Въведение
Eager Index Spool чете всички редове от своя дъщерен оператор в индексирана работна таблица, преди да започне да връща редове на своя родителски оператор. В някои отношения нетърпеливият набор за индекси е най-доброто липсващо предложение за индекс , но не се отчита като такъв.
Оценка на разходите
Вмъкването на редове в индексирана работна таблица е сравнително евтино, но не е безплатно. Оптимизаторът трябва да вземе предвид, че включената работа спестява повече, отколкото струва. За да работи това в полза на макарата, планът трябва да бъде оценен така, че да консумира редове от макарата повече от веднъж. В противен случай може да пропусне макарата и просто да извърши основната операция този път.
- За да бъде достъпен повече от веднъж, макарата трябва да се появи от вътрешната страна на вложен оператор за присъединяване на цикли.
- Всяка итерация на цикъла трябва да търси конкретна стойност на ключа на индекса, предоставена от външната страна на цикъла.
Това означава, че присъединяването трябва да бъде apply , а не присъединяване на вложени цикли . За разликата между двете, моля, вижте моята статия Прилагане срещу присъединяване на вложени цикли.
Забележителни характеристики
Докато нетърпелива шпула с индекс може да се появи само от вътрешната страна на вложени цикли приложи , това не е „шпула за производителност“. Нетърпеливата шпула с индекс не може да бъде деактивирана с флаг за проследяване 8690 или NO_PERFORMANCE_SPOOL намек за заявка.
Редовете, вмъкнати в индексната пулса, обикновено не са предварително сортирани в реда на ключове на индекса, което може да доведе до разделяне на индексни страници. Недокументиран флаг за проследяване 9260 може да се използва за генериране на Сортиране оператор преди индексната макара, за да избегнете това. Недостатъкът е, че допълнителните разходи за сортиране могат да разубедят оптимизатора изобщо да избере опцията за макара.
SQL Server не поддържа паралелни вмъквания в индекс на b-дърво. Това означава, че всичко под паралелна нетърпелива индексна макара работи на една нишка. Операторите под макарата все още са (подвеждащо) маркирани с иконата на паралелизъм. Избира се една нишка за записване към макарата. Другите нишки чакат EXECSYNC докато това завърши. След като макарата е попълнена, тя може да бъде прочетена от чрез успоредни нишки.
Индексните пулове не казват на оптимизатора, че поддържат изход, подреден от индексните ключове на макарата. Ако се изисква сортиран изход от макарата, може да видите ненужно Сортиране оператор. Така или иначе нетърпеливите шпули с индекс често трябва да се заменят с постоянен индекс, така че това е незначителна грижа през повечето време.
Има пет правила за оптимизатор, които могат да генерират Eager Index Spool опция (известна вътрешно като индекс в движение ). Ще разгледаме три от тях подробно, за да разберем откъде идват нетърпеливите шпули с индекси.
SelToIndexOnTheFly
Това е най-често срещаният. Той съвпада с една или повече релационни селекции (известни още като филтри или предикати) точно над оператор за достъп до данни. SelToIndexOnTheFly правилото заменя предикатите с предикат за търсене на нетърпелива шпула с индекс.
Демо
AdventureWorks примерен пример за база данни е показан по-долу:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%';
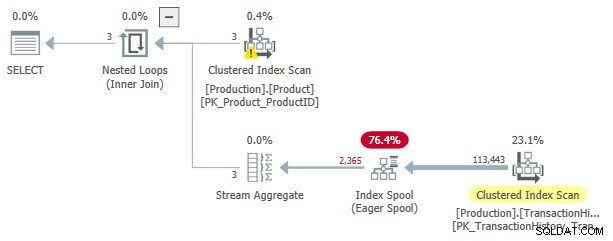
Този план за изпълнение има приблизителна цена от 3,0881 единици. Някои интересни точки:
- Вътрешно присъединяване на вложени цикли операторът е приложи , с
ProductIDиSafetyStockLevelотProductтаблица като външни препратки . - При първата итерация на приложението, Eager Index Spool е напълно попълнено от Сканиране на клъстериран индекс на
TransactionHistoryмаса. - Работната маса на макарата има клъстериран индекс с ключ на
(ProductID, Quantity). - Редове, съответстващи на предикатите
TH.ProductID = P.ProductIDиTH.Quantity < P.SafetyStockLevelотговарят от макарата, използвайки нейния индекс. Това важи за всяка итерация на приложението, включително първата. TransactionHistoryтаблицата се сканира само веднъж.
