Отказът е способността на системата да продължи да работи, дори ако възникне някаква повреда. Това предполага, че функциите на системата се поемат от вторични компоненти, ако първичните компоненти се повредят или ако е необходимо. Така че, ако го преведете в PostgreSQL мулти-облачна среда, това означава, че когато основният ви възел се провали (или друга причина, както ще споменем в следващия раздел) във вашия основен доставчик на облак, трябва да можете да популяризирате възела в режим на готовност във вторичния, за да поддържат системите работещи.
По принцип всички доставчици на облак ви дават опция за превключване при отказ в един и същ доставчик на облак, но е възможно да се наложи да преминете към друг различен доставчик на облак. Разбира се, можете да го направите ръчно, но можете също да използвате някои от функциите на ClusterControl, като автоматично отказване или насърчаване на подчинено действие, за да направите това по приятелски и лесен начин.
В този блог ще видите защо трябва да се нуждаете от отказ, как да го направите ръчно и как да използвате ClusterControl за тази задача. Ще приемем, че имате инсталирана инсталация на ClusterControl и вече имате създаден клъстер на база данни в два различни доставчици на облак.
За какво се използва отказът?
Има няколко възможни употреби на отказ.
Основна грешка
Ако основният ви възел не работи или дори ако основният ви доставчик на облак има някои проблеми, трябва да преминете при отказ, за да гарантирате наличността на вашата система. В този случай може да е необходимо наличието на автоматичен начин за това, за да се намали времето за престой.
Миграция
Ако искате да мигрирате системите си от един доставчик на облак към друг, като намалите времето на престой, можете да използвате отказ. Можете да създадете реплика във вторичния доставчик на облак и след като бъде синхронизирана, трябва да спрете системата си, да популяризирате своята реплика и да преминете при отказ, преди да насочите системата си към новия първичен възел във вторичния облачен доставчик.
Поддръжка
Ако трябва да изпълните някаква задача за поддръжка на своя основен възел на PostgreSQL, можете да популяризирате своята реплика, да изпълните задачата и да изградите отново стария си основен възел като резервен възел.
След това можете да популяризирате стария първичен и да повторите процеса на повторно изграждане на възел в режим на готовност, връщайки се към първоначалното състояние.
По този начин бихте могли да работите на сървъра си, без да рискувате да бъдете офлайн или да загубите информация, докато изпълнявате каквато и да е задача по поддръжката.
Надстройки
Възможно е да надстроите вашата версия на PostgreSQL (от PostgreSQL 10) или дори да надстроите операционната си система, използвайки логическа репликация с нулев престой, както може да се направи с други двигатели.
Стъпките ще бъдат същите като при мигриране към нов облачен доставчик, само че вашата реплика ще бъде в по-нова версия на PostgreSQL или OS и трябва да използвате логическа репликация, тъй като не можете да използвате стрийминг репликация между различни версии.
Отказът не е само за базата данни, но и за приложението. Как знаят към коя база данни да се свържат? Вероятно не искате да променяте приложението си, тъй като това само ще удължи времето ви за престой, така че можете да конфигурирате Load Balancer, че когато основният ви възел не работи, той автоматично ще сочи към сървъра, който е бил повишен.
Наличието на един екземпляр на Load Balancer не е най-добрият вариант, тъй като може да се превърне в единствена точка на отказ. Следователно, можете също да приложите отказоустойчивост за Load Balancer, като използвате услуга като Keepalived. По този начин, ако имате проблем с основния си Load Balancer, Keepalived ще мигрира виртуалния IP към вашия вторичен Load Balancer и всичко ще продължи да работи прозрачно.
Друга вариант е използването на DNS. Чрез популяризиране на възела в режим на готовност във вторичния облачен доставчик, вие директно променяте IP адреса на името на хоста, който сочи към основния възел. По този начин избягвате да се налага да променяте приложението си и въпреки че не може да се направи автоматично, това е алтернатива, ако не искате да внедрите Load Balancer.
Как ръчно да преодоля PostgreSQL при отказ
Преди да извършите ръчно преминаване при отказ, трябва да проверите състоянието на репликация. Възможно е, когато трябва да преминете към отказ, възелът в режим на готовност да не е актуален поради повреда в мрежата, високо натоварване или друг проблем, така че трябва да се уверите, че вашият възел в режим на готовност разполага с всички (или почти цялата) информацията. Ако имате повече от един възел в режим на готовност, трябва също да проверите кой е най-напредналият възел и да го изберете за превключване при отказ.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Когато изберете новия основен възел, първо можете да изпълните командата pg_lsclusters, за да получите информацията за клъстера:
$ pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
12 main 5432 online,recovery postgres /var/lib/postgresql/12/main log/postgresql-%Y-%m-%d_%H%M%S.logСлед това просто трябва да изпълните командата pg_ctlcluster с действието за популяризиране:
$ pg_ctlcluster 12 main promoteВместо предишната команда, можете да изпълните командата pg_ctl по този начин:
$ /usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main/
waiting for server to promote.... done
server promotedСлед това вашият резервен възел ще бъде повишен до основен и можете да го потвърдите, като изпълните следната заявка в новия си основен възел:
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Ако резултатът е “f”, това е вашият нов основен възел.
Сега трябва да промените IP адреса на основната база данни във вашето приложение, Load Balancer, DNS или реализацията, която използвате, което, както споменахме, ръчната промяна на това ще увеличи времето за престой. Трябва също така да се уверите, че връзката ви между възможните доставчици работи правилно, приложението има достъп до новия основен възел, потребителят на приложението има привилегии за достъп до него от друг доставчик на облак и трябва да изградите отново възела(ите) в режим на готовност в от дистанционното или дори в локалния доставчик на облак, за да се репликира от новия основен, в противен случай няма да имате нова опция за превключване при отказ, ако е необходимо.
Как да преобърна PostgreSQL с помощта на ClusterControl
ClusterControl има редица функции, свързани с репликацията на PostgreSQL и автоматичното преминаване при отказ. Ще приемем, че имате инсталиран вашия сървър ClusterControl и той управлява вашата Multi-Cloud PostgreSQL среда.
С ClusterControl можете да добавите толкова възли в режим на готовност или възли на Load Balancer, колкото са ви необходими, без никакво мрежово IP ограничение. Това означава, че не е необходимо възелът в режим на готовност да е в същата мрежа на първичен възел или дори в същия доставчик на облак. Що се отнася до отказ, ClusterControl ви позволява да го правите ръчно или автоматично.
Ръчно превключване при отказ
За да извършите ръчно преминаване при отказ, отидете на ClusterControl -> Изберете Cluster -> Nodes и в Действията на възел на един от вашите възли в режим на готовност изберете "Promote Slave".
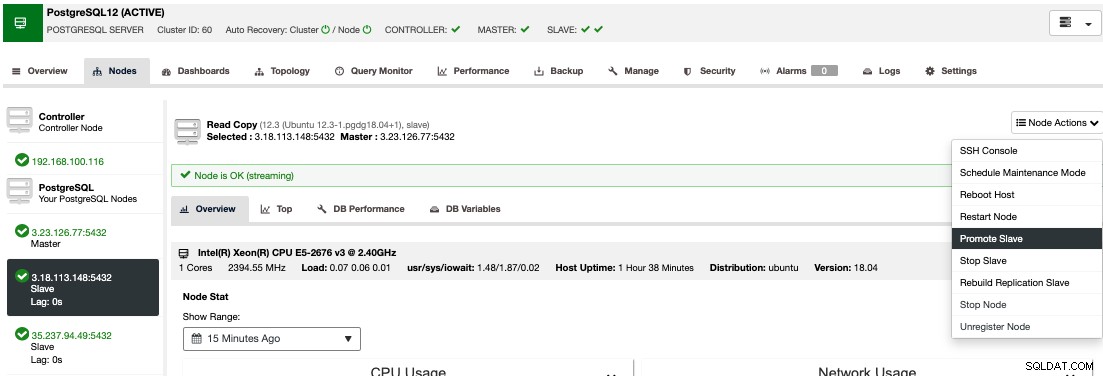
По този начин след няколко секунди вашият възел в режим на готовност става основен, и това, което беше основното ви преди, се превръща в режим на готовност. Така че, ако вашата реплика е била в друг доставчик на облак, новият ви основен възел ще бъде там, работещ и работещ.
Автоматично отказване
В случай на автоматично преминаване при отказ, ClusterControl открива неизправности в основния възел и популяризира възел в режим на готовност с най-актуалните данни като нов основен. Той също така работи на останалите възли в режим на готовност, за да се репликират от този нов първичен.

