Подреждането на данни за дата и час включва организиране на данни в групи, представляващи фиксирани интервали от време за аналитични цели. Често входните данни са данни от времеви серии, съхранявани в таблица, където редовете представляват измервания, направени на редовни интервали от време. Например, измерванията могат да бъдат показания на температура и влажност, взети на всеки 5 минути, а вие искате да групирате данните с помощта на почасови кофи и да изчислите агрегати като средно за час. Въпреки че данните от времевите серии са често срещан източник за анализ, базиран на кофа, концепцията е също толкова уместна за всички данни, които включват атрибути за дата и час и свързани мерки. Например, може да искате да организирате данни за продажбите в сегменти на фискалната година и да изчислите агрегати като общата стойност на продажбите за фискална година. В тази статия разглеждам два метода за групиране на данни за дата и час. Единият използва функция, наречена DATE_BUCKET, която към момента на писане е достъпна само в Azure SQL Edge. Друг е използването на персонализирано изчисление, което емулира функцията DATE_BUCKET, която можете да използвате във всяка версия, издание и вкус на SQL Server и Azure SQL база данни.
В моите примери ще използвам примерната база данни TSQLV5. Можете да намерите скрипта, който създава и попълва TSQLV5 тук, и неговата ER диаграма тук.
DATE_BUCKET
Както споменахме, функцията DATE_BUCKET в момента е достъпна само в Azure SQL Edge. SQL Server Management Studio вече има поддръжка на IntelliSense, както е показано на Фигура 1:
 Фигура 1:Поддръжка на Intellisence за DATE_BUCKET в SSMS
Фигура 1:Поддръжка на Intellisence за DATE_BUCKET в SSMS
Синтаксисът на функцията е както следва:
DATE_BUCKET ( <част от дата>, <ширина на кофата>, <клеймо за време>[, <начинание>] )Входният произход представлява опорна точка върху стрелката на времето. Може да бъде от всеки от поддържаните типове данни за дата и час. Ако не е посочено, по подразбиране е 1900, 1 януари, полунощ. След това можете да си представите времевата линия като разделена на отделни интервали, започващи от началната точка, където дължината на всеки интервал се основава на входните широчина на кофата и част за дата . Първото е количеството, а второто е единицата. Например, за да организирате времевата линия в 2-месечни единици, трябва да посочите 2 като ширината на кофата въвеждане и месец като част за дата въвеждане.
Входното клеймо за време е произволен момент от време, който трябва да бъде свързан със съдържащата се в него кофа. Неговият тип данни трябва да съответства на типа данни на входния произход . Входното клеймо за време е стойността на датата и часа, свързани с мерките, които заснемате.
Тогава изходът на функцията е началната точка на съдържащата кофа. Типът данни на изхода е този на входния timestamp .
Ако вече не беше очевидно, обикновено бихте използвали функцията DATE_BUCKET като елемент за групиране на набор в клаузата GROUP BY на заявката и естествено щеше да я върнете в списъка SELECT, заедно с агрегираните мерки.
Все още сте малко объркани относно функцията, нейните входове и изхода? Може би конкретен пример с визуално изображение на логиката на функцията би помогнал. Ще започна с пример, който използва входни променливи и по-късно в статията ще демонстрирам по-типичния начин, по който бихте го използвали като част от заявка към входна таблица.
Помислете за следния пример:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00'; SELECT DATE_BUCKET(month, @bucketwidth, @timestamp, @origin);
Можете да намерите визуално изображение на логиката на функцията на фигура 2.
