Системата за управление на базата данни е хранилището на информацията. Ще се опитаме да проектираме системата за управление на базата данни, така че базата данни да остане добре управлявана и да предоставя целите.
В тази статия ще обсъдим проектирането и администрирането на системи за бази данни с голям размер. Ще използваме множество конституции, които ще включват технологии за бази данни, съхранение, разпространение на данни, сървърни активи, архитектурен модел и някои други.
За предпочитане е да търсим голяма база данни в телеком домейна, платформи за електронна търговия, застрахователен домейн, банкова система, здравеопазване, енергийна система и т.н. Трябва да имаме предвид няколко параметъра, преди да изберем правилната технология за база данни. т.е. трафик, TPS (транзакции в секунда), прогнозно съхранение на ден, HA и DR.
Проектиране на база данни с голям размер
При конструирането на нашата база данни трябва да обърнем внимание на няколко параметъра, защото често е много проблематично да променим базата данни със заместител. Нека ги разгледаме сега.
Технология за бази данни
Технологията за бази данни е основният фактор. Ако изберете правилната система за управление на база данни, тя ще помогне на вашия бизнес да работи ефективно и без усилие.
Има различни технологии за бази данни с много функции. Въпреки това, докато работите с технологии за бази данни с отворен код, може да не получите достъп до някои изрични функции на предварително дефинирани решения. Технологиите за корпоративна база данни като Microsoft SQL Server, Oracle и т.н. биха ги предоставили.
Много технологии за корпоративни бази данни прилагат HA (висока достъпност), DR (възстановяване при бедствия), огледално копиране, репликация на данни, реплика за вторично четене и значително по-удобни и готови конфигурируеми бизнес решения. Те могат или не могат да присъстват в бази данни с отворен код.
Има много много причини. Например, понякога откриваме, че съществуващата архитектура е нарушена, защото тези фактори, споменати по-горе, не са функционални, тъй като имаме нужда от тях.
Съхранение
Съхранението влияе драстично върху производителността на бизнес решението. Бизнес решенията изискват първокласно съхранение или SSD с определено количество IOPS. Дали обаче е така? На място или в облак, размерът и типът на хранилището определят разходите за инфраструктура.
Докато разглеждаме производителността на съхранение, трябва да обърнем внимание на типа данни и поведението на обработката на данните. Трябва да изберем избор за съхранение според данните на потребителя и обработката им. Ако потребителят ще използва множество бази данни, трябва да предоставим избор за съхранение през SAN за различни бази данни за типовете данни и поведението при обработка на данни.
Инженерът на базата данни ще предостави по-добра ретроспекция на различните бази данни, необходими за изчисляване на IOPS, ако потребителите изобщо не се нуждаят от първокласно съхранение.
Разпространение на данни
Повечето от последните технологии за бази данни (SQL или NoSQL) предлагат функции за разделяне или разделяне.
- Дялът преразпределя данни във файловата система, която се основава на ключа на дяла.
- Sharding разпределя информация между възлите на базата данни и данните ще се съхраняват на една и съща или различна машина.
По принцип всяка услуга на база данни или таблица на база данни няма да изисква функциите за разделяне/разделяне на данни. Те изискват да се прилагат само върху бази данни, съдържащи обекти с по-голям размер. Това ще подобри производителността.
Активи на сървъра
Различните машини изискват различни видове и размери памет и процесор. Трябва да вземете предвид активите на хардуерно ниво, като памет, процесор и т.н. Например, машина, която трябва да обработва по-големи бази данни или множество бази данни, ще се нуждае от повече памет и процесори. Следователно качеството на паметта и процесора е значително. Той ще работи с различни видове процесори, налични на пазара, с различни кешове на процесора.
Много пъти се сблъскваме с проблеми, за които може да не сме наясно. Не обърнахме внимание на използването и ролята на кеша на процесора на хардуера. Но това е от решаващо значение за избора и отговарянето на хардуерните изисквания с по-големи системи за бази данни.
Архитектурен модел
При проектирането на база данни моделът на архитектурата винаги е примерна роля. По-рано системите за бази данни бяха проектирани по изключително монолитен начин. Сега използваме базирани на микро-услуги или хибридни (монолитни + микро).
Производителността, възможността за разширяване и нулевото време на престой зависят много от модела на архитектурата и дизайна на базата данни. Всяко приложение може да има отделна база данни и всички бази данни могат да бъдат слабо свързани една с друга. В случай на повреда на някое приложение или база данни, друга част от продукта няма да бъде нарушена. Всички микроуслуги ще бъдат независими и слабо свързани.
Микро услуга
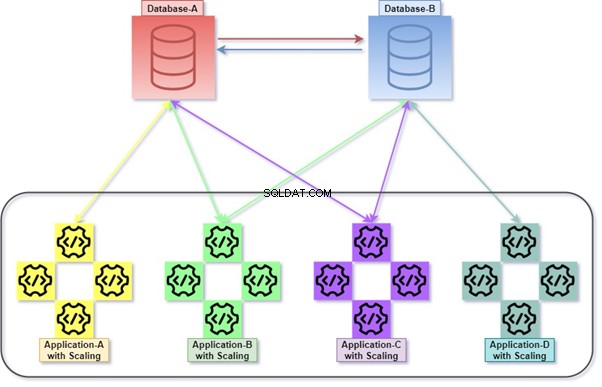
Диаграмата по-долу обяснява как всички приложения се разгръщат и комуникират с помощта на своите бази данни, които са слабо свързани едновременно. Можем да манипулираме данните с T-SQL. Информацията ще се събира или акумулира от различни приложения и клиентът ще има достъп до данните. Вижте диаграмата с броя на мащабираните приложения и нейната интегрирана база данни.
