Имате трудности с SQL UNION? Това се случва, ако комбинираните от вас резултати поставят вашия SQL Server в застой. Или отчет, който е работил преди, изскача поле с червена икона X. Възниква грешка „Сблъсък на типа на операнда“, сочеща линия с UNION. "Огънят" започва. Звучи ви познато?
Независимо дали сте използвали SQL UNION от известно време или просто сте го започнали, лист за измама или кратък набор от бележки няма да навредят. Това е, което ще получите днес в тази публикация. Този списък предлага 10 полезни съвета както за начинаещи, така и за ветерани. Освен това ще има примери и някои разширени дискусии.

[sendpulse-form id=”11900″]
Но преди да преминем към първата точка, нека изясним термините.
UNION е един от операторите за набори в SQL, който комбинира 2 или повече набора от резултати. Може да е полезно, когато трябва да комбинирате имена, месечни статистически данни и други от различни източници. И независимо дали използвате SQL Server, MySQL или Oracle, целта, поведението и синтаксисът ще бъдат много сходни. Но как работи?
1. Използвайте SQL UNION, за да комбинирате Unique Записи
Използването на UNION за комбиниране на набори от резултати премахва дубликатите.
Защо това е важно?
През повечето време не искате резултати с дубликати. Доклад с дублиращи се редове губи мастило и хартия в хартиени копия. И това ще ядоса потребителите ви.
Как да го използвам
Комбинирате резултатите от операторите SELECT с UNION между тях.
Преди да започнем с примера, нека подготвим нашите примерни данни.
USE AdventureWorks
GO
IF OBJECT_ID ('dbo.Customer1', 'U') IS NOT NULL
DROP TABLE dbo.Customer1;
GO
IF OBJECT_ID ('dbo.Customer2', 'U') IS NOT NULL
DROP TABLE dbo.Customer2;
GO
IF OBJECT_ID ('dbo.Customer3', 'U') IS NOT NULL
DROP TABLE dbo.Customer3;
GO
-- Get 3 customer names with Andersen lastname
SELECT TOP 3
p.LastName
, p.FirstName
, c.AccountNumber
INTO dbo.Customer1
FROM Person.Person AS p
INNER JOIN Sales.Customer c
ON c.PersonID = p.BusinessEntityID
WHERE p.LastName = 'Andersen';
-- Make sure we have a duplicate in another table
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer2
FROM Customer1 c
-- Seems it's not enough. Let's have a 3rd copy
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer3
FROM Customer1 c
Ще използваме данните, генерирани от горния код до третия съвет. След като сме готови, по-долу е примерът:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
Имаме 3 копия от имената на едни и същи клиенти и очакваме уникалните записи да изчезнат. Вижте резултатите:
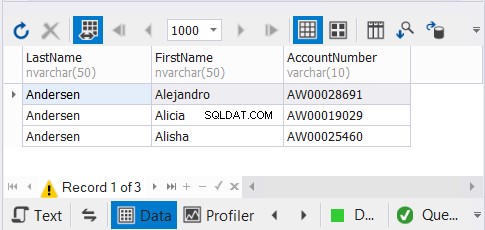
Решението dbForge Studio за SQL Server, което използваме за нашите примери, показва само 3 записа. Можеше да е 9. Като приложихме UNION, премахнахме дубликатите.
Как работи?
