Всички сме се разглезили от способността на търсачките да „заобикалят“ неща като правописни грешки, разлики в правописа на имената или всяка друга ситуация, при която думата за търсене може да съвпада на страници, чиито автори може да предпочетат да използват различно изписване на дума. Добавянето на такива функции към нашите собствени приложения, управлявани от база данни, може по подобен начин да обогати и подобри нашите приложения и докато предложенията на търговските системи за управление на релационни бази данни (RDBMS) предоставят свои собствени напълно разработени персонализирани решения на този проблем, разходите за лицензиране на тези инструменти могат да бъдат извън достигнете до по-малки разработчици или малки фирми за разработка на софтуер.
Може да се твърди, че това може да се направи с помощта на проверка на правописа. Въпреки това, проверката на правописа обикновено не е от полза, когато съвпада правилно, но алтернативно изписване на име или друга дума. Съвпадението по звук запълва тази функционална празнина. Това е темата на днешния урок по програмиране:как да заявявате звуци с Python с помощта на метафони.
Какво е Soundex?
Soundex е разработен в началото на 20-ти век като средство за преброяването на САЩ да съпостави имената въз основа на това как звучат. След това се използва от различни телефонни компании за съпоставяне на имена на клиенти. Той продължава да се използва за съвпадение на фонетични данни и до днес, въпреки че е ограничен до правописа и произношенията на американския английски. Той също така е ограничен до английски букви. Повечето RDBMS, като SQL Server и Oracle, заедно с MySQL и неговите варианти, имплементират функция Soundex и въпреки ограниченията си тя продължава да се използва за съпоставяне на много неанглийски думи.
Какво е двоен метафон?
Метафонът Алгоритъмът е разработен през 1990 г. и преодолява някои от ограниченията на Soundex. През 2000 г. подобрено продължение, Double Metaphone , беше разработен. Double Metaphone връща първична и вторична стойност, която съответства на два начина, по които една дума може да се произнесе. И до днес този алгоритъм остава един от най-добрите фонетични алгоритми с отворен код. Metaphone 3 беше пуснат през 2009 г. като подобрение на Double Metaphone, но това е търговски продукт.
За съжаление, много от известните RDBMS, споменати по-горе, не прилагат двоен метафон и повечето изявените скриптови езици не предоставят поддържана реализация на Double Metaphone. Въпреки това, Python предоставя модул, който внедрява двоен метафон.
Примерите, представени в този урок за програмиране на Python, използват MariaDB версия 10.5.12 и Python 3.9.2, като и двете работят на Kali/Debian Linux.
Как да добавя двоен метафон към Python
Както всеки модул на Python, инструментът pip може да се използва за инсталиране на Double Metaphone. Синтаксисът зависи от вашата инсталация на Python. Типичната инсталация на двоен метафон изглежда като следния пример:
# Typical if you have only Python 3 installed $ pip install doublemetaphone # If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install DoubleMetaphone
Имайте предвид, че допълнителното изписване с главни букви е умишлено. Следният код е пример за това как да използвате двоен метафон в Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 1 - Demo script to verify functionality
Горният скрипт на Python дава следния изход, когато се изпълнява във вашата интегрирана среда за разработка (IDE) или редактор на код:
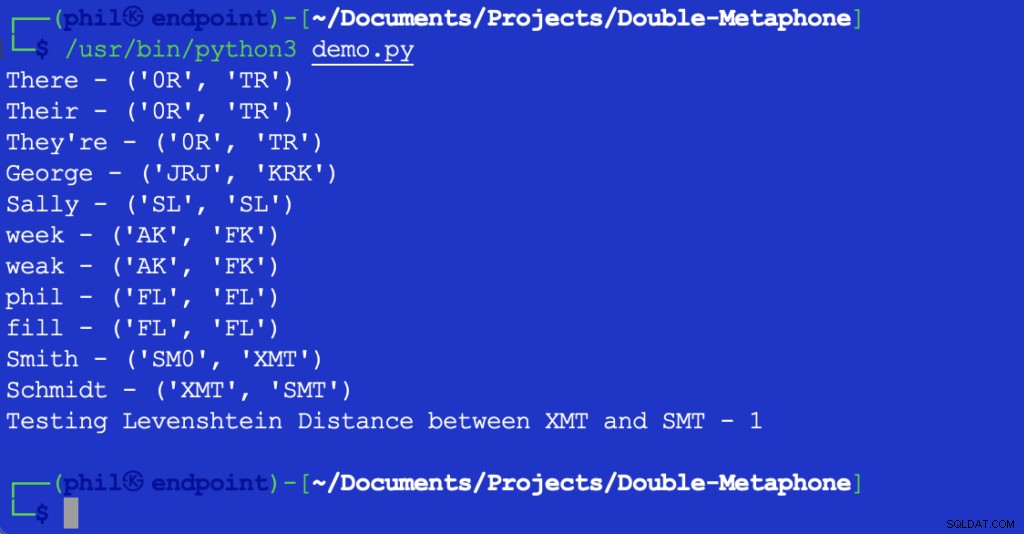
Фигура 1 – Изход на демонстрационен скрипт
Както може да се види тук, всяка дума има както първична, така и вторична фонетична стойност. Думите, които съвпадат както на първични, така и на вторични стойности, се наричат фонетични съвпадения. Думи, които споделят поне една фонетична стойност или които споделят първите няколко знака във всяка фонетична стойност, се казва, че са фонетично близо една до друга.