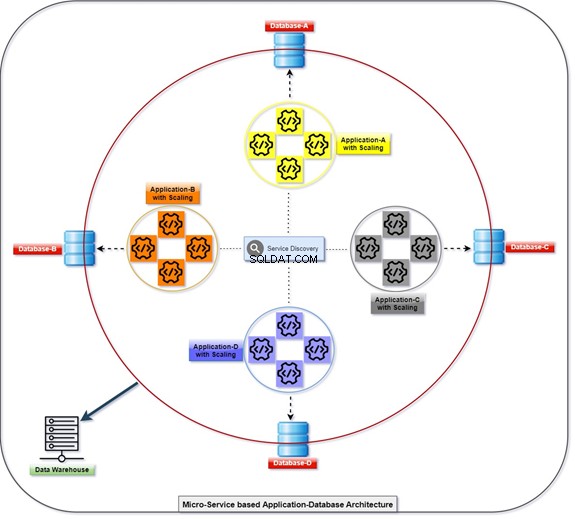
Монолитни
Коя RDBMS трябва да използваме? Може да бъде Oracle, Microsoft SQL Server, Postgres, MySQL, MongoDB или всяка друга база данни. Конвенционалният начин за работа с всички таблици или обекти, управлявани в една или множество бази данни в един сървър, е известен като монолитен.
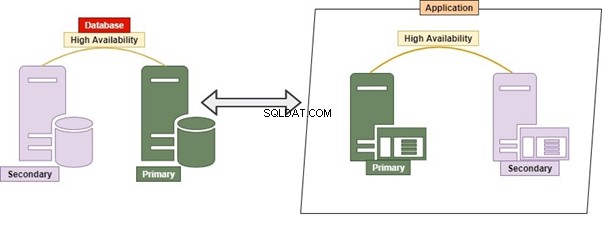
Хибрид
Hybrid е пермутация на Monolithic и Micro Service. Това е доста често срещана практика, тъй като позволява множество приложения, множество бази данни и сървъри на бази данни. Много бази данни и сървъри на бази данни могат да бъдат тясно свързани един с друг.
Например, запитване с JOIN между таблици, принадлежащи на две или повече бази данни в един и същ сървър на база данни или различен. Отдалечена заявка, използвана за извличане на данни/манипулация с друг сървър на база данни.
Всичко е свързано с архитектурата на SQL Server. Все пак говорим за манипулиране на данни между различни таблици в една и съща база данни или различни бази данни, които биха могли да се намират на един и същ сървър или различни сървъри.
В хибридна или монолитна архитектура ние използваме JOIN между различни таблици в една и съща или различни бази данни. Доста е сложно, когато следваме основните стандарти за Micro-Service, тъй като разпределението на таблиците може да бъде между услугите на базата данни (Dbas).
При технологиите за бази данни на Enterprise като Microsoft SQL Server, Oracle и др., потребителят може да запитва таблиците на разпределената база данни с помощта на Linked Server Joins. Но той не е наличен във всички технологии за бази данни с отворен код. Той е известен като тесно свързан подход, който може да не работи, когато услугата за отдалечена база данни не е налична.
Сега, нека обсъдим как го правим свободно свързан. Защо се нуждаем от манипулиране на данни между отдалечени бази данни?
Защо се нуждаем от манипулиране на данни между отдалечени бази данни?
Потребителите ще изискват данните да бъдат извлечени от повече от една услуга за база данни, когато системата е проектирана с помощта на микро или хибридни услуги. Целият процес се вижда от бекенда, който може да обработва количества данни, манипулирани от приложението.
Когато разглеждаме запитванията за кръстосани бази данни в реално време, ние винаги се присъединяваме към главните таблици на обекти, а не към таблиците с метаданни. Главните таблици няма да са по-големи от таблиците с метаданни. За целите на отчитането ние винаги използваме хранилището за данни, за да съберем цялата информация. Но това не е лесно за управление и поддръжка за всеки продукт. Ако проектираме корпоративното решение, можем да си позволим склада. Но не можем да си го позволим за малки или средни продукти.
Например, имаме нужда от отчет с данните от няколко таблици, намиращи се в различни бази данни. Това не е лесна задача за изпълнение, тъй като събира данните с помощта на различни микроуслуги и ги обединява, за да създаде отчета. Следователно необходимите данни трябва да се синхронизират.
Какво можем да използваме като стандартно решение да направите синхронизация на данни от хлабаво свързана таблица между две бази данни?
Репликацията на таблица трябва да се използва за проста синхронизация на данни между множество бази данни. Примерът е репликацията на транзакции за симплексната синхронизация на данни и репликацията на сливане за синхронизацията на дуплексните данни, предоставена от SQL Server.
Има няколко платени решения на трети страни и с отворен код, които могат да синхронизират данните между множество бази данни. Дори решения с хлабава връзка с помощта на опашки от съобщения като SQL Server Transaction Replication могат да бъдат разработени от потребителите самостоятелно.
Заключение
DBA проектират бази данни по свой начин. Докато проектират базата данни и избират системата за управление на базата данни, те трябва да имат предвид много аспекти. Представихме най-съществените фактори за дизайна на базата данни, особено за по-големите бази данни. Очаквайте следващите материали!