При включена опция „Autorecovery“, ClusterControl ще извърши автоматично превключване като както и да ви уведомя за проблема. По този начин вашите системи могат да се възстановят за секунди и без ваша намеса.
ClusterControl ви предлага възможността да конфигурирате бял списък/черен списък, за да дефинирате как искате вашите сървъри да бъдат взети (или да не бъдат взети) предвид при вземане на решение за основен кандидат.
ClusterControl също така извършва няколко проверки върху процеса на отказ, например, по подразбиране, ако успеете да възстановите стария си неуспешен основен възел, той няма да бъде въведен автоматично в клъстера, нито като основен, нито като режим на готовност, ще трябва да го направите ръчно. Това ще избегне възможността за загуба на данни или несъответствие в случай, че вашият режим на готовност (който сте промотирали) е бил забавен в момента на неуспеха. Може също да искате да анализирате проблема в детайли, но когато го добавите към своя клъстер, е възможно да загубите диагностична информация.
Балансьори на натоварване
Както споменахме по-рано, Load Balancer е важен инструмент, който трябва да вземете предвид при преодоляването на отказ, особено ако искате да използвате автоматично преминаване при отказ в топологията на базата си данни.
За да бъде преминаването при отказ да бъде прозрачно както за потребителя, така и за приложението, имате нужда от компонент между тях, тъй като не е достатъчно за популяризиране на нов първичен възел. За това можете да използвате HAProxy + Keepalived.
За да приложите това решение с ClusterControl, отидете на Cluster Actions -> Добавяне на Load Balancer -> HAProxy във вашия PostgreSQL клъстер. В случай, че искате да приложите отказ за вашия Load Balancer, трябва да конфигурирате поне две HAProxy инстанции и след това можете да конфигурирате Keepalived (Действия на клъстер -> Добавяне на Load Balancer -> Keepalived). Можете да намерите повече информация за това внедряване в тази публикация в блога.
След това ще имате следната топология:

