Наличието на референтни таблици във вашата база данни не е голяма работа, нали? Просто трябва да свържете код или идентификатор с описание за всеки референтен тип. Но какво ще стане, ако буквално имате десетки и десетки справочни таблици? Има ли алтернатива на подхода една маса за тип? Прочетете, за да откриете общ и разширяем дизайн на база данни за работа с всички ваши референтни данни.
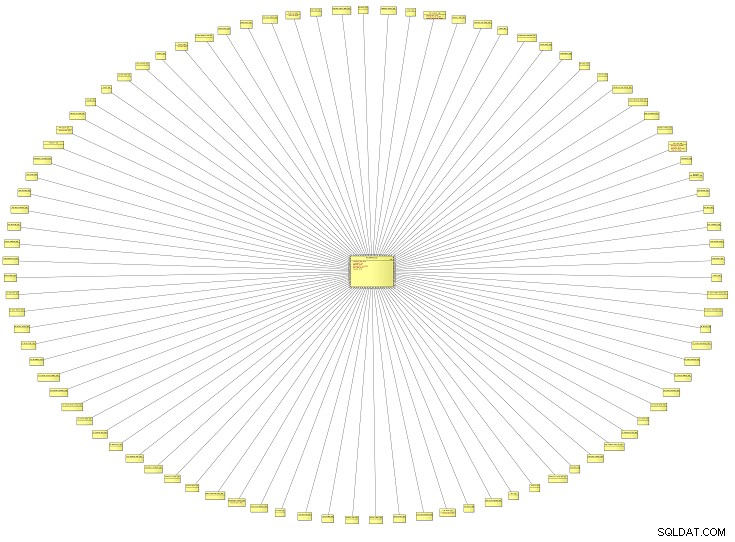
Тази необичайно изглеждаща диаграма е изглед от птичи поглед на логически модел на данни (LDM), съдържащ всички референтни типове за корпоративна система. Това е от образователна институция, но може да се приложи към модела на данни на всякакъв вид организация. Колкото по-голям е моделът, толкова повече референтни типове е вероятно да разкриете.
Под референтни типове имам предвид референтни данни или справочни стойности или – ако искате да бъдете флаш – таксономии . Обикновено дефинираните тук стойности се използват в падащи списъци в потребителския интерфейс на вашето приложение. Те могат да се появят и като заглавия в отчет.
Този конкретен модел на данни имаше около 100 референтни типа. Нека увеличим и разгледаме само две от тях.
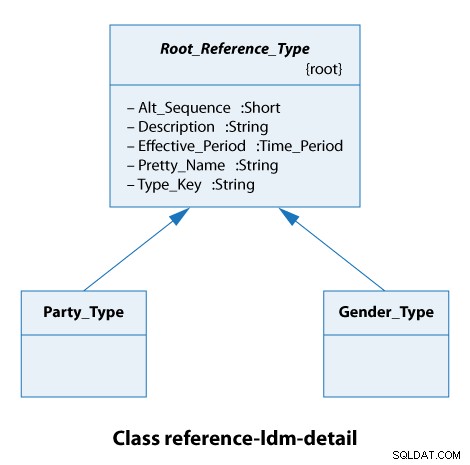
От тази диаграма на класа виждаме, че всички референтни типове разширяват Root_Reference_Type . На практика това просто означава, че всички наши референтни типове имат едни и същи атрибути от Alt_Sequence до Type_Key включително, както е показано по-долу.
| Атрибут | Описание |
|---|---|
Alt_Sequence | Използва се за дефиниране на алтернативна последователност, когато се изисква неазбучен ред. |
Description | Описанието на типа. |
Effective_Period | Ефективно дефинира дали референтният запис е разрешен или не. След като се използва препратка, тя не може да бъде изтрита поради референтни ограничения; може само да се деактивира. |
| Хубавото име за типа. Това е, което потребителят вижда на екрана. |
Type_Key | Уникалният вътрешен КЛЮЧ за типа. Това е скрито от потребителя, но разработчиците на приложения могат да използват широко това в своя SQL. |
Типът парти тук е или организация, или човек. Видовете пол са мъжки и женски. Така че това са наистина прости случаи.
