Въведение
Рано или късно всяка информационна система получава база данни, често – повече от една. С течение на времето тази база данни събира много данни, от няколко GB до десетки TB. За да разберем как ще се представят функциите с увеличаване на обема данни, трябва да генерираме данните, за да попълним тази база данни.

Всички представени и внедрени скриптове ще се изпълняват в JobEmplDB база данни на услуга за набиране на персонал. Реализацията на базата данни е достъпна тук.
Подходи за попълване на данни в бази данни за тестване и разработка
Разработването и тестването на база данни включват два основни подхода за попълване на данни:
- Да копирате цялата база данни от производствената среда с променени лични и други чувствителни данни. По този начин гарантирате данните и изтривате поверителни данни.
- За генериране на синтетични данни. Това означава генериране на тестови данни, подобни на реалните данни във вид, свойства и взаимовръзки.
Предимството на Подход 1 е, че приближава данните и тяхното разпределение по различни критерии към производствената база данни. Позволява ни да анализираме всичко прецизно и следователно да правим заключения и прогнози.
Този подход обаче не ви позволява да увеличите многократно самата база данни. Става проблематично да се предвидят промени във функционалността на цялата информационна система в бъдеще.
От друга страна, можете да анализирате безлични дезинфекцирани данни, взети от производствената база данни. Въз основа на тях можете да дефинирате как да генерирате тестови данни, които биха били като реалните данни по техния външен вид, свойства и взаимовръзки. По този начин Подход 1 произвежда Подход 2.
Сега нека разгледаме подробно и двата подхода за попълване на данни в бази данни за тестване и разработка.
Копиране и промяна на данни в производствена база данни
Първо, нека дефинираме общия алгоритъм за копиране и промяна на данните от производствената среда.
Общият алгоритъм
Общият алгоритъм е следният:
- Създайте нова празна база данни.
- Създайте схема в тази новосъздадена база данни – същата система като тази от производствената база данни.
- Копирайте необходимите данни от производствената база данни в новосъздадената база данни.
- Почистете и променете секретните данни в новата база данни.
- Направете резервно копие на новосъздадената база данни.
- Доставете и възстановете архива в необходимата среда.
Алгоритъмът обаче става по-сложен след стъпка 5. Например, стъпка 6 изисква специфична, защитена среда за предварително тестване. Този етап трябва да гарантира, че всички данни са безлични и секретните данни са променени.
След този етап можете отново да се върнете към стъпка 5 за тестваната база данни в защитената непроизводствена среда. След това препращате тествания архив към необходимите среди, за да го възстановите и да го използвате за разработка и тестване.
Представихме общия алгоритъм за копиране и промяна на данните на производствената база данни. Нека опишем как да го приложим.
Реализация на общия алгоритъм
Създаване на нова празна база данни
Можете да направите празна база данни с помощта на конструкцията CREATE DATABASE, както е тук.
Базата данни се казва JobEmplDB_Test . Има три файлови групи:
- ОСНОВНО – това е основната файлова група по подразбиране. Той дефинира два файла:JobEmplDB_Test1(път D:\DBData\JobEmplDB_Test1.mdf) и JobEmplDB_Test2 (път D:\DBData\JobEmplDB_Test2.ndf) . Първоначалният размер на всеки файл е 64 Mb, а стъпката на растеж е 8 Mb за всеки файл.
- DBTableGroup – персонализирана файлова група, която определя два файла:JobEmplDB_TestTableGroup1 (път D:\DBData\JobEmplDB_TestTableGroup1.ndf) и JobEmplDB_TestTableGroup2 (път D:\DBData\JobEmplDB_TestTableGroup2.ndf) . Първоначалният размер на всеки файл е 8 Gb, а стъпката на растеж е 1 Gb за всеки файл.
- DBIndexGroup – персонализирана файлова група, която определя два файла:JobEmplDB_TestIndexGroup1 (път D:\DBData\JobEmplDB_TestIndexGroup1.ndf) и JobEmplDB_TestIndexGroup2 (път D:\DBData\JobEmplDB_TestIndexGroup2.ndf) . Първоначалният размер е 16 Gb за всеки файл, а стъпката на растеж е 1 Gb за всеки файл.
Освен това тази база данни включва едно дневник на транзакциите:JobEmplDB_Testlog , път E:\DBlog\JobEmplDB_Testlog.ldf . Първоначалният размер на файла е 8 Gb, а стъпката на растеж е 1 Gb.
Копиране на схемата и необходимите данни от производствената база данни в новосъздадена база данни
За да копирате схемата и необходимите данни от производствената база данни в новата, можете да използвате няколко инструмента. Първо, това е Visual Studio (SSDT). Или можете да използвате помощни програми на трети страни като:
- Сравнение на DbForge Schema и DbForge Data Compare
- ApexSQL Diff и Apex Data Diff
- Инструмент за сравнение на SQL и инструмент за сравнение на SQL данни
Създаване на скриптове за промени в данните
Основни изисквания за скриптовете за промени в данните
1. Трябва да е невъзможно възстановяването на реалните данни с помощта на този скрипт.
например, инверсията на линиите не е подходяща, тъй като ни позволява да възстановим реалните данни. Обикновено методът е да се замени всеки знак или байт с псевдослучаен знак или байт. Същото важи и за датата и часа.
2. Промяната на данните не трябва да променя селективността на техните стойности.
Няма да работи да присвоите NULL на полето на таблицата. Вместо това трябва да гарантирате, че същите стойности в реалните данни ще останат същите в променените данни. Например, в реални данни имате стойност от 103785, намерена 12 пъти в таблицата. Когато промените тази стойност в променените данни, новата стойност трябва да остане 12 пъти в същите полета на таблицата.
3. Размерът и дължината на стойностите не трябва да се различават значително в променените данни. Например, заменяте всеки байт или знак с псевдослучаен байт или знак. Първоначалният низ остава същия по размер и дължина.
4. Взаимовръзките в данните не трябва да се нарушават след промените. Това се отнася до външните ключове и всички други случаи, когато се позовавате на променените данни. Променените данни трябва да останат в същите отношения като реалните данни.
Внедряване на скриптове за промени в данните
Сега нека разгледаме конкретния случай на промяна на данните, за да се обезличи и скрие секретната информация. Извадката е базата данни за набиране на персонал.
Примерната база данни включва следните лични данни, които трябва да деперсонализирате:
- Фамилия и име;
- Дата на раждане;
- Дата на издаване на личната карта;
- Сертификатът за отдалечен достъп като последователност от байтове;
- Таксата за услуга за промоция на автобиография.
Първо, ще проверим прости примери за всеки тип променени данни:
- Промяна на датата и часа;
- Промяна на числовата стойност;
- Промяна на последователностите от байтове;
- Промяна на данните за знаците.
Промяна на датата и часа
Можете да получите произволна дата и час, като използвате следния скрипт:
DECLARE @dt DATETIME;
SET @dt = CAST(CAST(@StartDate AS FLOAT) + (CAST(@FinishDate AS FLOAT) - CAST(@StartDate AS FLOAT)) * RAND(CHECKSUM(NEWID())) AS DATETIME);
Тук @StartDate и @FinishDate са началните и крайните стойности на диапазона. Те корелират съответно за псевдослучайното генериране на дата и час.
