Сватбите често са придружени от веселие и празнуване, с много гости, храна, напитки, музика и танци. Но всичко това не може да се случи без подходяща подготовка и координация. Нека разгледаме по-отблизо как моделирането на данни може да ни помогне да организираме по-добре сватба, така че всичко да върви гладко.
Предварителен фон
Въпреки че почти всички сме наясно как изглежда типичната сватбена церемония, не може да навреди да разгледаме накратко някои аспекти, които потенциално биха могли да повлияят на нашия модел на данни.
Сватбени партньори
Въпреки че повечето традиционни култури ще имат церемонии между мъж и жена, еднополовите бракове се извършват и в други общества. Нашият модел на данни трябва да бъде проектиран по такъв начин, че да побере всички възможности.
Мащаб и сложност
Сватбените церемонии се различават значително по техния размер, продължителност и сложност. Някои са малки, скромни поводи, но други са грандиозни празненства. В Хърватия, например, можете да имате обикновена сватбена церемония, при която двойка се венчава в кметството, разменя пръстените и обетите си пред гостите си и или да присъства на вечеря след церемонията, или да се прибира вкъщи. В други страни сватбите могат да бъдат доста сложни:могат да включват ергенски/момински партита, преговори, вечери, множество церемонии и т.н. В някои случаи тези церемонии могат да продължат няколко дни и да се проведат на няколко различни места! Отново нашият модел на данни трябва да бъде подготвен да се справи с тези ситуации.
Краен резултат и разходи
В повечето случаи двойката се жени след тържеството и получава фактура за всички разходи (наем, храна и напитки, група и т.н.). Те могат да решат да наемат агенция, която да се погрижи за всички тези разходи вместо тях, или могат да решат да се справят с всичко сами. Така или иначе, ние трябва да отчетем тези ситуации.
Моделът на данните:Общ преглед
Нашият модел на данни за тази статия се състои от пет раздела:
- Местоположения
- Партньори, продукти и услуги
- Сватби
- Участници
- Фактури
Ще обсъдим подробно всяка от тези области в реда, в който са изброени по-горе. Докато работим по разработването на нашия модел на данни, ще поемем ролята на агенцията, организираща сватбата.
Раздел 1:Местоположения
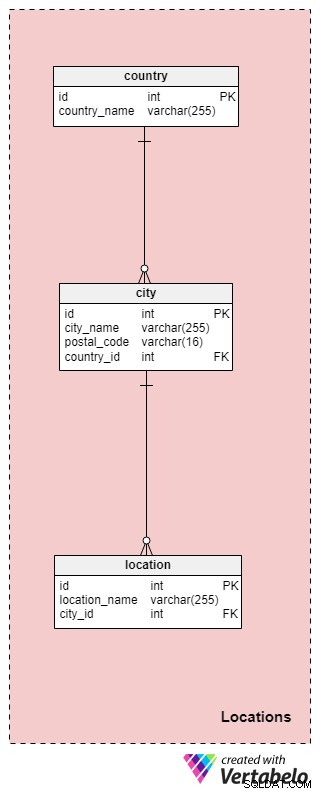
Locations Разделът включва универсални таблици, които могат да се използват в много други модели на данни. Както отбелязахме по-рано, цялата сватбена церемония може да се проведе само на едно място или потенциално да обхваща няколко места. Нека обсъдим таблиците в този раздел по-подробно.
country таблицата съхранява информация за страната, в която се провежда сватбата. В повечето случаи тази държава ще съответства на местоположението на нашата агенция, но това може да не е така, ако работим в международен план. Всяка държава в тази таблица е уникално дефинирана от своя country_name .
След това трябва да съхраним списъка с всички градове и/или села, където ще бъде организирана сватбата. Тази информация ще се съхранява в city маса. За всеки град ще съхраняваме неговото име и пощенски код, както и държавата, в която се намира.
