Когато чуят какво правя, хората са склонни да ми задават един и същи въпрос:Можете ли да разработите система, която да предвижда резултати от футболни мачове? Или резултати от олимпийски медали? Лично аз не вярвам много на прогнозите. И все пак, ако разполагахме с голямо количество исторически данни и подходящи индикатори, със сигурност бихме могли да проектираме система, която да ни помогне да излезем с по-точни предположения. В тази статия ще разгледаме модел, който може да съхранява резултатите от мачове и турнири.
Този модел е фокусиран основно върху европейските футболни (футболни) мачове, статистика и резултати, но може лесно да бъде настроен, за да побере много други спортове. Основната ми мотивация за тази статия бяха двете големи футболни събития тази година:Европейското първенство на УЕФА 2016, което току-що се случи, и Летните олимпийски игри 2016, които се случват в момента.
Какво знаем преди началото на турнира?
Преди турнира да започне, ние знаем почти всичко за него — освен най-важното:кой ще спечели. Нека накратко посочим точно това, което вече знаем:
- Датите на началото и края на турнира
- Места, където ще се проведат мачовете
- Точните часове, в които ще започнат мачовете
- Кои отбори са се класирали за турнира
- Играчите на всеки от тези отбори
- Миналото представяне на всеки играч и текущата му форма
Какви подробности за съвпадението искаме да съхраняваме?
Турнирите се състоят от множество мачове. Преди да съхраним подробности за мача, трябва да:
- Свържете всеки мач с турнира
- Запишете етапа на турнира, когато се е играл мачът (напр. групова фаза, полуфинали)
Също така трябва да съхраняваме подробности за единични съвпадения, включително:
- Отборите, участващи в мача
- Начални състави и смени
- Събития на мача (във футбола това са:гол, дузпа, фал, жълт картон и т.н.)
- Краен резултат
- Действията на играчите по време на мача
Ще използваме тези данни за заснемане на всички важни събития от мача. Сравняването на представянето на играч преди и по време на мача може да доведе до определени заключения. Може би не бихме могли да предвидим крайните резултати от тяхното представяне (т.е. победа или загуба), но статистиката със сигурност може да ни помогне да правим предположения с известна степен на надеждност.
Представяме модела
Моделът е разделен на четири основни области:
Tournament detailsMatch detailsEventsIndicators and Performance
Таблиците извън тези области са речници (sport , phase , position ), каталози (sport_event , team , player ) и единична връзка много към много (plays ).
Първо ще опишем некатегоризираните таблици и след това ще разгледаме отблизо всяка област.
Некатегоризираните таблици
Тези таблици са важни, защото таблиците и от четирите области ги използват като речници или каталози.

sport таблицата изброява всички спортове, които ще съхраняваме в нашата база данни. Тук вероятно ще имаме само един спорт, мъжки футбол, но тази таблица ни дава гъвкавостта да добавим подобни спортове (например женски футбол), ако е необходимо.

В sport_event таблица, ние ще съхраняваме събитията, свързани с нашите спортове. Един пример биха били „Олимпийските игри 2016“.
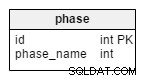
phase table е речник, който съдържа всички възможни етапи на турнира. Той съдържа стойности като „групова фаза“ , „осминадесет финала“ , „четвъртфинали“ , „полуфинали“ , „окончателно“ .
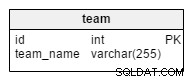
team таблицата е, както се досещате, прост списък с всички отбори. Възможните стойности са „Хърватия“ , „Полша“ , „САЩ“ и т.н. Ако използваме базата данни, за да съхраняваме информация за състезания в клуба или лигата, ще имаме и стойности като „Барселона“ , „Реал Мадрид“ , „Байерн“ , „Манчестър Юнайтед“ и др.
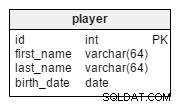
В player таблица, ще съхраняваме записи за всички играчи, принадлежащи към съответните отбори.
