Преди няколко седмици екипът на SQLskills беше в Тампа за нашето събитие за потапяне на производителността (IE2) и аз покривах основните положения. Базовите показатели са тема, която ми е близка и скъпа на сърцето, защото са толкова ценни по много причини. Две от тези причини, които винаги споменавам, независимо дали преподавам или работя с клиенти, са използването на изходни стойности за отстраняване на неизправности в производителността, а след това също и тенденция за използване и предоставяне на прогнози за планиране на капацитета. Но те също са от съществено значение, когато правите настройка или тестване на производителността – независимо дали смятате съществуващите си показатели за ефективност като базови или не.
По време на модула прегледах различни източници за данни като Performance Monitor, DMV и данни за проследяване или XE и възникна въпрос, свързан с натоварването на данни. По-конкретно, въпросът беше дали е по-добре да заредите данни в таблица без индекси и след това да ги създадете, когато приключите, вместо индексите да са на място по време на зареждането на данните. Моят отговор беше „Обикновено да“. Моят личен опит е, че това винаги е така, но никога не знаете с какво предупреждение или еднократен сценарий може да се сблъска някой, при който промяната в производителността не е това, което се очакваше, и както при всички въпроси за ефективността, не знаете със сигурност, докато не го тествате. Докато не установите базова линия за един метод и след това не видите дали другият метод се подобрява спрямо тази изходна линия, вие само предполагате. Мислех, че ще бъде забавно да тествам. този сценарий, не само за да докажа това, което очаквам да е вярно, но и за да покажа какви показатели бих проучил, защо и как да ги уловя. Ако сте правили тестове за ефективност по-рано, това вероятно е стара шапка. Но за тези хора. от вас, които сте нови в практиката, ще премина през процеса, който следвам, за да ви помогна да започнете. Осъзнайте, че има много начини да получите отговор на „Кой метод е по-добър?“ Очаквам, че ще приемете този процес, ще го настроите и ще го направите свой с течение на времето.
Какво се опитвате да докажете?
Първата стъпка е да решите какво точно тествате. В нашия случай е ясно:по-бързо ли е да се заредят данни в празна таблица, след това да се добавят индексите, или е по-бързо индексите да са в таблицата по време на зареждането на данните? Но можем да добавим някои вариации тук, ако желаем. Помислете за времето, необходимо за зареждане на данни в купчина, и след това създайте клъстерираните и неклъстерирани индекси, спрямо времето, необходимо за зареждане на данни в клъстериран индекс, и след това създайте неклъстерираните индекси. Има ли разлика в производителността? Дали ключът за клъстериране ще бъде фактор? Очаквам, че натоварването на данните ще доведе до фрагментиране на съществуващи неклъстерирани индекси, така че може би искам да видя какво влияние оказва възстановяването на индексите след натоварването върху общата продължителност. Важно е да обхванете тази стъпка колкото е възможно повече и да бъдете много конкретни относно това, което искате да измерите, тъй като това ще определи какви данни ще улавяте. За нашия пример нашите четири теста ще бъдат:
Тест 1: Заредете данни в купчина, създайте клъстерирания индекс, създайте неклъстерирани индекси
Тест 2: Заредете данни в клъстериран индекс, създайте неклъстерирани индекси
Тест 3: Създайте клъстерирания индекс и неклъстерираните индекси, заредете данните
Тест 4: Създайте клъстерирания индекс и неклъстерирани индекси, заредете данните, изградете отново неклъстерираните индекси
Какво трябва да знаете?
В нашия сценарий основният ни въпрос е „кой метод е най-бързият“? Следователно, ние искаме да измерим продължителността и за да го направим, трябва да уловим начален и краен час. Бихме могли да го оставим така, но може да искаме да разберем как изглежда използването на ресурсите за всеки метод, или може би искаме да знаем най-голямото изчакване, или броя на транзакциите, или броя на блокирането. Данните, които са най-интересни и уместни, ще зависят от това какви процеси сравнявате. Улавянето на броя на транзакциите не е толкова интересно за нашето натоварване с данни; но за промяна на кода може да е така. Тъй като създаваме индекси и ги изграждаме отново, ме интересува колко IO генерира всеки метод. Въпреки че общата продължителност вероятно е решаващият фактор в крайна сметка, разглеждането на IO може да е полезно не само да разберете коя опция генерира най-много IO, но и дали съхранението на базата данни работи според очакванията.
Къде са данните, от които се нуждаете?
