Хората се чудят дали трябва да направят всичко възможно, за да предотвратят изключения, или просто да оставят системата да се справи с тях. Виждал съм няколко дискусии, в които хората обсъждат дали трябва да направят каквото могат, за да предотвратят изключение, защото обработката на грешки е „скъпа“. Няма съмнение, че обработката на грешки не е безплатна, но бих предвидил, че нарушението на ограничението е поне толкова ефективно, колкото първо проверката за потенциално нарушение. Това може да е различно за ключово нарушение от нарушение на статично ограничение, например, но в тази публикация ще се съсредоточа върху първото.
Основните подходи, които хората използват за справяне с изключенията, са:
- Просто оставете двигателя да се справи с това и изпратете всяко изключение обратно към обаждащия се.
- Използвайте
BEGIN TRANSACTIONиROLLBACKако@@ERROR <> 0. - Използвайте
TRY/CATCHсROLLBACKвCATCHблок (SQL Server 2005+).
И мнозина възприемат подхода, че първо трябва да проверят дали ще доведат до нарушението, тъй като изглежда по-чисто да се справите с дубликата сами, отколкото да принудите двигателя да го направи. Моята теория е, че трябва да вярвате, но да проверявате; например, помислете за този подход (предимно псевдокод):
АКО НЕ СЪЩЕСТВУВА ([ред, който би довел до нарушение])ЗАПОЧНЕТЕ ЗАПОЧНЕТЕ ОПИТ ЗАПОЧНЕТЕ ТРАНЗАКЦИЯ; INSERT ()... COMMIT TRANSACTION; END TRY BEGIN CATCH -- добре, така или иначе получихме нарушение; -- Предполагам, че нов ред е бил вмъкнат или -- актуализиран, тъй като извършихме проверката на ТРАНЗАКЦИЯ ЗА ОТМЕНЯНЕ; END CATCHEND
Знаем, че IF NOT EXISTS проверката не гарантира, че някой друг няма да е вмъкнал реда до момента, в който стигнем до INSERT (освен ако не поставим агресивни ключалки на масата и/или използваме SERIALIZABLE ), но външната проверка ни пречи да се опитаме да извършим грешка и след това да се наложи да се върнем назад. Стоим извън целия TRY/CATCH структура, ако вече знаем, че INSERT ще се провали и би било логично да се предположи, че – поне в някои случаи – това ще бъде по-ефективно от въвеждането на TRY/CATCH структура безусловно. Това няма никакъв смисъл в един INSERT сценарий, но си представете случай, в който в този TRY се случва повече блокиране (и още потенциални нарушения, за които бихте могли да проверите предварително, което означава още повече работа, която иначе може да се наложи да извършите и след това да върнете обратно, ако възникне по-късно нарушение).
Сега би било интересно да видим какво ще се случи, ако използвате ниво на изолация, което не е по подразбиране (нещо, което ще разгледам в бъдеща публикация), особено с едновременност. За тази публикация обаче исках да започна бавно и да тествам тези аспекти с един потребител. Създадох таблица, наречена dbo.[Objects] , много опростена таблица:
СЪЗДАЙТЕ ТАБЛИЦА dbo.[Objects]( ObjectID INT IDENTITY(1,1), Name NVARCHAR(255) PRIMARY KEY);GO
Исках да запълня тази таблица със 100 000 реда примерни данни. За да направя стойностите в колоната с име уникални (тъй като PK е ограничението, което исках да нарушя), създадох помощна функция, която приема определен брой редове и минимален низ. Минималният низ ще се използва, за да се гарантира, че или (а) наборът е започнал над максималната стойност в таблицата с обекти, или (б) наборът е започнал от минималната стойност в таблицата с обекти. (Ще ги уточня ръчно по време на тестовете, проверени просто чрез проверка на данните, въпреки че вероятно бих могъл да вградя тази проверка във функцията.)
