Животозастраховането е нещо, което всички се надяваме, че няма да ни трябва, но както знаем, животът е непредсказуем. В тази статия ще се съсредоточим върху формулирането на модел на данни, който животозастрахователна компания може да използва, за да съхранява своята информация.
Животозастраховането като концепция
Преди да започнем да обсъждаме действителния модел на данни за животозастрахователна компания, ще си припомним накратко какво представлява застраховката и как работи, за да имаме по-добра представа с какво работим.
Застраховането е доста стара концепция, която датира още преди Средновековието, когато много гилдии предлагаха полици за защита на своите членове в неочаквани ситуации. Дори известният астроном, математик, учен и изобретател Едмънд Халей се занимава със застраховане, работейки върху статистиката и нивата на смъртност, които формират гръбнака на съвременните застрахователни модели.
Защо трябва да плащате за застраховка? Идеята е доста проста – плащате определена сума (премия) в замяна на гаранцията на застрахователната компания, че вие или вашето семейство ще бъдете обезщетени финансово, ако нещо неочаквано се случи с вас или вашия имот. В случай на животозастрахователна полица, вие определяте бенефициент, който ще получи парична сума (ползата) в случай на вашата смърт. Идеята е тези пари да им помогнат да се възстановят от загубата си, особено ако смъртта ви създаде финансови проблеми.
Разбира се, застрахователните компании обикновено плащат много по-малко обезщетения, отколкото печелят от премии и от инвестиране на парите ви, да речем, на фондовия пазар. В противен случай щяха да фалират и цялата система ще се разпадне!
Това до голяма степен е същността на нещата. Сега, след като извадихме това от пътя, нека да продължим и да разгледаме модела на данни за типична животозастрахователна компания.
Моделът на данните:Общ преглед
Моделът на данни, с който ще работим, се състои от пет тематични области:
- Служители
- Продукти
- Клиенти
- Оферти
- Плащания
Ще покрием всеки от тези раздели по-подробно, в реда, в който са изброени по-горе.
Предметна област №1:Служители
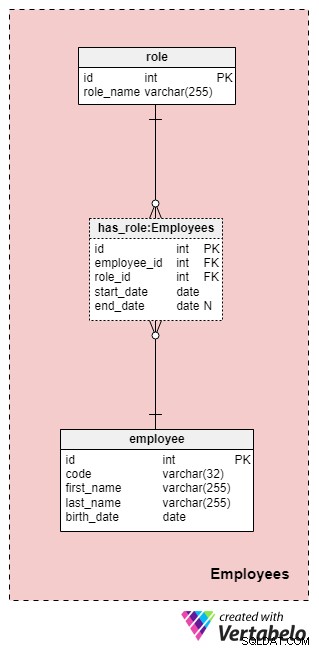
Тази област не е непременно специфична за този модел на данни, но все пак е много важна, тъй като таблиците, съдържащи се тук, ще бъдат посочени от други предметни области. За целите на нашия модел на данни на застрахователната компания, разбира се, ще трябва да знаем кой какво действие е извършил (например кой е представлявал нашата компания при работа с клиента/клиента, кой е подписал полицата и т.н.).
Списъкът на всички служители на компанията се съхранява в employee маса. За всеки служител ще съхраняваме следната информация:
code— уникален ключ, който идентифицира един-единствен служител. Тъй като кодът ще се използва като атрибут в други таблици, той ще служи като алтернативен ключ в тази таблица.first_nameиlast_name— съответно име и фамилия на служителя.birth_date— дата на раждане на служителя.
Разбира се, със сигурност бихме могли да включим много други атрибути, свързани със служителите в тази таблица, но тези четири са повече от достатъчни за момента. Ще следваме този модел в цялата статия и ще се опитаме да поддържаме нещата възможно най-прости, но имайте предвид, че определено можете да разширите този модел на данни, за да включите допълнителна информация.