Традиционното решение за референтна таблица
И така, как ще приложим логическия модел във физическия свят на действителна база данни?
Бихме могли да приемем, че всеки референтен тип ще се съпостави със собствената си таблица. Може да наречете това по-традиционното една маса на клас решение. Това е достатъчно просто и би изглеждало така:
Недостатъкът на това е, че може да има десетки и десетки тези таблици, всички да имат едни и същи колони, всички да правят почти едно и също нещо.
Освен това, може да създаваме много повече разработка . Ако се изисква потребителски интерфейс за всеки тип за администраторите, за да поддържат стойностите, тогава количеството работа бързо се умножава. Няма твърди и бързи правила за това – това наистина зависи от вашата среда за разработка – така че ще трябва да говорите с вашите разработчици за да разберете какво въздействие има това.
Но като се има предвид, че всички наши референтни типове имат едни и същи атрибути или колони, има ли по-общ начин за прилагане на нашия логически модел на данни? Да, има! Иизисква само две таблици .
Решение с две таблици
Първата дискусия, която имах по тази тема, беше в средата на 90-те, когато работех за застрахователна компания на Лондонския пазар. Тогава ние отидохме направо към физическия дизайн и използвахме предимно естествени/бизнес ключове, а не ID. Когато съществуваха референтни данни, решихме да запазим една таблица за тип, която се състои от уникален код (VARCHAR PK) и описание. Всъщност тогава е имало много по-малко справочни таблици. По-често, отколкото не, ограничен набор от бизнес кодове ще се използва в колона, вероятно с дефинирано ограничение за проверка на база данни; изобщо няма да има референтна таблица.
Но оттогава играта продължи. Ето какво е решение с две маси може да изглежда така:
Както можете да видите, този модел на физически данни е много прост. Но това е доста различно от логическия модел и не защото нещо е станало изцяло крушовидно. Това е така, защото редица неща бяха направени като част от физическия дизайн .
reference_type таблицата представя всеки отделен референтен клас от LDM. Така че, ако имате 20 референтни типа във вашия LDM, ще имате 20 реда метаданни в таблицата. reference_value таблицата съдържа допустимите стойности за всички референтните типове.
По време на този проект имаше доста оживени дискусии между разработчиците. Някои предпочитаха решението с две маси, а други предпочитаха една маса на тип метод.
Има плюсове и минуси за всяко решение. Както може би се досещате, разработчиците бяха загрижени най-вече за количеството работа, която потребителският интерфейс ще поеме. Някои смятаха, че събирането на администраторски потребителски интерфейс за всяка маса ще бъде доста бързо. Други смятаха, че изграждането на един потребителски интерфейс на администратор ще бъде по-сложно, но в крайна сметка ще се изплати.
В този конкретен проект решението с две маси беше предпочитано. Нека го разгледаме по-подробно.
Разширяем и гъвкав модел на референтни данни
Тъй като вашият модел на данни се развива с течение на времето и се изискват нови референтни типове, не е необходимо да правите промени във вашата база данни за всеки нов референтен тип. Просто трябва да дефинирате нови данни за конфигурация. За да направите това, добавяте нов ред към reference_type таблица и добавете нейния контролиран списък с допустими стойности към reference_value таблица.
Важна концепция, съдържаща се в това решение, е тази за дефиниране на ефективни периоди от време за определени стойности. Например, вашата организация може да се наложи да улови нова reference_value на „Доказателство за самоличност“, което ще бъде приемливо на някоя бъдеща дата. Лесно е да добавите тази нова reference_value с effective_period_from правилно зададена дата. Това може да се направи предварително. До настъпването на тази дата новият запис няма да се появи в падащия списък със стойности, които потребителите на вашето приложение виждат. Това е така, защото приложението ви показва само стойности, които са текущи или активирани.
От друга страна, може да се наложи да спрете потребителите да използват определена reference_value . В такъв случай просто го актуализирайте с effective_period_to правилно зададена дата. Когато този ден мине, стойността вече няма да се показва в падащия списък. От този момент нататък става деактивиран. Но тъй като все още съществува физически като ред в таблицата, целостта на препратката се поддържа за онези таблици, където вече е споменато.
