Някои интересни дискусии винаги се развиват около темата за разделянето на низове. В две предишни публикации в блога, „Разделяне на низове по правилния начин – или следващият най-добър начин“ и „Разделяне на низове:последващо действие“, надявам се, че съм демонстрирал, че преследването на „най-добре представящата се“ функция за разделяне на T-SQL е безплодна . Когато разделянето е действително необходимо, CLR винаги печели и следващата най-добра опция може да варира в зависимост от действителната задача. Но в тези публикации намекнах, че разделянето от страна на базата данни може да не е необходимо на първо място.
SQL Server 2008 въведе параметри с таблично стойности, начин за предаване на "таблица" от приложение към съхранена процедура, без да се налага да се изгражда и анализира низ, да се сериализира в XML или да се работи с която и да е от тази методология за разделяне. Затова реших да проверя как този метод се сравнява с победителя от предишните ни тестове – тъй като може да е жизнеспособна опция, независимо дали можете да използвате CLR или не. (За най-добрата библия за TVP, моля, вижте изчерпателната статия на колегата SQL Server MVP Ерланд Сомарског.)
Тестовете
За този тест ще се преструвам, че имаме работа с набор от низове на версията. Представете си C# приложение, което преминава в набор от тези низове (да речем, които са били събрани от набор от потребители) и трябва да съпоставим версиите с таблица (да речем, която показва версиите на услугата, които са приложими към конкретен набор от версии). Очевидно едно истинско приложение би имало повече колони от това, но само за да създаде малко обем и все пак да поддържа таблицата тънка (аз също използвам NVARCHAR навсякъде, защото това е, което отнема функцията за разделяне на CLR и искам да премахна всяка неяснота поради имплицитно преобразуване) :
CREATE TABLE dbo.VersionStrings(left_post NVARCHAR(5), right_post NVARCHAR(5)); CREATE CLUSTERED INDEX x ON dbo.VersionStrings(left_post, right_post); ;WITH x AS ( SELECT lp = CONVERT(DECIMAL(4,3), RIGHT(RTRIM(s1.[object_id]), 3)/1000.0) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ) INSERT dbo.VersionStrings ( left_post, right_post ) SELECT lp - CASE WHEN lp >= 0.9 THEN 0.1 ELSE 0 END, lp + (0.1 * CASE WHEN lp >= 0.9 THEN -1 ELSE 1 END) FROM x;
Сега, когато данните са на мястото си, следващото нещо, което трябва да направим, е да създадем дефиниран от потребителя тип таблица, която може да съдържа набор от низове. Първоначалният тип таблица, която да държи този низ, е доста прост:
CREATE TYPE dbo.VersionStringsTVP AS TABLE (VersionString NVARCHAR(5));
Тогава имаме нужда от няколко съхранени процедури, за да приемем списъците от C#. За простота отново ще направим преброяване, за да сме сигурни, че ще извършим пълно сканиране, и ще игнорираме броя в приложението:
CREATE PROCEDURE dbo.SplitTest_UsingCLR
@list NVARCHAR(MAX)
AS
BEGIN
SET NOCOUNT ON;
SELECT c = COUNT(*)
FROM dbo.VersionStrings AS v
INNER JOIN dbo.SplitStrings_CLR(@list, N',') AS s
ON s.Item BETWEEN v.left_post AND v.right_post;
END
GO
CREATE PROCEDURE dbo.SplitTest_UsingTVP
@list dbo.VersionStringsTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
SELECT c = COUNT(*)
FROM dbo.VersionStrings AS v
INNER JOIN @list AS l
ON l.VersionString BETWEEN v.left_post AND v.right_post;
END
GO Обърнете внимание, че TVP, прехвърлен в съхранена процедура, трябва да бъде маркиран като ЧЕТЕНЕ – в момента няма начин да се извърши DML върху данните, както бихте направили за променлива на таблица или временна таблица. Въпреки това, Ерланд изпрати много популярно искане Microsoft да направи тези параметри по-гъвкави (и много по-задълбочено прозрение зад аргумента му тук).
