Всички правим грешки и всички можем да се поучим от грешките на другите хора. В тази публикация ще разгледаме множество онлайн ресурси за избягване на лош дизайн на база данни, който може да доведе до много проблеми и да струва както време, така и пари. И в предстояща статия ще ви кажем къде да намерите съвети и най-добри практики.
Грешки и грешки в дизайна на базата данни, които трябва да се избягват
Има много онлайн ресурси, които да помогнат на дизайнерите на бази данни да избегнат често срещани грешки и грешки. Очевидно тази статия не е изчерпателен списък на всяка статия там. Вместо това ние прегледахме и коментирахме различни източници, за да можете да намерите този, който най-добре ви подхожда.
Нашата препоръка
Ако сред тези ресурси има само една статия, която ще прочетете, тя трябва да бъде „Как да получите ужасно грешен дизайн на базата данни“ от Робърт Шелдън
Нека започнем с блога DATAVERSITY, който предоставя широк набор от доста добри ресурси:
Грешки в първичния и външния ключ, които трябва да се избягват
от Майкъл Блаха | Блог на DATAVERSITY | 2 септември 2015 г.
Още грешки в дизайна на базата данни – объркване с връзки много към много
от Майкъл Блаха | Блог на DATAVERSITY | 30 септември 2015 г.
Разни грешки в дизайна на базата данни
от Майкъл Блаха | Блог на DATAVERSITY | 26 октомври 2015 г.
Майкъл Блаха допринесе с хубав набор от три статии. Всяка статия разглежда различни капани на моделирането на база данни и физическия дизайн; темите включват ключове, връзки и общи грешки. Освен това има дискусии с Майкъл по някои от точките. Ако търсите клопки около ключовете и взаимоотношенията, това би било добро място да започнете.
Г-н Блаха заявява, че „около 20% от базите данни нарушават правилата за първичен ключ“. Еха! Това означава, че около 20% от разработчиците на бази данни не са създали правилно първични ключове. Ако тази статистика е вярна, тогава тя наистина показва важността на инструментите за моделиране на данни, които силно „насърчават“ или дори изискват моделистите да дефинират първични ключове.
Г-н Блаха също споделя евристичния принцип, че „около 50% от базите данни“ имат проблеми с външния ключ (според опита му с наследени бази данни, които е изучавал). Той ни напомня да избягваме неформални връзки между таблици, като вграждаме стойността от една таблица в друга, вместо да използваме външен ключ.
Виждал съм този проблем много пъти. Признавам, че неформалната връзка може да се изисква от функционалността, която трябва да бъде внедрена, но по-често това се случва поради обикновен мързел. Например, може да искаме да покажем потребителския идентификатор на някой, който е променил нещо, така че съхраняваме потребителския идентификатор директно в таблицата. Но какво ще стане, ако този потребител промени потребителския си идентификатор? Тогава тази неформална връзка е прекъсната. Това често се дължи на лош дизайн и моделиране.
Проектиране на вашата база данни:Топ 5 грешки, които трябва да избягвате
от Хенрике Нецка | Блог на DATAVERSITY | 2 ноември 2015 г.
Бях малко разочарован от тази статия, тъй като имаше няколко доста специфични елемента (съхранение на протокол в CLOB) и няколко много общи (помислете за локализация). Като цяло статията е добра, но това наистина ли са първите 5 грешки, които трябва да се избягват? Според мен има няколко други често срещани грешки, които трябва да попаднат в списъка.
Въпреки това, в положителна нотка, това е една от малкото статии, които споменават глобализацията и локализацията по някакъв смислен начин. Работя в многоезична среда и съм виждал няколко ужасни реализации на локализация, така че бях щастлив да открия, че този проблем е споменат. Езикови колони и колони за часови зони може да изглеждат очевидни, но се появяват много рядко в моделите на бази данни.