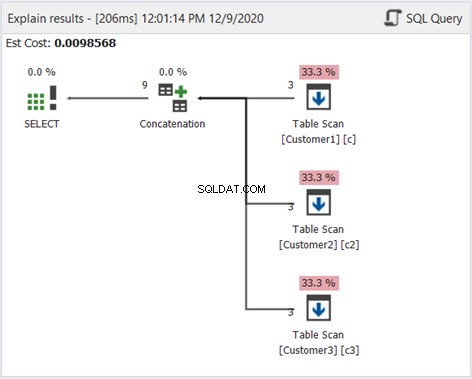
Плановата диаграма в dbForge Studio разкрива как SQL Server произвежда резултата, показан на фигура 1. Вижте:
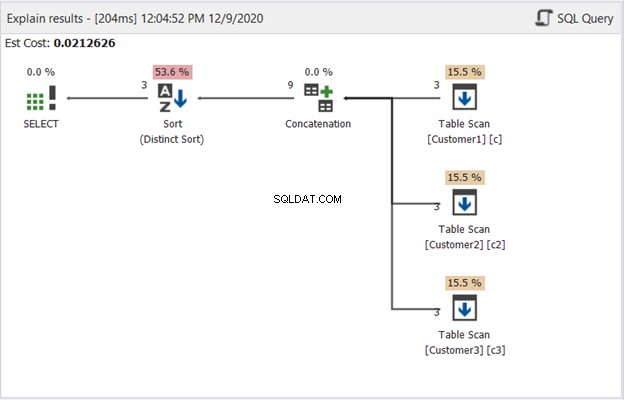
За да интерпретирате фигура 2, започнете от дясно наляво:
- Извлечехме 3 записа от всеки оператор за сканиране на таблици. Това са 3-те оператора SELECT от примера по-горе. Всеки ред, излизащ от него, показва „3“, което означава по 3 записа.
- Операторът за конкатенация извършва комбинирането на резултатите. Редът, излизащ от него, показва „9“ – изход от 9 записа от комбинирането на резултатите.
- Операторът Distinct Sort гарантира, че уникалните записи са крайният изход. Редът, излизащ от него, показва „3“, което е в съответствие с броя на записите на фигура 1.
Горната диаграма показва как UNION се обработва от SQL Server. Броят и типът на използваните оператори може да са различни в зависимост от заявката и основния източник на данни. Но в обобщение, СЪЮЗ работи по следния начин:
- Извличане на резултатите от всеки оператор SELECT.
- Комбинирайте резултатите с оператор за конкатенация.
- Ако комбинираните резултати не са уникални, SQL Server ще филтрира дубликатите.
Всички успешни примери с UNION следват тези основни стъпки.
2. Използвайте SQL UNION ALL, за да комбинирате записи с дубликати
Използването на UNION ALL комбинира набори от резултати с включени дубликати.
Защо това е важно?
Може да искате да комбинирате набори от резултати и след това да получите записите с дубликати за обработка по-късно. Тази задача е полезна за почистване на вашите данни.
Как да го използвам
Комбинирате резултатите от операторите SELECT с UNION ALL между тях. Разгледайте примера:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION ALL
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
Горният код извежда 9 записа, както е показано на Фигура 3:
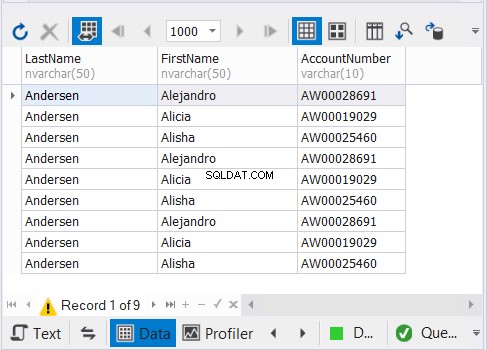
Как работи?
Както преди, ние използваме диаграмата на плана, за да разберем как работи това:
С изключение на Sort Distinct на фигура 2, диаграмата по-горе е същата. Това е подходящо, защото не искаме да филтрираме дубликатите.
Горната диаграма показва как работи UNION ALL. В обобщение, това са стъпките, които SQL Server ще следва:
- Извличане на резултатите от всеки оператор SELECT.
- След това комбинирайте резултатите с оператор за конкатенация.
Успешните примери с UNION ALL следват този модел.
3. Можете да смесвате SQL UNION и UNION ALL, но да ги групирате със скоби
Можете да смесите използването на UNION и UNION ALL в поне три оператора SELECT.
Как да го използвам?
