Ключови неща за наблюдение в PostgreSQL – анализиране на вашето работно натоварване
В компютърните системи мониторингът е процес на събиране на показатели, анализиране, изчисляване на статистически данни и генериране на обобщения и графики относно производителността или капацитета на системата, както и генериране на сигнали в случай на неочаквани проблеми или повреди, които изискват незабавно внимание или действие. Следователно мониторингът има две приложения:едно за анализ и представяне на исторически данни, което ни помага да идентифицираме средносрочни и дългосрочни тенденции в нашата система и по този начин ни помага да планираме надстройки, и второ за незабавни действия в случай на проблем.
Наблюдението ни помага да идентифицираме проблеми и да реагираме на тези проблеми, отнасящи се до широк спектър от полета, като например:
- Инфраструктура/Хардуер (физическа или виртуална)
- Мрежа
- Съхранение
- Системен софтуер
- Приложен софтуер
- Сигурност
Мониторингът е основна част от работата на DBA. PostgreSQL, традиционно, е известен като „ниска поддръжка“ благодарение на усъвършенствания си дизайн и това означава, че системата може да живее с ниска посещаемост в сравнение с други алтернативи. Въпреки това, за сериозни инсталации, при които високата наличност и производителност са от ключово значение, системата от база данни трябва да се наблюдава редовно.
Ролята на PostgreSQL DBA може да се издигне до по-високи нива в йерархията на компанията, освен строго техническа:освен основното наблюдение и анализ на ефективността, трябва да може да забелязва промените в моделите на използване, да идентифицира възможните причини, да проверява предположенията и накрая да превежда констатации в бизнес план. Като пример, DBA трябва да може да идентифицира някаква внезапна промяна в определена дейност, която може да бъде свързана с възможна заплаха за сигурността. Така че ролята на PostgreSQL DBA е ключова роля в компанията и трябва да работи в тясно сътрудничество с други ръководители на отдели, за да идентифицира и решава проблемите, които възникват. Наблюдението е голяма част от тази отговорност.
PostgreSQL предоставя много готови инструменти, които ни помагат да събираме и анализираме данни. Освен това, поради своята разширяемост, той предоставя средства за разработване на нови модули в основната система.
PostgreSQL е силно зависим от системата (хардуер и софтуер), на която работи. Не можем да очакваме PostgreSQL сървър да работи добре, ако има проблеми в някой от жизненоважните компоненти в останалата част от системата. Така ролята на PostgreSQL DBA се припокрива с ролята на системния администратор. По-долу, докато разглеждаме какво да гледаме в мониторинга на PostgreSQL, ще се сблъскаме както с зависими от системата променливи и показатели, така и с конкретни цифри на PostgreSQL.
Наблюдението не е безплатно. Компанията/организацията трябва да инвестира добра инвестиция в него с ангажимент да управлява и поддържа целия процес на наблюдение. Той също така добавя леко натоварване на сървъра на PostgreSQL. Това е малко повод за притеснение, ако всичко е конфигурирано правилно, но трябва да имаме предвид, че това може да е друг начин за злоупотреба със системата.
Основи на системния мониторинг
Важни променливи в системния мониторинг са:
- Използване на процесора
- Използване на мрежата
- Дисково пространство/Използване на диска
- Използване на RAM
- Диск IOPS
- Използване на място за размяна
- Грешки в мрежата
Ето пример за ClusterControl, показващ графики за някои критични PostgreSQL променливи, идващи от pg_stat_database и pg_stat_bgwriter (които ще разгледаме в следващите параграфи), докато изпълнявате pgbench -c 64 -t 1000 pgbench два пъти:

Забелязваме, че имаме пик на четените блокове при първото изпълнение, но се приближаваме до нула по време на второто изпълнение, тъй като всички блокове се намират в shared_buffers.