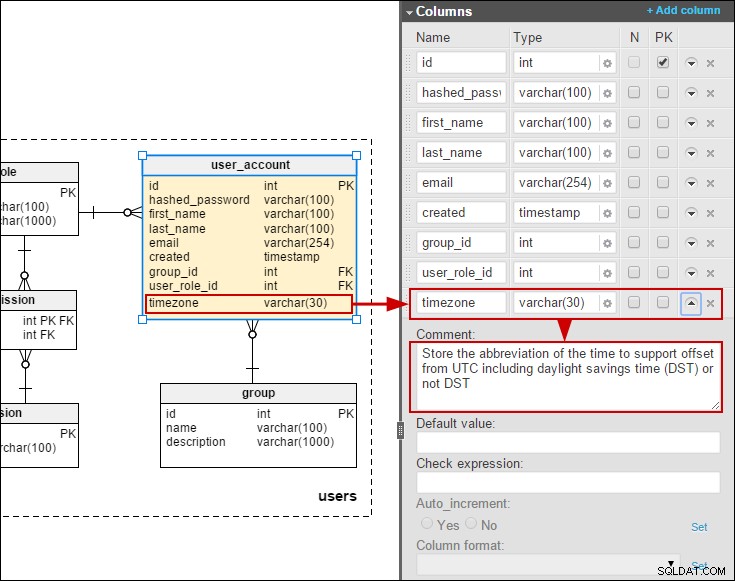
Като се има предвид това, реших, че би било интересно да се създаде модел, включващ преводи, които могат да бъдат променяни от крайните потребители (за разлика от използването на пакети от ресурси). Преди време писах за модел за онлайн база данни от анкети. Тук моделирах опростен превод на въпроси и избор на отговор:
Ако приемем, че трябва да позволим на крайните потребители да поддържат преводите, предпочитаният метод би бил да добавим таблици за превод за въпроси и отговори:
Добавих и часова зона към user_account таблица, така че да можем да съхраняваме дати/часове в местното време на потребителите:
7 често срещани грешки при проектирането на база данни
от Гжегож Кацор | Блог на Vertabelo | 17 юли 2015 г.
Тук ще направя малко самореклама. Стремим се редовно да публикуваме интересни и завладяващи статии тук.
Тази конкретна статия посочва няколко важни области на загриженост, като именуване, индексиране, съображения за обем и одитни пътеки. Статията дори се занимава с проблеми, свързани със специфични DBM системи, като ограниченията на Oracle върху имената на таблици. Наистина харесвам хубави ясни примери, дори ако те илюстрират как дизайнерите правят грешки и грешки.
Очевидно не е възможно да се изброят всички грешки в дизайна и изброените може да не са ваши най-често срещаните грешки. Когато пишем за често срещани грешки, ние черпим от тези, които сме допуснали или открили в работата на другите. Пълен списък с грешки, подредени по честота, би било невъзможно за един човек да състави. Въпреки това мисля, че тази статия предоставя няколко полезни прозрения за потенциалните клопки. Като цяло е добър солиден ресурс.
Докато г-н Kaczor изтъква няколко интересни точки в статията си, намерих коментарите му относно „неотчитането на възможния обем или трафик“ доста интересни. По-специално, препоръката за отделяне на често използвани данни от исторически данни е особено уместна. Това е решение, което използваме често в нашите приложения за съобщения; трябва да имаме история на всички съобщения с възможност за търсене, но съобщенията, които най-вероятно ще бъдат достъпни, са тези, които са били публикувани през последните няколко дни. Така че разделянето на „активни“ или скорошни данни, които са често достъпни (много по-малък обем данни) от дългосрочни исторически данни (голямата маса данни) като цяло е много добра техника.
Чести грешки при проектирането на база данни
от Трой Блейк | Блог на старши DBA | 11 юли 2015 г.
Статията на Трой Блейк е друг добър ресурс, въпреки че може би щях да преименувам тази статия „Общи грешки в дизайна на SQL Server“.
Например, имаме коментар:„запазените процедури са най-добрият ви приятел, когато става въпрос за ефективно използване на SQL Server“. Това е добре, но това честа обща грешка ли е, или е по-специфична за SQL Server? Ще трябва да избера това да е малко специфично за SQL Server, тъй като има недостатъци при използването на съхранени процедури, като завършване със специфични за доставчика съхранени процедури и по този начин блокиране на доставчика. Така че не съм фен на включването на „Не използвам съхранени процедури“ в този списък.