Комбинирате резултатите от операторите SELECT с UNION или UNION ALL между тях. Скоби групират резултатите, които се събират. Нека използваме същите данни за следващия пример:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
(
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
)
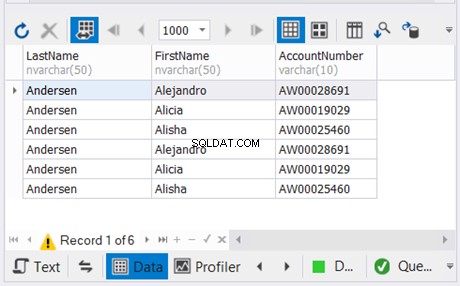
Горният пример комбинира резултатите от последните два оператора SELECT без дубликати. След това комбинира това с резултата от първия оператор SELECT. Резултатът е на фигура 5 по-долу:
4. Колоните на всеки оператор SELECT трябва да имат съвместими типове данни
Колоните във всеки оператор SELECT, който използва UNION, могат да имат различни типове данни. Приемливо е, стига да са съвместими и позволяват имплицитно преобразуване върху тях. Крайният тип данни на комбинираните резултати ще използва типа данни с най-висок приоритет. Също така, основата на крайния размер на данните са данните с най-голям размер. В случай на низове, той ще използва данните с най-голям брой знаци.
Защо това е важно?
Ако трябва да вмъкнете резултата от UNION в таблица, окончателният тип и размер на данните ще определят дали се вписват в колоната на целевата таблица или не. Ако не, ще възникне грешка. Например, една от колоните в UNION има краен тип NVARCHAR(50). Ако колоната на целевата таблица е VARCHAR(50), тогава не можете да я вмъкнете в таблицата.
Как работи?
Няма по-добър начин да го обясните от пример:
SELECT N'김지수' AS FullName
UNION
SELECT N'김제니' AS KoreanName
UNION
SELECT N'박채영' AS KoreanName
UNION
SELECT N'ลลิษา มโนบาล' AS ThaiName
UNION
SELECT 'Kim Ji-soo' AS EnglishName
UNION
SELECT 'Jennie Kim' AS EnglishName
UNION
SELECT 'Roseanne Park' AS EnglishName
UNION
SELECT 'Lalisa Manoban' AS EnglishName
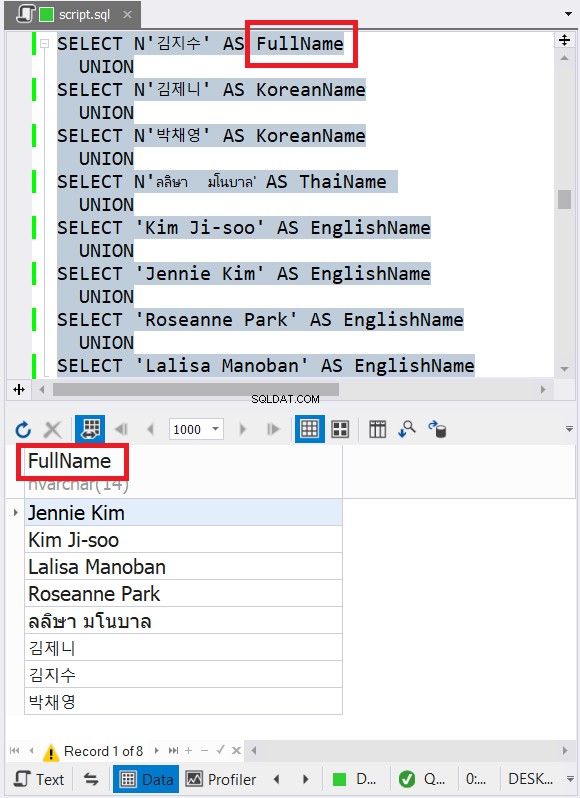
Пробата по-горе съдържа данни с имена на знаци на английски, корейски и тайландски. Тайландският и корейският са символи в Unicode. Английските знаци не са. И така, какъв според вас ще бъде окончателният тип и размер на данните? dbForge Studio го показва в набора от резултати:
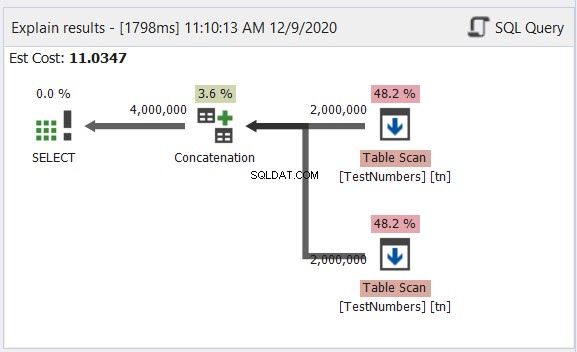
Забелязахте ли окончателния тип данни на фигура 6? Не може да бъде VARCHAR поради символите в Unicode. Така че трябва да е NVARCHAR. Междувременно размерът не може да бъде по-малък от 14, тъй като данните с най-голям брой знаци имат 14 знака. Вижте надписите в червено на фигура 6. Добре е да включите типа данни и размера в заглавката на колоната в dbForge Studio.