Сортиран вход към макарата
Възможно е да се наложи сортиран вход към eager index spool, но това се отразява на прогнозните разходи, както е отбелязано във въведението. За примера по-горе, активирането на флага за недокументирано проследяване създава план без макара:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%'
OPTION (QUERYTRACEON 9260);
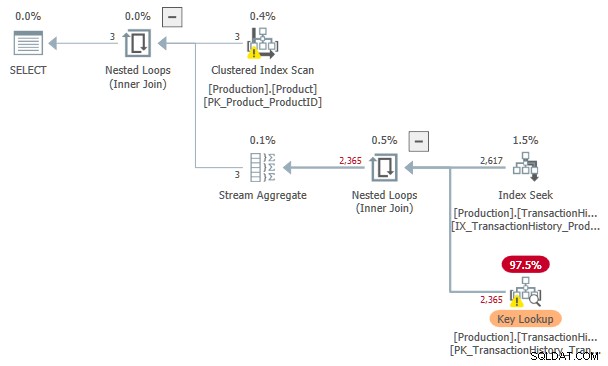
Прогнозната цена на това търсене на индекси и Ключово търсене планът е3.11631 единици. Това е повече от цената на плана само с индексна шпула, но по-малко от плана с индексна шпула и сортирани входни данни.
За да видим план със сортиран вход към макарата, трябва да увеличим очаквания брой повторения на цикъла. Това дава на макарата шанс да изплати допълнителните разходи за Сортиране . Един от начините за разширяване на броя на редовете, очаквани от Product таблица е да направите Name предикат по-малко ограничаващ:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'[A-P]%'
OPTION (QUERYTRACEON 9260); Това ни дава план за изпълнение със сортирани входни данни към пулта:
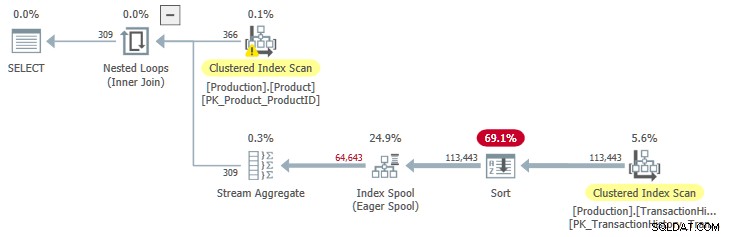
JoinToIndexOnTheFly
Това правило трансформира вътрешно присъединяване за прилагане , с нетърпелива индексна макара от вътрешната страна. Поне един от предикатите за свързване трябва да е неравенство, за да може това правило да бъде съвпадение.
Това е много по-специализирано правило от SelToIndexOnTheFly , но идеята е почти същата. В този случай селекцията (предикат), която се трансформира в търсене на индексна спула, е свързана с присъединяването. Трансформацията от присъединяване към прилагане позволява преместването на предиката за свързване от самото присъединяване към вътрешната страна на приложението.
