Имаше много дискусии относно In-Memory OLTP (функцията, известна преди като "Hekaton") и как тя може да помогне за много специфични, големи обеми натоварвания. В разгара на различен разговор случайно забелязах нещо в CREATE TYPE документация за SQL Server 2014, която ме накара да мисля, че може да има по-общ случай на употреба:

Сравнително тихи и непредвидими допълнения към документацията CREATE TYPE
Въз основа на синтаксичната диаграма изглежда, че параметрите с стойност на таблицата (TVPs) могат да бъдат оптимизирани за паметта, точно както могат да бъдат постоянните таблици. И с това колелата веднага започнаха да се въртят.
Едно нещо, за което използвах TVP, е да помогна на клиентите да премахнат скъпите методи за разделяне на низове в T-SQL или CLR (вижте фона в предишни публикации тук, тук и тук). В моите тестове използването на обикновен TVP превъзхожда еквивалентните модели, използващи функциите за разделяне на CLR или T-SQL със значителна разлика (25-50%). Логично се зачудих:Ще има ли някаква печалба в производителността от оптимизиран за памет TVP?
Имаше известни опасения относно In-Memory OLTP като цяло, тъй като има много ограничения и пропуски в функциите, имате нужда от отделна файлова група за оптимизирани за паметта данни, трябва да преместите цели таблици в оптимизирани за памет и най-добрата полза обикновено е се постига и чрез създаване на собствено компилирани съхранени процедури (които имат свой собствен набор от ограничения). Както ще демонстрирам, ако приемем, че вашият тип таблица съдържа прости структури от данни (например представляващи набор от цели числа или низове), използването на тази технология само за TVP елиминира някои от тези проблеми.
Тестът
Все още ще имате нужда от оптимизирана за памет файлова група, дори ако няма да създавате постоянни, оптимизирани за паметта таблици. Така че нека създадем нова база данни с подходяща структура:
СЪЗДАВАНЕ НА БАЗА ДАННИ xtp;БАЗА ДАННИ НА GOALTER xtp ДОБАВЯНЕ НА ФАЙЛОВА ГРУПА xtp СЪДЪРЖА MEMORY_OPTIMIZED_DATA;БАЗА ДАННИ GOALTER xtp ДОБАВЯНЕ НА ФАЙЛ (name='xtpmod', filename='c:\...\xtp.mod') КЪМ xtpFIGOALGROUP xtpFI; SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT =ON; GO
Сега можем да създадем обикновен тип таблица, както бихме направили днес, и оптимизиран за памет тип таблица с неклъстериран хеш индекс и брой на кофата, който извадих от въздуха (повече информация за изчисляване на изискванията за памет и броя на кофата в реалния свят тук):
ИЗПОЛЗВАЙТЕ xtp; ИЗПОЛЗВАЙТЕ СЪЗДАВАЙТЕ ТИП dbo.ClassicTVP КАТО ТАБЛИЦА( Елемент INT ПРАВИЛЕН КЛЮЧ); CREATE TYPE dbo.InMemoryTVP КАТО ТАБЛИЦА( Елемент INT NOT NULL ПЪРВИЧЕН КЛЮЧ НЕКЛУСТРИРАН ХЕШ С (BUCKET_COUNT =256)) WITH (MEMORY_OPTIMIZED =ON);
Ако опитате това в база данни, която няма оптимизирана за памет файлова група, ще получите това съобщение за грешка, точно както бихте направили, ако се опитате да създадете нормална таблица, оптимизирана за памет:
Съобщение 41337, ниво 16, състояние 0, ред 9Файловата група MEMORY_OPTIMIZED_DATA не съществува или е празна. Оптимизирани за памет таблици не могат да бъдат създадени за база данни, докато тя няма една файлова група MEMORY_OPTIMIZED_DATA, която не е празна.