Такъв е случаят не само с низовите типове данни. Важи и за числата и датите. Междувременно, ако се опитате да комбинирате данни с несъвместими типове данни, ще възникне грешка. Вижте примера по-долу:
SELECT CAST('12/25/2020' AS DATE) AS col1
UNION
SELECT CAST('10' AS INT) AS col1
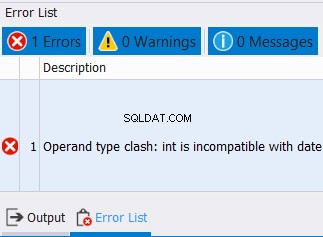
Не можем да комбинираме дати и цели числа в една колона. Така че очаквайте грешка като тази по-долу:
5. Имената на колоните на комбинираните резултати ще използват имената на колоните на първия оператор SELECT
Този проблем е свързан с предишния съвет. Обърнете внимание на имената на колоните в кода в Съвет №4. Във всеки оператор SELECT има различни имена на колони. Въпреки това видяхме последното име на колона в комбинирания резултат на фигура 6 по-рано. По този начин основата е името на колоната на първия оператор SELECT.
Защо това е важно?
Това може да бъде удобно, когато трябва да изхвърлите резултата от UNION във временна таблица. Ако трябва да се позовавате на имената на колоните му в следващите изрази, трябва да сте сигурни в имената. Освен ако не използвате усъвършенстван редактор на код с IntelliSense, сте готови за друга грешка във вашия T-SQL код.
Как работи?
Вижте Фигура 8 за по-ясни резултати от използването на dbForge Studio:
6. Добавете ORDER BY в последния оператор SELECT с SQL UNION, за да сортирате резултатите
Трябва да сортирате комбинираните резултати. В поредица от оператори SELECT с UNION между тях можете да го направите с клаузата ORDER BY в последния оператор SELECT.
Защо това е важно?
Потребителите искат да сортират данните по начина, по който предпочитат в приложения, уеб страници, отчети, електронни таблици и др.
Как да го използвам
Използвайте ORDER BY в последния оператор SELECT. Ето един пример:
SELECT
e.BusinessEntityID
,p.FirstName
,p.MiddleName
,p.LastName
,'Employee' AS PersonType
FROM HumanResources.Employee e
INNER JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID
UNION
SELECT
c.PersonID
,p.FirstName
,p.MiddleName
,p.LastName
,'Customer' AS PersonType
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
ORDER BY p.LastName, p.FirstName
Пробата по-горе прави да изглежда, че сортирането се случва само в последния оператор SELECT. Но не е така. Ще работи за комбинирания резултат. Ще имате проблеми, ако го поставите във всеки оператор SELECT. Вижте резултата:
Без ORDER BY резултатният набор ще има всички служители PersonType първо следван от всички клиентски PersonType . Фигура 9 обаче показва, че имената стават реда на сортиране на комбинирания резултат.