Други интересни променливи са активността на пейджинг, прекъсвания, превключване на контекста, наред с други. Има множество инструменти за използване в Linux/BSD и unix или unix-подобни системи. Някои от тях са:
-
ps:за списък на работещите процеси
-
top/htop/systat:за наблюдение на използването на системата (CPU/памет)
-
vmstat:за мониторинг на общата системна активност (включително виртуална памет)
-
iostat/iotop/top -mio:за мониторинг на IO
-
ntop:за наблюдение на мрежата
Ето пример за vmstat в кутия FreeBSD по време на заявка, която изисква известно четене на диск, а също и известно изчисление:
procs memory page disks faults cpu
r b w avm fre flt re pi po fr sr ad0 ad1 in sy cs us sy id
0 0 0 98G 666M 421 0 0 0 170 2281 5 0 538 6361 2593 1 1 97
0 0 0 98G 665M 141 0 0 0 0 2288 13 0 622 11055 3748 3 2 94
--- query starts here ---
0 0 0 98G 608M 622 0 0 0 166 2287 1072 0 1883 16496 12202 3 2 94
0 0 0 98G 394M 101 0 0 0 2 2284 4578 0 5815 24236 39205 3 5 92
2 0 0 98G 224M 4861 0 0 0 1711 2287 3588 0 4806 24370 31504 4 6 91
0 0 0 98G 546M 84 188 0 0 39052 41183 2832 0 4017 26007 27131 5 7 88
2 0 0 98G 469M 418 0 0 1 397 2289 1590 0 2356 11789 15030 2 2 96
0 0 0 98G 339M 112 0 0 0 348 2300 2852 0 3858 17250 25249 3 4 93
--- query ends here ---
1 0 0 98G 332M 1622 0 0 0 213 2289 4 0 531 6929 2502 3 2 95Повтаряйки заявката, няма да забележим нов взрив в дисковата активност, тъй като тези блокове диск вече биха били в кеша на операционната система. Въпреки че PostgreSQL DBA трябва да може напълно да разбере какво се случва в основната инфраструктура, където се изпълнява базата данни, по-сложното наблюдение на системата обикновено е работа за системния администратор, тъй като това е голяма тема само по себе си.
В linux, много удобен пряк път за горе помощната програма натиска „C“, което превключва показването на командния ред на процесите. PostgreSQL по подразбиране пренаписва командния ред на бекенда с действителната SQL активност, която изпълняват в момента, а също и с потребителя.
Основи на наблюдението на PostgreSQL
Важни променливи в мониторинга на PostgreSQL са:
- Ефективност на кеша на буфера (посещения в кеша срещу четене на диск)
- Брой ангажименти
- Брой връзки
- Брой сесии
- Контролни точки и статистика за bgwriter
- Прахосмукачки
- Ключи
- Репликация
- И не на последно място, запитвания
Обикновено има два начина в настройката за наблюдение за извършване на събиране на данни:
- За получаване на данни чрез регистрационен файл
- За получаване на данни чрез запитване на системата PostgreSQL
Получаването на данни, базирано на регистрационни файлове, зависи от (правилно конфигурирания) дневник на PostgreSQL. Можем да използваме този вид регистриране за „офлайн“ обработка на данните. Мониторингът, базиран на регистрационни файлове, е най-подходящ, когато се изискват минимални разходи за PostgreSQL сървъра и когато не ни пука за данни на живо или за получаване на сигнали на живо (въпреки че наблюдението на живо с помощта на данни от лог файл може да бъде възможно, например чрез насочване на регистрационния файл на postgresql към syslog и след това поточно системния журнал към друг сървър, предназначен за обработка на регистрационни файлове).
Изтеглете Бялата книга днес Управление и автоматизация на PostgreSQL с ClusterControl Научете какво трябва да знаете, за да внедрите, наблюдавате, управлявате и мащабирате PostgreSQLD Изтеглете Бялата книгаPostgreSQL Statistics Collector
PostgreSQL предоставя богат набор от изгледи и функции, лесно достъпни чрез подсистемата Statistics Collector. Отново тези данни са разделени в две категории:
- Динамична информация за това какво прави системата в момента.
- Статистика, натрупана след последното нулиране на подсистемата за събиране на статистики.