Повечето показаните букви съответстват на тяхното английско произношение. X може да съответства на KS , SH , или C . 0 съответства на тия звук в в или там . Гласните се съпоставят само в началото на думата. Поради безбройния брой разлики в регионалните акценти не е възможно да се каже, че думите могат да бъдат обективно точно съвпадение, дори ако имат еднакви фонетични стойности.
Сравняване на фонетични стойности с Python
Има много онлайн ресурси, които могат да опишат пълната работа на алгоритъма на двойния метафон; това обаче не е необходимо, за да го използваме, защото ние сме по-заинтересовани от сравняване изчислените стойности, повече, отколкото ни интересува да изчислим стойностите. Както беше посочено по-рано, ако има поне една обща стойност между две думи, може да се каже, че тези стойности са фонетични съвпадения и фонетични стойности, които са сходни са фонетично близки .
Сравняването на абсолютни стойности е лесно, но как може да се определи, че низовете са подобни? Въпреки че няма технически ограничения, които да ви попречат да сравнявате низове от няколко думи, тези сравнения обикновено са ненадеждни. Придържайте се към сравняване на отделни думи.
Какви са разстоянията на Левещайн?
Разстоянието Левещайн между два низа е броят на единичните символи, които трябва да бъдат променени в един низ, за да съответства на втория низ. Двойка струни, които имат по-ниско разстояние на Левещайн, са по-сходни една с друга от двойка струни, които имат по-високо разстояние на Левещайн. Разстоянието на Левещайн е подобно на Разстоянието на Хаминг , но последното е ограничено до низове с еднаква дължина, тъй като фонетичните стойности на Double Metaphone могат да варират по дължина, по-логично е да ги сравняваме с помощта на разстоянието на Левенщайн.
Библиотека за разстояние на Python Levenshtein
Python може да бъде разширен, за да поддържа изчисления на разстоянието на Levenshtein чрез модул на Python:
# If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install python-Levenshtein
Имайте предвид, че както при инсталирането на DoubleMetaphone по-горе, синтаксисът на извикването на pip може да варира. Модулът python-Levenshtein предоставя много повече функционалност от просто изчисляване на разстоянието Levenshtein.
Кодът по-долу показва тест за изчисляване на разстоянието на Левещайн в Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 2 - Demo extended to verify Levenshtein Distance calculation functionality
Изпълнението на този скрипт дава следния изход:
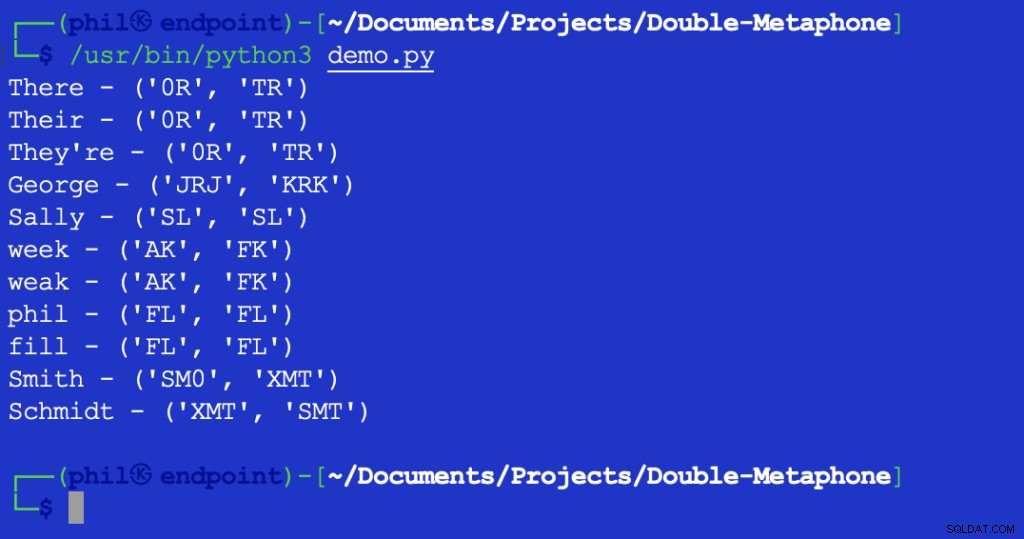
Фигура 2 – Изход на тест за разстояние на Левещайн
Върнатата стойност на 1 показва, че има един знак между XMT и SMT това е различно. В този случай това е първият символ и в двата низа.