Ако се опитате да поставите ORDER BY във всеки оператор SELECT за сортиране, ето какво ще се случи:
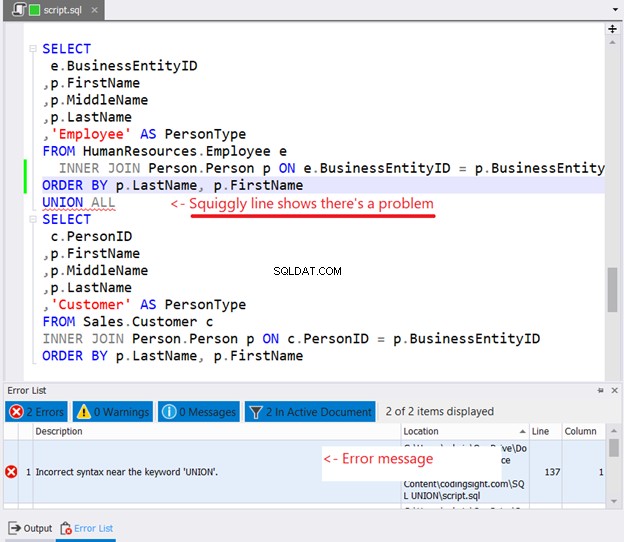
Видяхте ли криволичещата линия на фигура 10? Това е предупреждение. Ако не сте го забелязали и продължите, ще се появи грешка в прозореца със списък с грешки на dbForge Studio.
7. Клаузите WHERE и GROUP BY могат да се използват във всеки оператор SELECT с SQL UNION
Клаузата ORDER BY не работи във всеки оператор SELECT с UNION между тях. Клаузите WHERE и GROUP BY обаче работят.
Защо това е важно?
Може да искате да комбинирате резултатите от различни заявки, които филтрират, отчитат или обобщават данни. Например, можете да направите това, за да получите общите поръчки за продажба за януари 2012 г. и да ги сравните с януари 2013 г., януари 2014 г. и т.н.
Как да го използвам
Поставете клаузите WHERE и/или GROUP BY във всеки оператор SELECT. Вижте примера по-долу:
USE AdventureWorks
GO
-- Get the number of orders for January 2012, 2013, 2014 for comparison
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
Кодът по-горе комбинира броя на поръчките за януари за три последователни години. Сега проверете изхода:
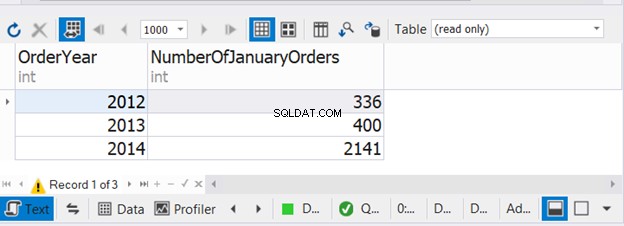
Този пример показва, че е възможно да използвате WHERE и GROUP BY във всеки от трите оператора SELECT с UNION.
8. SELECT INTO Работи с SQL UNION
Когато трябва да вмъкнете резултатите от заявка с SQL UNION в таблица, можете да го направите, като използвате SELECT INTO.
Защо това е важно?
Ще има моменти, когато трябва да поставите резултатите от заявка с UNION в таблица за по-нататъшна обработка.
Как да го използвам
Поставете клаузата INTO в първия оператор SELECT. Ето един пример:
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
INTO JanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
Не забравяйте да поставите само една клауза INTO в първия оператор SELECT.
Как работи
SQL Server следва модела на обработка UNION. След това вмъква резултата в таблицата, посочена в клаузата INTO.
9. Разграничете SQL UNION от SQL JOIN
И SQL UNION, и SQL JOIN комбинират данните от таблицата, но разликата в синтаксиса и резултатите е като нощ и ден.
Защо това е важно?
Ако вашият отчет или някое изискване се нуждае от JOIN, но сте направили UNION, изходът ще бъде грешен.