Динамични статистически изгледи предоставя информация за текущата активност на процес (pg_stat_activity), състояние на физическа репликация (pg_stat_replication), състояние на физическа готовност (pg_stat_wal_receiver) или логическо (pg_stat_subscription), ssl (pg_stat_ssl) и вакуум (pg_stat_progress>_vacuum).
Събрани статистически изгледи предоставя информация за важни фонови процеси като wal archiver, bgwriter и обекти на база данни:потребителски или системни таблици, индекси, последователности и функции, както и самите бази данни.Вече трябва да е съвсем очевидно, че има множество начини за категоризиране на данните, свързани с наблюдението:
- По източник:
- Системни инструменти (ps, top, iotop и др.)
- Регистрационен файл на PgSQL
- База данни
- Динамичен
- Събрани
- По конкретна операция с база данни:
- Буферен кеш
- Отвързване
- Запитвания
- Сесии
- Пропускателни пунктове
- И др.
След като прочетете тази статия и експериментирате с представените понятия, концепции и термини, трябва да можете да направите 2D матрица с всички възможни комбинации. Като пример, конкретната дейност на PostgreSQL (SQL команда) може да бъде намерена с помощта на:ps или top (системни помощни програми), регистрационните файлове на PostgreSQL, pg_stat_activity (динамичен изглед), но също така с помощта на pg_stat_statements разширение, намерено в contrib (събран изглед на статистиката) . По същия начин информация за заключване може да бъде намерена в регистрационните файлове на PostgreSQL, pg_locks и pg_stat_activity (представено малко по-долу) с помощта на wait_event и тип_на_събитие . Поради това е трудно да се покрие огромната област на наблюдение по едномерен линеен начин и авторът рискува да създаде объркване на читателя поради това. За да избегнем това, ще покрием наблюдението приблизително, като следваме хода на официалната документация и добавяме свързана информация, ако е необходимо.
Динамични статистически изгледи
Използване на pg_stat_activity ние сме в състояние да видим каква е текущата активност от различните бекенд процеси. Например, ако изпълним следната заявка върху части от таблицата с около 3M реда:
testdb=# \d parts
Table "public.parts"
Column | Type | Collation | Nullable | Default
------------+------------------------+-----------+----------+---------
id | integer | | |
partno | character varying(20) | | |
partname | character varying(80) | | |
partdescr | text | | |
machine_id | integer | | |
parttype | character varying(100) | | |
date_added | date | | |И нека изпълним следната заявка, която се нуждае от няколко секунди, за да завърши:
testdb=# select avg(age(date_added)) FROM parts;Като отворим нов терминал и изпълним следната заявка, докато предишната все още работи, получаваме:
testdb=# select pid,usename,application_name,client_addr,backend_start,xact_start,query_start,state,backend_xid,backend_xmin,query,backend_type from pg_stat_activity where datid=411547739 and usename ='achix' and state='active';
-[ RECORD 1 ]----+----------------------------------------
pid | 21305
usename | achix
application_name | psql
client_addr |
backend_start | 2018-03-02 18:04:35.833677+02
xact_start | 2018-03-02 18:04:35.832564+02
query_start | 2018-03-02 18:04:35.832564+02
state | active
backend_xid |
backend_xmin | 438132638
query | select avg(age(date_added)) FROM parts;
backend_type | background worker
-[ RECORD 2 ]----+----------------------------------------
pid | 21187
usename | achix
application_name | psql
client_addr |
backend_start | 2018-03-02 18:02:06.834787+02
xact_start | 2018-03-02 18:04:35.826065+02
query_start | 2018-03-02 18:04:35.826065+02
state | active
backend_xid |
backend_xmin | 438132638
query | select avg(age(date_added)) FROM parts;
backend_type | client backend
-[ RECORD 3 ]----+----------------------------------------
pid | 21306
usename | achix
application_name | psql
client_addr |
backend_start | 2018-03-02 18:04:35.837829+02
xact_start | 2018-03-02 18:04:35.836707+02
query_start | 2018-03-02 18:04:35.836707+02
state | active
backend_xid |
backend_xmin | 438132638
query | select avg(age(date_added)) FROM parts;
backend_type | background workerИзгледът pg_stat_activity ни дава информация за задния процес, потребителя, клиента, транзакцията, заявката, състоянието, както и изчерпателна информация за състоянието на изчакване на заявката.