СЪЗДАВАНЕ НА ФУНКЦИЯ dbo.GenerateRows(@n INT, @minString NVARCHAR(32)) ВРЪЩА ТАБЛИЦИ ВЪЗРАЩАНЕ ( ИЗБЕРЕТЕ TOP (@n) име =име + '_' + RTRIM(rn) ОТ ( ИЗБЕРЕТЕ a.name, rn =ROW_NUMBER() НАД (РАЗДЕЛЯНЕ ПО a.name ORDER BY a.name) ОТ sys.all_objects КАТО КРЪСТНО ПРИСЪЕДИНЕНИЕ към sys.all_objects КАТО b КЪДЕ a.name>=@minString И b.name>=@minString ) AS x );GO
Това се отнася за CROSS JOIN на sys.all_objects върху себе си, добавяйки уникален row_number към всяко име, така че първите 10 резултата ще изглеждат така:
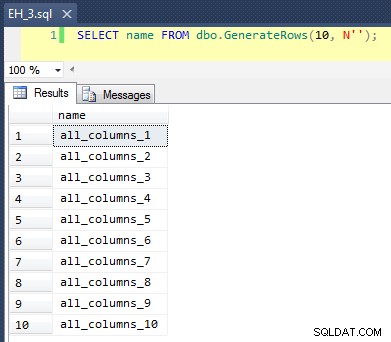
Попълването на таблицата със 100 000 реда беше просто:
INSERT dbo.[Objects](name) SELECT name FROM dbo.GenerateRows(100000, N'') ORDER BY name;GO
Сега, тъй като ще вмъкнем нови уникални стойности в таблицата, създадох процедура за извършване на известно почистване в началото и в края на всеки тест – освен да изтрием всички нови редове, които сме добавили, тя също ще изчисти кеша и буферите. Разбира се, не е нещо, което искате да кодирате в процедура на вашата производствена система, но е добре за локално тестване на производителността.
СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.EH_Cleanup-- P.S. "EH" означава обработка на грешки, а не "Eh?" ASBEGIN SET NOCOUNT ON; DELETE dbo.[Objects] WHERE ObjectID> 100000; DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS;ENDGO
Също така създадох регистрационна таблица, за да следя началното и крайното време за всеки тест:
СЪЗДАВАНЕ НА ТАБЛИЦА dbo.RunTimeLog( LogID INT IDENTITY(1,1), Spid INT, InsertType VARCHAR(255), ErrorHandlingMethod VARCHAR(255), StartDate DATETIME2(7) НЕ НУЛА ПО ПОДРАЗБИРАНЕ SYSUTCDATETIME(), EndDate );GO
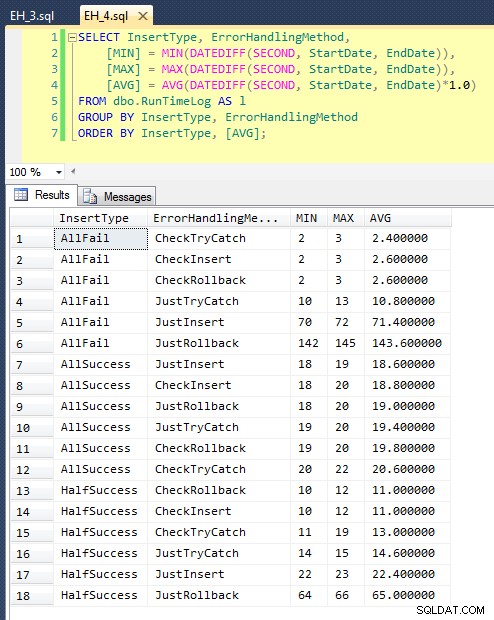
И накрая, съхранената процедура за тестване обработва различни неща. Имаме три различни метода за обработка на грешки, както е описано в куршумите по-горе:„JustInsert“, „Rollback“ и „TryCatch“; имаме също три различни типа вмъкване:(1) всички вмъквания са успешни (всички редове са уникални), (2) всички вмъквания са неуспешни (всички редове са дублирани) и (3) половината вмъквания са успешни (половината редове са уникални, а половината редовете са дублирани). В съчетание с това има два различни подхода:проверете за нарушение, преди да опитате вложката, или просто продължете напред и оставете двигателя да определи дали е валиден. Мислех, че това ще даде добро сравнение на различните техники за обработка на грешки, комбинирани с различни вероятности от сблъсъци, за да се види дали висок или нисък процент на сблъсък ще повлияе значително на резултатите.
За тези тестове избрах 40 000 реда като общ брой опити за вмъкване и в процедурата изпълнявам обединение на 20 000 уникални или неуникални реда с 20 000 други уникални или неуникални реда. Можете да видите, че кодирах твърдо изрязващите низове в процедурата; моля, имайте предвид, че във вашата система тези прекъсвания почти сигурно ще се появят на различно място.
СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.EH_Insert @ErrorHandlingMethod VARCHAR(255), @InsertType VARCHAR(255), @RowSplit INT =20000ASBEGIN SET NOCOUNT ON; -- почистете всички нови редове и пуснете буферите/изчистете кеша на процеса EXEC dbo.EH_Cleanup; ДЕКЛАРИРАНЕ @CutoffString1 NVARCHAR(255), @CutoffString2 NVARCHAR(255), @Име NVARCHAR(255), @Продължи BIT =1, @LogID INT; -- генериране на нов запис в дневника INSERT dbo.RunTimeLog(Spid, InsertType, ErrorHandlingMethod) SELECT @@SPID, @InsertType, @ErrorHandlingMethod; SET @LogID =SCOPE_IDENTITY(); -- ако искаме всичко да успее, се нуждаем от набор от данни -- който има 40 000 реда, които всички са уникални. И така, обединете две -- набори, всеки от които е на>=20 000 реда един от друг и не - вече съществува в основната таблица:IF @InsertType ='AllSuccess' SELECT @CutoffString1 =N'database_audit_specifications_1000', @Cutoffpermties_1_r38 '; -- ако искаме всички те да се провалят, тогава е лесно, можем просто -- да обединим два набора, които започват на същото място като първоначалното -- население:IF @InsertType ='AllFail' SELECT @CutoffString1 =N'', @CutoffString2 =N''; -- и ако искаме половината да успее, имаме нужда от 20 000 уникални -- стойности и 20 000 дубликата:IF @InsertType ='HalfSuccess' SELECT @CutoffString1 =N'database_audit_specifications_1000', @CutoffString2 =N''; ДЕКЛАРИРАНЕ c КУРСОР ЛОКАЛЕН СТАТИЧЕН FORWARD_ONLY_READ_ONLY FOR SELECT име FROM dbo.GenerateRows(@RowSplit, @CutoffString1) UNION ALL SELECT име FROM dbo.GenerateRows(@RowSplit, @CutoffString2); ОТВОРЕНО c; ИЗВЛЕКНЕ СЛЕДВАЩО ОТ c В @Име; WHILE @@FETCH_STATUS =0 BEGIN SET @Continue =1; -- нека въведем основния кодов блок само ако -- трябва да проверим и проверката се връща празна -- (с други думи, изобщо не опитвайте, ако имаме -- дубликат, а проверете само за дубликат - - в определени случаи:АКО @ErrorHandlingMethod КАТО 'Check%' ЗАПОЧНЕ АКО СЪЩЕСТВУВА (ИЗБЕРЕТЕ 1 ОТ dbo.[Objects] WHERE Име =@Name) SET @Continue =0; КРАЙ, АКО @Continue =1 ЗАПОЧНЕ -- просто оставете двигателя да се използва. catch IF @ErrorHandlingMethod КАТО '%Insert' BEGIN INSERT dbo.[Objects](name) SELECT @name; END -- започнете транзакция, но оставете двигателя да хване IF @ErrorHandlingMethod КАТО '%Rollback' ЗАПОЧНЕТЕ ЗАПОЧВАНЕ НА ТРАНЗАКЦИЯ; INSERT dbo. [Обекти](име) ИЗБЕРЕТЕ @name; IF @@ERROR <> 0 ЗАПОЧНЕТЕ ТРАНЗАКЦИЯ ЗА ОТМЕНЯНЕ; END ELSE BEGIN COMMIT TRANSACTION; END END -- използвайте try / catch IF @ErrorHandlingMethod КАТО '%TryCatch' ЗАПОЧВАТЕ ЗАПОЧВАТЕ ОПИТ ЗАПОЧВАТЕ ЗАПОЧВАНЕ НА TRANSACTION; INSERT dbo.[Обекти](име) ИЗБЕРЕТЕ @Име; ИЗВЪРШАТЕ ТРАНЗАКЦИЯ; КРАЙ ОПИТАЙТЕ BEGIN CATCH ТРАНЗАКЦИЯ ОТМЕНА; END CATCH END END FETCH NEXT FROM c INTO @Name; КРАЙ ЗАТВОРИ c; ОТМЕНИ c; -- актуализиране на записа в дневника UPDATE dbo.RunTimeLog SET EndDate =SYSUTCDATETIME() WHERE LogID =@LogID; -- почистете всички нови редове и пуснете буферите/изчистете кеша на процеса EXEC dbo.EH_Cleanup;ENDGO