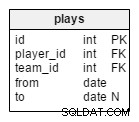
plays таблицата е единствената ни връзка много към много и тя свързва играчи и отбори. Един играч може да принадлежи към повече от един отбор едновременно (например национален отбор и клуб), но по време на турнир той очевидно ще играе само за един отбор.
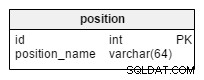
И накрая, имаме position маса. Този прост речник ще съхранява списък с всички необходими позиции. Във футбола те включват вратар, централен халф, нападател и др.
Подробности за турнира
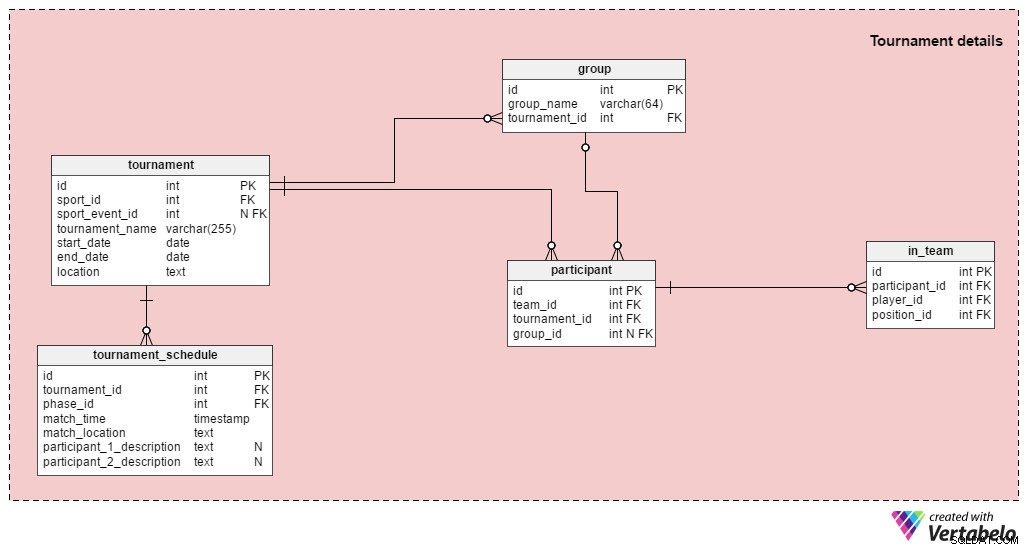
Забележка: Ако просто искате да съхранявате резултатите от единични съвпадения, не е необходимо да използвате този раздел.
Един турнир се състои от повече от един мач; както УЕФА Евро 2016, така и футболните събития на Летните олимпийски игри през 2016 г. са турнири. Както казахме преди, можем да съхраняваме един мач в нашата база данни, но също така можем да свържем мачове със съответните им турнири. Таблиците в секцията Турнир са:
tournament– Това съдържа всички основни данни за турнира:спорт, начална дата, крайна дата и т.н. Също така трябва да съхраним името на турнира и описание на това къде се провежда.sport_event_idатрибутът не е задължителен, тъй като турнирът не трябва да се свързва с по-голямо събитие (като Олимпийските игри).group– Това изброява всички групи в този турнир. УЕФА Евро 2016 имаше шест групи от A до F.participant– Това са отборите, които играят в турнира; всеки участник може да бъде причислен към група. Повечето турнири започват с групова фаза и след това продължават до фаза на елиминациите (например Евро на УЕФА, Световно първенство на УЕФА, олимпийски футбол). Някои турнири ще имат само групова фаза (например национални лиги), докато други ще имат само фаза на елиминациите (например национални купи).in_team– Тази таблица предоставя релация много към много, която съхранява информация за играчите, регистрирани за този турнир, и техните очаквани позиции.tournament_schedule– Според мен това е най-интересната таблица в този раздел. Списъкът с всички игри, изиграни по време на този турнир, се съхранява тук.tournament_idатрибутът обозначава към кой турнир принадлежи всеки мач иphase_idатрибутът определя фазата, през която ще се проведе мачът. Също така ще съхраняваме мястото на мача и часа, когато той започва. И двамата участници ще бъдат описани с текстови полета. Когато груповата фаза приключи, ще знаем всички мачове за елиминационния кръг. Например в началото на УЕФА Евро 2016 знаехме, че победителят от група E (1E) ще играе срещу вицешампиона от група D (2D). След като бяха изиграни и трите кръга в груповата фаза, тази двойка беше Италия срещу Испания.