Но защо 3 реда? Във версии>=9.6, ако заявка може да се изпълнява паралелно или части от нея могат да се изпълняват паралелно и оптимизаторът смята, че паралелното изпълнение е най-бързата стратегия, тогава той създава Gather или Gather Merge възел и след това иска най-много max_parallel_workers_per_gather фонови работни процеси, които по подразбиране са 2, следователно 3-те реда, които виждаме в изхода по-горе. Можем да различим клиентския бекенд процес от фоновия работник, като използваме backend_type колона. За да бъде активиран изгледът pg_stat_activity, ще трябва да се уверите, че системният конфигурационен параметър track_activities е включено. pg_stat_activity предоставя богата информация за определяне на блокирани заявки чрез използване на колони wait_event_type и wait_event.
По-прецизен начин за наблюдение на изявленията е чрез pg_stat_statements contrib разширение, споменато по-рано. На скорошна Linux система (Ubuntu 17.10, PostgreSQL 9.6), това може да се инсталира доста лесно:
testdb=# create extension pg_stat_statements ;
CREATE EXTENSION
testdb=# alter system set shared_preload_libraries TO 'pg_stat_statements';
ALTER SYSTEM
testdb=# \q
example@sqldat.com:~$ sudo systemctl restart postgresql
example@sqldat.com:~$ psql testdb
psql (9.6.7)
Type "help" for help.
testdb=# \d pg_stat_statementsНека създадем таблица с 100 000 реда и след това нулираме pg_stat_statements, рестартираме PostgreSQL сървъра, извършваме избор на тази таблица на (все още студена) система и след това видим съдържанието на pg_stat_statements за избрания:
testdb=# select 'descr '||gs as descr,gs as id into medtable from generate_series(1,100000) as gs;
SELECT 100000
testdb=# select pg_stat_statements_reset();
pg_stat_statements_reset
--------------------------
(1 row)
testdb=# \q
example@sqldat.com:~$ sudo systemctl restart postgresql
example@sqldat.com:~$ psql testdb -c 'select * from medtable' > /dev/null
testdb=# select shared_blks_hit,shared_blks_read from pg_stat_statements where query like '%select%from%medtable%';
shared_blks_hit | shared_blks_read
-----------------+------------------
0 | 541
(1 row)
testdb=#Сега нека изпълним избора * още веднъж и след това да погледнем отново в съдържанието на pg_stat_statements за тази заявка:
example@sqldat.com:~$ psql testdb -c 'select * from medtable' > /dev/null
example@sqldat.com:~$ psql testdb
psql (9.6.7)
Type "help" for help.
testdb=# select shared_blks_hit,shared_blks_read from pg_stat_statements where query like '%select%from%medtable%';
shared_blks_hit | shared_blks_read
-----------------+------------------
541 | 541
(1 row)И така, втория път, когато операторът select намира всички необходими блокове в споделените буфери на PostgreSQL и pg_stat_statements отчита това чрез shared_blks_hit . pg_stat_statements предоставя информация за общия брой извиквания на оператор, total_time, min_time, max_time и mean_time, което може да бъде изключително полезно, когато се опитвате да анализирате натоварването на вашата система. Бавна заявка, която се изпълнява много често, трябва да изисква незабавно внимание. По същия начин, постоянно ниските нива на посещения може да означават необходимостта от преглед на споделените_буфери настройка.