Сравняване на двойни метафони в Python
Това, което следва, не е всичко и край на фонетичните сравнения. Това е просто един от многото начини за извършване на подобно сравнение. За да се сравни ефективно фонетичната близост на всеки два дадени низа, тогава всяка фонетична стойност на двойна метафона на един низ трябва да бъде сравнена със съответната фонетична стойност на двойна метафона на друг низ. Тъй като и двете фонетични стойности на даден низ имат еднаква тежест, тогава средната стойност на тези сравнителни стойности ще даде сравнително добро приближение на фонетичната близост:
PN = [ Dist(DM11, DM21,) + Dist(DM12, DM22,) ] / 2.0
Къде:
- DM1(1) :Първа двойна метафонна стойност на низ 1,
- DM1(2) :Втора двойна метафонна стойност на низ 1
- DM2(1) :Първа двойна метафонна стойност на низ 2
- DM2(2) :Втора двойна метафонна стойност на низ 2
- PN :Фонетична близост, като по-ниските стойности са по-близки от по-високите стойности. Нулева стойност показва фонетично сходство. Най-високата стойност за това е броят на буквите в най-късия низ.
Тази формула се разпада в случаи като Schmidt (XMT, SMT) и Смит (SM0, XMT) където първата фонетична стойност на първия низ съвпада с втората фонетична стойност на втория низ. В такива ситуации и двамата Schmidt и Смит може да се счита за фонетично сходно поради споделената стойност. Кодът за функцията за близост трябва да прилага формулата по-горе само когато всичките четири фонетични стойности са различни. Формулата също има слабости при сравняване на низове с различна дължина.
Забележете, че няма изключително ефективен начин за сравняване на низове с различни дължини, въпреки че се изчислява разстоянието на Левещайн между два фактора на низовете в разликите в дължината на низовете. Възможно решение би било да се сравнят двата низа до дължината на по-късия от двата низа.
По-долу е даден примерен кодов фрагмент, който имплементира кода по-горе, заедно с някои тестови проби:
# demo2.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testwords = ["Philippe", "Phillip", "Sallie", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt", "Harold", "Herald"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
print ("Distance between AK and AK - " + str(distance('AK', 'AK')) + "]")
print ("Comparing week and weak - [" + str(Nearness("week", "weak")) + "]")
print ("Comparing Harold and Herald - [" + str(Nearness("Harold", "Herald")) + "]")