Тъй като служителите могат да променят ролите си в нашата компания по всяко време, ще ни трябва таблица с речник, която да представя ролите на компанията, и таблица за съхраняване на стойности. Списъкът с всички възможни роли, които служителите могат да поемат в нашата животозастрахователна компания, се съхранява в role речник. Той има само един атрибут с име role_name който съдържа уникално идентифициращи стойности.
Ще свържем служителите и ролите с помощта на has_role маса. В допълнение към външните ключове employee_id и role_id , ще съхраняваме две стойности:start_date и end_date . Тези две стойности обозначават диапазона, в който тази фирмена роля е била активна за конкретен служител. end_date ще съдържа стойност null, докато не бъде определена крайна дата за ролята на този служител. Алтернативният ключ за тази таблица е комбинацията от employee_id , role_id и start_date . За да избегнем дублирането на една и съща роля за един и същ служител, ще трябва да проверяваме програмно за припокривания всеки път, когато добавяме нов запис към таблицата или актуализираме съществуващ.
Област №2:Продукти
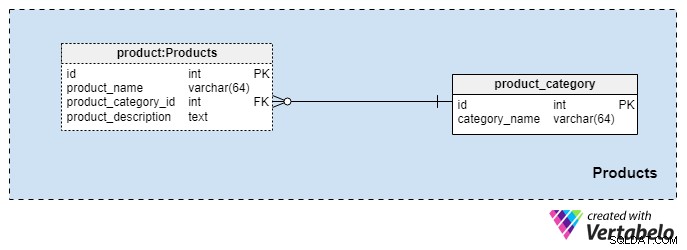
Тази тематична област е доста малка и съдържа само две таблици. Стойностите от тези таблици са предпоставки за другите ни предметни области, така че ще ги обсъдим накратко.
product_category речникът съхранява най-общите категории продукти, които планираме да предложим на нашите клиенти. Единствената стойност, която ще съхраняваме в тази таблица, е уникалната category_name за да обозначим вида застраховка, която предлагаме, която може да бъде лична застраховка живот, семейна застраховка живот и т.н.
Ще категоризираме продуктите си още повече, като използваме product маса. Тази таблица представя действителните продукти, които продаваме, а не техните категории. Както можете да си представите, можем да групираме продуктите по продължителност (например 10 или 20 години или дори цял живот). Ако решим да го направим, вероятно ще имаме продукти със същия product_category_id но различни имена и описания. За всеки продукт ще съхраняваме следната основна информация:
product_name— името на този продукт. Използва се като алтернативен ключ за тази таблица в комбинация сproduct_category_idатрибут. Малко вероятно е да имаме два продукта с едно и също име, които принадлежат към различни категории, но въпреки това е възможно.product_category_id— идентифицира категорията, към която принадлежи този продукт.product_description— текстово описание на този продукт.