За да генерирате тези данни, използвате системните функции RAND, CHECKSUM и NEWID.
UPDATE [dbo].[Employee]
SET [DocDate] = CAST(CAST(CAST(CAST([BirthDate] AS DATETIME) AS FLOAT) + (CAST(GETDATE() AS FLOAT) - CAST(CAST([BirthDate] AS DATETIME) AS FLOAT)) * RAND(CHECKSUM(NEWID())) AS DATETIME) AS DATE);
Полето [DocDate] означава датата на издаване на документа. Заменяме го с псевдослучайна дата, като имаме предвид диапазоните на датите и техните ограничения.
„Долната“ граница е датата на раждане на кандидата. „Горният“ край е текущата дата. Нямаме нужда от времето тук, така че трансформацията на формата на часа и датата до необходимата дата идва накрая. Можете да получите псевдослучайни стойности за всяка част от датата и часа по същия начин.
Промяна на числовата стойност
Можете да получите произволно цяло число с помощта на следния скрипт:
DECLARE @Int INT;
SET @Int = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS INT);
@MinVal и @MaxVal са стойностите на началния и крайния диапазон за генерирането на псевдослучайни числа. Генерираме го с помощта на системните функции RAND, CHECKSUM и NEWID.
UPDATE [dbo].[Employee]
SET [CountRequest] = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS INT);
Полето [CountRequest] означава броя заявки, които компаниите отправят за автобиографията на този кандидат.
По същия начин можете да получите псевдослучайни стойности за всяка числова стойност. Например, вижте произволното число от десетичен тип (18,2) поколение:
DECLARE @Dec DECIMAL(18,2);
SET @Dec=CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS DECIMAL(18,2));
По този начин можете да актуализирате таксата за услуга за популяризиране на автобиографията по следния начин:
UPDATE [dbo].[Employee]
SET [PaymentAmount] = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS DECIMAL(18,2));
Промяна на последователностите от байтове
Можете да получите произволна последователност от байтове, като използвате следния скрипт:
DECLARE @res VARBINARY(MAX);
SET @res = CRYPT_GEN_RANDOM(@Length, CAST(NEWID() AS VARBINARY(16)));
@дължина означава дължината на последователността. Той определя броя на върнатите байтове. Тук @Length не трябва да е по-голямо от 16.
Генерирането се извършва с помощта на системните функции CRYPT_GEN_RANDOM и NEWID.
Например, можете да актуализирате сертификата за отдалечен достъп за всеки кандидат по следния начин:
UPDATE [dbo].[Employee]
SET [RemoteAccessCertificate] = CRYPT_GEN_RANDOM(CAST(LEN([RemoteAccessCertificate]) AS INT), CAST(NEWID() AS VARBINARY(16)));
Ние генерираме псевдослучайна последователност от байтове със същата дължина, присъстваща в полето [RemoteAccessCertificate] в момента на промяната. Предполагаме, че дължината на байтовата последователност не надвишава 16.
По подобен начин можем да създадем нашата функция, която ще връща псевдослучайни последователности от байтове с произволна дължина. Резултатите от системната функция CRYPT_GEN_RANDOM ще работят заедно с помощта на простия оператор за добавяне „+“. Но 16 байта обикновено са достатъчни на практика.
Нека направим примерна функция, връщаща псевдослучайната последователност от байтове с определена дължина, където ще бъде възможно да се зададе дължина от повече от 16 байта. За целта направете следната презентация:
CREATE VIEW [test].[GetNewID]
AS
SELECT NEWID() AS [NewID];
GO
Нуждаем се от него, за да избегнем ограничението, което ни забранява да използваме NEWID във функцията.
По същия начин създайте следващата презентация със същата цел:
CREATE VIEW [test].[GetRand]
AS
SELECT RAND(CHECKSUM((SELECT TOP(1) [NewID] FROM [test].[GetNewID]))) AS [Value];
GO
Създайте още една презентация:
CREATE VIEW [test].[GetRandVarbinary16]
AS
SELECT CRYPT_GEN_RANDOM(16, CAST((SELECT TOP(1) [NewID] FROM [test].[GetNewID]) AS VARBINARY(16))) AS [Value];
GO
Дефинициите на трите функции са тук. И тук е реализацията на функцията, която връща псевдослучайна последователност от байтове с определена дължина.
Първо, ние дефинираме дали е налице необходимата функция. Ако не – първо създаваме шпилка. Във всеки случай кодът включва подходяща промяна на дефиницията на функцията. В крайна сметка добавяме описанието на функцията чрез разширените свойства. Повече подробности за документацията на базата данни са в тази статия.
За да актуализирате сертификата за отдалечен достъп за всеки кандидат, можете да направите следното:
UPDATE [dbo].[Employee]
SET [RemoteAccessCertificate] = [test].[GetRandVarbinary](CAST(LEN([RemoteAccessCertificate]) AS INT));
Както виждате, тук няма ограничения за дължината на байтовата последователност.
Промяна на данни – Промяна на данни за знаци
Тук ще вземем пример за английската и руската азбука, но можете да го направите за всяка друга азбука. Единственото условие е неговите знаци да присъстват в типовете NCHAR.
Трябва да създадем функция, която приема реда, заменя всеки знак с псевдослучаен знак и след това събира резултата и го връща.
Но първо трябва да разберем кои герои са ни необходими. За това можем да изпълним следния скрипт:
DECLARE @tbl TABLE ([ValueInt] INT, [ValueNChar] NCHAR(1), [ValueChar] CHAR(1));
DECLARE @ind int=0;
DECLARE @count INT=65535;
WHILE(@count>=0)
BEGIN
INSERT INTO @tbl ([ValueInt], [ValueNChar], [ValueChar])
SELECT @ind, NCHAR(@ind), CHAR(@ind)
SET @ind+=1;
SET @count-=1;
END
SELECT *
INTO [test].[TblCharactersCode]
FROM @tbl;
Правим таблицата [тест].[TblCharacterCode], която включва следните полета:
- ValueInt – числовата стойност на знака;
- ValueNChar – символът от типа NCHAR;
- ValueChar – символът от типа CHAR.