print ("Comparing Smith and Schmidt - [" + str(Nearness("Smith", "Schmidt")) + "]")
print ("Comparing Philippe and Phillip - [" + str(Nearness("Philippe", "Phillip")) + "]")
print ("Comparing Phil and Phillip - [" + str(Nearness("Phil", "Phillip")) + "]")
print ("Comparing Robert and Joseph - [" + str(Nearness("Robert", "Joseph")) + "]")
print ("Comparing Samuel and Elizabeth - [" + str(Nearness("Samuel", "Elizabeth")) + "]")
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 3 - Implementation of the Nearness Algorithm Above
Примерният код на Python дава следния изход:
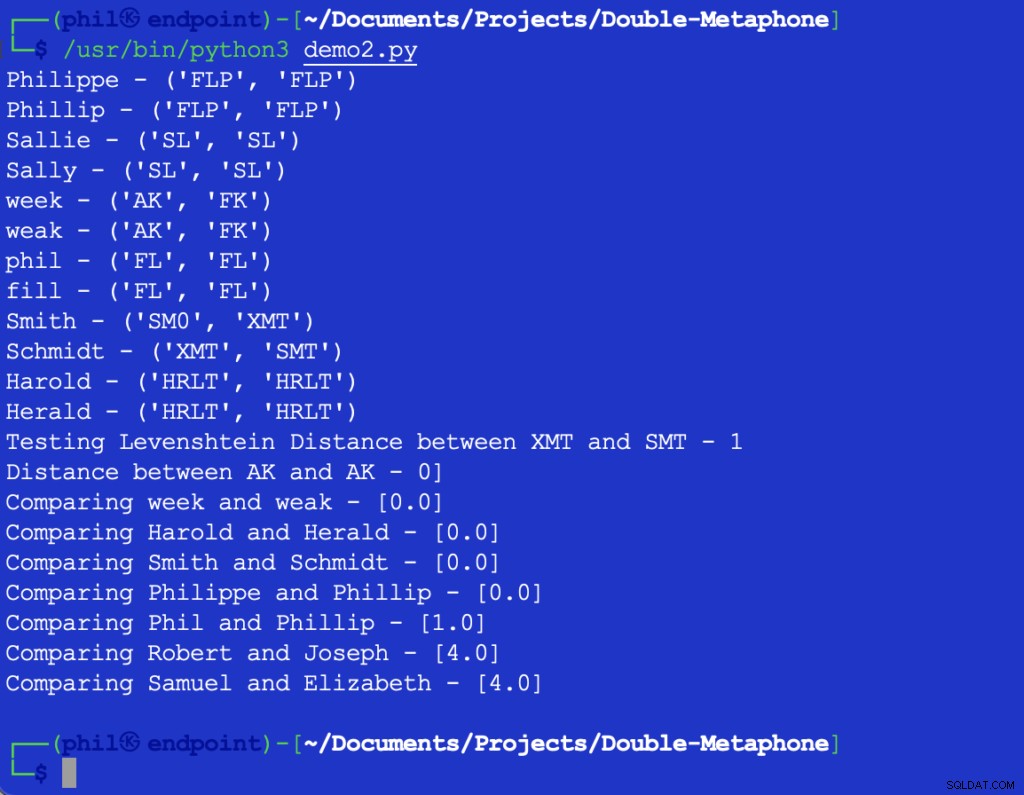
Фигура 3 – Изход на алгоритъма за близост
Наборът от извадки потвърждава общата тенденция, че колкото по-големи са разликите в думите, толкова по-висок е изходът на Близостта функция.
Интегриране на база данни в Python
Кодът по-горе нарушава функционалната пропаст между дадена RDBMS и реализация на двоен метафон. Освен това, чрез внедряване на Близостта функция в Python, става лесно да се замени, ако се предпочете различен алгоритъм за сравнение.
Помислете за следната таблица на MySQL/MariaDB:
create table demo_names (record_id int not null auto_increment, lastname varchar(100) not null default '', firstname varchar(100) not null default '', primary key(record_id)); Listing 4 - MySQL/MariaDB CREATE TABLE statement
В повечето приложения, управлявани от база данни, междинният софтуер съставя SQL изявления за управление на данните, включително вмъкването им. Следващият код ще вмъкне някои примерни имена в тази таблица, но на практика всеки код от уеб или настолно приложение, което събира такива данни, може да направи същото.
# demo3.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testNames = ["Smith, Jane", "Williams, Tim", "Adams, Richard", "Franks, Gertrude", "Smythe, Kim", "Daniels, Imogen", "Nguyen, Nancy",
"Lopez, Regina", "Garcia, Roger", "Diaz, Catalina"]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
for name in testNames:
nameParts = name.split(',')
# Normally one should do bounds checking here.
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
sql = "insert into demo_names (lastname, firstname) values(%s, %s)"
values = (lastname, firstname)
insertCursor = mydb.cursor()
insertCursor.execute (sql, values)
mydb.commit()
mydb.close()
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Inserting sample data into a database.