Последната таблица в тази тематична област е location . Местоположенията са по-конкретни, като кметства, църкви, паркове и т.н. За всяко местоположение ще съхраняваме неговото име и препратка към идентификатора на града, в който се намира. Комбинацията от тези два атрибута формира уникалния ключ за тази таблица.
За местоположенията, имайте предвид, че тук сме възприели консервативен подход, за да избегнем покриването на необичайните случаи, в които церемонията се провежда, да речем, във влак или самолет (в този случай „местоположението“ може да включва множество градове). Ако искаме да покрием тези случаи, ще трябва да направим някои промени в нашия модел.
Раздел 2:Партньори, продукти и услуги

Преди да преминем към централната част на нашия модел на данни, трябва да съхраним списъка на всички партньори, с които работим, както и продуктите и услугите, които предлагат. За да постигнем това, ще използваме пет таблици.
Първо, списъкът с всички партньори, с които работим, се съхранява в partner речник. За всеки партньор ще съхраняваме неговия уникален partner_code и partner_name .
Разбира се, нашите партньори ще предоставят сватбени услуги, които могат да включват кетъринг, организиране на групи, настройка на аудио и видео оборудване, предоставяне на поддръжка под наем и много други. По същество всичко, за което се сетите, може потенциално да бъде свързано със сватба по някакъв начин. Ще съхраняваме този списък с услуги в service речник. За всяка услуга ще съхраняваме:
service_code– стойност, която ще използваме вътрешно, за да обозначим уникално конкретна услуга.service_name– име на услугата. Имайте предвид, че различните услуги могат да споделят едно и също име. Това би се случило, ако двама от нашите партньори предлагат една и съща услуга, което е доста вероятно. Би било дори желателно да използват едно и също име за същия тип услуга, защото това би направило сравняването на цените за едни и същи услуги много по-лесно.description– по избор текстово описание на услугата.picture– връзка към местоположението, където се съхранява свързаната услуга.price– текущата цена за тази услуга. Може да съдържа стойност NULL, ако цената не може да бъде определена, без първо да се оценят различни фактори, като например колко хора планират да присъстват на церемонията.
provides_service таблицата свързва партньорите със списъка на услугите, които предоставят. За всяка уникална комбинация от partner_id и service_id , ще съхраняваме подробно текстово описание на естеството на услугата, предоставяна от партньора, и дали услугата е налична в момента.
Нуждаем се и от таблици за съхраняване на информация за продуктите и отношенията им с партньорите. product таблицата следва същата логика като service таблица, освен, както подсказва името, тя е специфична за продуктите. В тази таблица ще съхраняваме всички възможни продукти, които са от съществено значение за повечето сватбени церемонии, като пръстени, тоалети, декорации, цветя, мебели и др.
Последната таблица в този раздел е provides_product маса. Работи точно като provides_service таблица, освен че е специфична за продукти, а не за услуги. Посочва кой от нашите партньори предлага въпросния продукт.