Демо
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN);
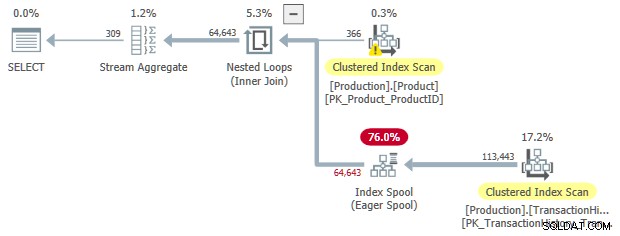
Както и преди, можем да поискаме сортирани входни данни към пулта:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN, QUERYTRACEON 9260);
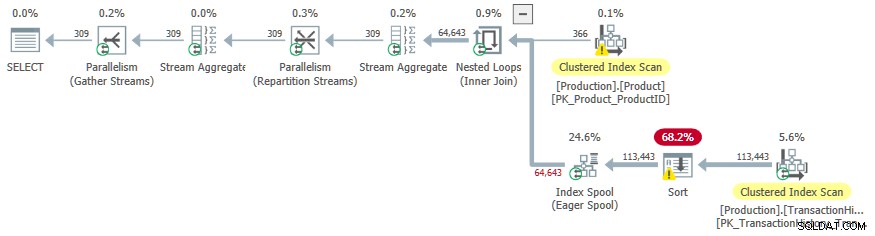
Този път допълнителните разходи за сортиране насърчиха оптимизатора да избере паралелен план.
Нежелан страничен ефект е Сортирането оператор прехвърля към tempdb . Общата предоставена памет за сортиране е достатъчна, но е разделена равномерно между паралелни нишки (както обикновено). Както е отбелязано във въведението, SQL Server не поддържа паралелни вмъквания към индекс на b-дърво, така че операторите под нетърпеливия индекс пулове се изпълняват в една нишка. Тази единична нишка получава само част от предоставената памет, така че Сортиране прехвърля към tempdb .
Този страничен ефект може би е една от причините флагът за проследяване да е недокументиран и неподдържан.
SelSTVFToIdxOnFly
Това правило прави същото като SelToIndexOnTheFly , но за поточна функция със стойност на таблица (sTVF) източник на ред. Тези sTVF се използват широко вътрешно за внедряване на DMV и DMF, наред с други неща. Те се появяват в съвременните планове за изпълнение като Функция с стойност на таблица оператори (първоначално като отдалечено сканиране на таблица ).
В миналото много от тези sTVF не можеха да приемат корелирани параметри от прилагане. Те могат да приемат литерали, променливи и модулни параметри, но не и прилагане външни препратки. Все още има предупреждения за това в документацията, но вече са малко остарели.
Както и да е, въпросът е, че понякога не е възможно SQL Server да предаде apply външна препратка като параметър към sTVF. В тази ситуация може да има смисъл част от резултата sTVF да се материализира в нетърпелива шпула с индекс. Настоящото правило предоставя тази способност.
Демо
Следващият пример с код показва DMV заявка, която е успешно преобразувана от присъединяване към прилагане . Външни препратки се предават като параметри към втория DMV:
-- Transformed to an apply
-- Outer reference passed as a parameter
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id = DES.session_id
OPTION (FORCE ORDER);
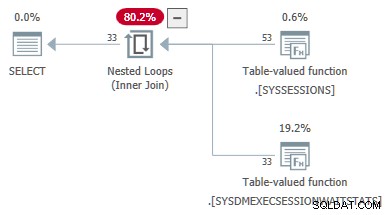
Свойствата на плана на TVF за статистиката за чакане показват входните параметри. Стойността на втория параметър се предоставя като външна препратка от сесиите DMV:
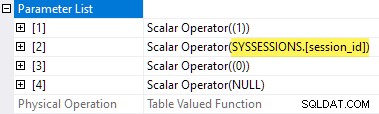
Жалко е, че sys.dm_exec_session_wait_stats е изглед, а не функция, защото това ни пречи да напишем прилагане директно.