Красотата тук е, че SQL Server вече изобщо не трябва да се занимава с разделянето на низ – нито в T-SQL, нито с предаването му на CLR – тъй като той вече е в зададена структура, където е превъзходен.
След това C# конзолно приложение, което прави следното:
- Приема число като аргумент, за да посочи колко низови елемента трябва да бъдат дефинирани
- Създава CSV низ от тези елементи, използвайки StringBuilder, за преминаване към съхранената процедура на CLR
- Създава DataTable със същите елементи за преминаване към съхранената процедура на TVP
- Също тества допълнителните разходи за преобразуване на CSV низ в DataTable и обратно, преди да извика съответните съхранени процедури
Кодът за приложението C# се намира в края на статията. Мога да пиша C#, но в никакъв случай не съм гуру; Сигурен съм, че има неефективност, която можете да забележите там, което може да накара кода да работи малко по-добре. Но всички подобни промени трябва да повлияят на целия набор от тестове по подобен начин.
Пуснах приложението 10 пъти, използвайки 100, 1000, 2500 и 5000 елемента. Резултатите бяха както следва (това показва средна продължителност в секунди за 10-те теста):
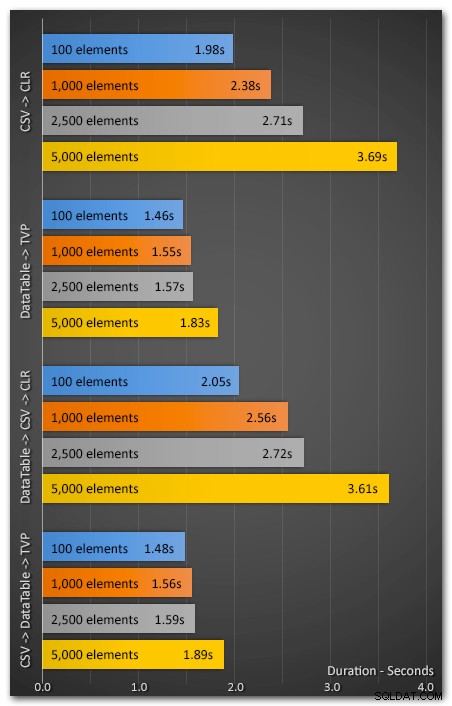
Изпълнението настрана...
В допълнение към ясната разлика в производителността, TVP имат и друго предимство – типовете таблици са много по-лесни за внедряване от CLR асемблите, особено в среди, където CLR е забранен по други причини. Надявам се, че бариерите пред CLR постепенно изчезват и новите инструменти правят внедряването и поддръжката по-малко болезнени, но се съмнявам, че лекотата на първоначалното внедряване за CLR някога ще бъде по-лесна от естествените подходи.
От друга страна, освен ограничението само за четене, типовете таблици са като типове псевдоними, тъй като са трудни за модифициране след факта. Ако искате да промените размера на колона или да добавите колона, няма команда ALTER TYPE и за да ОТПУСКАТЕ типа и да го създадете отново, първо трябва да премахнете препратките към типа от всички процедури, които го използват . Така например в горния случай, ако трябва да увеличим колоната VersionString до NVARCHAR(32), ще трябва да създадем фиктивен тип и да променим съхранената процедура (и всяка друга процедура, която я използва):
CREATE TYPE dbo.VersionStringsTVPCopy AS TABLE (VersionString NVARCHAR(32)); GO ALTER PROCEDURE dbo.SplitTest_UsingTVP @list dbo.VersionStringsTVPCopy READONLY AS ... GO DROP TYPE dbo.VersionStringsTVP; GO CREATE TYPE dbo.VersionStringsTVP AS TABLE (VersionString NVARCHAR(32)); GO ALTER PROCEDURE dbo.SplitTest_UsingTVP @list dbo.VersionStringsTVP READONLY AS ... GO DROP TYPE dbo.VersionStringsTVPCopy; GO
(Или алтернативно, махнете процедурата, махнете типа, създайте отново типа и създайте отново процедурата.)