Раздел 3:Сватби
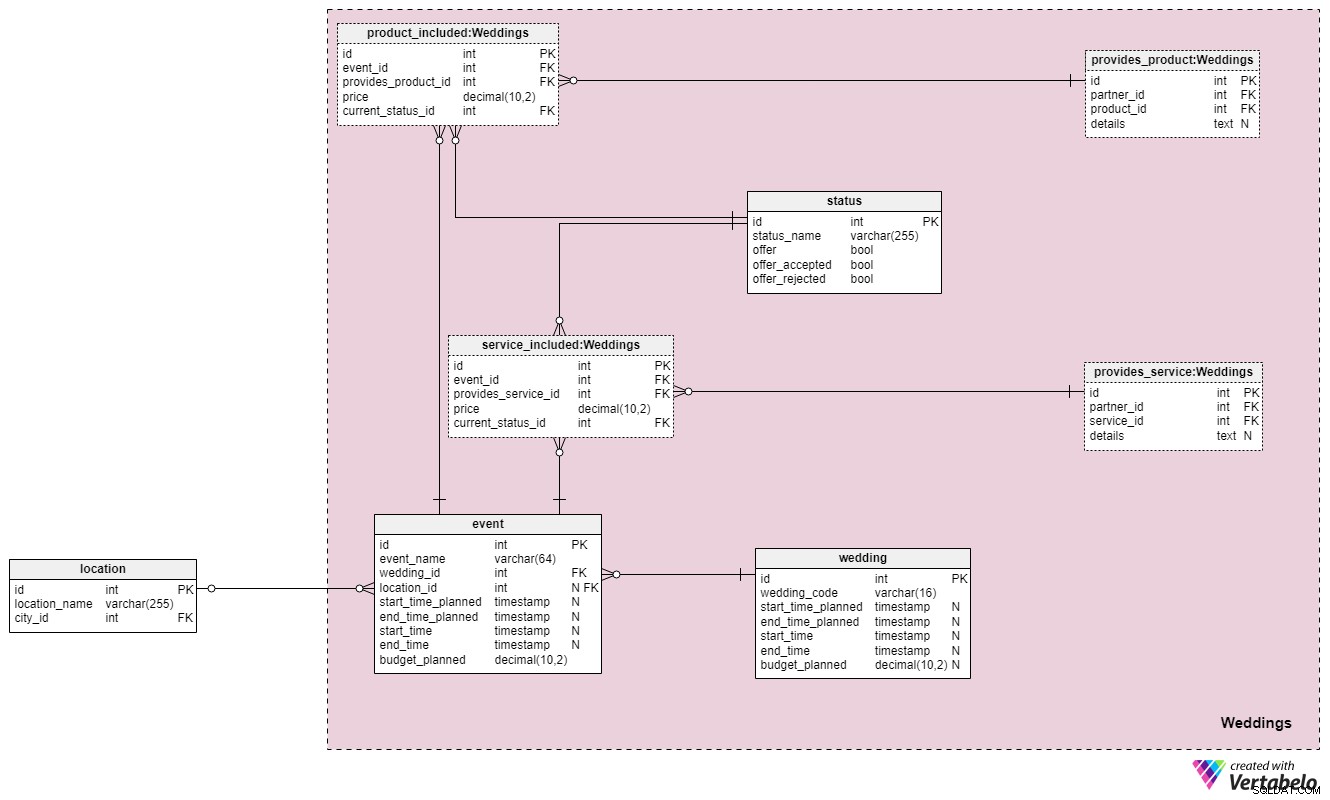
Най-накрая стигнахме до сърцето на нашия модел на данни – Weddings раздел. Той съдържа пет нови таблици, които препращат към таблиците на други раздели. Имайте предвид, че собствените таблици на този раздел също ще бъдат посочени в следващите части на нашия модел.
В wedding таблица, ще съхраняваме пълния списък на всички сватби, в които участваме/сме участваме в организирането. На всяка сватба ще бъде присвоен собствен уникален wedding_code . Ние също така ще съхраняваме планираните начални и крайни часове за цялата церемония и ще актуализираме реалните начални и крайни часове, когато тази информация стане достъпна. Освен това ще съхраняваме budget_planned стойност, така че да имаме поне оценка колко ще струва всичко това. Всички други подробности, свързани със сватбата, се съхраняват в други области на модела на данни, така че това е всичко, от което наистина се нуждаем засега.
Идеята тук е всяка сватба да се третира като поредица от събития. Събитията от своя страна ще бъдат свързани с оферти за желани продукти/услуги, отхвърлени и приети оферти и други важни подробности. За да ви дадем по-добра представа как работи всичко това, бихме могли да разделим цялата сватба на следните събития:фаза на планиране, ергенско/моминско парти, церемония и след парти/вечеря. Разбира се, това са само някои от най-често срещаните сватбени събития. Всички сватбени събития се съхраняват в таблицата със събития. event ще има уникален идентификатор.