Въпреки това, от положителна страна, мисля, че авторът идентифицира някои много често срещани грешки, като лошо планиране, лош дизайн на системата, ограничена документация, слаби стандарти за именуване и липса на тестване.
Така че бих класифицирал това като много полезна справка за практикуващите SQL Server и полезна справка за други.
Седем грешки при моделирането на данни
от Кърт Кейгъл | LinkedIn | 12 юни 2015 г.
Наистина ми хареса да прочета списъка на г-н Кейгъл с грешки при моделирането на база данни. Това са от гледната точка на архитекта на базата данни за нещата; той ясно идентифицира грешките при моделиране на по-високо ниво, които трябва да се избягват. С този изглед на по-голяма картина можете да прекратите потенциална бъркотия при моделиране.
Някои от видовете, споменати в статията, могат да бъдат намерени другаде, но някои от тях са уникални:абстрактно твърде рано или смесване на концептуални, логически и физически модели. Те не се споменават често от други автори, вероятно защото се фокусират върху процеса на моделиране на данни, а не върху по-големия системен изглед.
По-специално, примерът на „Получаване твърде абстрактно твърде рано“ описва интересен мисловен процес за създаване на някои примерни „истории“ и тестване кои взаимоотношения са важни в тази област. Това фокусира мисленето върху връзките между моделираните обекти. Това води до въпроси като кои са важните взаимоотношения в този домейн ?
Въз основа на това разбиране ние създаваме модела около връзките, вместо да започваме от отделни елементи на домейна и да изграждаме връзките върху тях. Въпреки че много от нас може да използват този подход, сред тези ресурси никой друг автор не го е коментирал. Намерих това описание и примерите за доста интересни.
Как да получите ужасно грешен дизайн на базата данни
от Робърт Шелдън | Прост разговор | 6 март 2015 г.
Ако има само една статия сред тези ресурси, която ще прочетете, тя трябва да е тази от Робърт Шелдън
Това, което наистина харесвам в тази статия, е, че за всяка от споменатите грешки има съвети как да го направите правилно. Повечето от тях се фокусират върху избягването на провала, вместо да го коригират, но все пак смятам, че са много полезни. Тук има много малко теория; предимно прави отговори за избягване на грешки при моделиране на данни. Има няколко конкретни точки на SQL Server, но най-вече SQL Server се използва за предоставяне на примери за избягване на грешки или начини за излизане от повреда.
Обхватът на статията също е доста широк:обхваща пренебрегване на планирането, не се занимава с документация, използване на лоши конвенции за именуване, проблеми с нормализирането (твърде много или твърде малко), неуспех на ключове и ограничения, неправилно индексиране и изпълнение неадекватно тестване.
По-специално ми харесаха практическите съвети относно целостта на данните – кога да се използват ограничения за проверка и кога да се дефинират външни ключове. В допълнение, г-н Шелдън също така описва ситуацията, когато екипите се придържат към приложението, за да наложат почтеността. Той е направо, когато заявява, че базата данни може да бъде достъпна по множество начини и чрез множество приложения. Неговият заключава, че „данните трябва да бъдат защитени там, където се намират:в рамките на базата данни“. Това е толкова вярно, че може да се повтори на екипите за разработка и мениджърите, за да се обясни важността на внедряването на проверки на целостта в модела на данните.
Това е моят вид статия и можете да кажете, че други са съгласни въз основа на многобройните коментари, които я подкрепят. И така, най-добри оценки тук; това е много ценен ресурс.
Десет често срещани грешки при проектирането на база данни
от Луис Дейвидсън | Прост разговор | 26 февруари 2007 г.
Намерих тази статия за доста добра, тъй като обхваща много често срещани грешки в дизайна. Имаше смислени аналогии, примери, модели и дори някои класически цитати от Уилям Шекспир и Дж.Р.Р. Толкин.
