Имаше много коментари след публикацията ми миналата седмица относно разделянето на низове. Мисля, че смисълът на статията не беше толкова очевиден, колкото би могъл да бъде:че прекарването на много време и усилия, опитвайки се да "усъвършенствате" по своята същност бавна функция за разделяне, базирана на T-SQL, няма да бъде от полза. Оттогава събрах най-новата версия на функцията за разделяне на низове на Джеф Модън и я противопоставих на останалите:
ALTER FUNCTION [dbo].[DelimitedSplitN4K]
(@pString NVARCHAR(4000), @pDelimiter NCHAR(1))
RETURNS TABLE WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
cteTally(N) AS (SELECT TOP (ISNULL(DATALENGTH(@pString)/2,0))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4),
cteStart(N1) AS (SELECT 1 UNION ALL
SELECT t.N+1 FROM cteTally t WHERE SUBSTRING(@pString,t.N,1) = @pDelimiter
),
cteLen(N1,L1) AS(SELECT s.N1,
ISNULL(NULLIF(CHARINDEX(@pDelimiter,@pString,s.N1),0)-s.N1,4000)
FROM cteStart s
)
SELECT ItemNumber = ROW_NUMBER() OVER(ORDER BY l.N1),
Item = SUBSTRING(@pString, l.N1, l.L1)
FROM cteLen l;
GO (Единствените промени, които направих:форматирах го за показване и премахнах коментарите. Можете да извлечете оригиналния източник тук.)
Трябваше да направя няколко корекции в тестовете си, за да представя справедливо функцията на Джеф. Най-важното:трябваше да изхвърля всички проби, които включват низове> 4000 знака. Затова промених низовете от 5000 знака в таблицата dbo.strings, за да бъдат 4000 знака вместо това и се фокусирах само върху първите три не-MAX сценария (запазване на предишните резултати за първите два и стартиране на третите тестове отново за новия дължина на низовете от 4000 знака). Също така изпуснах таблицата с числата от всички тестове освен един, защото беше ясно, че производителността там винаги е била по-лоша с коефициент поне 10. Следващата диаграма показва отново изпълнението на функциите във всеки от четирите теста средно за 10 стартирания и винаги със студен кеш и чисти буфери.
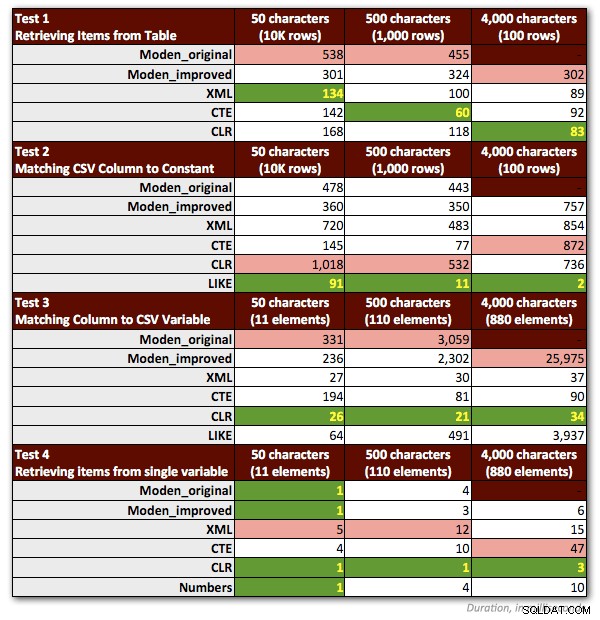
И така, ето моите леко преработени предпочитани методи за всеки тип задача:
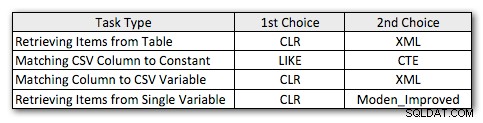
Ще забележите, че CLR остана моят избор, освен в единия случай, когато разделянето няма смисъл. И в случаите, когато CLR не е опция, методите XML и CTE обикновено са по-ефективни, освен в случай на разделяне на единична променлива, където функцията на Джеф може да бъде най-добрият вариант. Но като се има предвид, че може да се наложи да поддържам повече от 4000 знака, решението на таблицата Numbers просто може да се върне в списъка ми в специфични ситуации, в които нямам право да използвам CLR.
Обещавам, че следващата ми публикация, включваща списъци, изобщо няма да говори за разделяне чрез T-SQL или CLR и ще демонстрира как да опрости този проблем, независимо от типа данни.
Като настрана забелязах този коментар в една от версиите на функциите на Джеф, която беше публикувана в коментарите:Благодаря и на този, който е написал първата статия, която някога видях за „таблици с числа“, която се намира на следния URL адрес и на Адам Мачаник че ме доведе до него преди много години.https://web.archive.org/web/20150411042510/https://sqlserver2000.databases.aspfaq.com/why-should-i-consider-using-an -auxiliary-numbers-table.html
Тази статия е написана от мен през 2004 г. Така че който и да е добавил коментара към функцията, добре дошъл. :-)