HAProxy е конфигуриран по подразбиране с два различни порта, един за четене-запис и един само за четене.
В порта за четене и запис имате основния си възел като онлайн, а останалите възли като офлайн. В порта само за четене имате онлайн както основния, така и резервния възел. По този начин можете да балансирате трафика за четене между възлите. При запис ще се използва портът за четене-запис, който ще сочи към текущия първичен възел.

Когато HAProxy открие, че един от възлите, първичен или в режим на готовност, е не е достъпен, автоматично го маркира като офлайн. HAProxy няма да изпраща трафик към него. Тази проверка се извършва от скриптове за проверка на състоянието, които са конфигурирани от ClusterControl по време на внедряването. Те проверяват дали екземплярите са актуални, дали са в процес на възстановяване или са само за четене.
Когато ClusterControl популяризира нов първичен възел, HAProxy маркира стария като офлайн (и за двата порта) и поставя популяризирания възел онлайн в порта за четене и запис. По този начин вашите системи продължават да работят нормално.
Ако активният HAProxy (който е присвоил виртуален IP адрес, към който се свързват системите ви) не успее, Keepalived автоматично мигрира този виртуален IP към пасивния HAProxy. Това означава, че вашите системи могат да продължат да функционират нормално.
Репликация от клъстер в клъстер в облака
За да имате многооблачна среда, можете да използвате действието ClusterControl Add Slave върху вашия PostgreSQL клъстер, но също и функцията за репликация от клъстер към клъстер. В момента тази функция има ограничение за PostgreSQL, което ви позволява да имате само един отдалечен възел, но ние работим за премахването на това ограничение скоро в бъдеща версия.
За да го разгърнете, можете да проверите секцията „Репликация от клъстер към клъстер в облака“ в тази публикация в блога.

Когато е на място, можете да популяризирате отдалечения клъстер, който ще генерира независим PostgreSQL клъстер с първичен възел, работещ на вторичния доставчик на облак.

Така че, в случай че имате нужда от него, ще имате работещ същия клъстер в нов доставчик на облак само за няколко секунди.
Заключение
Наличието на процес на автоматичен отказ е задължителен, ако искате да имате по-малко престой, а също така използването на различни технологии като HAProxy и Keepalived ще подобри това преминаване при отказ.
Функциите на ClusterControl, които споменахме по-горе, ще ви позволят бързо да превключвате между различни доставчици на облак и да управлявате настройката по лесен и удобен начин.
Най-важното нещо, което трябва да вземете предвид, преди да извършите процес на отказ между различни доставчици на облак, е свързаността. Трябва да се уверите, че вашето приложение или връзките с вашата база данни ще работят както обикновено, като използвате основния, но също и вторичния доставчик на облак в случай на отказ, и от съображения за сигурност трябва да ограничите трафика само от известни източници, така че само между облака Доставчици и не го позволяват от външен източник.