Сега можем да извикаме тази процедура с различни аргументи, за да получим различното поведение, което търсим, опитвайки се да вмъкнем 40 000 стойности (и знаейки, разбира се, колко трябва да успеят или неуспешни във всеки случай). За всеки „метод за обработка на грешки“ (просто опитайте вмъкването, използвайте begin tran/rollback или try/catch) и всеки тип вмъкване (всички успешни, наполовина успешни и нито един успех), съчетано с това дали да проверите за нарушението или не първо, това ни дава 18 комбинации:
EXEC dbo.EH_Insert 'JustInsert', 'AllSuccess', 20000;EXEC dbo.EH_Insert 'JustInsert', 'HalfSuccess', 20000;EXEC dbo.EH_Insert 'JustInsert',00A'; EXEC dbo.EH_Insert 'JustTryCatch', 'AllSuccess', 20000;EXEC dbo.EH_Insert 'JustTryCatch', 'HalfSuccess', 20000;EXEC dbo.EH_Insert, 'All'0'; EXEC dbo.EH_Insert 'JustRollback', 'AllSuccess', 20000;EXEC dbo.EH_Insert 'JustRollback', 'HalfSuccess', 20000;EXEC dbo.EH_Insert 'Just'Allback','02F; EXEC dbo.EH_Insert 'CheckInsert', 'AllSuccess', 20000;EXEC dbo.EH_Insert 'CheckInsert', 'HalfSuccess', 20000;EXEC dbo.EH_Insert ',CheckInsert',0 'All'; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllSuccess', 20000;EXEC dbo.EH_Insert 'CheckTryCatch', 'HalfSuccess', 20000;EXEC dbo.EH_Insert 'CheckTryCatch',All0'CheckTry'; EXEC dbo.EH_Insert 'CheckRollback', 'AllSuccess', 20000;EXEC dbo.EH_Insert 'CheckRollback', 'HalfSuccess', 20000;EXEC dbo.EH_Insert 'Check'Allback',0'Allback',0'Allback';След като изпълнихме това (отнема около 8 минути в моята система), имаме някои резултати в нашия дневник. Прокарах цялата партида пет пъти, за да се уверя, че имаме прилични средни стойности и да изгладя всички аномалии. Ето резултатите:
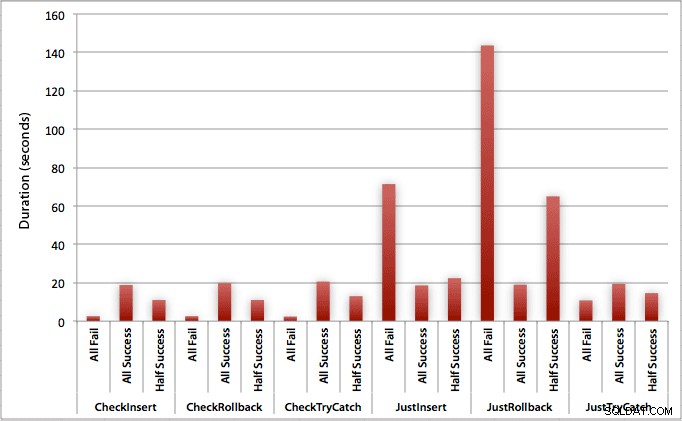
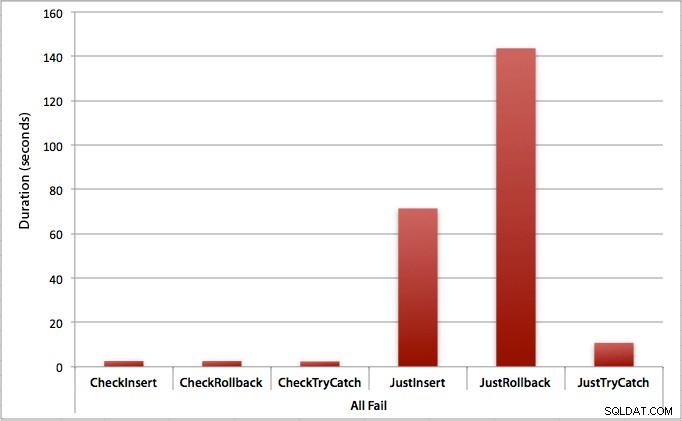
Графиката, която изобразява всички продължителности наведнъж, показва няколко сериозни отклонения:
Можете да видите, че в случаите, когато очакваме висок процент на неуспех (в този тест, 100%), започването на транзакция и връщането назад е най-малко привлекателният подход (3,59 милисекунди на опит), докато просто оставяте двигателя да се повдигне грешка е наполовина по-лоша (1,785 милисекунди на опит). Следващият най-лош резултат беше случаят, когато започваме транзакция, след което я отменяме, в сценарий, при който очакваме около половината от опитите да се провалят (средно 1,625 милисекунди на опит). 9-те случая от лявата страна на графиката, където първо проверяваме за нарушение, не надвишаваха 0,515 милисекунди на опит.
