Базите данни с времеви серии, както подсказва името, са предназначени да съхраняват данни, които се променят с времето. Това може да бъде всякакъв вид данни, които са били събрани във времето. Това може да са показатели, събрани от някои системи и всъщност всички системи с тенденция са примери за данните от времевите редове.
Имаме различни типове бази данни с времеви серии, кои да използваме?
В този блог ще видим какви са основните разлики между две от основните опции, TimescaleDB и InfluxDB.
InfluxDB
InfluxDB е създаден от InfluxData. Това е персонализирана база данни с времеви серии NoSQL с отворен код, написана на Go. Съхранението на данни предоставя SQL-подобен език за запитване на данните, наречен InfluxQL, което улеснява интегрирането на разработчиците в техните приложения. Той също така има нов персонализиран език за заявки, наречен Flux, този език може да улесни някои задачи, но винаги има крива на обучение, когато приемате персонализиран език за заявки.
Това е пример за Flux заявка:
from(db:"testing")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "cpu")
|> exponentialMovingAverage()В тази база данни всяко измерване има времева марка и свързан набор от тагове и набор от полета. Полето представлява действителните отчитани стойности на измерването, докато етикетът представлява метаданните за описание на измерванията. Типовете данни на полето са ограничени до float, ints, низове и булеви стойности и не могат да бъдат променяни без пренаписване на данните. Стойностите на етикета са индексирани. Те са представени като низове и не могат да бъдат актуализирани.
InfluxDB е доста лесно да започнете, тъй като не е нужно да се притеснявате за създаване на схеми или индекси. Въпреки това, той е доста твърд и ограничен, без възможност за създаване на допълнителни индекси, индекси в непрекъснати полета, актуализиране на метаданни след факта, налагане на валидиране на данни и т.н.
Не е безсхемен. Има основна схема, която се създава автоматично от входните данни.
InfluxDB трябва да внедри от нулата няколко инструмента за устойчивост на грешки, като репликация, висока наличност и архивиране/възстановяване, и е отговорен за неговата надеждност на диска. Ние сме ограничени до използването на тези инструменти и много от тези функции, като HA, са налични само в корпоративната версия.
Инструментът за архивиране на InfluxDB може да извършва пълно или инкрементално архивиране и може да се използва за възстановяване в даден момент.
InfluxDB също така предлага значително по-добра компресия на диска от PostgreSQL и TimescaleDB.
TimescaleDB
TimescaleDB е база данни с времеви серии с отворен код, оптимизирана за бързо поглъщане и сложни заявки, която поддържа пълен SQL. Той е базиран на PostgreSQL и предлага най-доброто от NoSQL и релационните светове за данни от времеви серии.
Това е пример за заявка TimescaleDB:
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM testing
WHERE measurement = cpu and time > now() - '1 hour';TimescaleDB, като разширение на PostgreSQL, е релационна база данни. Това позволява да имате кратка крива на обучение за новите потребители и да наследите инструменти като pg_dump или pg_backup за архивиране и инструменти с висока наличност, което е предимство пред други бази данни от времеви серии. Той също така поддържа стрийминг репликация като основен метод за репликация, който може да се използва при настройка с висока наличност. По отношение на отказ и архивиране, можете да автоматизирате този процес, като използвате външна система като ClusterControl.
В TimescaleDB всяко измерване на времеви серии се записва в отделен ред, с поле за време, последвано от произволен брой други полета, които могат да бъдат float, ints, низове, булеви стойности, масиви, JSON блобове, геопространствени измерения, дата/час/ времеви марки, валути, двоични данни и др.
Можете да създавате индекси за всяко поле (стандартни индекси) или множество полета (композитни индекси), или за изрази като функции или дори да ограничите индекс до подмножество от редове (частичен индекс). Всяко от тези полета може да се използва като външен ключ към вторични таблици, които след това могат да съхраняват допълнителни метаданни.
По този начин трябва да изберете схема и да решите кои индекси ще са ви необходими за вашата система.
Ефективност
Ако говорим за производителност, можем да проверим страхотния блог за сравнение на TimescaleDB. Там имате подробно сравнение за производителност между двете бази данни с диаграми и показатели. Нека видим някои от най-важната информация от този блог.