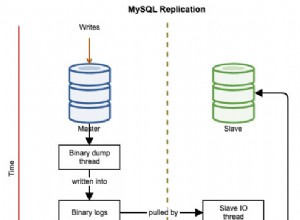
pg_stat_replication предоставя информация за текущото състояние на репликация за всеки wal_sender. Да предположим, че сме настроили проста топология на репликация с нашия първичен и един горещ режим на готовност, тогава можем да потърсим pg_stat_replication на първичния (правянето на същото в режим на готовност няма да доведе до никакви резултати, освен ако не сме настроили каскадна репликация и този специфичен режим на готовност служи като upstream към други резерви надолу по веригата), за да видите текущото състояние на репликация:
testdb=# select * from pg_stat_replication ;
-[ RECORD 1 ]----+------------------------------
pid | 1317
usesysid | 10
usename | postgres
application_name | walreceiver
client_addr | 10.0.2.2
client_hostname |
client_port | 48192
backend_start | 2018-03-03 11:59:21.315524+00
backend_xmin |
state | streaming
sent_lsn | 0/3029DB8
write_lsn | 0/3029DB8
flush_lsn | 0/3029DB8
replay_lsn | 0/3029DB8
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async4-те колони sent_lsn , write_lsn , flush_lsn , replay_lsn кажете ни точната позиция на WAL на всеки етап от процеса на репликация в отдалечения режим на готовност. След това създаваме интензивен трафик на основния с команда като:
testdb=# insert into foo(descr) select 'descr ' || gs from generate_series(1,10000000) gs;И вижте pg_stat_replication отново:
postgres=# select * from pg_stat_replication ;
-[ RECORD 1 ]----+------------------------------
pid | 1317
usesysid | 10
usename | postgres
application_name | walreceiver
client_addr | 10.0.2.2
client_hostname |
client_port | 48192
backend_start | 2018-03-03 11:59:21.315524+00
backend_xmin |
state | streaming
sent_lsn | 0/D5E0000
write_lsn | 0/D560000
flush_lsn | 0/D4E0000
replay_lsn | 0/C5FF0A0
write_lag | 00:00:04.166639
flush_lag | 00:00:04.180333
replay_lag | 00:00:04.614416
sync_priority | 0
sync_state | asyncСега виждаме, че имаме забавяне между основното и режима на готовност, изобразени в sent_lsn , write_lsn , flush_lsn , replay_lsn стойности. От PgSQL 10.0 pg_stat_replication също показва изоставането между наскоро локално прочистен WAL и времето, необходимо за дистанционно записване, прочистване и повторно възпроизвеждане съответно. Виждането на нулеви стойности в тези 3 колони означава, че основният и режимът на готовност са синхронизирани.
Еквивалентът на pg_stat_replication от страната на готовност се нарича:pg_stat_wal_receiver:
testdb=# select * from pg_stat_wal_receiver ;
-[ RECORD 1 ]---------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 17867
status | streaming
receive_start_lsn | 0/F000000
receive_start_tli | 1
received_lsn | 0/3163F210
received_tli | 1
last_msg_send_time | 2018-03-03 13:32:42.516551+00
last_msg_receipt_time | 2018-03-03 13:33:28.644394+00
latest_end_lsn | 0/3163F210
latest_end_time | 2018-03-03 13:32:42.516551+00
slot_name | fbsdclone
conninfo | user=postgres passfile=/usr/local/var/lib/pgsql/.pgpass dbname=replication host=10.0.2.2 port=20432 fallback_application_name=walreceiver sslmode=disable sslcompression=1 target_session_attrs=any
testdb=#Когато няма активност и в режим на готовност е възпроизведено всичко, тогава latest_end_lsn трябва да е равно на sent_lsn на основния (и всички междинни последователни номера на журнала).
Подобно на физическата репликация, в случай на логическа репликация, където ролята на основното се поема от издателя, а ролята на резервно състояние се поема от абоната, естествено ролята на pg_stat_wal_receiver се взема от pg_stat_subscription . Можем да направим заявка за pg_stat_subscription както следва:
testdb=# select * from pg_stat_subscription ;
-[ RECORD 1 ]---------+------------------------------
subid | 24615
subname | alltables_sub
pid | 1132
relid |
received_lsn | 0/33005498
last_msg_send_time | 2018-03-03 17:05:36.004545+00
last_msg_receipt_time | 2018-03-03 17:05:35.990659+00
latest_end_lsn | 0/33005498
latest_end_time | 2018-03-03 17:05:36.004545+00Обърнете внимание, че от страна на издателя съответният изглед е същият като в случая на физическо репликация:pg_stat_replication .
