се вземат на ниво страница.
Може да очакваме ROW_NUMBER едно средно решение да се възползва от същата вътрешна оптимизация, но не. Наблюдаване на активността по заключване, докато ROW_NUMBER заявката се изпълнява, виждаме над половин милион споделени брави на ниво отделен ред са взети и освободени.
И така, сега знаем какъв е проблемът, можем да подобрим ефективността на заключване по същия начин, по който направихме преди:или с PAGLOCK намек за заключване на детайлност или чрез увеличаване на оценката за кардиналност с помощта на документиран флаг за проследяване 4138.
Деактивирането на "цел на ред" с помощта на флага за проследяване е по-малко задоволителното решение по няколко причини. Първо, той е ефективен само в SQL Server 2008 R2 или по-нова версия. Най-вероятно бихме предпочели OFFSET решение в SQL Server 2012, така че това ефективно ограничава корекцията на флага за проследяване само до SQL Server 2008 R2. Второ, прилагането на флага за проследяване изисква разрешения на ниво администратор, освен ако не се прилага чрез ръководство за план. Трета причина е, че деактивирането на целите на редове за цялата заявка може да има други нежелани ефекти, особено при по-сложни планове.
За разлика от това, PAGLOCK намекът е ефективен, наличен във всички версии на SQL Server без специални разрешения и няма големи странични ефекти освен детайлността на заключването.
Прилагане на PAGLOCK намек за ROW_NUMBER заявката увеличава производителността драстично:от 4000 ms до 1500 ms:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK) -- New!
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
1500 ms резултатът все още е значително по-бавен от 910 ms за OFFSET решение, но поне сега е на същото ниво. Оставащата разлика в производителността се дължи просто на допълнителната работа в плана за изпълнение:

В OFFSET план, пет милиона реда се обработват до върха (с изразите, дефинирани в Compute Scalar, отложени, както беше обсъдено по-рано). В ROW_NUMBER план, същият брой редове трябва да бъдат обработени от сегмента, проекта за последователност, върха и филтъра.