Всяко събитие е свързано с една сватба и ще бъде свързано или с едно място, или с нито една. Последният случай възниква, ако събитието е по-концептуално , като фазата на планиране (тъй като няма едно място, където трябва да се проведе). Както при самата сватбена церемония, събитието ще има планирани и реални начални/крайни часове, както и планиран бюджет. Имайте предвид, че тук сме опростили нещата по отношение на местоположенията. Ако събитията включват множество местоположения, ще трябва да коригираме нашия модел на данни.
Продължавайки напред, искаме да съхраняваме всички услуги и продукти, които са свързани със събитие. За да го направим, ще използваме три таблици:status , product_included и service_included .
status table е речник, който следи всички състояния, свързани с продукти и услуги за определено събитие. Той включва променливи за флаг, които обозначават дали даден продукт/услуга е бил предложен, приет или отхвърлен. За всеки запис в тази таблица ще съхраняваме уникален status_name .
Останалите две таблици в този раздел, озаглавени product_included и service_included , си приличат структурно и концептуално. За всяко събитие ще съхраняваме списъка на предлаганите продукти и услуги и ще променим статуса им, ако бъдат приети или отхвърлени. За всеки запис в тези две таблици ще съхраняваме следните общи атрибути:
event_id– препратка към свързаното събитие.provides_product_id/provides_service_id– препратки към таблиците с продукти/услуги, които нашите партньори предлагат.price– предложена цена за продукта/услугата. Тази цена може да се различава от стандартната цена, която имаме в архива, ако предложим специална оферта.current_status_id– препратка къмstatusречник, показващ дали този запис е бил предложен, приет или отхвърлен.
Раздел 4:Участници
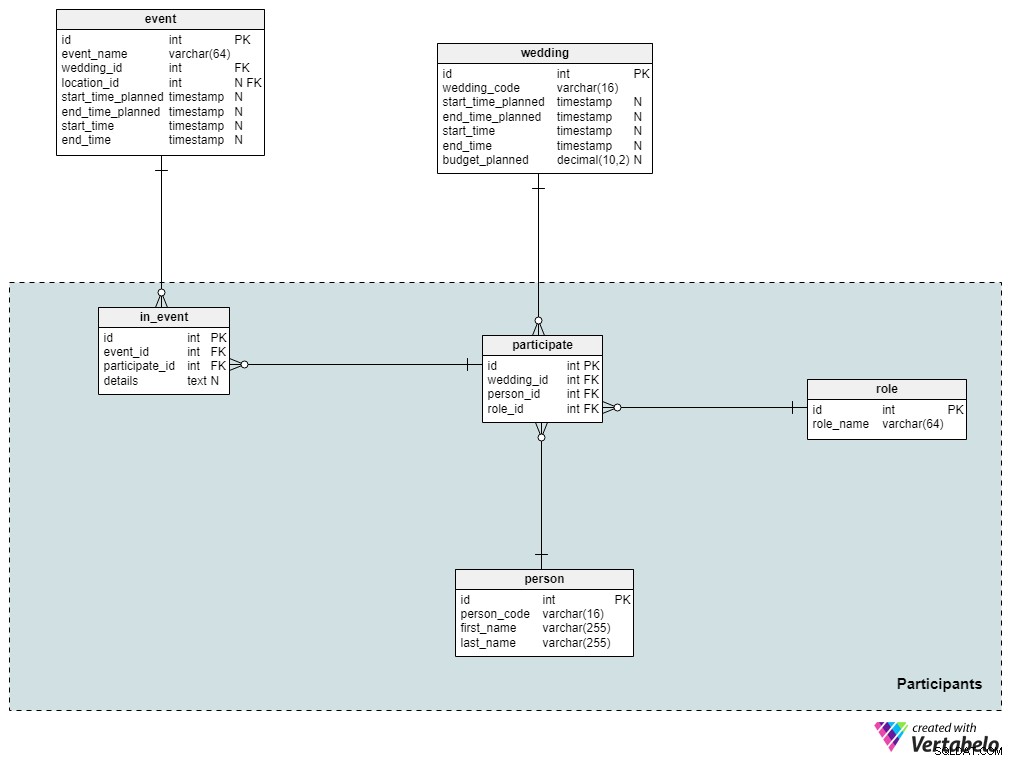
Ако организирате голяма сватба, има вероятност да сте запознати с повечето гости, които планират да присъстват. Разбира се, гостите, които каните – независимо дали са ваши приятели или роднини – вероятно ще доведат други хора, които не познавате лично, като техни приятели или колеги. В този раздел ще съхраняваме пълния списък на гостите, които са били поканени на сватбата, както и техните роли.