Сега, когато работихме върху решението с две таблици, стана очевидно, че някои допълнителни колони ще бъдат полезни за reference_type маса. Те са съсредоточени най-вече върху опасенията за потребителския интерфейс.
Например pretty_name на reference_type таблицата беше добавена за използване в потребителския интерфейс. За големи таксономии е полезно да използват прозорец с функция за търсене. След това pretty_name може да се използва за заглавие на прозореца.
От друга страна, ако падащ списък със стойности е достатъчен, pretty_name може да се използва за подканата LOV. По подобен начин описанието може да се използва в потребителския интерфейс за попълване на помощ при превъртане.
Разглеждането на типа конфигурация или метаданни, които влизат в тези таблици, ще помогне да се изяснят малко нещата.
Как да управлявам всичко това
Докато примерът, използван тук, е много прост, референтните стойности за голям проект могат бързо да станат доста сложни. Така че може да е препоръчително да поддържате всичко това в електронна таблица. Ако е така, можете да използвате самата електронна таблица, за да генерирате SQL чрез конкатенация на низове. Това се поставя в скриптове, които се изпълняват срещу целевите бази данни, които поддържат жизнения цикъл на разработка и производствената (на живо) база данни. Това създава базата данни с всички необходими референтни данни.
Ето конфигурационните данни за двата типа LDM, Gender_Type и Party_Type :
PROMPT Gender_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Gender Type', 'GENDER_TYPE', ' Identifies the gender of a person.', 13000000, 13999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000010,'Female', 'Female', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000020,'Male', 'Male', TRUNC(SYSDATE), 20, rety_seq.currval); PROMPT Party_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Party Type', 'PARTY_TYPE', A controlled list of reference values that identifies the type of party.', 23000000, 23999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000010,'Organisation', 'Organisation', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000020,'Person', 'Person', TRUNC(SYSDATE), 20, rety_seq.currval);
Има ред в reference_type за всеки LDM подтип на Root_Reference_Type . Описанието в reference_type е взето от описанието на класа LDM. За Gender_Type , това би гласи „Идентифицира пола на дадено лице“. DML фрагментите показват разликите в описанията между тип и стойност, които могат да се използват в потребителския интерфейс или в отчети.
Ще видите този reference_type наречен Gender_Type е разпределен диапазон от 13000000 до 13999999 за свързаните с него reference_value.ids . В този модел всеки reference_type се разпределя уникален, неприпокриващ се диапазон от идентификатори. Това не е строго необходимо, но ни позволява да групираме свързани идентификатори на стойности заедно. Това имитира това, което бихте получили, ако имате отделни маси. Хубаво е да го имаш, но ако не мислиш, че има полза от това, тогава можеш да се откажеш от него.
Друга колона, добавена към PDM, е admin_role . Ето защо.
Кои са администраторите
Някои таксономии могат да имат добавени или премахнати стойности с малко или никакво въздействие. Това ще се случи, когато нито една програма не използва стойностите в своята логика или когато типът не е свързан с други системи. В такива случаи е безопасно администраторите на потребителите да ги поддържат актуални.
Но в други случаи трябва да се внимава много повече. Нова референтна стойност може да причини непредвидени последици за логиката на програмата или за системите надолу по веригата.
Например, да предположим, че добавяме следното към таксономията на типа пол:
INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000040,'Not Known', 'Gender has not been recorded. Covers gender of unborn child, when someone has refused to answer the question or when the question has not been asked.', TRUNC(SYSDATE), 30, (SELECT id FROM reference_type WHERE ref_type_key = 'GENDER_TYPE'));
Това бързо се превръща в проблем, ако някъде имаме вградена следната логика:
IF ref_key = 'MALE' THEN RETURN 'M'; ELSE RETURN 'F'; END IF;
Ясно е, че логиката „ако не си мъж, трябва да си жена“ вече не се прилага в разширената таксономия.