Нека разгледаме съдържанието на тази таблица. Нуждаем се от следната заявка:
SELECT [ValueInt]
,[ValueNChar]
,[ValueChar]
FROM [test].[TblCharactersCode];
Числата са в диапазона от 48 до 57:
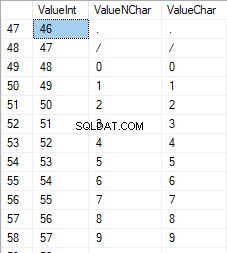
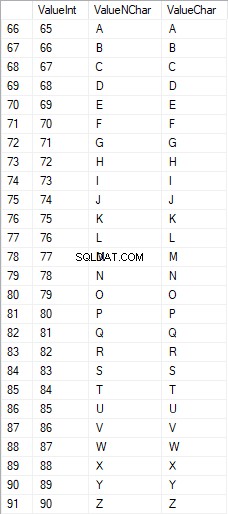
Латинските знаци в главните букви са в диапазона от 65 до 90:
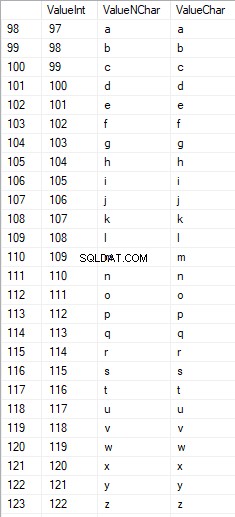
Латинските знаци в долната грижа са в диапазона от 97 до 122:
Руските знаци в главни букви са в диапазона от 1040 до 1071:

Руските знаци в малките букви са в диапазона от 1072 до 1103:


И знаци в диапазона от 58 до 64:

Избираме необходимите знаци и ги поставяме в таблицата [тест].[SelectCharactersCode] по следния начин:
SELECT
[ValueInt]
,[ValueNChar]
,[ValueChar]
,CASE
WHEN ([ValueInt] BETWEEN 48 AND 57) THEN 1
ELSE 0
END AS [IsNumeral]
,CASE
WHEN (([ValueInt] BETWEEN 65 AND 90) OR
([ValueInt] BETWEEN 1040 AND 1071)) THEN 1
ELSE 0
END AS [IsUpperCase]
,CASE
WHEN (([ValueInt] BETWEEN 65 AND 90) OR
([ValueInt] BETWEEN 97 AND 122)) THEN 1
ELSE 0
END AS [IsLatin]
,CASE
WHEN (([ValueInt] BETWEEN 1040 AND 1071) OR
([ValueInt] BETWEEN 1072 AND 1103)) THEN 1
ELSE 0
END AS [IsRus]
,CASE
WHEN (([ValueInt] BETWEEN 33 AND 47) OR
([ValueInt] BETWEEN 58 AND 64)) THEN 1
ELSE 0
END AS [IsExtra]
INTO [test].[SelectCharactersCode]
FROM [test].[TblCharactersCode]
WHERE ([ValueInt] BETWEEN 48 AND 57)
OR ([ValueInt] BETWEEN 65 AND 90)
OR ([ValueInt] BETWEEN 97 AND 122)
OR ([ValueInt] BETWEEN 1040 AND 1071)
OR ([ValueInt] BETWEEN 1072 AND 1103)
OR ([ValueInt] BETWEEN 33 AND 47)
OR ([ValueInt] BETWEEN 58 AND 64);
Сега, нека да разгледаме съдържанието на тази таблица, като използваме следния скрипт:
SELECT [ValueInt]
,[ValueNChar]
,[ValueChar]
,[IsNumeral]
,[IsUpperCase]
,[IsLatin]
,[IsRus]
,[IsExtra]
FROM [test].[SelectCharactersCode];
Получаваме следния резултат:

По този начин имаме [теста].[SelectCharactersCode] таблица, където:
- ValueInt – числовата стойност на знака
- ValueNChar – символът от типа NCHAR
- ValueChar – символът от типа CHAR
- IsNumeral – критерият знак да е цифра
- UpperCase – критерият за символ в главни букви
- Е латински – критерият знак да е латински знак;
- ИсРус – критерият персонаж е руски характер
- Екстра – критерият символ е допълнителен знак
Сега можем да получим кода за вмъкване на необходимите знаци. Например, това е как да го направите за латински букви в малки букви:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+''''+[ValueChar]+''''+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsUpperCase]=0
AND [IsLatin]=1;
Получаваме следния резултат:

Същото е и за руските знаци в малки букви:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+COALESCE(''''+[ValueChar]+'''', 'NULL')+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsUpperCase]=0
AND [IsRus]=1;
Получаваме следния резултат:

Същото е и за знаците:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+''''+[ValueChar]+''''+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsNumeral]=1;
Резултатът е следният:

И така, имаме кодове за вмъкване на следните данни поотделно:
- Латинските знаци в малки букви.
- Руските знаци в малки букви.
- Цифрите.
Работи както за типовете NCHAR, така и за CHAR.
По същия начин можем да подготвим скрипт за вмъкване за произволен набор от знаци. Освен това всеки набор ще получи своя собствена функция за таблица.
За да бъдем опростени, ние внедряваме общата функция за табулиране, която ще върне необходимия набор от данни за предварително избраните данни по следния начин:
SELECT
'SELECT ' + CAST([ValueInt] AS NVARCHAR(255)) + ' AS [ValueInt], '
+ '''' + [ValueNChar] + '''' + ' AS [ValueNChar], '
+ COALESCE('''' + [ValueChar] + '''', ‘NULL’) + ' AS [ValueChar], '
+ CAST([IsNumeral] AS NCHAR(1)) + ' AS [IsNumeral], ' +
+CAST([IsUpperCase] AS NCHAR(1)) + ' AS [IsUpperCase], ' +
+CAST([IsLatin] AS NCHAR(1)) + ' AS [IsLatin], ' +
+CAST([IsRus] AS NCHAR(1)) + ' AS [IsRus], ' +
+CAST([IsExtra] AS NCHAR(1)) + ' AS [IsExtra]' +
+' UNION ALL'
FROM [test].[SelectCharactersCode];
Крайният резултат е както следва:

Готовият скрипт е обвит във функцията за табулиране [тест].[GetSelectCharacters].
Важно е да премахнем допълнително UNION ALL в края на генерирания скрипт и в [ValueInt]=39 трябва да променим ”’ на ””:
SELECT 39 AS [ValueInt], '''' AS [ValueNChar], '''' AS [ValueChar], 0 AS [IsNumeral], 0 AS [IsUpperCase], 0 AS [IsLatin], 0 AS [IsRus], 1 AS [IsExtra] UNION ALLТази функция за таблица връща следния набор от полета:
- Брой – номера на реда в върнатия набор от данни;
- ValueInt – числовата стойност на знака;
- ValueNChar – символът от типа NCHAR;
- ValueChar – символът от типа CHAR;
- IsNumeral – критерият знакът да е цифра;
- UpperCase – критерият, определящ, че символът е с главни букви;
- Е латински – критерият, определящ, че знакът е латински знак;
- ИсРус – критерият, определящ, че персонажът е руски герой;
- Екстра – критерият, определящ, че персонажът е допълнителен.
За входа имате следните параметри:
- @IsNumeral – ако трябва да върне числата;
- @IsUpperCase :
- 0 – трябва да връща само малките букви за буквите;
- 1 – трябва да връща само главните букви;
- NULL – трябва да връща букви във всички случаи.
- @EsLatin – трябва да върне латинските знаци
- @IsRus – трябва да върне руските знаци
- @IsExtra – трябва да връща допълнителни знаци.
Всички флагове се използват според логическото ИЛИ. Например, ако трябва да върнете цифри и латински знаци в малки букви, вие извикате функцията за табулиране по следния начин:
Получаваме следния резултат:
declare
@IsNumeral BIT=1
,@IsUpperCase BIT=0
,@IsLatin BIT=1
,@IsRus BIT=0
,@IsExtra BIT=0;
SELECT *
FROM [test].[GetSelectCharacters](@IsNumeral, @IsUpperCase, @IsLatin, @IsRus, @IsExtra);
Получаваме следния резултат:

Реализираме функцията [test].[GetRandString], която ще замени реда с псевдослучайни знаци, запазвайки първоначалната дължина на низа. Тази функция трябва да включва възможността за работа само с тези знаци, които са цифри. Например, може да бъде полезно, когато променяте серията и номера на личната карта.