Област №3:Клиенти
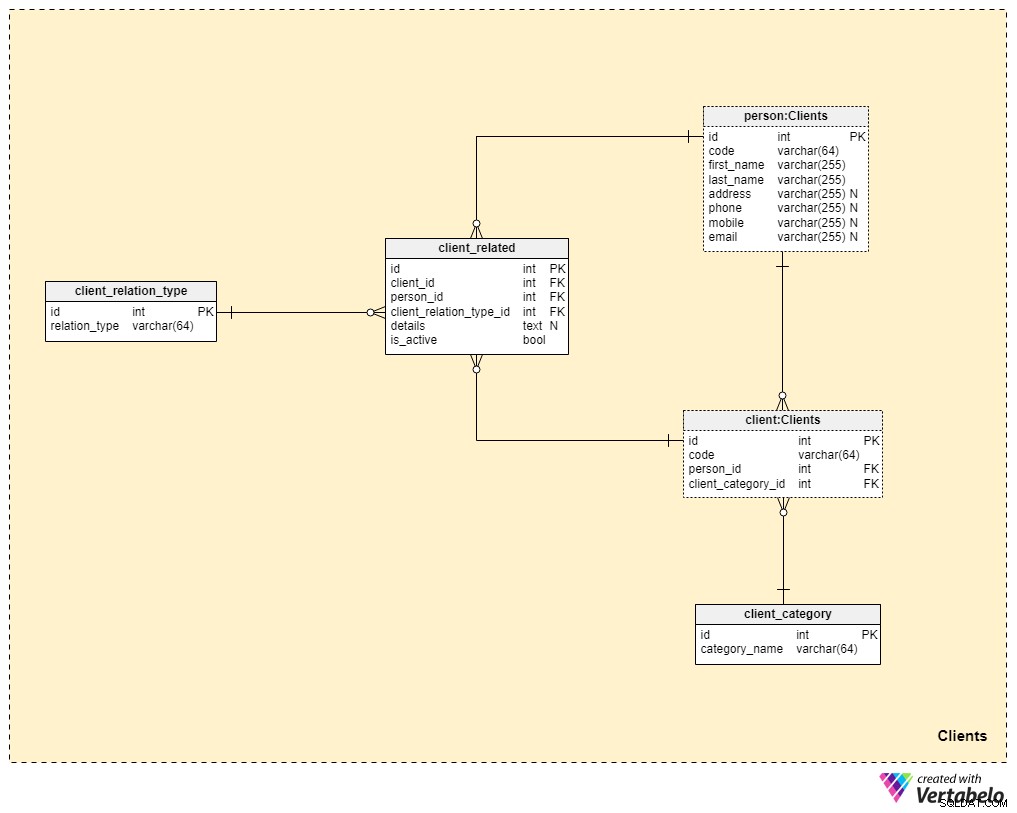
Сега се доближаваме много по-близо до ядрото на нашия модел на данни, но все още не сме съвсем там. Застраховката „Живот“ е уникална, тъй като полица може да бъде прехвърлена на член на семейството или някой друг, докато полиците за други форми на застраховка (като здравно осигуряване или автомобилна застраховка) принадлежат на един клиент и не могат да бъдат прехвърлени. Поради тази причина ще трябва да съхраняваме не само информация за клиента, на когото принадлежи политиката, но и информация за всички свързани хора и връзката им с клиента.
Ще започнем с client маса. За всеки клиент ще съхраняваме уникалния код, генериран или ръчно вмъкнат за този клиент, както и външните ключове, препращащи таблицата с техните лични данни (person_id ) и таблицата, съдържаща нашата вътрешна категоризация (client_category_id ).
client_category речникът ни позволява да групираме клиенти въз основа на техните демографски и финансови данни. След това клиентските категории ще бъдат използвани за определяне на застрахователната полица, която сме готови да предложим на конкретен клиент. Тук ще съхраняваме само списък с уникални стойности, които след това ще присвоим на клиентите.
Тъй като говорим за животозастраховане, ще приемем, че клиентът е едно лице. Въпреки това, както споменахме по-рано, може да има други хора, свързани с клиента, на които полицата може да бъде прехвърлена или които могат да получат полицата при смъртта на клиента. Поради тази причина създадохме отделен person маса. За всеки запис в тази таблица ще съхраняваме следната информация:
code— автоматично генерирана или ръчно въведена стойност, използвана за уникално идентифициране на свързаното лице.first_nameиlast_name— съответно собственото и фамилното име на лицето.address,phone,mobileиemail— данни за връзка с това лице, всички от които съдържат произволни стойности.
Останалите две таблици в тази тема са необходими за описание на естеството на взаимоотношенията между клиенти и други хора.
Списъкът с всички възможни типове релации се съхранява в client_relation_type речник. Както при други речници, това ще съдържа списък с уникални имена, които по-късно ще използваме, когато описваме връзката между конкретен клиент и друго лице.