Това е мястото, където admin_role колона влиза в игра. Той се роди от дискусии с разработчиците относно физическия дизайн и работеше във връзка с тяхното UI решение. Но ако беше избрано решението с една таблица на клас, тогава reference_type нямаше да съществува. Метаданните, които съдържа, биха били твърдо кодирани в приложението Gender_Type таблица – , която не е нито гъвкава, нито разширяема.
Само потребители с правилните привилегии могат да администрират таксономията. Това вероятно ще се основава на експертен опит по темата (SME ). От друга страна може да се наложи някои таксономии да бъдат администрирани от ИТ, за да позволят анализ на въздействието, задълбочено тестване и всякакви промени в кода да бъдат хармонично пуснати навреме за новата конфигурация. (Дали това се прави чрез заявки за промяна или по някакъв друг начин зависи от вашата организация.)
Може да сте забелязали, че одитните колони created_by , created_date , updated_by и updated_date изобщо не са посочени в горния скрипт. Отново, ако не се интересувате от тях, не е нужно да ги използвате. Тази конкретна организация имаше стандарт, който изискваше да има колони за одит на всяка таблица.
Задействания:Поддържане на нещата последователни
Тригерите гарантират, че тези колони за одит се актуализират последователно, без значение какъв е източникът на SQL (скриптове, вашето приложение, планирани пакетни актуализации, ad-hoc актуализации и т.н.).
-------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_TYPE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER rety_bri BEFORE INSERT ON reference_type FOR EACH ROW DECLARE BEGIN IF (:new.id IS NULL) THEN :new.id := rety_seq.nextval; END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END rety_bri; / CREATE OR REPLACE TRIGGER rety_bru BEFORE UPDATE ON reference_type FOR EACH ROW DECLARE BEGIN :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END rety_bru; / -------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_VALUE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER reva_bri BEFORE INSERT ON reference_value FOR EACH ROW DECLARE BEGIN IF (:new.type_key IS NULL) THEN -- create the type_key from pretty_name: :new.type_key := function_to_create_key(new.pretty_name); END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END reva_bri; / CREATE OR REPLACE TRIGGER reva_bru BEFORE UPDATE ON reference_value FOR EACH ROW DECLARE BEGIN -- once the type_key is set it cannot be overwritten: :new.type_key := :old.type_key; :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END reva_bru; /
Моят фон е предимно Oracle и, за съжаление, Oracle ограничава идентификаторите до 30 байта. За да се избегне превишаването на това, на всяка таблица се дава кратък псевдоним от три до пет знака и други артефакти, свързани с таблицата, използват този псевдоним в имената си. И така, reference_value Псевдонимът на е reva – първите два знака от всяка дума. Преди вмъкване на ред и преди актуализирането на реда да бъде съкратено на bri и bru съответно. Името на последователността reva_seq , и така нататък.
Ръчно кодиране на тригери като това, таблица след таблица, изисква много деморализираща стандартна работа за разработчиците. За щастие, тези тригери могат да бъдат създадени чрез генериране на код , но това е тема на друга статия!
Значението на ключовете
ref_type_key и type_key и двете колони са ограничени до 30 байта. Това им позволява да се използват в SQL заявки от тип PIVOT (в Oracle. Други бази данни може да нямат същото ограничение за дължина на идентификатора).
Тъй като уникалността на ключа се осигурява от базата данни и тригерът гарантира, че стойността му остава една и съща за всички времена, тези ключове могат – и трябва – да се използват в заявки и код, за да ги направят по-четливи . Какво имам предвид с това? Е, вместо:
SELECT … FROM … INNER JOIN … WHERE reference_value.id = 13000020
Пишете:
SELECT … FROM … INNER JOIN … WHERE reference_value.type_key = 'MALE'
По принцип ключът ясно посочва какво прави заявката .
От LDM към PDM, с място за растеж
Пътуването от LDM до PDM не е непременно прав път. Нито пък е пряка трансформация от едното в другото. Това е отделен процес, който въвежда свои собствени съображения и собствени притеснения.
Как моделирате референтните данни във вашата база данни?