След като определите какви данни ви трябват, решете откъде ще бъдат заснети. Интересуваме се от продължителността, така че искаме да запишем времето, в което започва всеки тест за натоварване на данни и кога приключва. Ние също се интересуваме от IO и можем да извлечем тези данни от множество места – на ум идват броячите на Performance Monitor и sys.dm_io_virtual_file_stats DMV.
Разберете, че можем да получим тези данни ръчно. Преди да стартираме тест, можем да изберем срещу sys.dm_io_virtual_file_stats и да запишем текущите стойности във файл. Можем да отбележим времето и след това да започнем теста. Когато приключи, отново отбелязваме времето, заявяваме отново sys.dm_io_virtual_file_stats и изчисляваме разликите между стойностите за измерване на IO.
Има много недостатъци в тази методология, а именно, че оставя значително място за грешки; какво ще стане, ако забравите да отбележите началния час или забравите да заснемете статистически данни за файла, преди да започнете? Много по-добро решение е да се автоматизира не само изпълнението на скрипта, но и улавянето на данни. Например, можем да създадем таблица, която съдържа информацията за нашия тест – описание на това какво представлява тестът, в колко часа е започнал и в колко часа е завършил. Можем да включим статистическите данни на файла в същата таблица. Ако събираме други показатели, можем да ги добавим към таблицата. Или може да е по-лесно да създадете отделна таблица за всеки набор от данни, които улавяме. Например, ако съхраняваме статистически данни за файла в различна таблица, трябва да дадем на всеки тест уникален идентификатор, за да можем да съпоставим нашия тест с правилните статистически данни за файла. Когато улавяме статистически данни за файловете, трябва да уловим стойностите за нашата база данни, преди да започнем, а след това и да изчислим разликата. След това можем да съхраним тази информация в собствена таблица, заедно с уникалния тест ID.
Примерно упражнение
За този тест създадох празно копие на таблицата Sales.SalesOrderHeader с име Sales.Big_SalesOrderHeader и използвах вариант на скрипт, който използвах в публикацията си за разделяне, за да заредя данни в таблицата на партиди от приблизително 25 000 реда. Можете да изтеглите скрипта за зареждане на данни тук. Изпълних го четири пъти за всяка вариация и също така промених общия брой вмъкнати редове. За първия набор от тестове вмъкнах 20 милиона реда, а за втория набор вмъкнах 60 милиона реда. Данните за продължителността не са изненадващи:
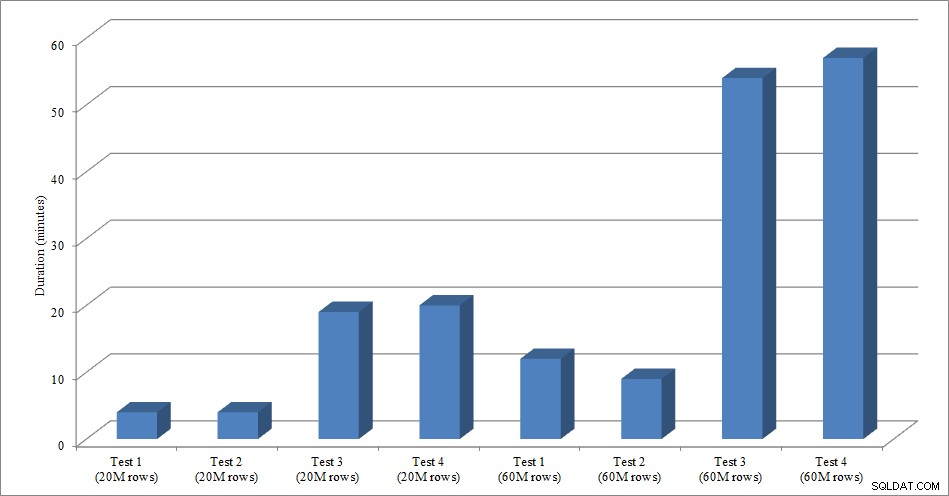
Продължителност на зареждане на данни
Зареждането на данни без неклъстерираните индекси е много по-бързо от зареждането им с вече наличните неклъстерирани индекси. Това, което намерих за интересно, е, че за натоварването от 20 милиона реда, общата продължителност беше приблизително еднаква между тест 1 и тест 2, но тест 2 беше по-бърз при зареждане на 60 милиона реда. В нашия тест нашият ключ за клъстериране беше SalesOrderID, който е идентичност и следователно добър ключ за клъстериране за нашето натоварване, тъй като то е нарастващо. Ако вместо това имахме ключ за клъстериране, който беше GUID, времето за зареждане може да е по-високо поради произволни вмъквания и разделяне на страници (друг вариант, който бихме могли да тестваме).