Като се има предвид това, отделните графики за всеки сценарий (висок % на успех, висок % на неуспех и 50-50) наистина показват въздействието на всеки метод.
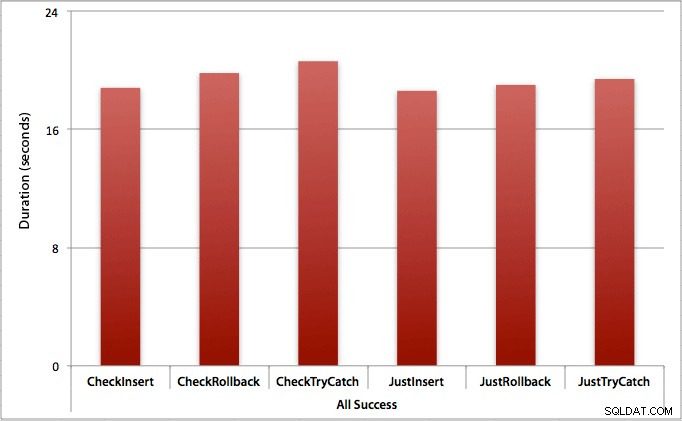
Където всички вмъквания са успешни
В този случай виждаме, че разходите за проверка за първо нарушение са незначителни, със средна разлика от 0,7 секунди в цялата партида (или 125 микросекунди на опит за вмъкване):
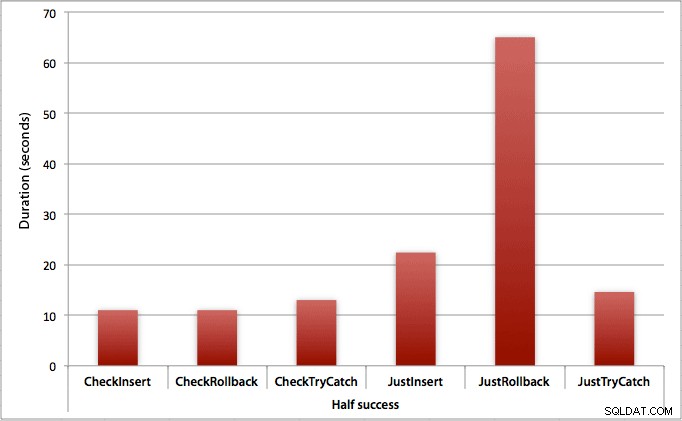
Когато само половината вмъквания са успешни
Когато половината от вмъкванията се провалят, виждаме голям скок в продължителността на методите за вмъкване / връщане назад. Сценарият, при който стартираме транзакция и я връщаме назад, е около 6 пъти по-бавен в цялата партида в сравнение с проверката първа (1,625 милисекунди на опит срещу 0,275 милисекунди на опит). Дори методът TRY/CATCH е с 11% по-бърз, когато първо проверим:
Когато всички вложки се провалят
Както може да очаквате, това показва най-изразеното въздействие на обработката на грешки и най-очевидните ползи от проверката първо. Методът за връщане назад е почти 70 пъти по-бавен в този случай, когато не проверяваме в сравнение с този, когато го правим (3,59 милисекунди на опит срещу 0,065 милисекунди на опит):
Какво ни казва това? Ако смятаме, че ще имаме висок процент на откази или нямаме представа какъв ще бъде потенциалният ни процент на отказ, тогава първо проверката, за да избегнем нарушения в двигателя, ще си струва изключително много. Дори в случай, когато имаме успешно вмъкване всеки път, цената на първата проверка е незначителна и лесно се оправдава от потенциалните разходи за обработка на грешки по-късно (освен ако очакваният ви процент на неуспех е точно 0%).
Така че засега мисля, че ще се придържам към теорията си, че в прости случаи има смисъл да проверявате за потенциално нарушение, преди да кажете на SQL Server да продължи и да вмъкне все пак. В бъдеща публикация ще разгледам въздействието върху производителността на различни нива на изолация, едновременност и може би дори няколко други техники за обработка на грешки.
[Като настрана, написах съкратена версия на тази публикация като съвет за mssqltips.com още през февруари.]