Пренаписването по-долу е достатъчно, за да победи вътрешното преобразуване:
-- Rewrite to avoid TVF parameter trickery
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id >= DES.session_id
AND DESWS.session_id <= DES.session_id
OPTION (FORCE ORDER);
С session_id предикатите вече не се консумират като параметри, SelSTVFToIdxOnFly правилото е свободно да ги преобразува в нетърпелива индексна шпула:
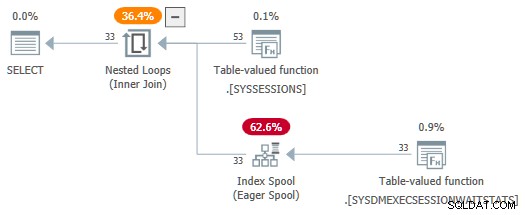
Не искам да ви оставя с впечатлението, че са необходими сложни пренаписвания, за да получите нетърпелив индекс шпула над DMV източник – това просто прави по-лесна демонстрация. Ако случайно срещнете заявка с DMV присъединявания, която произвежда план с нетърпелива шпула, поне знаете как е стигнала до там.
Не можете да създавате индекси на DMV, така че може да се наложи да използвате хеш или обединяване, ако планът за изпълнение не работи достатъчно добре.
Рекурсивни CTEs
Останалите две правила са SelIterToIdxOnFly и JoinIterToIdxOnFly . Те са преки двойници на SelToIndexOnTheFly и JoinToIndexOnTheFly за рекурсивни източници на данни за CTE. Те са изключително редки според моя опит, така че няма да предоставям демонстрации за тях. (Точно така Iter част от името на правилото има смисъл:идва от факта, че SQL Server прилага опашната рекурсия като вложена итерация.)
Когато рекурсивна CTE се препраща няколко пъти от вътрешната страна на приложение, различно правило (SpoolOnIterator ) може да кешира резултата от CTE:
WITH R AS
(
SELECT 1 AS n
UNION ALL
SELECT R.n + 1
FROM R
WHERE R.n < 10
)
SELECT
R1.n
FROM R AS R1
CROSS JOIN R AS R2; Планът за изпълнение включва рядка Eager Row Count Spool :
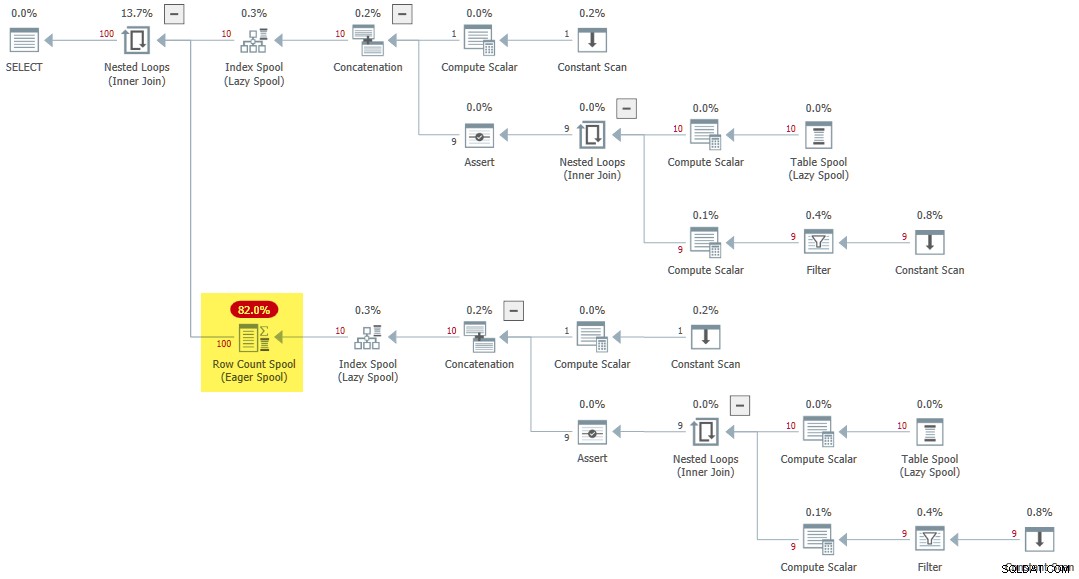
Последни мисли
Нетърпеливите индексни пулове често са знак, че полезен постоянен индекс липсва от схемата на базата данни. Това не винаги е така, както показват примерите за функцията за поточно предаване на стойност на таблица.