person таблицата съдържа списък на всички лица, които са част от сватбата. За всеки човек ще съхраняваме неговия уникален person_code и име и фамилия. Разбира се, можем да добавим повече подробности, ако желаем.
След това ще дефинираме всички възможни роли, които човек може да поеме по време на сватба. Тези роли включват „гост“, „кум“, „кум“, „шаферка“, „булка“, „младоженец“ и т.н. За всяка роля ще съхраняваме само уникалния role_name в тази таблица. Човек може да поеме само една роля за конкретна сватба.
След това ще свържем сватбите с техните участници. Обърнете внимание, че participate таблицата съдържа само препратки към таблиците wedding , person , и role . Комбинацията от wedding_id и person_id служи като алтернативен ключ за тази таблица.
Сватбата ще се състои от няколко събития, но не всички участници ще участват в тях. Следователно трябва да съхраняваме тази информация отделно. В in_event таблица, ние ще съхраняваме уникални двойки външни ключове, препращащи към таблиците event и participate . Цялата допълнителна информация ще се съхранява в details приписван текст.
Раздел 5:Фактури
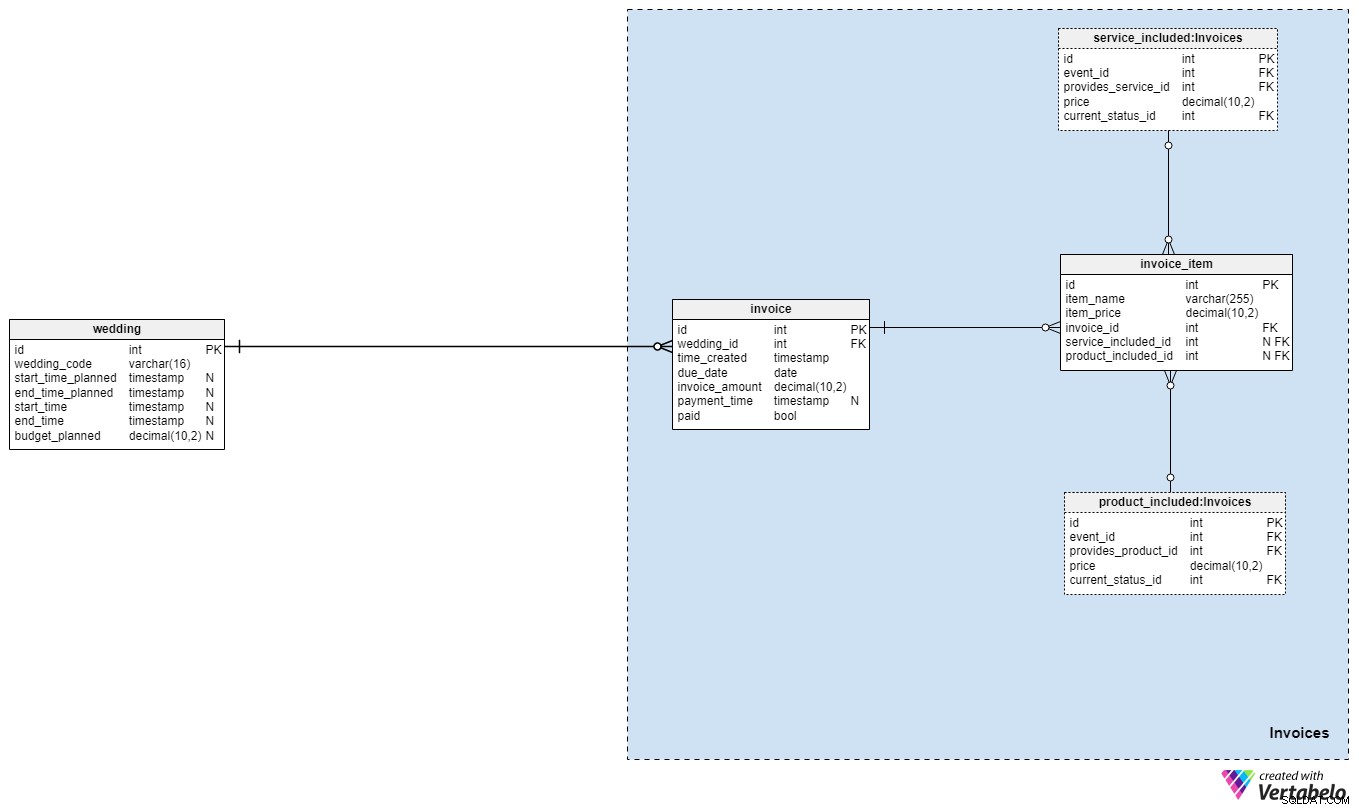
Почти сме готови! Последният раздел от нашия модел на данни ни позволява да проследяваме разходите, свързани със сватбата. Вълнуващо, нали?
Обикновено генерираме една invoice на сватба, но бихме могли да генерираме и повече, ако трябва. Надяваме се, че общата сума, която фактурираме на двойката, ще съвпадне в голяма степен с планирания ни бюджет, но това може да не винаги е така. За всяка фактура ще съхраняваме следната информация:
wedding_id– препратка към сватбата, за която е издадена фактурата.time_created– времевата марка за генериране на фактурата.due_date– датата, до която трябва да бъде платена фактурата.invoice_amount– общата сума, която трябва да бъде платена.payment_time– клеймото за датата на действително извършване на плащането. Разбира се, този атрибут ще съдържа стойност NULL, докато не бъде извършено плащането.paid– флаг, обозначаващ дали фактурата е платена. Този атрибут ще бъде зададен на „Вярно“ веднага след катоpayment_timeсе актуализира.
Последната таблица в нашия модел се отнася до самите фактурирани артикули. Ще ги съхраняваме в invoice_item маса. За всеки запис ще съхраняваме следните подробности:
item_name– избраното от нас име за конкретния артикул.item_price– цената, която е свързана с този конкретен артикул.invoice_id– идентификационният номер на свързаната фактура.service_included_id– идентификационният номер на услугата, към която е свързана фактурата. Този атрибут може да бъде зададен на NULL, ако въпросният артикул всъщност не е свързан с никаква услуга или ако е просто допълнителна такса, която сме приложили към фактурата.product_included_id– идентификационният номер на продукта, към който се отнася артикулът във фактурата. Този атрибут може да бъде зададен на NULL, ако въпросният артикул всъщност не е свързан с никакъв продукт или ако е просто допълнителна такса, която сме приложили към фактурата.
Резюме
Това до голяма степен обобщава всичко за този модел на данни! Още веднъж виждаме колко полезно е моделирането на данни при организирането на информация за компанията.
Както отбелязахме, има много неща, които сме пропуснали от нашия модел на данни с цел простота. Например, нашият модел в идеалния случай трябва да проследява историите на офертите, финансовите подробности и други.
Кажете ни по-долу, ако имате някакви предложения. Ще се радваме да чуем вашите мисли!