Действителните данни за връзката се съхраняват в client_related маса. За всеки запис в тази таблица ще съхраняваме препратки към клиента (client_id ), свързаното лице (person_id ), естеството на тази връзка (client_relation_type_id ), всички подробности за добавянето (details ), ако има, и флаг, указващ дали връзката е активна в момента (is_active ). Алтернативният ключ в тази таблица се дефинира от комбинацията от client_id , person_id и client_relation_type_id .
Област №4:Оферти
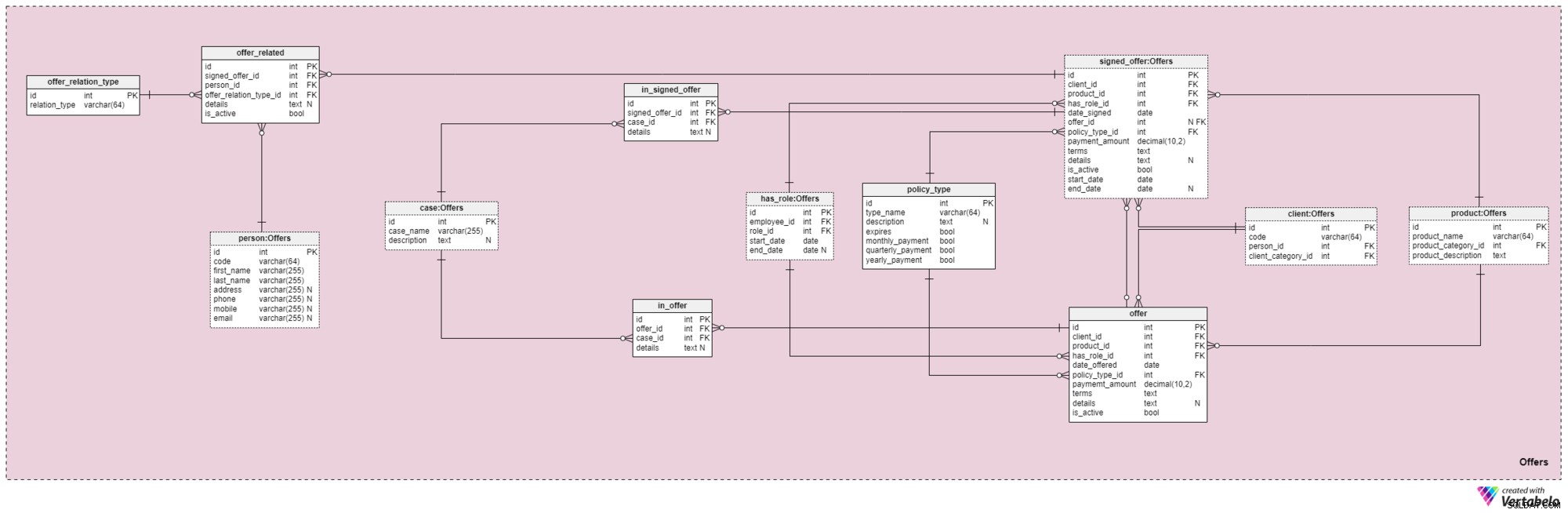
Тази предметна област и тази, която следва, са в основата на този модел на данни. Те обхващат оферти и подписани политики, както и плащания, свързани с оферти. Първо, ще опишем предметната област на офертите. Може да изглежда сложно, защото съдържа 12 таблици. Въпреки това, четири от тези 12 (has_role , product , client , и person ) бяха описани в предишни области, така че няма да повтаряме дискусията си тук.