Вложки
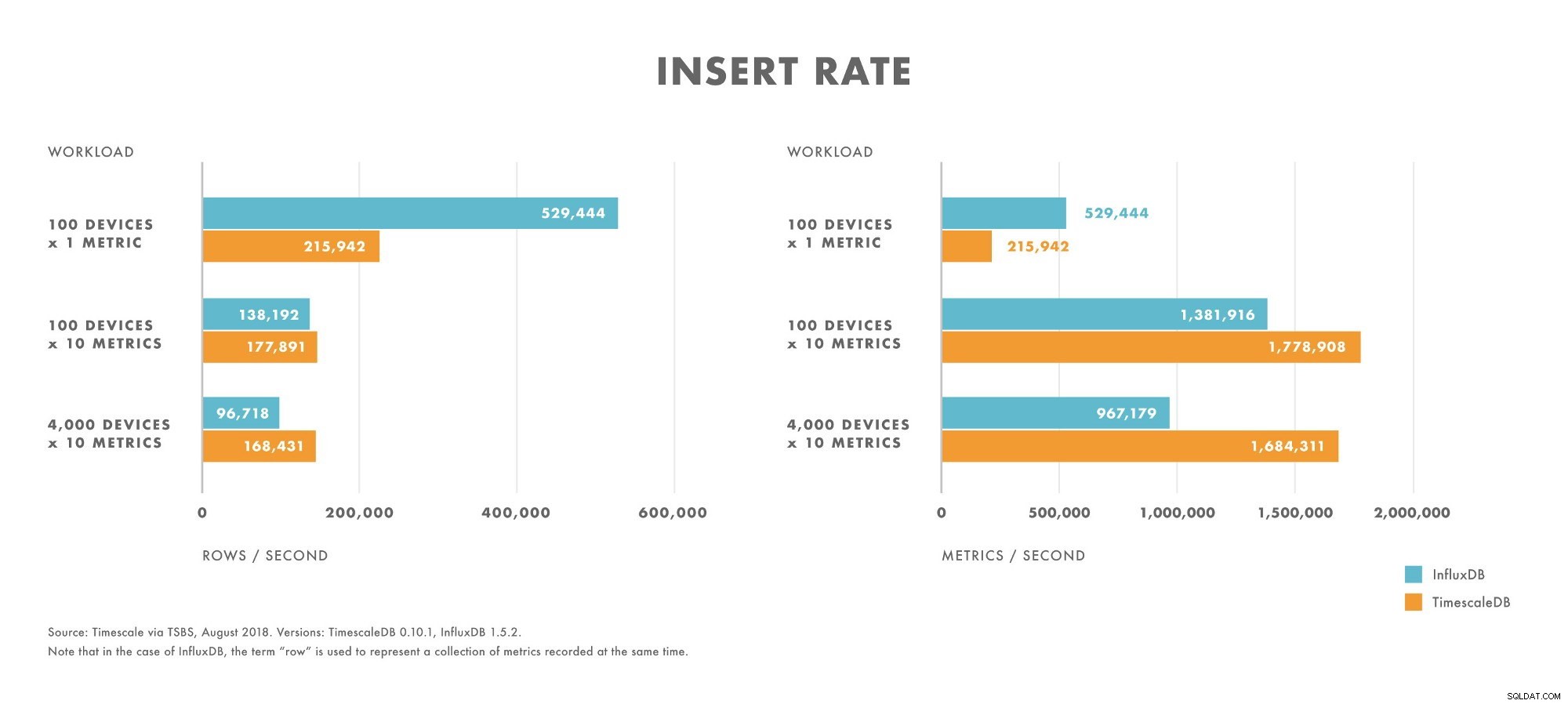
- За натоварвания с много ниска мощност (напр. 100 устройства) InfluxDB превъзхожда TimescaleDB.
- С увеличаването на мощността производителността на вмъкване на InfluxDB спада по-бързо, отколкото при TimescaleDB.
- За натоварвания с умерена до висока мощност (напр. 100 устройства, изпращащи 10 показателя), TimescaleDB превъзхожда InfluxDB.