Данните за IO имитират ли тенденцията в данните за продължителността? Да, с разликите, когато индексите вече са на място или не, дори са преувеличени:
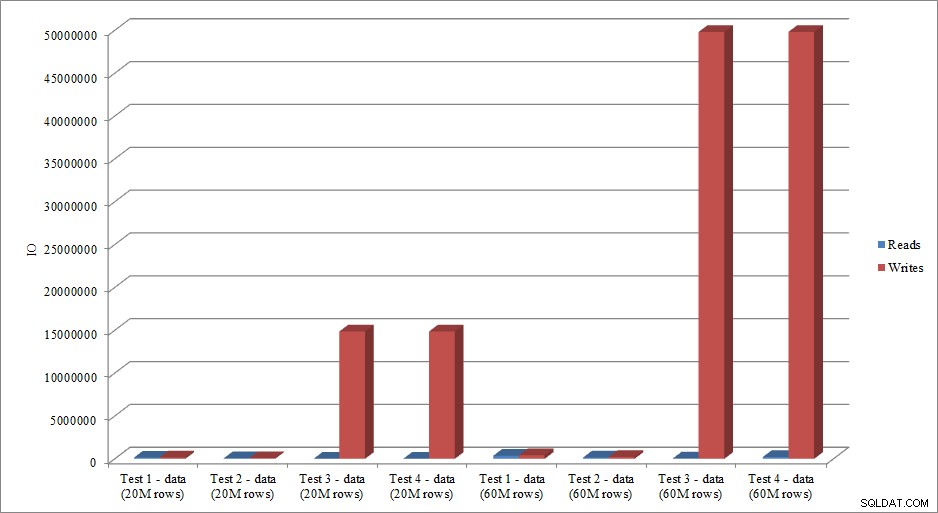
Зареждане на данни за четене и запис
Методът, който представих тук за тестване на производителността или измерване на промените в производителността въз основа на модификации на код, дизайн и т.н., е само една от възможностите за улавяне на основна информация. В някои сценарии това може да е излишно. Ако имате една заявка, която се опитвате да настроите, настройването на този процес за улавяне на данни може да отнеме повече време, отколкото би отнело по-дълго време за коригиране на заявката! Ако сте направили някаква настройка на заявката, вероятно имате навика да улавяте данните от STATISTICS IO и STATISTICS TIME, заедно с плана на заявката, и след това да сравнявате изхода, докато правите промени. Правя това от години, но наскоро открих по-добър начин... SQL Sentry Plan Explorer PRO. Всъщност, след като завърших всички тестове за натоварване, които описах по-горе, преминах и проведох отново тестовете си чрез PE и открих, че мога да уловя информацията, която исках, без да се налага да настройвам таблиците си за събиране на данни.
В рамките на Plan Explorer PRO имате възможност да получите действителния план – PE ще изпълни заявката срещу избрания екземпляр и база данни и ще върне плана. И с него получавате всички други страхотни данни, които PE предоставя (статистически данни за времето, четене и запис, IO по таблица), както и статистика за чакане, което е приятно предимство. Използвайки нашия пример, започнах с първия тест – създаване на купчина, зареждане на данни и след това добавяне на клъстерирания индекс и неклъстерирани индекси – и след това стартирах опцията Get Actual Plan. Когато приключи, промених своя тест за скрипт 2, стартирах отново опцията Получаване на действителен план. Повторих това за третия и четвъртия тест и когато приключих, имах това:
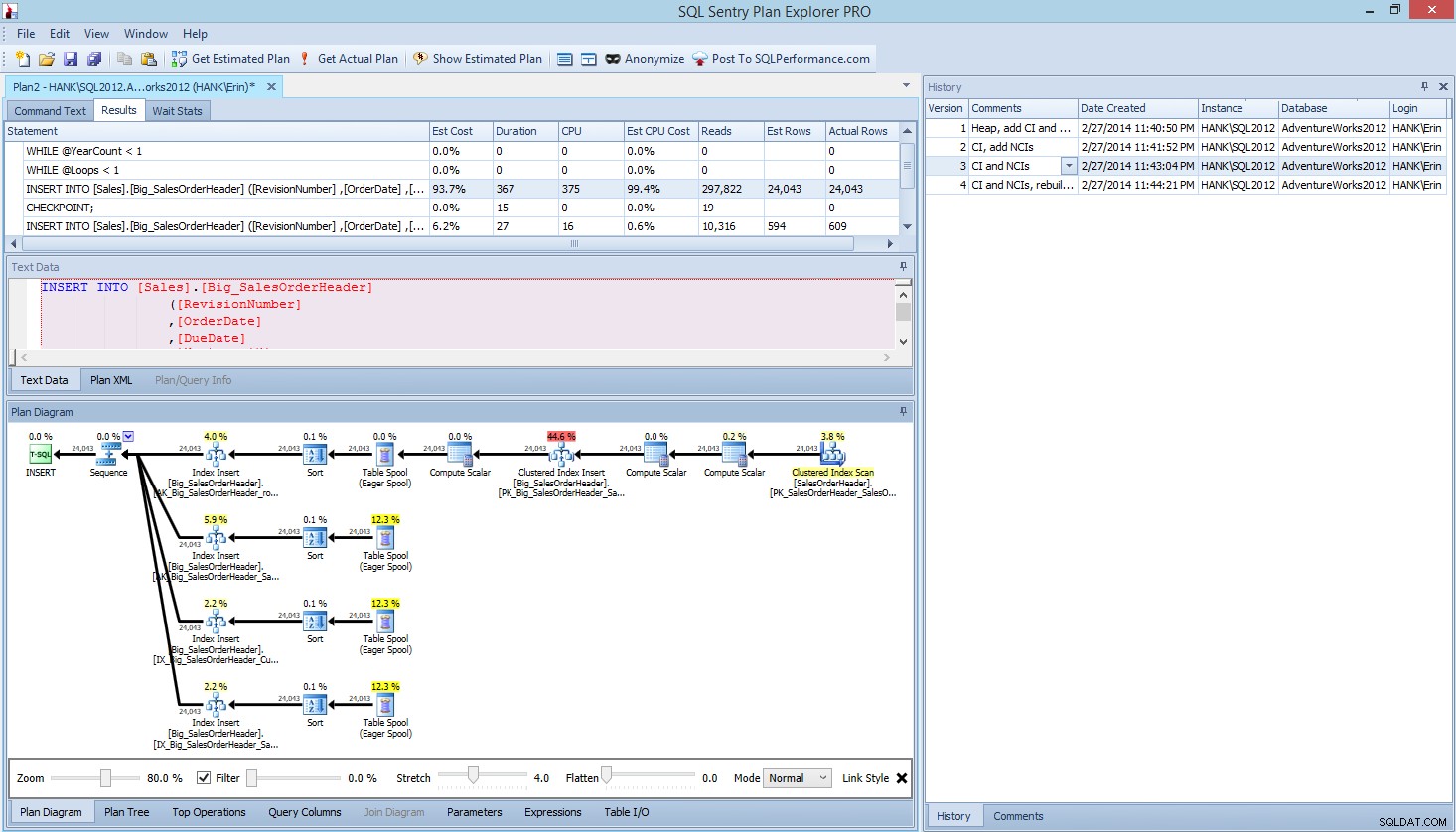
Планирайте Explorer PRO изглед след стартиране на 4 теста
Забелязвате ли екрана за история от дясната страна? Всеки път, когато променях кода си и възстановявах действителния план, той запазваше нов набор от информация. Имам възможността да запазя тези данни като .pesession файл, който да споделя с друг член на моя екип, или да се върна по-късно и да превъртя различните тестове, и да пробвам в различни изявления в рамките на пакета, ако е необходимо, като разглеждам различни показатели, като като продължителност, CPU и IO. На екранната снимка по-горе маркирах INSERT от тест 3 и планът на заявката показва актуализациите на всичките четири неклъстерирани индекса.
Резюме
Както при толкова много задачи в SQL Server, има много начини за улавяне и преглед на данни, когато изпълнявате тестове за производителност или извършвате настройка. Колкото по-малко ръчни усилия трябва да положите, толкова по-добре, тъй като остава повече време, за да направите промените, да разберете въздействието и след това да преминете към следващата си задача. Независимо дали персонализирате скрипт за улавяне на данни, или оставите помощна програма на трета страна да го направи вместо вас, стъпките, които очертах, все още са валидни:
- Определете какво искате да подобрите
- Обхват на вашето тестване
- Определете какви данни могат да се използват за измерване на подобрение
- Решете как да заснемате данните
- Настройте автоматизиран метод, когато е възможно, за тестване и улавяне
- Тествайте, оценете и повторете, ако е необходимо
Приятно тестване!