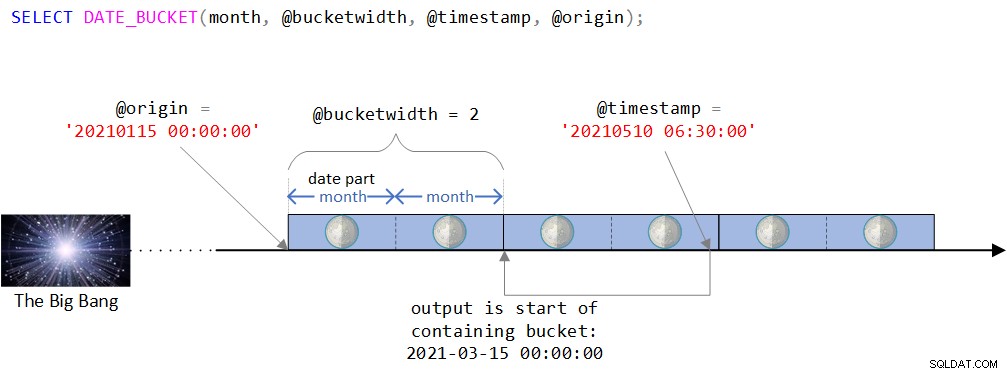 Фигура 2:Визуално изобразяване на логиката на функцията DATE_BUCKET
Фигура 2:Визуално изобразяване на логиката на функцията DATE_BUCKET
Както можете да видите на фигура 2, началната точка е стойността DATETIME2 15 януари 2021 г., полунощ. Ако тази начална точка изглежда малко странна, ще сте прави, като интуитивно усетите, че обикновено ще използвате по-естествена, като началото на някоя година или началото на някой ден. Всъщност често бихте били доволни от стандартното, което, както си спомняте, е 1 януари 1900 г. в полунощ. Умишлено исках да използвам по-малко тривиална начална точка, за да мога да обсъждам определени сложности, които може да не са уместни, когато използвам по-естествена. Повече за това скоро.
След това времевата линия се разделя на отделни 2-месечни интервали, започващи от началната точка. Въведената дата за време е стойността DATETIME2 на 10 май 2021 г., 6:30 ч.
Обърнете внимание, че входната дата за време е част от групата, която започва на 15 март 2021 г., полунощ. Всъщност функцията връща тази стойност като стойност, въведена от DATETIME2:
--------------------------- 2021-03-15 00:00:00.0000000
Емулиране на DATE_BUCKET
Освен ако не използвате Azure SQL Edge, ако искате да събирате данни за дата и час, за момента ще трябва да създадете свое собствено персонализирано решение, за да емулирате това, което прави функцията DATE_BUCKET. Правенето на това не е прекалено сложно, но и не е твърде просто. Работата с данни за дата и час често включва сложна логика и клопки, за които трябва да внимавате.
Ще изградя изчислението на стъпки и ще използвам същите входни данни, които използвах с примера DATE_BUCKET, който показах по-рано:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00';
Уверете се, че сте включили тази част преди всяка от примерните кодове, които ще покажа, ако наистина искате да стартирате кода.
В стъпка 1 използвате функцията DATEDIFF, за да изчислите разликата в част от дата единици между произход и клеймо за време . Ще наричам тази разлика diff1 . Това става със следния код:
SELECT DATEDIFF(month, @origin, @timestamp) AS diff1;
С нашите примерни входове този израз връща 4.
Трудната част тук е, че трябва да изчислите колко цели единици от част за дата съществуват между произход и клеймо за време . С нашите примерни входни данни има цели 3 месеца между двете, а не 4. Причината, поради която функцията DATEDIFF отчита 4 е, че когато изчислява разликата, тя разглежда само исканата част от входните данни и по-високите части, но не и по-ниските части . Така че, когато поискате разликата в месеците, функцията се грижи само за частите от годината и месеца на входовете, а не за частите под месеца (ден, час, минута, секунда и т.н.). Всъщност има 4 месеца между януари 2021 г. и май 2021 г., но само цели 3 месеца между пълните данни.
Целта на стъпка 2 е да се изчисли колко цели единици от част за дата съществуват между произход и клеймо за време . Ще наричам тази разлика diff2 . За да постигнете това, можете да добавите diff1 единици от част за дата до произход . Ако резултатът е по-голям от timestamp , изваждате 1 от diff1 за изчисляване на diff2 , в противен случай извадете 0 и следователно използвайте diff1 като diff2 . Това може да стане с помощта на CASE израз, както следва:
SELECT
DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END AS diff2; Този израз връща 3, което е броят на цели месеци между двата входа.