Подробности за мача
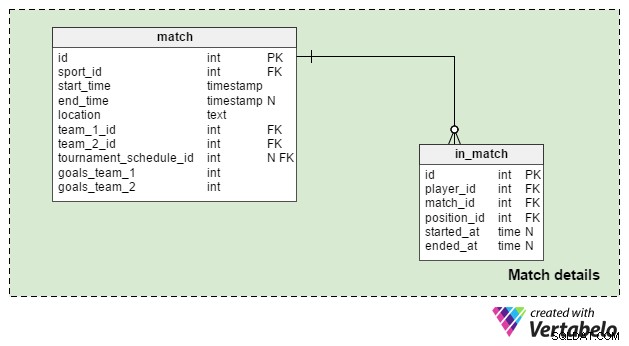
Match details областта се използва за съхраняване на данни за единични съвпадения. Ще използваме две таблици:
match– Това съдържа всички подробности за един мач; този мач може да бъде свързан с турнир, но може да бъде и единична игра. Така чеtournament_schedule_idатрибутът не е задължителен и ние ще съхранявамеsport_id,start_timeиlocationатрибути отново тук. Ако мачът е част от турнир, тогаваtournament_schedule_idще бъде присвоена стойност.team_1_idиteam_2_idатрибутите са препратки към отборите, участващи в мача.goals_team_1иgoals_team_2атрибутите съдържат резултата от съвпадението. Те са задължителни и трябва да имат „0“ като стойност по подразбиране и за двете.in_match– Тази таблица е списък на всички играчи, които са регистрирани за този мач; играчите, които не участват, ще имат NULL вstarted_atатрибут, докато играчите, които са влезли като замени, ще иматstarted_at> 0 . Ако играч е заменен, той ще имаended_atатрибут, който съответства наstarted_atатрибут на играча, който ги е заменил. Ако играчът е останал за целия мач, неговиятended_atатрибутът ще има същата стойност катоend_timeатрибут.
Събития на мача
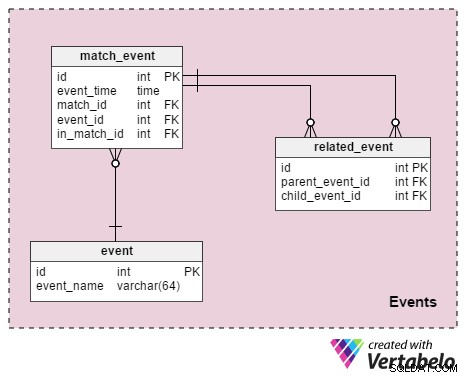
Този раздел е предназначен да съхранява всички подробности или събития, случили се по време на играта. А таблиците са:
event– Това е речник, който изброява всички събития, които искаме да съхраняваме. Във футбола това са ценности като „извършен фал“ , „претърпяна грешка“ , „жълт картон“ , „червен картон“ , „свободен удар“ , „наказание“ , „цел“ , „офсайд“ , „замяна“ , „играчът е изгонен от мача“ .match_event– Това свързва събитията с мача. Ще съхранявамеevent_timeкакто и информация за играча, свързана с това събитие (in_match_id).related_event– Това е, което обединява информацията за събитието. За да обясним, нека разгледаме пример, когато играч А фаулира играч B. Ще вмъкнем запис вmatch_eventтаблица, която показва, че играч А е извършил фаул и друга, която показва, че играч Б е претърпял фаул. Ще добавим и запис къмrelated_eventтаблица, където „извършеният фал“ ще бъде родителят, а „изтърпеният фал“ ще бъде детето. Ще запишем и резултатите от фаула:жълт картон, свободен удар или дузпа и може би гол.