Когато внедрим функцията [test].[GetRandString], първо получаваме набора от знаци, необходими за генериране на псевдослучаен ред с определена дължина във входния параметър @Length. Останалите параметри работят, както е описано по-горе.
След това поставяме получения набор от данни в табулационната променлива @tbl . Тази таблица записва полетата [ID] – номерът на поръчката в резултантната таблица със знаци и [Стойност] – представянето на знака в тип NCHAR.
След това, в цикъл, той генерира псевдослучайно число в диапазона от 1 до мощността на @tbl знаците, получени по-рано. Поставяме този номер в [ID] на табулационната променлива @tbl за търсене. Когато търсенето върне реда, ние вземаме знака [Стойност] и го „залепваме“ към получения ред @res.
Когато работата на цикъла приключи, полученият ред се връща обратно чрез променливата @res.
Можете да промените както името, така и фамилията на кандидата по следния начин:
UPDATE [dbo].[Employee]
SET [FirstName] = [test].[GetRandString](LEN([FirstName])),
[LastName] = [test].[GetRandString](LEN([LastName]));
По този начин, ние разгледахме изпълнението на функцията и нейното използване за типовете NCHAR и NVARCHAR. Можем лесно да направим същото за типовете CHAR и VARCHAR.
Понякога обаче трябва да генерираме ред според набора от знаци, а не азбучните знаци или цифри. По този начин първо трябва да използваме следната многооператорна функция [тест].[GetListCharacters].
Функцията [test].[GetListCharacters] получава следните два параметъра за входа:
- @str – самата линия от знаци;
- @IsGroupUnique – определя дали трябва да групира уникални знаци в реда.
С рекурсивния CTE, входният ред @str се трансформира в таблица със знаци – @ListCharacters. Тази таблица съдържа следните полета:
- ИД – поредният номер на реда в получената таблица със знаци;
- Характер – представянето на героя в NCHAR(1)
- Брой – броят на повторенията на символа в реда (винаги е 1, ако параметърът @IsGroupUnique=0)
Нека вземем два примера за използването на тази функция, за да разберем по-добре нейната работа:
- Трансформиране на реда в списък с неуникални знаци:
SELECT *
FROM [test].[GetListCharacters]('123456888 789 0000', 0);
Получаваме резултата:

Този пример показва, че редът се трансформира в списък със знаци „както е“, без да се групира според уникалността на знаците (полето [Count] винаги съдържа 1).
- Преобразуването на реда в списък с уникални знаци
SELECT *
FROM [test].[GetListCharacters]('123456888 789 0000', 1);
Резултатът е следният:
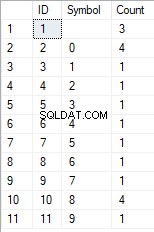
Този пример показва, че линията се трансформира в списък със знаци, групирани по тяхната уникалност. Полето [Count] показва броя на находките на всеки знак във входния ред.
Въз основа на многооператорната функция [test].[GetListCharacters], ние създаваме скаларна функция [test].[GetRandString2].
Дефиницията на новата скаларна функция показва нейното сходство със скаларната функция [test].[GetRandString]. Единствената разлика е, че използва многооператорната функция [test].[GetListCharacters] вместо табулационната функция [test].[GetSelectCharacters].
Тук нека прегледаме два примера за използване на внедрена скаларна функция :
Ние генерираме псевдослучаен ред с дължина 12 знака от входния ред на знаци, които не са групирани по уникалност:
SELECT [test].[GetRandString2](12, '123456789!!!!!!!!0!!!', DEFAULT);Резултатът е:
64017!!5!!!7
Ключовата дума е DEFAULT. Посочва, че стойността по подразбиране задава параметъра. Тук е нула (0).
Или
Ние генерираме псевдослучаен ред с дължина 12 знака от входния ред от знаци, групирани по уникалност:
SELECT [test].[GetRandString2](12, '123456789!!!!!!!!0!!!', 1);Резултатът е:
35792!428273
Внедряване на общия скрипт за саниране на данните и промени в секретните данни
Разгледахме прости примери за всеки тип променени данни:
- Промяна на датата и часа;
- Промяна на числовата стойност;
- Промяна на последователността от байтове;
- Промяна на данните на героите.
Тези примери обаче не отговарят на критерии 2 и 3 за скриптовете за промяна на данните:
- Критерий 2 :селективността на стойностите няма да се промени значително в променените данни. Не можете да използвате NULL за полето на таблицата. Вместо това трябва да се уверите, че същите реални стойности на данни остават същите в променените данни. Например, ако реалните данни съдържат стойността 103785 12 пъти в полето на таблица, обект на промени, модифицираните данни трябва да включват различна (променена) стойност, намерена 12 пъти в едно и също поле на таблицата.
- Критерий 3 :дължината и размерът на стойностите не трябва да се променят значително в променените данни. Например замествате всеки знак/байт с псевдослучаен знак/байт.
По този начин трябва да създадем скрипт, като вземем предвид избирателността на стойностите в полетата на таблицата.
Нека да разгледаме нашата база данни за услугата за набиране на персонал. Както виждаме, личните данни присъстват само в таблицата на кандидатите [dbo].[Служител].
Да приемем, че таблицата включва следните полета:
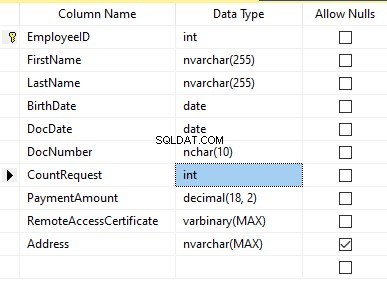
Описания:
- Име – име, ред NVARCHAR(255)
- Фамилия – фамилия, ред NVARCHAR(255)
- Дата на раждане – дата на раждане, ДАТА
- Номер на документ – номера на личната карта с две цифри в началото за серията на паспорта, а следващите седем цифри са номера на документа. Между тях имаме тире като ред NCHAR(10).
- Дата на документа – дата на издаване на личната карта ДАТА
- CountRequest – броят на заявките за този кандидат по време на търсенето на автобиография, цяло число INT
- Сума на плащане – получената такса за промоция на автобиографията, десетичното число (18,2)
- Сертификат за отдалечен достъп – сертификатът за отдалечен достъп, последователност от байтове VARBINARY
- Адрес – адресът на местожителство или адресът на регистрация, ред NVARCHAR(MAX)
След това, за да запазим първоначалната селективност, трябва да приложим следния алгоритъм:
- Извличане на всички уникални стойности за всяко поле и запазване на резултатите във временни таблици или табулационни променливи;
- Генерирайте псевдослучайна стойност за всяка уникална стойност. Тази псевдослучайна стойност не трябва да се различава значително по дължина и размер от първоначалната стойност. Запазете резултата на същото място, където запазихме резултатите от точка 1. Всяка новогенерирана стойност трябва да има уникална корелирана текуща стойност.
- Заменете всички стойности в таблицата с нови стойности от точка 2.
В началото обезличаваме имената и фамилните имена на кандидатите. Предполагаме, че фамилното и собственото име винаги присъстват и са с дължина не по-малко от два знака във всяко поле.