offer и signed_offer таблиците имат сходни структури, защото ще се използват за съхраняване на много сходни данни в нашия модел. Въпреки това, докато offer ще се използва основно за съхраняване на всички правила (и техните подробности), които сме предложили на нашите клиенти, signed_offer таблицата ще се използва стриктно за съхраняване на информация за клиенти, които действително са подписали политики с нашата компания. Ще покрием тези таблици заедно, като отбележим всякакви разлики къде се появяват. Атрибутите в тези две таблици са както следва:
client_id— препратка към уникалния идентификатор за клиента, подписал конкретна оферта.product_id— препратка към уникалния идентификатор на продукта, който е включен в подписаната оферта.has_role_id— позоваване на идентификатора на служителя и ролята, която са изпълнявали към момента на представяне/подписване на офертата.date_offeredиdate_signed— действителни дати, означаващи кога тази оферта е била представена на клиента и съответно кога е подписана.offer_id— препратка към предишната оферта за този клиент. Това може да съдържа стойност null, тъй като клиентът би могъл да подпише политика, без да има никаква предходна оферта от компанията, например ако се обърна към нас сам. Този атрибут стриктно принадлежи наsigned_offerмаса.policy_type_id— препратка към речника на типа политика, обозначаващ типа политика, която сме предложили на клиента или сме ги накарали да подпишат.payment_amount— сумата, която клиентът трябва да плаща редовно за полицата.terms— всички условия на споразумението в текстов (XML) формат. Идеята е в този атрибут да се съхраняват всички важни детайли, отнасящи се до финансовата част на полицата. Примери за текст, който бихме могли да съхраняваме, са общата сума на полицата, броят на плащанията, които клиентът трябва да извърши, и т.н.details— всякакви допълнителни подробности в текстов формат.is_active— флаг, обозначаващ дали записът все още е активен.start_dateиend_date— обозначава интервала от време, в който тази политика е/ е била активна. Ако правилото е подписано за цял живот, тогава end_date ще съдържа стойност null.
Има и policy_type речник, който накратко споменахме преди. Нуждаем се от известна степен на гъвкавост в начина, по който предлагаме един и същ продукт на различни клиенти, въз основа на фактори като възраст, здраве, семейно положение, кредитен риск и т.н. За всеки тип политика ще съхраняваме type_name идентификатор, допълнително текстово description , флаг с име expires, означаващ дали полицата може да изтече, и друг флаг, указващ дали премиите за този тип полица трябва да се плащат месечно, тримесечно или годишно. Някои очаквани типове полици са:срочен живот, цял живот, универсален живот, гарантиран универсален живот, променлив живот, променлив универсален живот и животозастраховане след пенсиониране.
Продължавайки напред, сега трябва да дефинираме всички случаи и ситуации, които дадена политика може да обхване. Трябва да свържем тези случаи с конкретни оферти и подписани оферти.
Списъкът с всички възможни случаи, които покриват нашите правила, се съхранява в case речник. Всеки запис в тази таблица може да бъде уникално идентифициран чрез своя case_name и има допълнително description , ако е необходимо.
in_offer и in_signed_offer таблиците споделят една и съща структура, защото съхраняват едни и същи данни. Единствената разлика между двете е, че първият съхранява случаите, обхванати в полицата, която просто е била предложена на клиента, докато втората съхранява случаите в политиката, подписана от клиента. За всеки запис в тези две таблици ще съхраняваме уникалната двойка offer_id /signed_offer_id и case_id , като последното обозначава случая или инцидента, обхванати от полицата. Всички други подробности ще бъдат съхранени в текстов атрибут, ако е необходимо.
Както споменахме преди, животозастрахователните полици почти винаги са свързани не само с клиенти, но и с членове на техните семейства или роднини. Трябва да съхраняваме тези отношения и в тази област. Те ще бъдат дефинирани в момента на подписване на политиката, но могат също да бъдат променени през целия срок на действие на политиката.
Първото нещо, което трябва да направим, е да създадем речник, съдържащ всички възможни стойности, които могат да бъдат присвоени на релация. В нашия модел това е offer_relation_type речник. Освен първичния ключ, тази таблица съдържа само един атрибут — relation_type – които могат да съдържат само уникални стойности.