Няколко от грешките бяха обяснени по-подробно от други, с дълги примери и SQL откъси, които намерих за малко тромави. Но това е въпрос на вкус.
Отново имаме няколко теми, специфични за SQL Server. Например, смисълът да не се използват Съхранени процедури за достъп до данни е добър за SQL, но SP-ите не винаги са добра идея, когато целта е поддръжка на множество СУБД. В допълнение, ние сме предупредени да не се опитваме да кодираме генерични T-SQL обекти. Тъй като рядко работя със SQL Server или Sybase, не намерих този съвет за подходящ.
Списъкът е доста подобен на този на Робърт Шелдън, но ако работите предимно върху SQL Server, тогава ще намерите няколко допълнителни парчета информация.
Пет прости грешки при проектирането на база данни, които трябва да избягвате
от Анит Сен Ларсън | Прост разговор | 16 октомври 2009 г.
Тази статия дава някои смислени примери за всяка от простите дизайнерски грешки, които покрива. От друга страна, той е по-скоро фокусиран върху подобни типове грешки:общи справочни таблици, таблици със стойности на обект-атрибут и разделяне на атрибути.
Наблюденията са добри, а статията дори има препратки, които обикновено са рядкост. Все пак бих искал да видя по-общи грешки в дизайна на базата данни. Тези грешки изглеждаха доста специфични, но както вече писах, грешките, за които пишем, обикновено са тези, с които имаме личен опит.
Един елемент, който ми хареса, беше специфично правило за решаване кога да се използва ограничение за проверка спрямо отделна таблица с ограничение за външен ключ. Няколко автори дават подобни препоръки, но г-н Ларсън ги разделя на „трябва“, „да се обмисли“ и „силен случай“ – с признанието, че „дизайнът е смесица от изкуство и наука и следователно включва компромиси“. Намирам това за много вярно.
Десетте най-често срещани грешки в дизайна на физическа база данни
от Крейг Мълинс | Данни и технологии днес | 5 август 2013 г.
Както подсказва името му, „Топ десетте най-често срещани грешки в дизайна на физически бази данни“ е малко по-ориентиран към физическия дизайн, а не към логическия и концептуален дизайн. Нито една от грешките, споменати от автора Крейг Мълинс, наистина не се откроява или не е уникална, така че бих препоръчал тази информация на хора, работещи от страна на физическия DBA.
Освен това описанията са малко кратки, така че понякога е трудно да се разбере защо конкретна грешка ще причини проблеми. Няма нищо лошо в кратките описания, но те не ви дават много за размисъл. И не са представени примери.
Има един интересен въпрос, повдигнат, свързан с несподелянето на данни. Тази точка понякога се споменава в други статии, но не като грешка в дизайна. Въпреки това виждам този проблем доста често, когато базите данни се „пресъздават“ въз основа на много сходни изисквания, но от нов екип или за нов продукт
.Често се случва продуктовият екип да осъзнае по-късно, че би искал да използва данни, които вече са присъствали в „бащата“ на текущата им база данни. В действителност обаче те трябваше да подобрят родителя, вместо да създават ново потомство. Приложенията са предназначени да споделят данни; добрият дизайн може да позволи на база данни да се използва по-често.
Правиш ли тези 5 грешки в дизайна на базата данни?
от Томас Ларок | Блогът на Томас Ларок | 2 януари 2012 г.
Може да откриете няколко интересни точки, докато отговаряте на въпроса на Томас Ларок:Правите ли тези 5 грешки в дизайна на база данни?
Тази статия е донякъде претеглена по отношение на ключовете (външни ключове, сурогатни ключове и генерирани ключове). И все пак, той има един важен момент:не трябва да се предполага, че характеристиките на СУБД са еднакви във всички системи. Мисля, че това е много добра точка. Също така е такъв, който не се среща в повечето други статии, може би защото много автори се фокусират върху и работят предимно с една СУБД.
Проектиране на база данни:7 неща, които не искате да правите
от Томас Ларок | Блогът на Томас Ларок | 16 януари 2013 г.