Спомнете си, че по-рано споменах, че в моя пример умишлено използвах начална точка, която не е естествена, като кръгло начало на период, за да мога да обсъждам определени сложности, които тогава може да са от значение. Например, ако използвате месец като част от датата и точното начало на някой месец (1 от някой месец в полунощ) като начало, можете спокойно да пропуснете стъпка 2 и да използвате diff1 като diff2 . Това е защото произход + разл.1 никога не може да бъде> timestamp в такъв случай. Въпреки това, моята цел е да осигуря логически еквивалентна алтернатива на функцията DATE_BUCKET, която да работи правилно за всяка изходна точка, обща или не. Така че ще включа логиката за Стъпка 2 в моите примери, но просто не забравяйте, че когато идентифицирате случаи, в които тази стъпка не е уместна, можете безопасно да премахнете частта, където изваждате изхода на израза CASE.
В стъпка 3 идентифицирате колко единици от част за дата има в цели кофи, които съществуват между произход и клеймо за време . Ще наричам тази стойност diff3 . Това може да стане със следната формула:
diff3 = diff2 / <bucket width> * <bucket width>
Номерът тук е, че когато използвате оператора за деление / в T-SQL с целочислени операнди, получавате целочислено деление. Например, 3/2 в T-SQL е 1, а не 1.5. Изразът diff2 / <ширина на кофата> ви дава броя на цели сегменти, които съществуват между произход и клеймо за време (1 в нашия случай). Умножаване на резултата по широчина на кофата след това ви дава броя на единиците на част за дата които съществуват в рамките на тези цели кофи (2 в нашия случай). Тази формула се превежда в следния израз в T-SQL:
SELECT
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth AS diff3; Този израз връща 2, което е броят на месеците в целите двумесечни пакети, които съществуват между двата входа.
В стъпка 4, която е последната стъпка, добавяте diff3 единици от част за дата до произход за да се изчисли началото на съдържащата кофа. Ето кода за постигане на това:
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Този код генерира следния изход:
--------------------------- 2021-03-15 00:00:00.0000000
Както си спомняте, това е същият изход, произведен от функцията DATE_BUCKET за същите входове.
Предлагам ви да опитате този израз с различни входове и части. Тук ще покажа няколко примера, но не се колебайте да опитате своя собствен.
Ето пример за произход е малко по-напред от timestamp през месеца:
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:01';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Този код генерира следния изход:
--------------------------- 2021-03-10 06:30:01.0000000
Забележете, че началото на контейнера е през март.
Ето пример за произход е в същата точка в рамките на месеца като timestamp :
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:00';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Този код генерира следния изход:
--------------------------- 2021-05-10 06:30:00.0000000
Обърнете внимание, че този път началото на контейнера е през май.
Ето пример с 4-седмични групи:
DECLARE
@timestamp AS DATETIME2 = '20210303 21:22:11',
@bucketwidth AS INT = 4,
@origin AS DATETIME2 = '20210115';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
week,
( DATEDIFF(week, @origin, @timestamp)
- CASE
WHEN DATEADD(
week,
DATEDIFF(week, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Забележете, че кодът използва седмицата част този път.
Този код генерира следния изход:
--------------------------- 2021-02-12 00:00:00.0000000
Ето пример с 15-минутни кофи:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF(minute, @origin, @timestamp)
- CASE
WHEN DATEADD(
minute,
DATEDIFF(minute, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Този код генерира следния изход:
--------------------------- 2021-02-03 21:15:00.0000000
Забележете, че частта е минута . В този пример искате да използвате 15-минутни сегменти, започващи от дъното на часа, така че начална точка, която е дъното на всеки час, ще работи. Всъщност, начална точка, която има минутна единица от 00, 15, 30 или 45 с нули в долните части, с всяка дата и час, би работила. Така че по подразбиране, която функцията DATE_BUCKET използва за входния произход бих работил. Разбира се, когато използвате персонализирания израз, трябва да сте изрични относно началната точка. Така че, за да симпатизирате на функцията DATE_BUCKET, можете да използвате основната дата в полунощ, както правя в горния пример.
Между другото, виждате ли защо това би било добър пример, когато е напълно безопасно да пропуснете стъпка 2 в решението? Ако наистина сте избрали да пропуснете стъпка 2, ще получите следния код:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF( minute, @origin, @timestamp ) ) / @bucketwidth * @bucketwidth,
@origin
); Ясно е, че кодът става значително по-опростен, когато стъпка 2 не е необходима.