Първо избираме уникални имена. След това генерира псевдослучаен ред за всяко име. Дължината на името остава същата; първият знак е с главни букви, а другите знаци са с малки. Използваме предварително създадената скаларна функция [test].[GetRandString], за да генерираме псевдослучаен ред със специфична дължина според дефинираните критерии на символите.
След това актуализираме имената в таблицата на кандидатите според техните уникални стойности. Същото е и за фамилните имена.
Деперсонализираме полето DocNumber. Това е номерът на личната карта (паспорт). Първите два знака означават серията на документа, а последните седем цифри са номера на документа. Тирето е между тях. След това извършваме операцията по дезинфекция.
Ние събираме всички уникални номера на документи и генерираме псевдослучаен ред за всеки от тях. Форматът на реда е 'XX-XXXXXXX', където X е цифрата в диапазона от 0 до 9. Тук използваме скаларната функция [test].[GetRandString], за да генерираме псевдослучаен ред с определена дължина в съответствие с посочената дължина. зададените параметри на символите.
След това полето [DocNumber] се актуализира в таблицата на кандидатите [dbo].[Employee].
Деперсонализираме полето DocDate (дата на издаване на личната карта) и полето BirthDate (дата на раждане на кандидата).
First, we select all the unique pairs made of “date of birth &date of the ID-card issue.” For each such pair, we create a pseudorandom date for the date of birth. The pseudorandom date of the ID-card issue is made according to that “date of birth” – the date of the document’s issue must not be earlier than the date of birth.
After that, these data are updated in the respective fields of the candidates’ table [dbo].[Employee].
And, we update the remaining fields of the table.
The CountRequest value stands for the number of requests made for that candidate by companies during the resume search.
The PaymentAmount is the final amount of the resume promotion service fee paid. We calculate these numbers similarly to the previous fields.
Note that it generates a pseudorandom integer for the first case and a pseudorandom decimal for the second case. In both cases, the pseudorandom number generation occurs in the range of “two times less than original” to “two times more than original.” The selectivity of values in the fields is not changed too much.
After that, it writes the values into the fields of the candidates’ table [dbo].[Employee].
Further, we collect unique values of the RemoteAccessCertificate field for the remote access certificate. We generate a pseudorandom byte sequence for each such value. The length of the sequence must be the same as the original. Here, we use the previously created [test].[GetRandVarbinary] scalar function to generate the pseudorandom byte sequence of the specified length.
Then recording into the respective field [RemoteAccessCertificate] of the [dbo].[Employee] candidates’ table takes place.
The last step is the collection of the unique addresses from the [Address] field. For each value, we generate a pseudorandom line of the same length as the original. Note that if it was NULL originally, it must be NULL in the generated field. It allows you to keep NULL and don’t replace it with an empty line. It minimizes the selectivity values’ mismatch in this field between the production database and the altered data.
We use the previously created [test].[GetRandString] scalar function to generate the pseudorandom line of the specified length according to the characters’ parameters defined.
It then records the data into the respective [Address] field of the candidates’ table [dbo].[Employee].
This way, we get the full script for depersonalization and altering of the confidential data.
Finally, we get the database with altered personal and confidential data. The algorithms we used make it impossible to restore the original data from the altered data. Also, the values’ selectivity, length, and size aren’t changed significantly. So, the three criteria for the personal and secret data altering scripts are ensured.
We won’t review the criterion 4 separately here. Our database contains all the data subject to change in one candidates’ table [dbo].[Employee]. The data conformity is needed within this table only. Thus, criterion 4 is also here. However, we need to remember this criterion 4 claiming that all interrelations must remain the same in the altered data.
We often see other conditions for personal and confidential data altering algorithms, but we won’t review them here. Besides, the four criteria described above are always present. In many cases, it is enough to estimate the functionality of the algorithm suitable to use it.
Now, we need to make a backup of the created database, check it by restoring on another instance, and transfer that copy into the necessary environment for development and testing. For this, we examine the full database backup creation.
Full database backup creation
We can make a database backup with construction BACKUP DATABASE as in our example.
Make a compressed full backup of the database JobEmplDB_Test. The checksum calculation takes place in the file E:\Backup\JobEmplDB_Test.bak. Further, we check the backup created.
Then, we check the backup created by restoring the database for it. Let’s examine the database restoring.
Restoring the database
You can restore the database with the help of RESTORE DATABASE construction in the following way:
USE [master]
RESTORE DATABASE [JobEmplDB_Test]
FROM DISK = N'E:\Backup\JobEmplDB_Test.bak' WITH FILE = 1,
MOVE N'JobEmplDB' TO N'E:\DBData\JobEmplDB.mdf',
MOVE N'JobEmplDB_log' TO N'F:\DBLog\JobEmplDB_log.ldf',
NOUNLOAD,
REPLACE,
STATS = 5;
GO
We restore the JobEmplDB_Test database of the E:\Backup\JobEmplDB_Test.bak архивиране. The files will be overwritten, and the data file will be transferred into the file E:\DBData\JobEmplDB.mdf , while the transactions log file will be moved into F:\DBLog\JobEmplDB_log.ldf .
After we successfully check how the database is restored from the backup, we forward the backup to the development and testing environments. It will be restored again with the same method as described above.
We’ve examined the first approach to the data populating into the database for testing and development. This approach implies copying and altering the data from the production database. Now, we’ll examine the second approach – the synthetic data generation.
Synthetic data generation
The General algorithm for the synthetic data generation is following:
- Make a new empty database or clear a previously created database by purging all data.
- Create or renew a scheme in the newly created database – the same as that of the production databases.
- Copy of renew guidelines and regulations from the production database and transfer them into the new database.
- Generate synthetic data into the necessary tables of the new database.
- Make a backup of a new database.
- Deliver and restore the new backup in the necessary environment.
We already have the JobEmplDB_Test database to practice, and we have reviewed the means of creating a schema in the new database. Let’s focus on the tasks that are specific to this approach.
Clean up the database with the data purge
To clear the database off all its data, we need to do the following:
- Keep the definitions of all external keys.
- Disable all limitations and triggers.
- Delete all external keys.
- Clear the tables using the TRUNCATE construction.
- Restore all the external keys deleted in point 3.
- Enable all the limitations disabled in point 2.
You can save the definitions of all external keys with the following script:
1. The external keys’ definitions are saved in the tabulation variable @tbl_create_FK
2. You can disable the limitations and triggers with the following script:
EXEC sp_MSforeachtable "ALTER TABLE ? NOCHECK CONSTRAINT ALL";
EXEC sp_MSforeachtable "ALTER TABLE ? DISABLE TRIGGER ALL";
To enable the limitations and triggers, you can use the following script:
EXEC sp_MSforeachtable "ALTER TABLE ? WITH CHECK CHECK CONSTRAINT ALL";
EXEC sp_MSforeachtable "ALTER TABLE ? ENABLE TRIGGER ALL";
Here, we use the saved procedure sp_MSforeachtable that applies the construction to all the database’s tables.
3. To delete external keys, use the special script. Here, we receive the information about the external keys through the INFORMATION_SCHEMA.TABLE_CONSTRAINTS system presentation. We delete external keys through the cursor, one by one, using the formed dynamic script T-SQL, transferring the request into the system saved procedure sp_executesql .