Изпълнението на този код не отпечатва нищо, но попълва тестовата таблица в базата данни за следващия списък, който да се използва. Запитването на таблицата директно в MySQL клиента може да провери дали кодът по-горе работи:
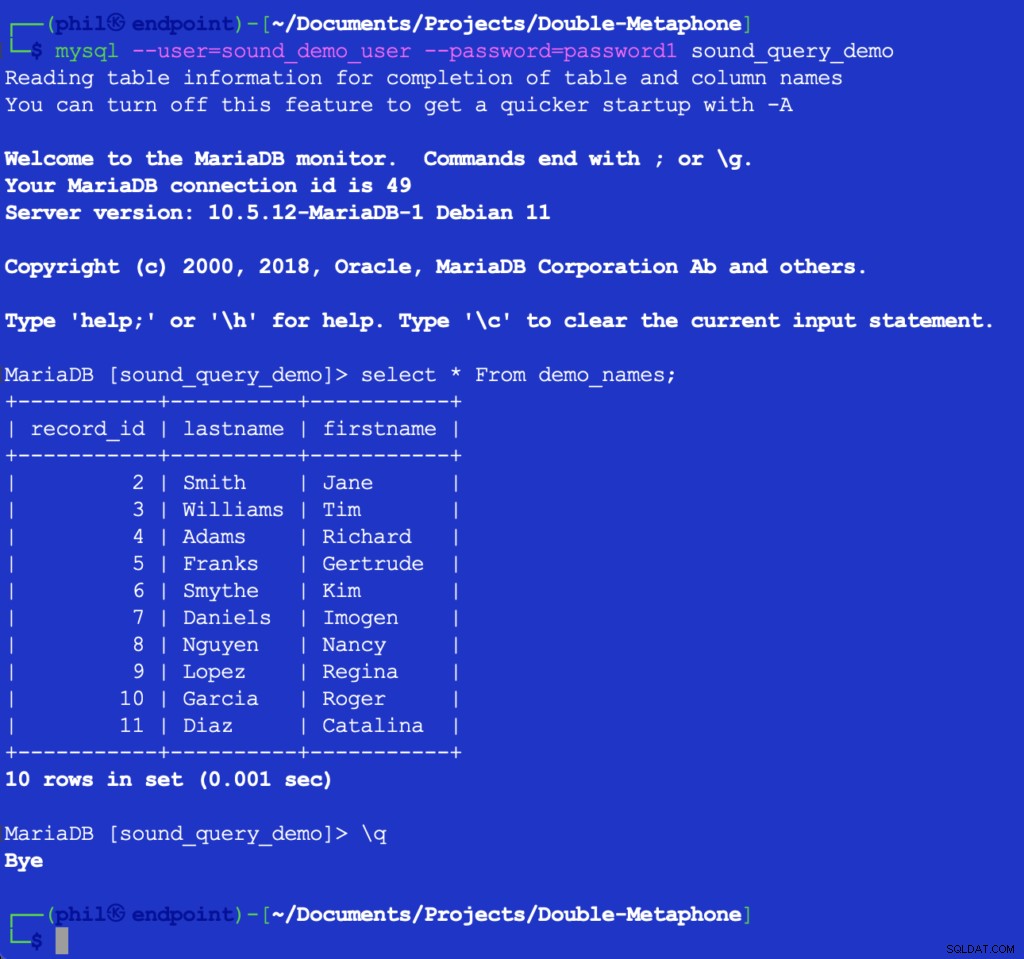
Фигура 4 – Вмъкнатите данни от таблица
Кодът по-долу ще подаде някои сравнителни данни в данните от таблицата по-горе и ще извърши сравнение на близост с тях:
# demo4.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
comparisonNames = ["Smith, John", "Willard, Tim", "Adamo, Franklin" ]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
sql = "select lastname, firstname from demo_names order by lastname, firstname"
cursor1 = mydb.cursor()
cursor1.execute (sql)
results1 = cursor1.fetchall()
cursor1.close()
mydb.close()
for comparisonName in comparisonNames:
nameParts = comparisonName.split(",")
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
print ("Comparison for " + firstname + " " + lastname + ":")
for result in results1:
firstnameNearness = Nearness (firstname, result[1])
lastnameNearness = Nearness (lastname, result[0])
print ("\t[" + firstname + "] vs [" + result[1] + "] - " + str(firstnameNearness)
+ ", [" + lastname + "] vs [" + result[0] + "] - " + str(lastnameNearness))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Nearness Comparison Demo
Изпълнението на този код ни дава изхода по-долу:
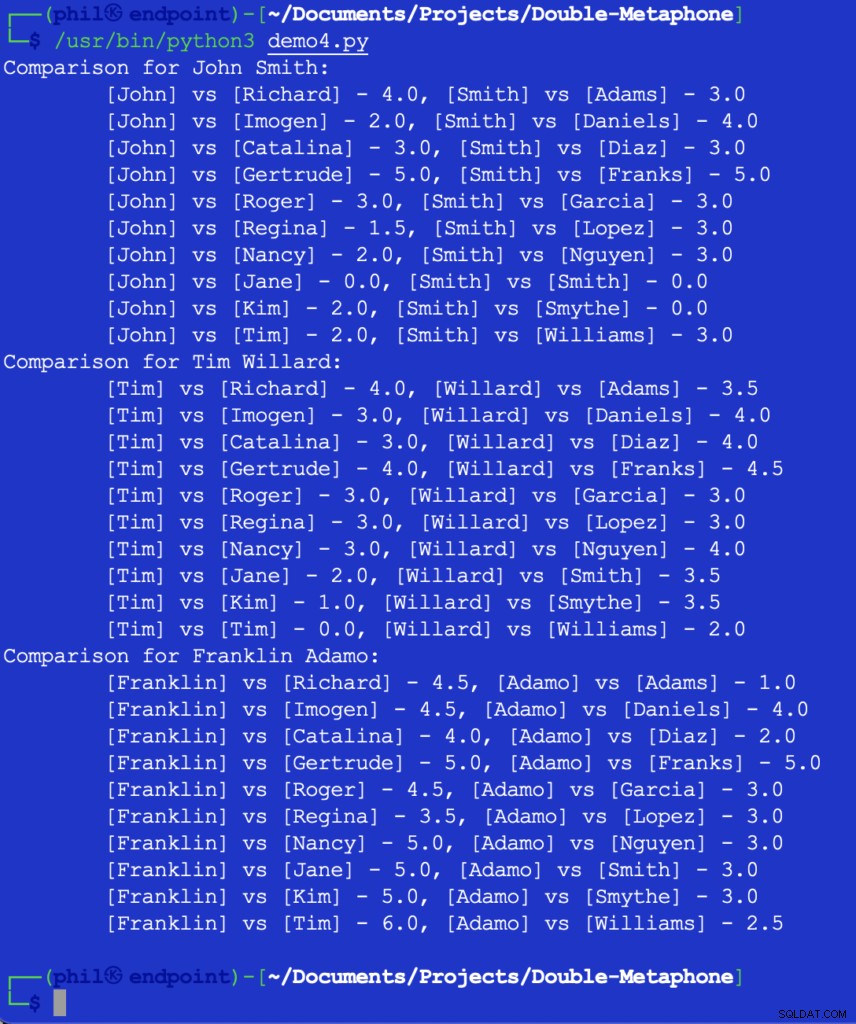
Фигура 5 – Резултати от сравнението на близост