Г-н Ларок рециклира няколко от своите „5 грешки в дизайна на база данни“, когато пише „7 неща, които не искате да правите“, но тук има и други добри точки.
Интересното е, че някои от точките, които г-н Ларок прави, не се намират в много други източници. Получавате няколко доста уникални наблюдения, като „да нямате очаквания за представяне“. Това е сериозна грешка, която според моя опит се случва доста често. Дори при разработването на кода на приложението, често след създаването на модела на данни, базата данни и самото приложение хората започват да мислят за нефункционалните изисквания (когато трябва да бъдат създадени нефункционални тестове) и започват да дефинират очакванията за производителност .
Обратно, има няколко точки, които не бих включил в собствения си списък с Топ десет, като например „да стане голям, за всеки случай“. Виждам смисъла, но не е толкова високо в списъка ми, когато създавам модел на данни. Няма специфичност за конкретна DBM система, така че това е бонус.
В заключение, много от тези точки могат да бъдат капсулирани под точката:„неразбиране на изискванията“, което наистина е в моя списък с топ 10 грешки.
Как да избегнем 8 често срещани грешки при разработването на бази данни
от Base36 | 6 декември 2012 г.
Беше ми доста интересно да прочета тази статия. Въпреки това бях малко разочарован. Няма много дискусии относно избягването и целта на статията наистина изглежда е „това са често срещани грешки в базата данни“ и „защо са грешки“; описанията как да избегнете грешката са по-малко забележими.
Освен това някои от Топ 8 грешки в статията всъщност са оспорени. Злоупотребата с първичен ключ е пример. Base36 ни казва, че те трябва да бъдат генерирани от системата, а не на база данни на приложението в реда. Макар че съм съгласен с това до известна степен, не съм убеден, че всички ПК трябва винаги да бъдат генерирани; това е малко твърде категорично.
От друга страна, грешката на “Hard Deletes” е интересна и не се споменава често другаде. Меките изтривания причиняват други проблеми, но е вярно, че простото маркиране на ред като неактивен има своите предимства, когато се опитвате да разберете къде са отишли тези данни, които са били в системата вчера. Търсенето в регистрационните файлове на транзакциите не е моята идея за приятен начин да прекарате един ден.
Седемте смъртни гряха на дизайна на база данни
от Джейсън Тирет | Enterprise Systems Journal | 16 февруари 2010 г.
Бях доста обнадежден, когато започнах да чета статията на Джейсън Тирет „Седемте смъртни гряха на дизайна на бази данни“. Така че бях щастлив да открия, че той не само рециклира грешки, които се срещат в много други статии. Напротив, той предложи „грях“, който не бях намерил в други списъци:опит за изпълнение на целия дизайн на база данни „отпред“ и не актуализиране на модела, след като базата данни е в производство, когато се правят промени в базата данни. (Или, както казва Джейсън, „Не третиране на модела на данни като жив, дишащ организъм“).
Виждал съм тази грешка много пъти. Повечето хора осъзнават грешката си едва когато трябва да направят актуализации на модел, който вече не съответства на действителната база данни. Разбира се, резултатът е безполезен модел. Както се казва в статията, „промените трябва да намерят пътя си обратно към модела.“
От друга страна, по-голямата част от списъците на Джейсън са доста добре известни. Описанията са добри, но няма много примери. Още примери и подробности биха били полезни.
Най-често срещаните грешки в дизайна на база данни
от Брайън Принс | eWeek.com | 19 март 2008 г.

Статията „Най-често срещаните грешки в дизайна на база данни“ всъщност е поредица от слайдове от презентация. Има няколко интересни мисли, но някои от уникалните предмети може би са малко езотерични. Имам предвид точки като „Запознайте се с RAID“ и участието на заинтересованите страни.
Като цяло не бих поставил това в списъка ви за четене, освен ако не сте фокусирани върху общи въпроси (планиране, именуване, нормализиране, индекси) и физически подробности.
10 често срещани грешки в дизайна
от davidm | Блогове на SQL Server – SQLTeam.com | 12 септември 2005 г.