За да тествам заявка спрямо обикновена таблица, която не е оптимизирана за памет, просто изтеглих някои данни в нова таблица от примерната база данни на AdventureWorks2012, използвайки SELECT INTO за да игнорирам всички тези досадни ограничения, индекси и разширени свойства, след което създадох клъстериран индекс в колоната, за която знаех, че ще търся (ProductID ):
SELECT * INTO dbo.Products FROM AdventureWorks2012.Production.Product; -- 504 реда СЪЗДАВАЙТЕ УНИКАЛЕН КЛУСТРИРАН ИНДЕКС p В dbo.Products(ProductID);
След това създадох четири съхранени процедури:две за всеки тип таблица; всеки използва EXISTS и JOIN подходи (обикновено обичам да разглеждам и двата, въпреки че предпочитам EXISTS; по-късно ще разберете защо не исках да огранича тестването си само до EXISTS ). В този случай просто присвоявам произволен ред на променлива, така че да мога да наблюдавам голям брой изпълнения, без да се занимавам с набори от резултати и други изходни данни и допълнителни разходи:
-- Old-school TVP, използвайки EXISTS:CREATE PROCEDURE dbo.ClassicTVP_Exists @Classic dbo.ClassicTVP READONLYASBEGIN SET NOCOUNT ON; ДЕКЛАРИРАНЕ @name NVARCHAR(50); ИЗБЕРЕТЕ @name =p.Name ОТ dbo.Products AS p WHERE EXISTS ( SELECT 1 FROM @Classic AS t WHERE t.Item =p.ProductID );ENDGO -- In-Memory TVP, използвайки EXISTS:CREATE PROCEDURE dbo.InMemoryTVP_Exists @InMemory dbo.InMemoryTVP READONLYASBEGIN SET NOCOUNT ON; ДЕКЛАРИРАНЕ @name NVARCHAR(50); ИЗБЕРЕТЕ @name =p.Name ОТ dbo.Products КАТО p КЪДЕ СЪЩЕСТВУВА (ИЗБЕРЕТЕ 1 ОТ @InMemory КАТО t WHERE t.Item =p.ProductID );ENDGO -- Old-school TVP с помощта на JOIN:CREATE PROCEDURE dbo.ClassicTVP_Join @ Classic dbo.ClassicTVP ЧЕТЕНЕ САМО ЗАПОЧНЕТЕ ЗАДАДЕТЕ NOCOUNT ON; ДЕКЛАРИРАНЕ @name NVARCHAR(50); SELECT @name =p.Name ОТ dbo.Products AS p INNER JOIN @Classic AS t ON t.Item =p.ProductID;ENDGO -- In-Memory TVP с помощта на JOIN:CREATE PROCEDURE dbo.InMemoryTVP_Join @InMemory dbo.InMemoryBEGINASP ВКЛЮЧЕТЕ NOCOUNT; ДЕКЛАРИРАНЕ @name NVARCHAR(50); SELECT @name =p.Name ОТ dbo.Products AS p INNER JOIN @InMemory AS t ON t.Item =p.ProductID;ENDGO
След това трябваше да симулирам вида заявка, която обикновено идва срещу този тип таблица и изисква TVP или подобен модел на първо място. Представете си формуляр с падащо меню или набор от квадратчета за отметка, съдържащ списък с продукти, и потребителят може да избере 20, 50 или 200, които иска да сравни, да изброи, какво имате. Стойностите няма да бъдат в хубав непрекъснат набор; те обикновено ще бъдат разпръснати навсякъде (ако беше предвидимо непрекъснат диапазон, заявката би била много по-проста:начални и крайни стойности). Така че току-що избрах произволни 20 стойности от таблицата (опитвайки се да остана под, да речем, 5% от размера на таблицата), подредени на случаен принцип. Лесен начин за създаване на VALUES за многократна употреба клауза като тази е както следва:
DECLARE @x VARCHAR(4000) =''; ИЗБЕРЕТЕ ВЪРХУ (20) @x +='(' + RTRIM(ProductID) + '),' ОТ dbo.Products ORDER BY NEWID(); ИЗБЕРЕТЕ @x; Резултатите (твоите почти сигурно ще варират):
(725), (524), (357), (405), (477), (821), (323), (526), (952), (473), (442), (450), (735 ),(441),(409),(454),(780),(966),(988),(512),