4. To clear the tables with the TRUNCATE construction, use the dedicated script. The script works in the same way as above, but it receives the data for tables, and then it clears the tables one by one through the cursor, using the TRUNCATE construction.
5. Restoring the external keys is possible with the below script (earlier, we saved the external keys’ definitions in the tabulation variable @tbl_create_FK):
DECLARE @tsql NVARCHAR(4000);
DECLARE FK_Create CURSOR LOCAL FOR SELECT
[Script]
FROM @tbl_create_FK;
OPEN FK_Create;
FETCH NEXT FROM FK_Create INTO @tsql;
WHILE (@@fetch_status = 0)
BEGIN
EXEC sp_executesql @tsql = @tsql;
FETCH NEXT FROM FK_Create INTO @tsql;
END
CLOSE FK_Create;
DEALLOCATE FK_Create;
The script works in the same way as the two other scripts we mentioned above. But it restores the external keys’ definitions through the cursor, one for each iteration.
A particular case of data purging in the database is the current script. To get this output, we need the below construction in the scripts:
EXEC sp_executesql @tsql = @tsql;Before this construction, or instead of it, we need to write the generated construction output. It is necessary to call it manually or via the dynamic T-SQL query. We do it via the system saved procedure sp_executesql.
Instead of the below code fragment in all cases:
WHILE (@@fetch_status = 0)
BEGIN
EXEC sp_executesql @tsql = @tsql;
...
We write:
WHILE (@@fetch_status = 0)
BEGIN
PRINT @tsql;
EXEC sp_executesql @tsql = @tsql;
...
Или:
WHILE (@@fetch_status = 0)
BEGIN
PRINT @tsql;
...
The first case implies both the output of constructions and their execution. The second case if for the output only – it is helpful for the scripts’ debugging.
Thus, we get the general database cleaning script.
Copy guidelines and references from the production database to the new one
Here you can use the T-SQL scripts. Our example database of the recruitment service includes 5 guidelines:
- [dbo].[Company] – companies
- [dbo].[Skill] – skills
- [dbo].[Position] – positions (occupation)
- [dbo].[Project] – projects
- [dbo].[ProjectSkill] – project and skills’ correlations
The “skills” table [dbo].[Skill] serves to show how to make a script for the data insertion from the production database into the test database.
We form the following script:
SELECT 'SELECT '+CAST([SkillID] AS NVARCHAR(255))+' AS [SkillID], '+''''+[SkillName]+''''+' AS [SkillName] UNION ALL'
FROM [dbo].[Skill]
ORDER BY [SkillID];
We execute it in a copy of the production database that is usually available in read-only mode. It is a replica of the production database.
The result is:
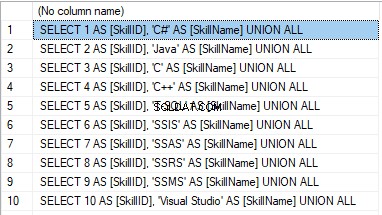
Now, wrap the result up into the script for the data adding as here. We have a script for the skills’ guideline compilation. The scripts for other guidelines are made in the same way.
However, it is much easier to copy the guidelines’ data through the data export and import in SSMS. Or, you can use the data import and export wizard.
Generate synthetic data
We’ve determined the pseudorandom values’ generation for lines, numbers, and byte sequences. It took place when we examined the implementation of the data sanitization and the confidential data altering algorithms for approach 1. Those implemented functions and scripts are also used for the synthetic data generation.
The recruitment service database requires us to fill the synthetic data in two tables only:
- [dbo].[Employee] – candidates
- [dbo].[JobHistory] – a candidate’s work history (experience), the resume itself
We can fill the candidates’ table [dbo].[Employee] with synthetic data using this script.
At the beginning of the script, we set the following parameters:
- @count – the number of lines to be generated
- @LengthFirstName – the name’s length
- @LengthLastName – the last name’s length
- @StartBirthDate – the lower limit of the date for the date of birth
- @FinishBirthDate – the upper limit of the date for the date of birth
- @StartCountRequest – the lower limit for the field [CountRequest]
- @FinishCountRequest – the upper limit for the field [CountRequest]
- @StartPaymentAmount – the lower limit for the field [PaymentAmount]
- @FinishPaymentAmount – the upper limit for the field [PaymentAmount]
- @LengthRemoteAccessCertificate – the byte sequence’s length for the certificate
- @LengthAddress – the length for the field [Address]
- @count_get_unique_DocNumber – the number of attempts to generate the unique document’s number [DocNumber]
The script complies with the uniqueness of the [DocNumber] field’s value.
Now, let’s fill the [dbo].[JobHistory] table with synthetic data as follows.
The start date of work [StartDate] is later than the issuing date of the candidate’s document [DocDate]. The end date of work [FinishDate] is later than the start date of work [StartDate].
It is important to note that the current script is simplified, as it does not deal with parameters of the generated data selectivity configuration.
Make a full database backup
We can make a database backup with the construction BACKUP DATABASE, using our script.
We create a full compressed backup of the database JobEmplDB_Test. The checksum is calculated into the file E:\Backup\JobEmplDB_Test.bak. It also ensures further testing of the backup.
Let’s check the backup by restoring the database from it. We need to examine the database restoring then.
Restore the database
You can restore the database with the help of the RESTORE DATABASE construction, as shown below:
USE [master]
RESTORE DATABASE [JobEmplDB_Test]
FROM DISK = N'E:\Backup\JobEmplDB_Test.bak' WITH FILE = 1,
MOVE N'JobEmplDB' TO N'E:\DBData\JobEmplDB.mdf',
MOVE N'JobEmplDB_log' TO N'F:\DBLog\JobEmplDB_log.ldf',
NOUNLOAD,
REPLACE,
STATS = 5;
GO
We restore the database JobEmplDB_Test from the backup E:\Backup\JobEmplDB_Test.bak. The files are overwritten, and the data file is transferred to the file E:\DBData\JobEmplDB.mdf. The transaction log file is transferred to file F:\DBLog\JobEmplDB_log.ldf.
After checking the database restoring from the backup successfully, we transfer the backup to the necessary environments. It will be used for testing and development, and further deployment through the database restoring, as described above.
This way, we’ve examined the second approach to filling the database in with data for testing and development purposes. It is the synthetic data generation approach.
Data generation tools (for external resources)
When we have a job to fill in the database with data for testing and development purposes, it can be much faster and easier with the help of specialized tools. Let’s review the most popular and powerful data generation tools and explore their practical usage.
Full list of tools
DATPROF
IRI RowGen
Data Generator for SQL Server
Redgate SQL Data Generator
DTM Data Generator
Datanamic Data Generator MultiDB
Now, let’s examine one of these tools more precisely.
An overview of the employees’ generation by the Data Generator for SQL Server
The Data Generator for SQL Server utility is embedded in SSMS, and also it is a part of dbForge Studio. We reviewed this utility here. Let’s now examine how it works for synthetic data generation. As examples, we use the [dbo].[Employee] and the [dbo].[JobHistory] tables.