Индикатори и производителност
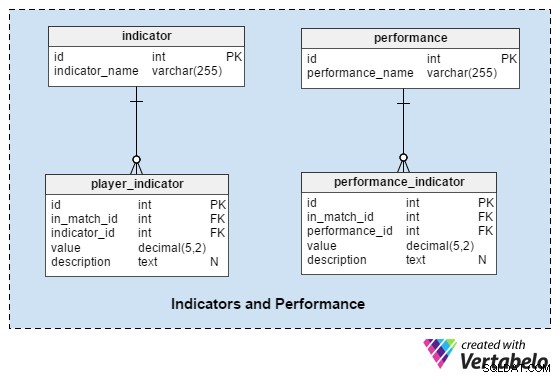
Този раздел трябва да ни помогне да анализираме играчите и отборите преди и след мача.
Индикаторът indicator таблицата е речник с предварително дефиниран набор от индикатори за всеки играч преди всеки мач. Тези индикатори трябва да описват текущата форма на играча. Този списък може да съдържа стойности като:„брой голове в последните 10 мача“ , “средно изминато разстояние в последните 10 мача” , “брой спасявания за GK в последните 10 мача” .
performance речникът е много подобен на indicator , но ще го използваме, за да съхраняваме само стойности, които са свързани с единичното съвпадение:„покрито разстояние“ , „точни пасове“ и др.
player_indicator и performance_indicator таблиците споделят почти идентична структура:
in_match_id– се отнася до играча, който участва в определен мачindicator_id/performance_id– препраща къмindicatorили „производствени речнициvalue– съхранява стойността за този индикатор (например играч, изминал 10,72 км разстояние)description– съдържа допълнително описание, ако е необходимо
Какво се случи по време на мача?
С всички тези въведени данни бихме могли лесно да получим подробности за мача, събития и статистика за всеки мач в нашата база данни.
Тази проста заявка ще върне основни подробности за предстоящо съвпадение:
SELECT team_1.`team_name`, team_2.`team_name`, `match`.`start_time`, `match`.`location` FROM `match`, `team` AS team_1, `team` AS team_2 WHERE `match`.`team_1_id` = team_1.`id` AND `match`.`team_2_id` = team_2.`id`
За да получите списък с всички събития в играта по време на определен мач, ще използваме заявката по-долу:
SELECT `event`.`event_name`, `match_event`.`event_time`, `player`.`first_name`, `player`.`last_name` FROM `match`, `match_event`, `event`, `in_match`, `player` WHERE `match_event`.`match_id` = `match`.`id` AND `event`.`id` = `match_event`.`event_id` AND `in_match`.`id` = `match_event`.`in_match_id` AND `player`.`id` = `in_match`.`player_id` AND `match`.`id` = @match ORDER BY `match_event`.`event_time` ASC
Има множество допълнителни заявки, за които се сещам; лесно е да направите анализ, когато разполагате с данните. Ако сте измерили и съхранили голям брой индикатори и данни за представянето на играчите, може да сте в състояние да свържете тези параметри с крайния резултат. Аз лично не вярвам в подобни прогнози; има фактор късмет по време на мачове, плюс много други фактори, които не можете да знаете, докато играта не започне. Все пак, ако имате голям набор от данни и много параметри, шансът ви за по-точни прогнози се увеличава.
Моделът, представен в тази статия, ни позволява да съхраняваме мачове, подробности за мача и история на представянето на всеки играч. Можем също да зададем индикатори за формата за всеки играч преди мача. Съхраняването на достатъчно подробности трябва да ни осигури повече параметри, на които да базираме нашите предположения. Не казвам, че можем да предвидим резултата от мача, но бихме могли да се забавляваме с него.
Бихме могли също така лесно да настроим този модел, за да съхраняваме данни за други спортове. Тези промени не трябва да са твърде сложни. Добавяне на sport_id атрибутът към речниците трябва да свърши работа. Все пак мисля, че би било разумно да има нов екземпляр за всеки различен спорт.