Събрани статистически изгледи
pg_stat_archiver изгледът има един ред, който дава информация за wal архиватора. Поддържането на моментна снимка на този ред на редовни интервали ви позволява да изчислите размера на WAL трафика между тези интервали. Също така дава информация за неуспехи при архивиране на WAL файлове.
pg_stat_bgwriter view дава много важна информация за поведението на:
- Контролният указател
- Основният автор
- Берендовете (обслужващи клиенти)
Тъй като този изглед дава натрупващи се данни от последното нулиране, е много полезно да създадете друга таблица с времеви отпечатъци с периодични снимки на pg_stat_bgwriter , така че ще бъде лесно да се получи постепенна перспектива между две моментни снимки. Настройката е наука (или магия) и изисква обширно регистриране и наблюдение, както и ясно разбиране на основните концепции и вътрешните елементи на PostgreSQL, за да имате добри резултати и този изглед е откъде да започнете, търсейки неща като:
- Определени ли са контролните точки по-голямата част от общите контролно-пропускателни пунктове? Ако не, тогава трябва да се предприемат действия, да се измерят резултатите и да се повтори целият процес, докато не се намерят подобрения.
- Та са buffers_checkpoint добро мнозинство спрямо другите два вида (buffers_clean но най-важното buffers_backend ) ? Ако buffers_backend са високи, тогава отново трябва да се променят определени параметри на конфигурацията, да се направят нови измервания и да се преоценят.
Pg_stat_[user|sys|all]_tables
Най-основната употреба на тези изгледи е да се провери дали нашата вакуумна стратегия работи според очакванията. Големите стойности на мъртвите кортежи в сравнение с живите кортежи означават неефективно вакуумиране. Тези изгледи също предоставят информация за сканирането и извличането на последователни спрямо индекси, информация за броя на вмъкнатите, актуализирани, изтрити редове, както и ГОРЕЩИ актуализации. Трябва да се опитате да поддържате броя на ГОРЕЩИТЕ актуализации възможно най-висок, за да подобрите производителността.
Pg_stat_[user|sys|all]_indexes
Тук системата съхранява и показва информация за индивидуалното използване на индекса. Едно нещо, което трябва да имате предвид, е, че idx_tup_read е по-точен от idx_tup_fetch. Не PK/ неуникални индекси с нисък idx_scan трябва да се обмислят за премахване, тъй като те само възпрепятстват ГОРЕЩИТЕ актуализации. Както беше споменато в предишния блог, прекомерното индексиране трябва да се избягва, индексирането е на цена.
Pg_statio_[user|sys|all]_tables
В тези изгледи можем да намерим информация за производителността на кеша по отношение на четене на купчина таблица, четене на индекс и четене на TOAST. Проста заявка за отчитане на процента на посещенията и разпределението на посещенията в таблици би било:
with statioqry as (select relid,heap_blks_hit,heap_blks_read,row_number() OVER (ORDER BY 100.0*heap_blks_hit::numeric/(heap_blks_hit+heap_blks_read) DESC),COUNT(*) OVER () from pg_statio_user_tables where heap_blks_hit+heap_blks_read >0)
select relid,row_number,100.0*heap_blks_hit::float8/(heap_blks_hit+heap_blks_read) as "heap block hits %", 100.0 * row_number::real/count as "In top %" from statioqry order by row_number;
relid | row_number | heap block hits % | In top %
-----------+------------+-------------------+-------------------
16599 | 1 | 99.9993058404502 | 0.373134328358209
18353 | 2 | 99.9992251425738 | 0.746268656716418
18338 | 3 | 99.99917566565 | 1.11940298507463
17269 | 4 | 99.9990617323798 | 1.49253731343284
18062 | 5 | 99.9988021889522 | 1.86567164179104
18075 | 6 | 99.9985334109273 | 2.23880597014925
18365 | 7 | 99.9968070500335 | 2.61194029850746
………..