Заключение
Методът TVP постоянно превъзхожда метода на разделяне на CLR и с по-голям процент с увеличаване на броя на елементите. Дори добавянето на допълнителни разходи за преобразуване на съществуващ CSV низ в DataTable доведе до много по-добра производителност от край до край. Така че се надявам, че ако още не съм ви убедил да изоставите техниките си за разделяне на T-SQL низове в полза на CLR, ви призовах да опитате параметрите с таблица. Трябва да е лесно за тестване, дори ако в момента не използвате DataTable (или някакъв еквивалент).
Кодът на C#, използван за тези тестове
Както казах, не съм гуру на C#, така че вероятно има много наивни неща, които правя тук, но методологията трябва да е доста ясна.
using System;
using System.IO;
using System.Data;
using System.Data.SqlClient;
using System.Text;
using System.Collections;
namespace SplitTester
{
class SplitTester
{
static void Main(string[] args)
{
DataTable dt_pure = new DataTable();
dt_pure.Columns.Add("Item", typeof(string));
StringBuilder sb_pure = new StringBuilder();
Random r = new Random();
for (int i = 1; i <= Int32.Parse(args[0]); i++)
{
String x = r.NextDouble().ToString().Substring(0,5);
sb_pure.Append(x).Append(",");
dt_pure.Rows.Add(x);
}
using
(
SqlConnection conn = new SqlConnection(@"Data Source=.;
Trusted_Connection=yes;Initial Catalog=Splitter")
)
{
conn.Open();
// four cases:
// (1) pass CSV string directly to CLR split procedure
// (2) pass DataTable directly to TVP procedure
// (3) serialize CSV string from DataTable and pass CSV to CLR procedure
// (4) populate DataTable from CSV string and pass DataTable to TCP procedure
// ********** (1) ********** //
write(Environment.NewLine + "Starting (1)");
SqlCommand c1 = new SqlCommand("dbo.SplitTest_UsingCLR", conn);
c1.CommandType = CommandType.StoredProcedure;
c1.Parameters.AddWithValue("@list", sb_pure.ToString());
c1.ExecuteNonQuery();
c1.Dispose();
write("Finished (1)");
// ********** (2) ********** //
write(Environment.NewLine + "Starting (2)");
SqlCommand c2 = new SqlCommand("dbo.SplitTest_UsingTVP", conn);
c2.CommandType = CommandType.StoredProcedure;
SqlParameter tvp1 = c2.Parameters.AddWithValue("@list", dt_pure);
tvp1.SqlDbType = SqlDbType.Structured;
c2.ExecuteNonQuery();
c2.Dispose();
write("Finished (2)");
// ********** (3) ********** //
write(Environment.NewLine + "Starting (3)");
StringBuilder sb_fake = new StringBuilder();
foreach (DataRow dr in dt_pure.Rows)
{
sb_fake.Append(dr.ItemArray[0].ToString()).Append(",");
}
SqlCommand c3 = new SqlCommand("dbo.SplitTest_UsingCLR", conn);
c3.CommandType = CommandType.StoredProcedure;
c3.Parameters.AddWithValue("@list", sb_fake.ToString());
c3.ExecuteNonQuery();
c3.Dispose();
write("Finished (3)");
// ********** (4) ********** //
write(Environment.NewLine + "Starting (4)");
DataTable dt_fake = new DataTable();
dt_fake.Columns.Add("Item", typeof(string));
string[] list = sb_pure.ToString().Split(',');
for (int i = 0; i < list.Length; i++)
{
if (list[i].Length > 0)
{
dt_fake.Rows.Add(list[i]);
}
}
SqlCommand c4 = new SqlCommand("dbo.SplitTest_UsingTVP", conn);
c4.CommandType = CommandType.StoredProcedure;
SqlParameter tvp2 = c4.Parameters.AddWithValue("@list", dt_fake);
tvp2.SqlDbType = SqlDbType.Structured;
c4.ExecuteNonQuery();
c4.Dispose();
write("Finished (4)");
}
}
static void write(string msg)
{
Console.WriteLine(msg + ": "
+ DateTime.UtcNow.ToString("HH:mm:ss.fffff"));
}
}
}