Как се използват SQL UNION и SQL JOIN
Това е SQL UNION срещу JOIN. Това е една от свързаните заявки за търсене и въпроси, които начинаещият прави в Google, когато научава за SQL UNION. Ето таблицата с разликите:
| SQL UNION | SQL JOIN | |
| Какво е комбинирано | Редове | Колони (с помощта на ключ) |
| Брой колони на таблица | Еднакво за всички таблици | Променлива (нула за всички колони/таблица) |
Във всички проекти, с които съм участвал, SQL JOIN се прилага през повечето време. Имах само няколко случая, които използваха SQL UNION. Но както видяхте досега, SQL UNION далеч не е безполезен.
10. SQL UNION ALL е по-бърз от UNION
Плановите диаграми на фигура 2 и фигура 4 по-рано предполагат, че UNION изисква допълнителен оператор, за да осигури уникални резултати. Ето защо UNION ALL е по-бърз.
Защо това е важно?
Вие, вашите потребители, вашите клиенти, вашият шеф, всички искате бързи резултати. Знаейки, че UNION ALL е по-бърз от UNION, ви кара да се чудите какво да правите, ако имате нужда от уникални комбинирани резултати. Има едно решение, както ще видите по-късно.
SQL UNION ALL спрямо UNION производителност
Фигура 2 и Фигура 4 вече ви дадоха представа кое е по-бързо. Но използваните примерни кодове са прости с малък набор от резултати. Нека добавим още няколко сравнения, използвайки милиони записи, за да го направим убедителен.
Като начало, нека подготвим данните:
SELECT TOP (2000000)
val = ROW_NUMBER() OVER (ORDER BY sod.SalesOrderDetailID)
INTO dbo.TestNumbers
FROM AdventureWorks.Sales.SalesOrderDetail sod
CROSS JOIN AdventureWorks.Sales.SalesOrderDetail sod2
Това са 2 милиона записа. Надявам се, че това е достатъчно убедително. Сега нека имаме следващите две проби на заявка по-долу.
-- Using UNION ALL
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
-- Using UNION
SELECT
val
FROM TestNumbers tn
UNION
SELECT
val
FROM TestNumbers tn
Нека да разгледаме процесите, включени в тези заявки, като започнем с по-бързия.
Анализ на диаграма на план
Диаграмата на фигура 12 изглежда типична за процес UNION ALL. Резултатът обаче е 4 милиона комбинирани резултати. Вижте стрелката, излизаща от оператора за конкатенация. И все пак обикновено е, защото не се занимава с дубликатите.
Сега, нека имаме диаграмата на заявката UNION на фигура 13:
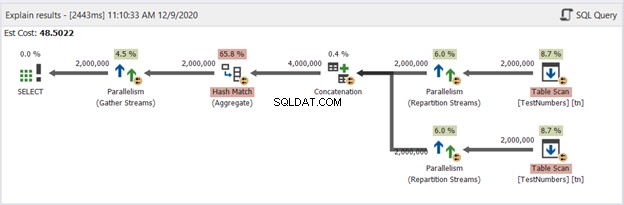
Този вече не е типичен. Планът се превръща в план за паралелна заявка за справяне с премахването на дубликати в четири милиона реда. Планът за паралелни заявки означава, че SQL Server трябва да раздели процеса на броя на наличните за него процесорни ядра.
Нека го интерпретираме, като започнем от десните оператори, отиващи наляво:
- Тъй като комбинираме таблица със себе си, SQL Server трябва да я извлече два пъти. Вижте двете сканирания на таблици с по два милиона записа всеки.
- Операторите на Repartition Stream ще контролират разпределението на всеки ред към следващата налична нишка.
- Конкатенацията удвоява резултата до четири милиона. Това все още се взема предвид броя на процесорните ядра.
- За премахване на дубликатите се прилага съвпадение на хеш. Това е скъп процес с 65,8% операторски разходи. В резултат на това два милиона записа бяха изхвърлени.
- Gather Streams рекомбинират резултатите, направени във всяко процесорно ядро или нишка, в едно.
Това е твърде много работа, въпреки че процесът е разделен на множество нишки. Следователно ще заключите, че ще работи по-бавно. Но какво ще стане, ако има решение за получаване на уникални записи с UNION ALL, но по-бързо от това?
Уникални резултати, но по-бързо коригиране с UNION ALL – Как?