Някои от точките в „Десет често срещани грешки в дизайна“ са интересни и сравнително нови. Въпреки това, някои от тези грешки са доста противоречиви, като например „използване на NULL“ и денормализиране.
Съгласен съм, че създаването на всички колони като nullable е грешка, но дефинирането на колона като nullable може да се изисква за конкретна бизнес функция. Следователно може ли да се счита за обща грешка? Мисля, че не.
Друг момент, с който имам проблеми, е денормализацията. Това не винаги е грешка в дизайна. Например, може да се наложи денормализиране от съображения за производителност.
В тази статия също до голяма степен липсват подробности и примери. Разговорите между DBA и програмиста или мениджъра са забавни, но бих предпочел по-конкретни примери и подробни обосновки за тези често срещани грешки.
OTLT и EAV:двете големи грешки в дизайна, които всички начинаещи допускат
от Тони Андрюс | Тони Андрюс за Oracle и бази данни | 21 октомври 2004 г.
Статията на г-н Андрюс ни напомня за грешките в „Една истинска таблица за търсене“ (OTLT) и Entity-Attribute-Value (EAV), които се споменават в други статии. Един хубав момент в тази презентация е, че се фокусира върху тези две грешки, така че описанията и примерите са точни. Освен това е дадено възможно обяснение защо някои дизайнери прилагат OTLT и EAV.
За да ви напомня, OTLT таблицата обикновено изглежда така, с записи от множество домейни, хвърлени в една и съща таблица:
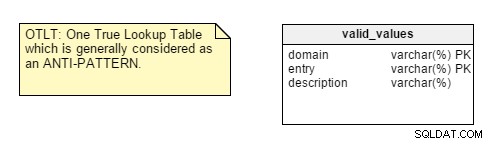
Както обикновено, има дискусия дали OTLT е работещо решение и добър модел на дизайн. Трябва да кажа, че съм на страната на анти-OTLT групата; тези таблици въвеждат множество въпроси. Можем да използваме аналогията с използването на единичен изброител, за да представим всички възможни стойности на всички възможни константи. Никога не съм виждал това досега.
Чести грешки в базата данни
от Джон Пол Ашенфелтър | Д-р Доб | 01 януари 2002 г.
Статията на г-н Ашенфелтър изброява огромни 15 често срещани грешки в базата данни. Има дори няколко грешки, които не се споменават често в други статии. За съжаление, описанията са сравнително кратки и няма примери. Заслугата на тази статия е, че списъкът обхваща много теми и може да се използва като „контролен списък“ с грешки, които трябва да се избягват. Въпреки че може да не ги класифицирам като най-важните грешки в базата данни, те със сигурност са сред най-често срещаните.
Положително е, че това е една от малкото статии, които споменават необходимостта от интернационализация на формати за данни като дата, валута и адрес. Един пример би бил добър тук. Може да бъде толкова просто като „уверете се, че държавата е колона с нула; в много страни няма държава, свързана с адрес.”
По-рано в тази статия споменах други опасения и някои подходи за подготовка за глобализация на вашата база данни, като часови зони и преводи (локализация). Фактът, че никоя друга статия не споменава загрижеността за валутата и форматите на датата, е обезпокоителен. Подготвени ли са нашите бази данни за глобално използване на нашите приложения?
Почетни споменавания
Очевидно има и други статии, които описват често срещани грешки и грешки в дизайна на база данни, но ние искахме да ви дадем широк преглед на различни ресурси. Можете да намерите допълнителна информация в статии като:
10 често срещани грешки в дизайна на база данни | Блог на MIS Class | 29 януари 2012 г.
10 често срещани грешки в дизайна на база данни | IDG.se | 24 юни 2010 г.
Онлайн ресурси:Откъде да започна? Къде да отида?
Както вече споменахме, този списък определено не е предназначен да бъде изчерпателен преглед на всяка онлайн статия, описваща грешки и грешки в дизайна на база данни. По-скоро сме идентифицирали няколко източника, които са особено полезни или имат специфичен фокус, който може да ви бъде полезен.
Моля, не се колебайте да препоръчате допълнителни статии.