За разлика от директния INSERT...SELECT , това прави доста лесно да се манипулира този изход в изявление за многократна употреба, за да се попълват многократно нашите TVP с едни и същи стойности и по време на множество итерации на тестване:
ЗАДАДЕТЕ NOCOUNT ON; ДЕКЛАРИРАНЕ @ClassicTVP dbo.ClassicTVP;ДЕКЛАРИРАНЕ @InMemoryTVP dbo.InMemoryTVP; ВМЕСТЕ @ClassicTVP(Item) STONS (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442) , (450), (735), (441), (409), (454), (780), (966), (988), (512); ВМЕСТЕ @InMemoryTVP(Item) STONS (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442) , (450), (735), (441), (409), (454), (780), (966), (988), (512); EXEC dbo.ClassicTVP_Exists @Classic =@ClassicTVP;EXEC dbo.InMemoryTVP_Exists @InMemory =@InMemoryTVP;EXEC dbo.ClassicTVP_Join @Classic =@ClassicTVP;EXEC dbo.InMemoryTVP_Exists @InMemory =@InMemoryTVP;EXEC dbo.ClassicTVP_Join @Classic =@ClassicTVP;EXEC dbo.InMemoryTVP@InMemory = Ако стартираме тази партида с помощта на SQL Sentry Plan Explorer, получените планове показват голяма разлика:TVP в паметта може да използва присъединяване с вложени цикли и 20 едноредови клъстерирани индексни търсения, спрямо обединяване с обединяване, захранвано от 502 реда от клъстерно индексно сканиране за класическия TVP. И в този случай EXISTS и JOIN дадоха идентични планове. Това може да доведе до много по-голям брой стойности, но нека продължим с допускането, че броят на стойностите ще бъде по-малък от 5% от размера на таблицата:
Планове за класически и в памет TVP
Инструменти за оператори за сканиране/търсене, подчертаващи основните разлики – класически вляво, In- Памет вдясно
Какво означава това в мащаб? Нека изключим всяка колекция от showplan и леко променим тестовия скрипт, за да стартираме всяка процедура 100 000 пъти, като улавяме кумулативно време на изпълнение ръчно:
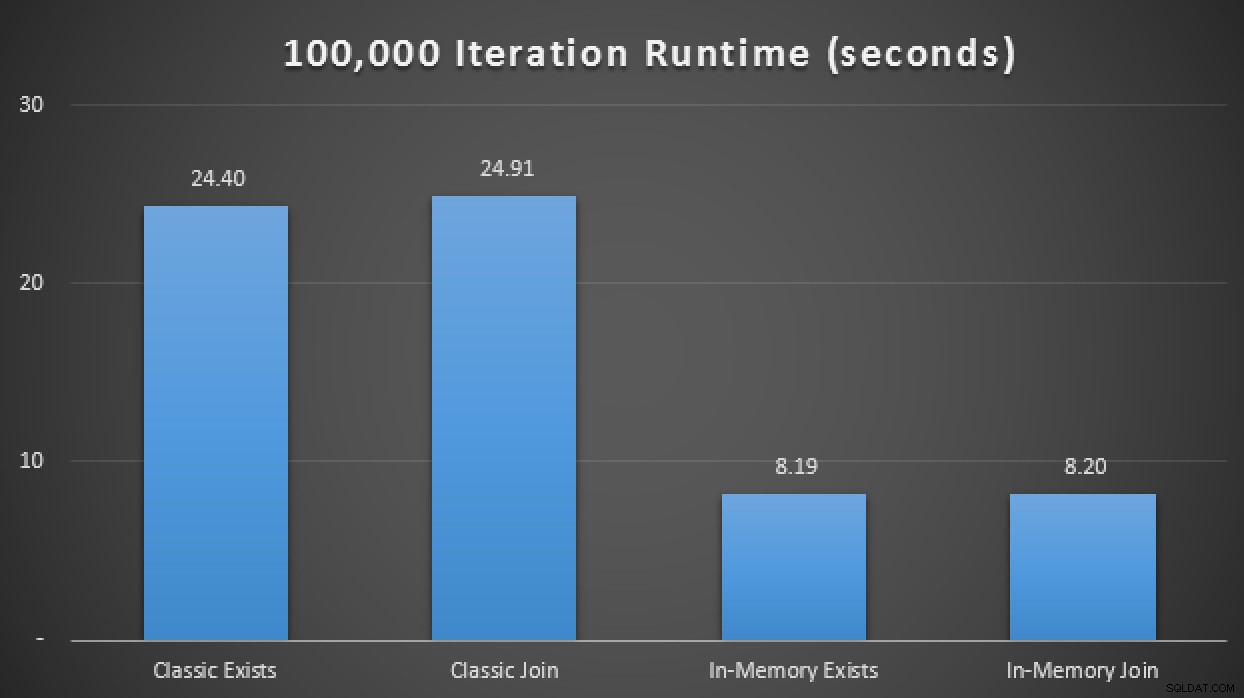
ДЕКЛАРИРАНЕ @i TINYINT =1, @j INT =1; WHILE @i <=4BEGIN SELECT SYSDATETIME(); WHILE @j <=100000 BEGIN IF @i =1 BEGIN EXEC dbo.ClassicTVP_Exists @Classic =@ClassicTVP; END IF @i =2 BEGIN EXEC dbo.InMemoryTVP_Exists @InMemory =@InMemoryTVP; END IF @i =3 BEGIN EXEC dbo.ClassicTVP_Join @Classic =@ClassicTVP; END IF @i =4 BEGIN EXEC dbo.InMemoryTVP_Join @InMemory =@InMemoryTVP; END SET @j +=1; КРАЙ ИЗБОР @i +=1, @j =1; КРАЙ ИЗБОР SYSDATETIME();В резултатите, осреднени за 10 цикъла, виждаме, че поне в този ограничен тестов случай използването на оптимизиран за памет тип таблица е довело до приблизително 3X подобрение на може би най-критичния показател за производителност в OLTP (време на изпълнение):
Резултати по време на изпълнение, показващи 3X подобрение с In-Memory TVPsIn-Memory + In-Memory + In-Memory:In-Memory Начало
Сега, когато видяхме какво можем да направим, като просто променим нашия обикновен тип таблица на оптимизиран за памет тип таблица, нека да видим дали можем да изтласкаме повече производителност от същия модел на заявка, когато приложим трифекта:в паметта таблица, като се използва нативно компилирана оптимизирана за паметта съхранена процедура, която приема таблица в паметта като параметър с таблица.