Групиране и агрегиране на данни по сегменти за дата и час
Има случаи, в които трябва да разпределите данни за дата и час, които не изискват сложни функции или тромави изрази. Например, да предположим, че искате да направите заявка за изгледа Sales.OrderValues в базата данни TSQLV5, да групирате данните годишно и да изчислите общия брой поръчки и стойности за година. Ясно е, че е достатъчно да използвате функцията YEAR(orderdate) като елемент за групиране, както следва:
USE TSQLV5; SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues GROUP BY YEAR(orderdate) ORDER BY orderyear;
Този код генерира следния изход:
orderyear numorders totalvalue ----------- ----------- ----------- 2017 152 208083.99 2018 408 617085.30 2019 270 440623.93
Но какво ще стане, ако искате да групирате данните по фискалната година на вашата организация? Някои организации използват фискална година за счетоводни, бюджетни и финансови цели, които не са съобразени с календарната година. Да кажем, например, че фискалната година на вашата организация работи по фискален календар от октомври до септември и се обозначава с календарната година, в която приключва фискалната година. Така че събитие, което се е състояло на 3 октомври 2018 г., принадлежи към фискалната година, започнала на 1 октомври 2018 г., приключила на 30 септември 2019 г. и е обозначена с годината 2019.
Това е доста лесно за постигане с функцията DATE_BUCKET, както следва:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year SELECT YEAR(startofbucket) + 1 AS fiscalyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
И ето кода, използващ персонализирания логически еквивалент на функцията DATE_BUCKET:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year
SELECT
YEAR(startofbucket) + 1 AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Този код генерира следния изход:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2017 70 79728.58 2018 370 563759.24 2019 390 622305.40
Тук използвах променливи за ширината на кофата и началната точка, за да направя кода по-обобщен, но можете да ги замените с константи, ако винаги използвате едни и същи, и след това да опростите изчислението според случая.
Като лека вариация на горното, да предположим, че вашата фискална година тече от 15 юли на една календарна година до 14 юли на следващата календарна година и се обозначава с календарната година, към която принадлежи началото на фискалната година. И така, събитие, което се е състояло на 18 юли 2018 г., принадлежи към фискалната 2018 г. Събитие, което се е състояло на 14 юли 2018 г., принадлежи към фискалната година 2017. Използвайки функцията DATE_BUCKET, ще постигнете това по следния начин:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19000715'; -- July 15 marks start of fiscal year SELECT YEAR(startofbucket) AS fiscalyear, -- no need to add 1 here COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Можете да видите промените в сравнение с предишния пример в коментарите.
И ето кода, използващ персонализирания логически еквивалент на функцията DATE_BUCKET:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19000715';
SELECT
YEAR(startofbucket) AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Този код генерира следния изход:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2016 8 12599.88 2017 343 495118.14 2018 479 758075.20
Очевидно има алтернативни методи, които можете да използвате в конкретни случаи. Вземете примера преди последната, където фискалната година тече от октомври до септември и се обозначава с календарната година, в която приключва фискалната година. В такъв случай можете да използвате следния, много по-опростен израз:
YEAR(orderdate) + CASE WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1 ELSE 0 END
И тогава вашата заявка ще изглежда така:
SELECT
fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
YEAR(orderdate)
+ CASE
WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1
ELSE 0
END ) ) AS A(fiscalyear)
GROUP BY fiscalyear
ORDER BY fiscalyear; Въпреки това, ако искате обобщено решение, което да работи в много повече случаи и което можете да параметризирате, естествено бихте искали да използвате по-общата форма. Ако имате достъп до функцията DATE_BUCKET, това е чудесно. Ако не го направите, можете да използвате персонализирания логически еквивалент.
Заключение
Функцията DATE_BUCKET е доста удобна функция, която ви позволява да разделяте данни за дата и час. Полезно е за работа с данни от времеви серии, но също и за групиране на всякакви данни, които включват атрибути за дата и час. В тази статия обясних как работи функцията DATE_BUCKET и предоставих персонализиран логически еквивалент, в случай че платформата, която използвате, не я поддържа.