18904 | 127 | 97.2972972972973 | 47.3880597014925
18801 | 128 | 97.1631205673759 | 47.7611940298507
16851 | 129 | 97.1428571428571 | 48.134328358209
17321 | 130 | 97.0043198249512 | 48.5074626865672
17136 | 131 | 97 | 48.8805970149254
17719 | 132 | 96.9791612263018 | 49.2537313432836
17688 | 133 | 96.969696969697 | 49.6268656716418
18872 | 134 | 96.9333333333333 | 50
17312 | 135 | 96.8181818181818 | 50.3731343283582
……………..
17829 | 220 | 60.2721026527734 | 82.089552238806
17332 | 221 | 60.0276625172891 | 82.4626865671642
18493 | 222 | 60 | 82.8358208955224
17757 | 223 | 59.7222222222222 | 83.2089552238806
17586 | 224 | 59.4827586206897 | 83.5820895522388Това ни казва, че най-малко 50% от таблиците имат процент на попадение, по-голям от 96,93%, а 83,5% от масите имат процент на попадение, по-добър от 59,4%
Pg_statio_[user|sys|all]_indexes
Този изглед съдържа информация за блоково четене/попадане за индекси.
Pg_stat_database
Този изглед съдържа по един ред на база данни. Той показва част от информацията от предходните изгледи, обобщена към цялата база данни (прочетени блокове, удари на блокове, информация за tups), част от информацията, свързана с цялата база данни (общо действия, временни файлове, конфликти, прекъсвания, време за четене/запис) и накрая брой текущи бекендове.
Нещата, които трябва да търсите тук, са съотношението blks_hit/(blks_hit + blks_read) :колкото по-висока е стойността, толкова по-добре за I/O на системата. Въпреки това пропуските не трябва непременно да се отчитат за четене на диск, тъй като те може да са били много добре обслужени от кеша на файловите системи на операционната система.
Подобно на други събрани статистически изгледи, споменати по-горе, трябва да се създаде версия с времеви печат на pg_stat_database вижте и имайте представа за разликите между две последователни моментни снимки:
- Увеличава ли се броят на връщанията?
- Или броя на извършените действия?
- Получаваме ли много повече конфликти от вчера (това се отнася за режимите на готовност)?
- Имаме ли необичайно голям брой блокирания?
Всичко това са много важни данни. Първите две може да означават някаква промяна в някакъв модел на използване, което трябва да бъде обяснено. Големият брой конфликти може да означава, че репликацията се нуждае от известна настройка. Големият брой блокирания е лош по много причини. Не само производителността е ниска, защото транзакциите се връщат назад, но и ако приложение страда от блокиране в една топология на главната, проблемите ще се засилят само ако преминем към мулти-главен. В този случай отделът за софтуерно инженерство трябва да пренапише парчетата от кода, които причиняват блокирането.
Ключи
Свързани ресурси ClusterControl за PostgreSQL Как да управлявате и наблюдавате съществуващия си Postgres сървър Как да сравните производителността на PostgreSQLЗаключването е много важна тема в PostgreSQL и заслужава собствен блог(и). Въпреки това основното наблюдение на бравите трябва да се извършва по същия начин като другите аспекти на наблюдението, представени по-горе. pg_locks view предоставя информация в реално време за текущите ключалки в системата. Можем да хванем дълго чакащи заключвания, като зададем log_lock_waits , тогава информацията за дълго чакане ще бъде регистрирана в дневника на PgSQL. Ако забележим необичайно високо заключване, което води до дълго чакане, както в случая със споменатите по-горе блокирания, софтуерните инженери трябва да прегледат всички части от кода, които могат да причинят дълго задържани заключвания, напр. изрично заключване в приложението (ЗАКЛЮЧАЙТЕ ТАБЛИЦА или ИЗБЕРЕТЕ... ЗА АКТУАЛИЗИРАНЕ).
Подобно на случаите на блокиране, система с къси заключвания ще премине по-лесно към настройка с няколко главни.