В този момент разработчикът трябва да реши какъв ще бъде прагът за това, което представлява полезно сравнение. Някои от числата по-горе може да изглеждат неочаквани или изненадващи, но едно възможно допълнение към кода може да бъде IF израз за филтриране на всяка стойност за сравнение, която е по-голяма от 2 .
Може да си струва да се отбележи, че самите фонетични стойности не се съхраняват в базата данни. Това е така, защото те се изчисляват като част от кода на Python и няма реална нужда да ги съхранявате някъде, тъй като те се изхвърлят, когато програмата излезе, но разработчикът може да намери стойност в съхраняването им в базата данни и след това прилагането на сравнението функция в базата данни съхранена процедура. Въпреки това, единственият основен недостатък на това е загубата на преносимост на кода.
Окончателни разсъждения относно запитването на данни чрез звук с Python
Сравняването на данни по звук изглежда не привлича „любовта“ или вниманието, което може да получи сравняването на данни чрез анализ на изображения, но ако приложението трябва да работи с множество подобни звучащи варианти на думи на множество езици, това може да бъде изключително полезно инструмент. Една полезна характеристика на този тип анализ е, че разработчикът не трябва да е експерт по лингвистика или фонетика, за да използва тези инструменти. Разработчикът също така има голяма гъвкавост при дефинирането на това как тези данни могат да се сравняват; сравненията могат да бъдат коригирани въз основа на нуждите на приложението или бизнес логиката.
Надяваме се, че тази област на изследване ще получи повече внимание в изследователската сфера и ще има по-способни и стабилни инструменти за анализ в бъдеще.