Първо, трябва да създадем ново копие на таблицата и да го попълним от локалната таблица, която вече създадохме:
CREATE TABLE dbo.Products_InMemory( ProductID INT NOT NULL, Име NVARCHAR(50) NOT NULL, ProductNumber NVARCHAR(25) NOT NULL, MakeFlag BIT NOT NULL, FinishedGoodsFlag BIT NULL, Цвят NULL, Цвят NULL, Цвят NVARCHALLNULL до , ReorderPoint SMALLINT NOT NULL, StandardCost MONEY NOT NULL, ListPrice MONEY NOT NULL, [Size] NVARCHAR(5) NULL, SizeUnitMeasureCode NCHAR(3) NULL, WeightUnitMeasureCode NCHAR(3) NULL, [Weight) NULL, [Weight] DaysToManufacture INT NOT NULL, ProductLine NCHAR(2) NULL, [Class] NCHAR(2) NULL, Style NCHAR(2) NULL, ProductSubcategoryID INT NULL, ProductModelID INT NULL, Se llStartDate DATETIME NOT NULL, SellEndDate DATETIME NULL, DiscontinuedDate DATETIME NULL, rowguid UNIQUEIDENTIFIER NULL, ModifiedDate DATETIME NULL, PRIMARY KEY NONCLUSTERED HASH (ProductID) WIED =(BUCKETMIUR_COUNT) =(BUCKETMIURMO) INSERT dbo.Products_InMemory SELECT * FROM dbo.Products;След това създаваме собствено компилирана съхранена процедура, която приема нашия съществуващ тип оптимизирана за памет таблица като TVP:
СЪЗДАДЕТЕ ПРОЦЕДУРА dbo.InMemoryProcedure @InMemory dbo.InMemoryTVP САМО ЧЕТЕНЕ С NATIVE_COMPILATION, SCHEMABINDING, ИЗПЪЛНЕТЕ КАТО СОБСТВЕНИК КАТО BEGIN ATOMIC WITH (НИВО НА ИЗОЛАЦИЯ НА ТРАНЗАКЦИЯТА =SNAPSHOT, LANGUAGE =N'us_english ДЕКЛАРИРАНЕ @Име NVARCHAR(50); SELECT @Name =Име ОТ dbo.Products_InMemory AS p INNER JOIN @InMemory AS t ON t.Item =p.ProductID;END GOНяколко предупреждения. Не можем да използваме обикновен, неоптимизиран за памет тип таблица като параметър на компилираната в оригинал процедура. Ако опитаме, получаваме:
Msg 41323, ниво 16, състояние 1, процедура InMemoryProcedure
Типът на таблицата 'dbo.ClassicTVP' не е оптимизиран за памет тип таблица и не може да се използва в компилирана съхранена процедура.Освен това не можем да използваме
Msg 12311, Ниво 16, Състояние 37, Процедура NativeCompiled_ExistsEXISTSмодел и тук; когато опитаме, получаваме:
Подзаявките (заявки, вложени в друга заявка) не се поддържат с нативно компилирани съхранени процедури.Има много други предупреждения и ограничения с In-Memory OLTP и собствено компилирани съхранени процедури, просто исках да споделя няколко неща, които може да изглеждат очевидно липсващи при тестването.
И така, като добавих тази нова компилирана съхранена процедура към тестовата матрица по-горе, открих, че – отново, средно за 10 стартирания – тя изпълни 100 000 итерации само за 1,25 секунди. Това представлява приблизително 20X подобрение спрямо обикновените TVP и 6-7X подобрение в сравнение с TVP в паметта, използвайки традиционни таблици и процедури:
Резултати по време на изпълнение, показващи до 20X подобрение с In-Memory навсякъдеЗаключение
Ако използвате TVP сега или използвате модели, които могат да бъдат заменени от TVP, абсолютно трябва да помислите за добавяне на оптимизирани за паметта TVP към вашите планове за тестване, но имайте предвид, че може да не видите същите подобрения във вашия сценарий. (И, разбира се, имайки предвид, че TVP като цяло имат много предупреждения и ограничения и те също не са подходящи за всички сценарии. Ерланд Сомарског има страхотна статия за днешните TVP тук.)
Всъщност може да видите, че в ниския край на обема и едновременността няма разлика – но моля, тествайте в реалистичен мащаб. Това беше много прост и измислен тест на модерен лаптоп с един SSD, но когато говорите за реален обем и/или въртящи се механични дискове, тези характеристики на производителност може да имат много по-голяма тежест. Предстои последващо действие с някои демонстрации на по-големи размери на данни.