В предишната си публикация за инкременталните статистически данни, нова функция в SQL Server 2014, демонстрирах как те могат да помогнат за намаляване на продължителността на задачата за поддръжка. Това е така, защото статистиката може да се актуализира на ниво дял и промените да се слеят в основната хистограма за таблицата. Също така отбелязах, че оптимизаторът на заявки не използва тези статистически данни на ниво дял, когато генерира планове за заявки, което може да е нещо, което хората очакваха. Не съществува документация, която да посочва, че инкременталните статистически данни ще бъдат или няма да бъдат използвани от оптимизатора на заявки. Е, откъде знаеш? Трябва да го тествате. :-)
Настройката
Настройката за този тест ще бъде подобна на тази в последния пост, но с по-малко данни. Имайте предвид, че размерите по подразбиране са по-малки за файловете с данни и скриптът се зарежда само в няколко милиона реда данни:
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', --everything in 2011 '20120101', --everything in 2012 '20130101', --everything in 2013 '20140101', --everything in 2014 '20150101' --everything in 2015 ); GO CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Когато създадем клъстерирания индекс за dbo.Orders, ще го създадем без STATISTICS_INCREMENTAL опцията е активирана, така че ще започнем с традиционна разделена таблица без нарастваща статистика:
ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ([OrderDate], [PurchaseOrderID]) ON [OrderDateRangePScheme] ([OrderDate]);
След това ще заредим на около 4 милиона реда, което отнема малко под минута на моята машина:
SET NOCOUNT ON; DECLARE @Loops SMALLINT = 0; DECLARE @Increment INT = 3000; WHILE @Loops < 1000 BEGIN INSERT [dbo].[Orders] ([PurchaseOrderID] ,[EmployeeID] ,[VendorID] ,[TaxAmt] ,[Freight] ,[SubTotal] ,[Status] ,[RevisionNumber] ,[ModifiedDate] ,[ShipMethodID] ,[ShipDate] ,[OrderDate] ,[TotalDue] ) SELECT [PurchaseOrderID] + @Increment , [EmployeeID] , [VendorID] , [TaxAmt] , [Freight] , [SubTotal] , [Status] , [RevisionNumber] , [ModifiedDate] , [ShipMethodID] , DATEADD(DAY, 365, [ShipDate]) , DATEADD(DAY, 365, [OrderDate]) , [TotalDue] + 365 FROM [Purchasing].[PurchaseOrderHeader]; CHECKPOINT; SET @Loops = @Loops + 1; SET @Increment = @Increment + 5000; END
След зареждането на данните ще актуализираме статистиката с FULLSCAN (за да можем да създадем възможно най-последователна хистограма за тестове) и след това ще проверим какви данни имаме във всеки дял:
UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN; SELECT $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number] , MIN([o].[OrderDate]) AS [Min_Order_Date] , MAX([o].[OrderDate]) AS [Max_Order_Date] , COUNT(*) AS [Rows_In_Partition] FROM [dbo].[Orders] AS [o] GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) ORDER BY [Partition Number];
 Данни във всеки дял след зареждане на данните
Данни във всеки дял след зареждане на данните
Повечето от данните са в дяла за 2015 г., но има и данни за 2012, 2013 и 2014 г. И ако проверим изхода от недокументирания DMV sys.dm_db_stats_properties_internal , можем да видим, че не съществуват статистически данни на ниво дял:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 sys.dm_db_stats_properties_internal изход, показващ само една статистика за dbo.Orders
sys.dm_db_stats_properties_internal изход, показващ само една статистика за dbo.Orders
Тестът
Тестването изисква проста заявка, която можем да използваме, за да проверим дали е налице елиминиране на дял, както и да проверим оценките въз основа на статистически данни. Заявката не връща никакви данни, но това няма значение, интересуваме се какво мисли оптимизаторът ще се върне въз основа на статистика:
SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
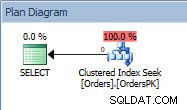 План на заявката за израза SELECT
План на заявката за израза SELECT
Планът има Clustered Index Seek и ако проверим свойствата, виждаме, че той оценява 4000 реда и има достъп до дял 5, който съдържа данни за 2014 г.