This generator can quickly generate first and last names of candidates for the [FirstName] and [LastName] fields respectively:
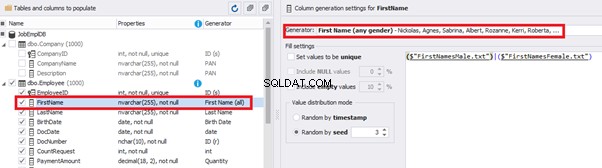
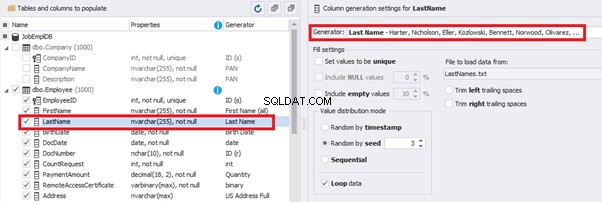
Note that FirstName requires choosing the “First Name” value in the “Generator” section. For LastName, you need to select the “Last Name” value from the “Generator” section.
It is important to note that the generator automatically determines which generation type it needs to apply to every field. The settings above were set by the generator itself, without manual correction.
You can configure distribution of values for the date of birth [BirthDate]:
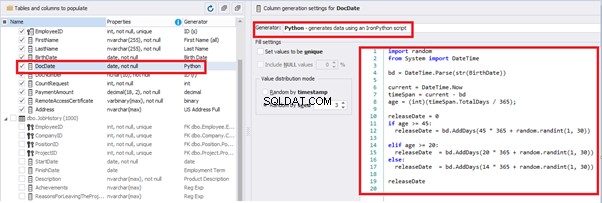
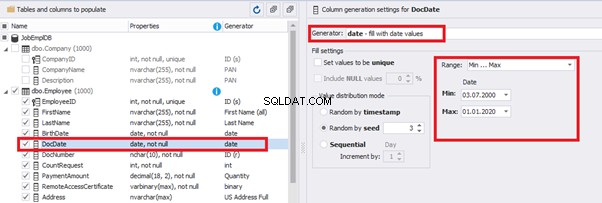
Set the distribution for the document’s date of issue [DocDate] through the Phyton generator using the below script:
import random
from System import DateTime
# receive the value from the Birthday field
bd = DateTime.Parse(str(BirthDate))
# receive the current date
current = DateTime.Now
# calculate the age in years
timeSpan = current - bd
age = (int)(timeSpan.TotalDays / 365);
# passport’s date of issue
releaseDate = 0
if age >= 45:
releaseDate = bd.AddDays(45 * 365 + random.randint(1, 30))
# randomize the issue during the month
elif age >= 20:
releaseDate = bd.AddDays(20 * 365 + random.randint(1, 30))
# randomize the issue during the month
else:
releaseDate = bd.AddDays(14 * 365 + random.randint(1, 30))
# randomize the issue during the month
releaseDateThis way, the [DocDate] configuration will look as follows:
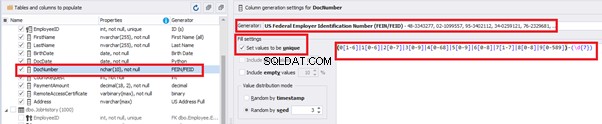
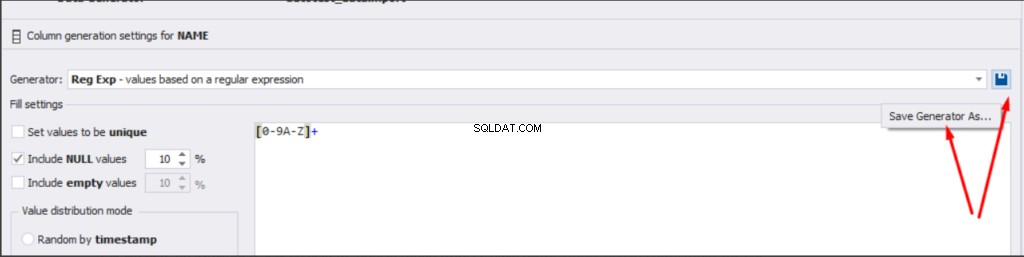
For the document’s number [DocNumber], we can select the necessary type of unique data generation, and edit the generated data format, if needed:
E.g., instead of the format
(0[1-6]|1[0-6]|2[0-7]|3[0-9]|4[0-68]|5[0-9]|6[0-8]|7[1-7]|8[0-8]|9[0-589])-(\d{7})We can set the following format:
(\d{2})-(\d{7})This format means that the line will be generated in format XX-XXXXXXX (X – is a digit in the range of 0 to 9).
We set up the generator for [CountRequest] and [PaymentAmount] fields in the same way, according to the generated data type:
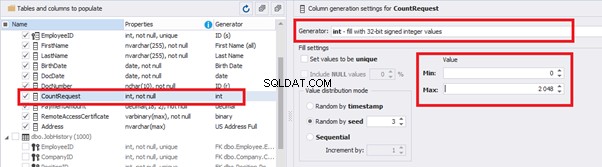
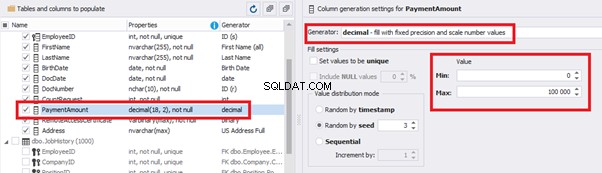
In the first case, we set the values’ range of 0 to 2048 for [CountRequest]. In the second case, it is the range of 0 to 100000 for [PaymentAmount].
We configure generation for [RemoteAccessCertificate] and [Address] fields in the same way:
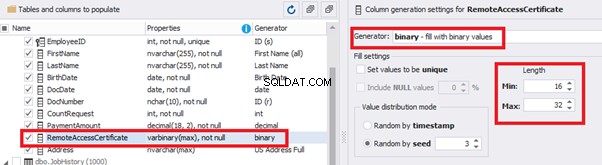
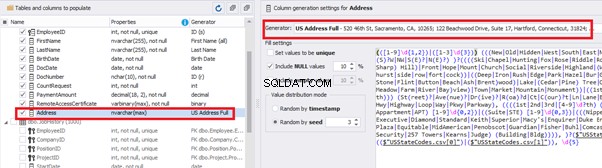
In the first case, we limit the byte sequence [RemoteAccessCertificate] with the range of lengths of 16 to 32. In the second case, we select values for [Address] as real addresses. It makes the generated values looking like the real ones.
This way, we’ve configured the synthetic data generation settings for the candidates’ table [dbo].[Employee]. Let’s now set up the synthetic data generation for the [dbo].[JobHistory] table.
We set it to take the data for the [EmployeeID] field from the candidates’ table [dbo].[Employee] in the following way:
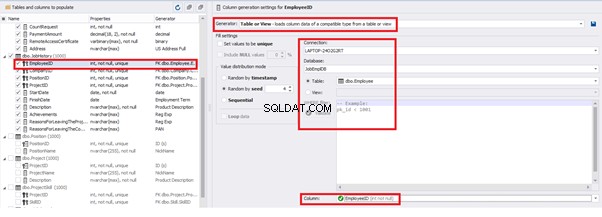
We select the generator’s type from the table or presentation. We then define the sample of MS SQL Server, the database, and the table to take the data from. We can also configure filters in the “WHERE filter” section, and select the [EmployeeID] field.