Забавяне на четене
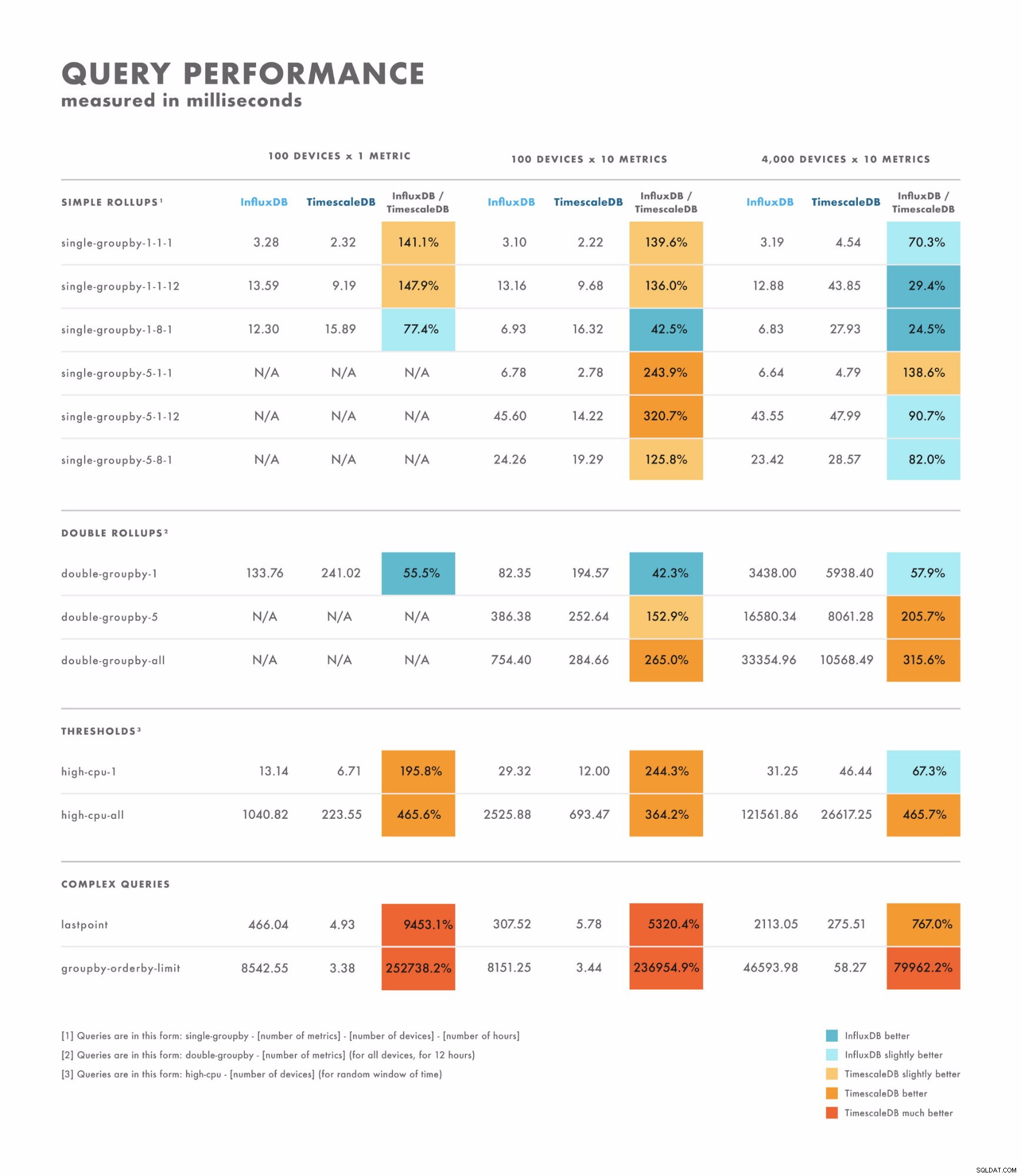
- При прости заявки резултатите се различават доста:има някои, при които една база данни е очевидно по-добра от другата, докато други зависят от мощността на вашия набор от данни. Разликата тук често е в диапазона от едноцифрени до двуцифрени милисекунди.
- За сложни заявки TimescaleDB значително превъзхожда InfluxDB и поддържа по-широк набор от типове заявки. Разликата тук често е в диапазона от секунди до десетки секунди.
- Имайки това предвид, най-добрият начин за правилно тестване е да сравните с помощта на заявките, които планирате да изпълните.
Проблеми със стабилността
- InfluxDB има проблеми със стабилността и производителността при високи (100K+) мощности.
Заключение
Ако вашите данни се вписват в модела на данни InfluxDB и не очаквате да се променят в бъдеще, тогава трябва да помислите за използването на InfluxDB, тъй като този модел е по-лесен за започване и подобно на повечето бази данни, които използват подход, ориентиран към колони, предлага по-добра компресия на диска от PostgreSQL и TimescaleDB.
Въпреки това, релационният модел е по-гъвкав и предлага повече функционалност, гъвкавост и контрол от модела InfluxDB. Това е особено важно, тъй като вашето приложение се развива. И когато планирате вашата система, трябва да вземете предвид както настоящите, така и бъдещите й нужди.
В този блог можем да видим кратко сравнение между TimescaleDB и InfluxDB и можем да кажем, че TimescaleDB като разширение на PostgreSQL изглежда доста зряло и богато на функции, тъй като наследява много от PostgreSQL. Но можете да вземете свое собствено решение въз основа на плюсовете и минусите, споменати по-рано в този блог, и се уверете, че сте сравнили собственото си работно натоварване. Успех в този нов свят на база данни от времеви серии!