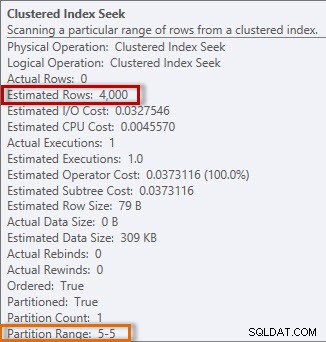 Прогнозна и действителна информация от търсенето на клъстерен индекс
Прогнозна и действителна информация от търсенето на клъстерен индекс
Ако погледнем хистограмата за таблицата dbo.Orders, конкретно в областта на данните за април 2014 г., виждаме, че няма стъпка за 2014-04-01, така че оптимизаторът изчислява броя на редовете за тази дата, използвайки стъпката за 2014-04-24, където AVG_RANGE_ROWS е 4000 (за всяка една стойност между 2014-02-14 и 2014-04-23 включително, оптимизаторът ще изчисли, че ще бъдат върнати 4000 реда).
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
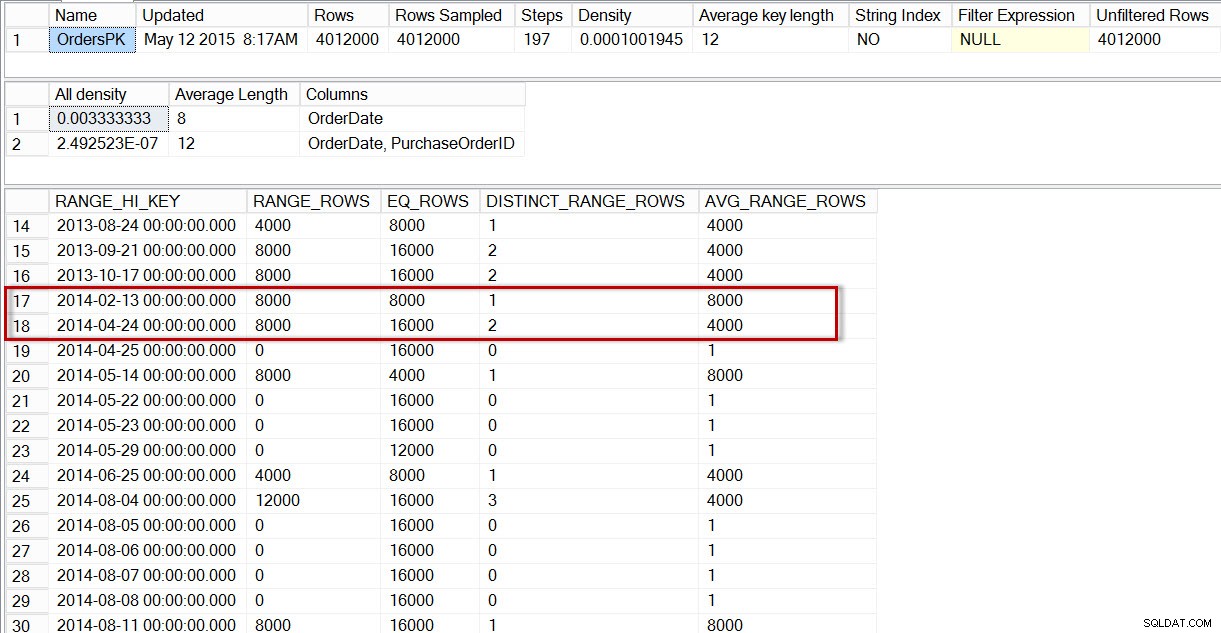 Разпределение в хистограмата на dbo.Orders
Разпределение в хистограмата на dbo.Orders
Разчетът и планът са напълно очаквани. Нека активираме постепенната статистика и да видим какво получаваме.
ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON); GO UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN;
Ако изпълним отново нашата заявка срещу sys.dm_db_stats_properties_internal , можем да видим постепенната статистика:
 sys.dm_db_stats_properties_internal показваща допълнителна статистическа информация
sys.dm_db_stats_properties_internal показваща допълнителна статистическа информация
Сега нека изпълним отново нашата заявка dbo.Orders и ще изпълним DBCC FREEPROCCACHE първо, за да се уверите, че планът няма да се използва повторно:
DBCC FREEPROCCACHE; GO SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
Получаваме същия план и същата оценка:
План на заявката за израза SELECT
Прогнозна и действителна информация от търсенето на клъстерен индекс
Ако проверим основната хистограма за dbo.Orders, ще видим почти същата хистограма като преди:
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
 Хистограма за dbo.Orders, след активиране на постепенна статистика
Хистограма за dbo.Orders, след активиране на постепенна статистика
Сега, нека проверим хистограмата за дяла с данни от 2014 г. (можем да направим това с помощта на недокументиран флаг за проследяване 2309, който позволява номер на дял да бъде посочен като допълнителен аргумент към DBCC SHOW_STATISTICS ):
DBCC TRACEON(2309);
GO
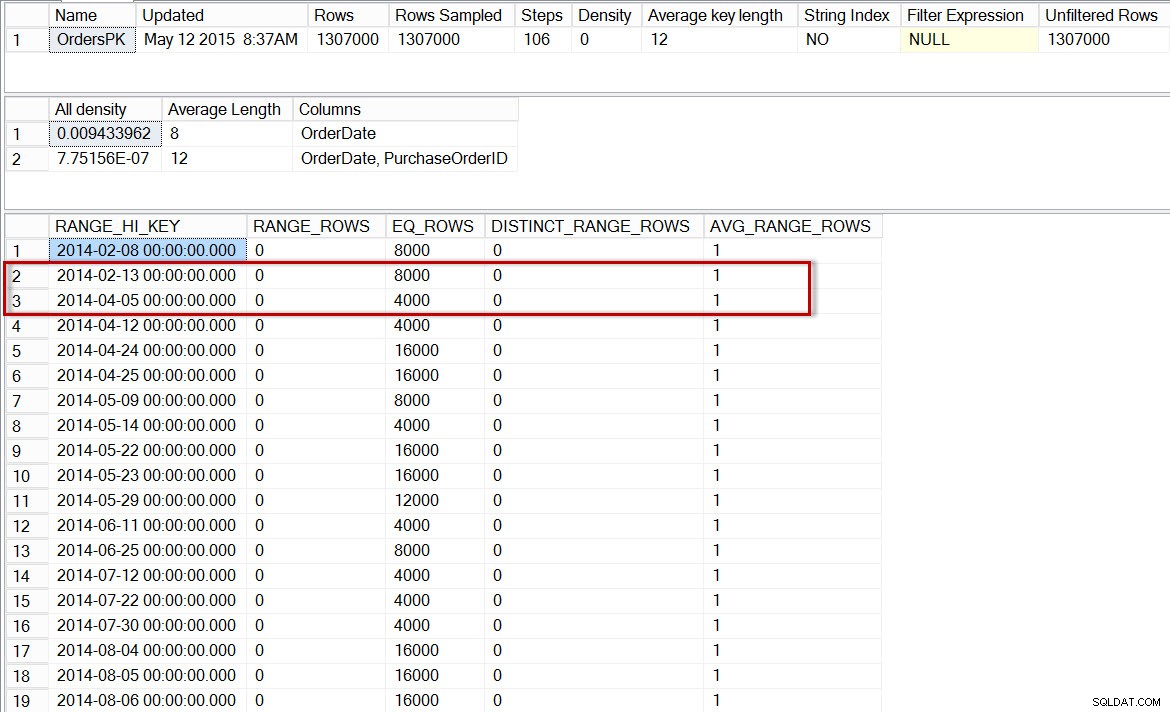
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK', 6);
Хистограма за дяла на dbo.Orders за 2014 г., след активиране на постепенна статистика
Тук виждаме, че отново няма стъпка за 2014-04-01, но има 0 RANGE_ROWS между 2014-02-13 и 2014-04-05, с AVG_RANGE_ROWS от 1. Ако оптимизаторът е използвал хистограмата за статистиката на ниво дял, тогава оценката за броя на редовете за 2014-04-01 ще бъде 1.
Забележка:Дялът, идентифициран като използван в плана на заявката, е 5, но ще забележите, че DBCC SHOW_STATISTICS Раздел 6 за препратки към изрази. Предположението е несъответствие в статистическите метаданни (често срещана грешка извън едно, вероятно поради преброяване на базата на 0 спрямо 1), което може или не може да бъде коригирано в бъдеще. Разберете, че флагът за проследяване не е документиран в момента и че не се препоръчва да се използва в производствена среда.
Резюме
Добавянето на инкрементални статистически данни в версията на SQL Server 2014 е стъпка в правилната посока за подобрени оценки на мощността за разделени таблици. Въпреки това, както демонстрирахме, текущата стойност на постепенната статистика е ограничена до намалена продължителност на поддръжката, тъй като тези допълнителни статистически данни все още не се използват от оптимизатора на заявки.