няма да те карам да чакаш. Ето кода:
SELECT DISTINCT
val
FROM
(
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
) AS uniqtn
Това може да бъде куцо решение. Но вижте неговата планова диаграма на фигура 14:
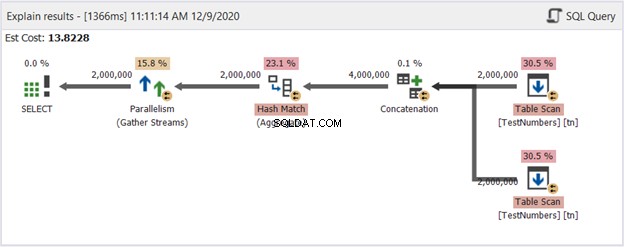
И така, какво го направи по-добър? Ако го сравните с Фигура 13, ще видите, че операторите на Repartition Stream са изчезнали. Въпреки това, той все още използва множество нишки, за да свърши работата. От друга страна, това означава, че оптимизаторът на заявки смята, че този процес е по-лесен за изпълнение от заявката, използваща UNION.
Можем ли безопасно да заключим, че трябва да избягваме използването на UNION и вместо това да използваме този подход? Въобще не! Винаги проверявайте диаграмата на плана за изпълнение! Винаги зависи от това какво искате да ви даде SQL Server. Това показва само, че ако се сблъскате със стена за производителност, трябва да промените подхода си към заявката.
Какво ще кажете за I/O статистика?
Не можем да отхвърлим колко ресурси са необходими на SQL Server, за да обработи нашите примери за заявки. Ето защо ние също трябва да проучим техните STATISTICS IO. Сравнявайки трите заявки по-горе, получаваме логическите показания по-долу:
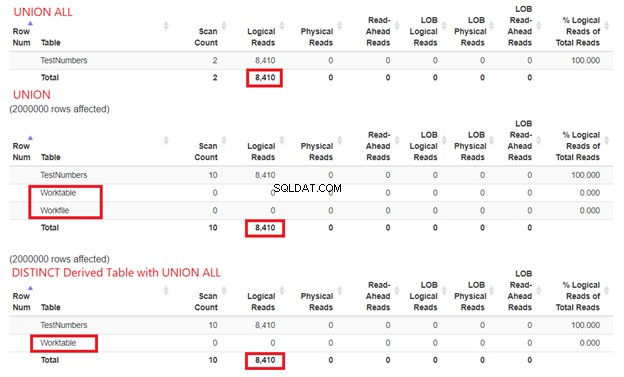
От фигура 15 все още можем да заключим, че UNION ALL е по-бърз от UNION, въпреки че логическите показания са едни и същи. Наличието на Worktable и Работен файл показва с помощта на tempdb за да свърши работата. Междувременно, когато използваме SELECT DISTINCT от извлечена таблица с UNION ALL, tempdb използването е по-малко в сравнение с UNION. Това допълнително потвърждава, че нашият анализ от диаграмите на плана по-рано е правилен.
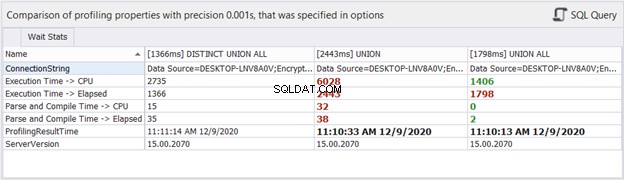
Какво ще кажете за статистиката за времето?
Въпреки че изминалото време може да се промени при всяко изпълнение, което правим на едни и същи заявки, това може да ни даде някаква представа и да добави повече доказателства към нашия анализ. dbForge Studio показва разликите във времето на трите заявки по-горе. Това сравнение е в съответствие с предишния анализ, който направихме.
Заключение
Покрихме много предистория, за да предоставим това, от което се нуждаете, за да използвате SQL UNION и UNION ALL. Може да не помните всичко, след като прочетете тази публикация, така че не забравяйте да маркирате тази страница.
Ако ви харесва публикацията, не се колебайте да я споделите в социалните медии.