Почти сме там! Последната таблица в тази тематична област е озаглавена offer_related . Той свързва подписана оферта с всеки, който е свързан с клиента. Следователно ще трябва да съхраняваме препратки към подписаната политика (signed_offer_id ) и свързаното лице (person_id). ) и също така посочете естеството на тази връзка (offer_relation_type_id ). Освен това ще трябва да съхраняваме details свързани с този запис и създайте флаг, за да проверите дали все още е валиден в нашата система.
Област №5:Плащания
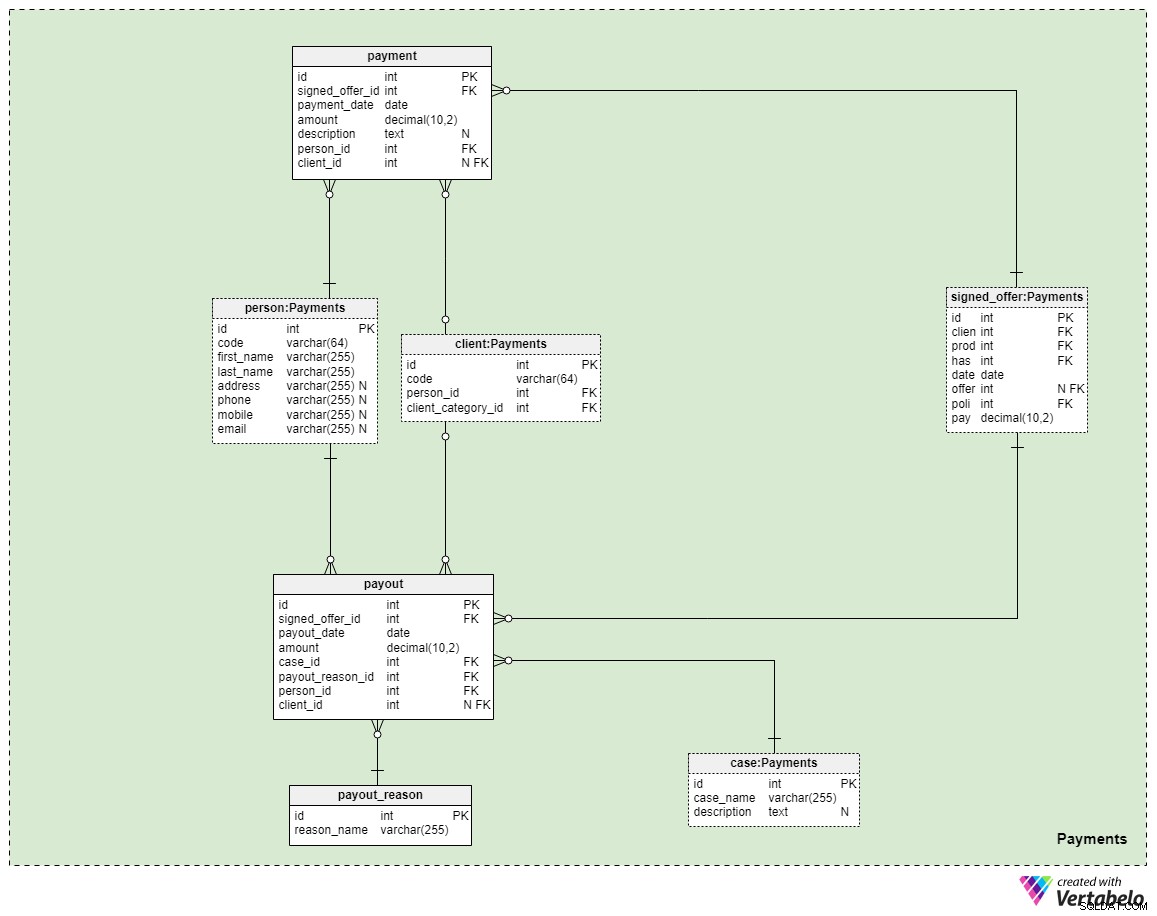
Последната предметна област в нашия модел се отнася до плащанията. Тук въвеждаме само три нови таблици:payment , payout_reason , и payout .