Here we suppose that we generate the “employees” first, and then we generate the data for the [dbo].[JobHistory] table, basing on the filled [dbo].[Employee] reference.
However, if we need to generate the data for both [dbo].[Employee] and [dbo].[JobHistory] at the same time, we need to select “Foreign Key (manually assigned) – references a column from the parent table,” referring to the [dbo].[Employee].[EmployeeID] column:
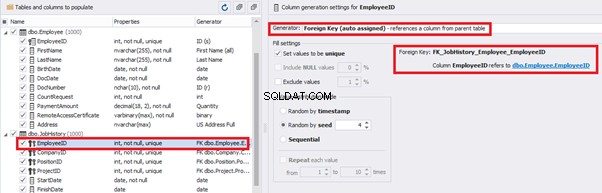
Similarly, we set up the data generation for the following fields.
[CompanyID] – from [dbo].[Company], the “companies” table:
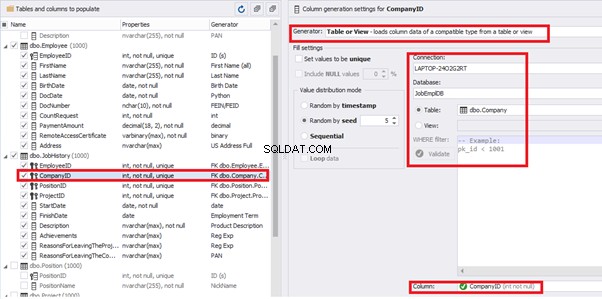
[PositionID] – from the table of positions [dbo].[Position]:
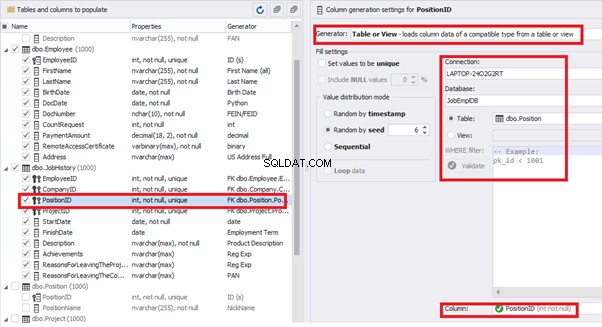
[ProjectID] – from the table of projects [dbo].[Project]:
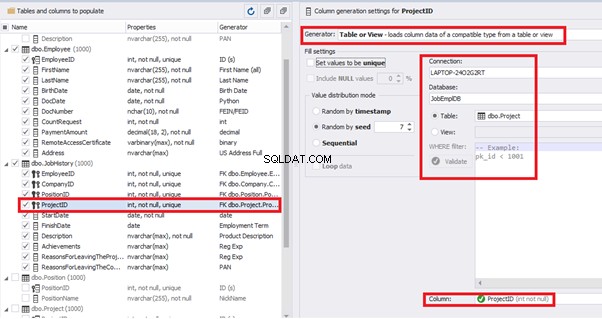
The tool cannot link the columns from different tables and shift them in some way. However, the generator can shift the date within one table – the “date” generator – fill with date values with Range – Offset from the column. Also, it can use data from a different table, but without any transformation (Table or View, SQL query, Foreign key generators).
That’s why we resolve the dates’ problem (BirthDate
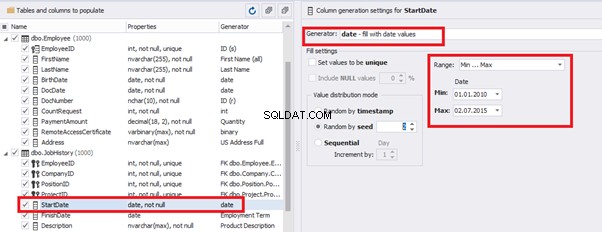
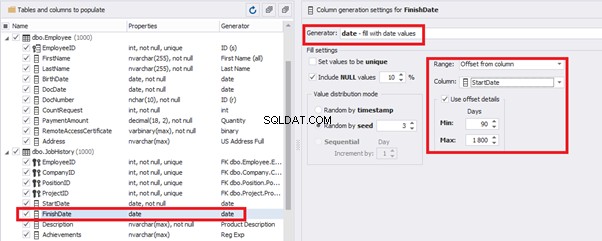
E.g., we limit the BirthDate with the 40-50 years’ interval. Then, we restrict the DocDate with 20-40 years’ interval. The StartDate is, respectively, limited with 25-35 years’ interval, and we set up the FinishDate with the offset from StartDate.
We set up the date of birth:
Set up the date of the document’s issue
Then, the StartDate will match the age from 35 to 45:
The simple offset generator sets FinishDate:
The result is, a person has worked for three months till the current date.
Also, to configure the date of the working end, we can use a small Python script:
This way, we receive the below configuration for the dates of work end [FinishDate] data generation:
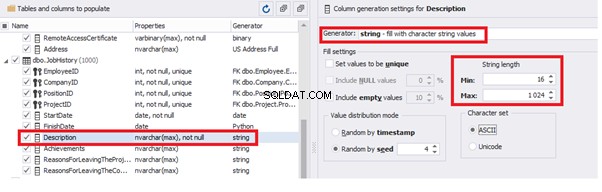
Similarly, we fill in the rest of fields. We set the generator type – string, and set the range for generated lines’ lengths:
Also, you can save the data generation project as dgen-file consisting of:
We can save all these settings:it is enough to keep the project’s file and work with the database further, using that file:
There is also the possibility to both save the new generators from scratch and save the custom settings in a new generator:
Thus, we’ve configured the synthetic data generation settings used for the jobs’ history table [dbo].[JobHistory].
We have examined two approaches to filling the data in the database for testing and development:
We’ve defied the objects for each approach and each script implementation. These objects are here. We’ve also provided scripts for changing the data from the production database and synthetic data generation. An example is the database of recruitment services. In the end, we’ve examined popular data generation tools and explored one of these tools in detail.
SQL SERVER – How to Disable and Enable All Constraint for Table and Database 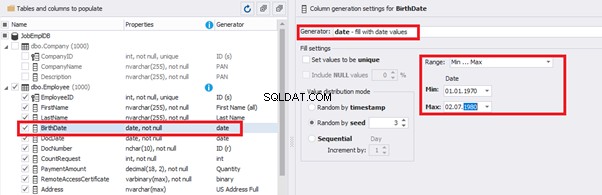
import random
from System import DateTime
bd = DateTime.Parse(str(StartDate))
releaseDate = bd.AddDays(random.randint(1, 30))
releaseDate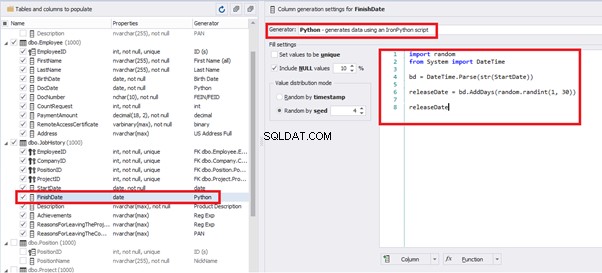
Заключение
Препратки
Microsoft TechNet Wiki
Top 10 Best Test Data Generation Tools In 2020
SQL Server Documentation