Всички плащания, свързани с правилата, се съхраняват в payment маса. Тук включихме само най-важните атрибути:
signed_offer_id— препратка към уникалния идентификатор на подписаната оферта (политика).payment_date— датата, на която е извършено това плащане.amount— действителната сума, която е била платена.description— незадължително описание на плащането в текстов формат.person_id— препратка към уникалния идентификатор на лицето, извършило плащането. Имайте предвид, че клиентът, който е подписал офертата, не е непременно единственото лице, което може да извърши плащане.client_id— препратка към уникалния идентификатор на клиента, извършил плащането. Този атрибут ще съдържа стойност само ако клиентът е извършил плащането.
Останалите две таблици представляват може би най-важната причина, поради която плащаме застраховка „Живот“ – че в случай, че нещо ни се случи, изплащанията ще бъдат извършени на членовете на нашето семейство или на партньорите в живота/бизнеса. Как се случва това зависи от вашата ситуация и условията на конкретната политика, която сте подписали. Ще използваме две прости таблици, за да покрием тези случаи.
Първият е речник, озаглавен payout_reason и разполага с класическа речникова структура. Освен атрибута на първичния ключ, имаме само един атрибут – reason_name – който ще съхранява списък с уникални стойности, указващи защо е извършено това изплащане.
Последната таблица в модела е payout маса. Много е подобно на payment таблица, но най-важните разлики са отбелязани по-долу:
payout_date— датата, на която е извършено изплащането.case_id— препратка към уникалния идентификатор на свързания случай или инцидент, който е задействал плащането. Това трябва да съвпада с един от идентификаторите, включени в правилата.payout_reason_id— препратка към речника, който описва по-подробно причината за изплащането. Въпреки че случаят за изплащане е по-кратък и по-общ, причината за изплащане ще предложи по-конкретни подробности за случилото се.person_idиclient_id— препраща съответно към лицето и клиента, свързани с изплащането.
Резюме
Страхотно! Успешно изградихме нашия модел на данни за животозастраховане. Преди да приключим нашата дискусия, си струва да отбележим, че има много повече, които могат да бъдат обхванати в този модел. В тази статия ние основно искахме да покрием основите на модела, за да ви дадем представа как изглежда и функционира. Ето още някои подробности, които човек може да включи в такъв модел на данни:
- Допълнителните надстройки на правилата не са обхванати в настоящия ни модел (напр. ако искате да правите годишни оферти за съществуващи правила, няма да можете да го направите с тази структура). Трябва да добавим още няколко таблици, за да съхраняваме всички промени в правилата за представени/подписани оферти.
- Всички документи са умишлено пропуснати. Разбира се, ще има доста документи, свързани с конкретна животозастрахователна полица, особено за процеса на подписване и изплащания. Бихме могли да прикачим документи, които описват състоянието на клиента към момента на подписване на полицата и всякакви промени по пътя, както и всякакви документи, свързани с изплащанията.
- Този модел не включва структурата, необходима за изчисляване на риска от политика. Трябва да имаме всички параметри, които трябва да тестваме, и всички диапазони, които определят как стойността на клиента влияе върху цялостното изчисление. Резултатите от тези изчисления трябва да се съхраняват за всяка оферта и подписана политика.
- Структурата на фактурата в действителност е много по-сложна от това, което обхванахме в темата за плащанията. Дори не споменахме финансовите сметки никъде в нашия модел.
Очевидно застрахователният бизнес е доста сложен. В тази статия обсъдихме само модел на данни за животозастраховане — можете ли да си представите как би се развил този модел на данни, ако управляваме компания, която предлага редица различни видове застраховки? Със сигурност ще отнеме много планиране и мисъл, за да се представи организиран модел на данни за такава компания.
Ако имате някакви предложения или идеи за подобряване на нашия модел на данни, не се колебайте да ни уведомите в коментарите по-долу!