ANY агрегатът не е нещо, което можем да напишем директно в Transact SQL. Това е само вътрешна функция, използвана от оптимизатора на заявки и машината за изпълнение.
Аз лично много харесвам ANY агрегат, така че беше малко разочароващо да научим, че е счупен по доста фундаментален начин. Конкретният вкус на „счупен“, за който имам предвид тук, е разнообразието с грешни резултати.
В тази публикация разглеждам две конкретни места, където ANY обобщението обикновено се показва, демонстрира проблема с грешните резултати и предлага заобиколни решения, където е необходимо.
За фон на ANY aggregate, моля, вижте предишната ми публикация Планове за недокументирани заявки:ВСЯКАКВА Агрегат.
1. Един ред на групови заявки
Това трябва да е едно от най-често срещаните ежедневни изисквания за заявка, с много добре познато решение. Вероятно пишете този вид заявка всеки ден, автоматично следвайки шаблона, без наистина да мислите за това.
Идеята е да номерирате входния набор от редове с помощта на ROW_NUMBER функция прозорец, разделена от групиращата колона или колони. Това е обвито в Общ израз на таблица или производна таблица и се филтрира до редове, където изчисленият номер на ред е равен на единица. От ROW_NUMBER рестартира от един за всяка група, това ни дава необходимия един ред за група.
Няма проблем с този общ модел. Типът на един ред на групова заявка, която е предмет на ANY обобщен проблем е този, при който не ни интересува кой конкретен ред е избран от всяка група.
В такъв случай не е ясно коя колона трябва да се използва в задължителния ORDER BY клауза от ROW_NUMBER функция прозорец. В крайна сметка, ние изрично не ни пука кой ред е избран. Един често срещан подход е повторното използване на PARTITION BY колона(и) в ORDER BY клауза. Тук може да възникне проблемът.
Пример
Нека разгледаме пример с набор от данни за играчки:
CREATE TABLE #Data
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL
);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, NULL, 1),
(1, 1, NULL),
(1, 111, 111),
-- Group 2
(2, NULL, 2),
(2, 2, NULL),
(2, 222, 222);
Изискването е да се върне всеки един пълен ред данни от всяка група, където членството в групата се определя от стойността в колона c1 .

Следвайки ROW_NUMBER модел, можем да напишем заявка като следната (забележете ORDER BY клауза от ROW_NUMBER функцията прозорец съвпада с PARTITION BY клауза):
WITH
Numbered AS
(
SELECT
D.*,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM #Data AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Както е представено, тази заявка се изпълнява успешно, с правилни резултати. Резултатите са технически недетерминирани тъй като SQL Server може валидно да върне всеки един от редовете във всяка група. Независимо от това, ако изпълните тази заявка сами, е много вероятно да видите същия резултат като аз:
Планът за изпълнение зависи от използваната версия на SQL Server и не зависи от нивото на съвместимост на базата данни.
На SQL Server 2014 и по-стари, планът е:

За SQL Server 2016 или по-нова версия ще видите:

И двата плана са безопасни, но по различни причини. Отличен сорт планът съдържа ANY агрегат, но Отличен сорт реализацията на оператора не показва грешката.
По-сложният план за SQL Server 2016+ не използва ANY агрегат изобщо. Сортиране поставя редовете в реда, необходим за операцията за номериране на редове. Сегментът операторът задава флаг в началото на всяка нова група. Проектът последователност изчислява номера на реда. И накрая, Филтър операторът предава само тези редове, които имат изчислен номер на ред един.
Бъгът
За да получим неправилни резултати с този набор от данни, трябва да използваме SQL Server 2014 или по-стара версия и ANY агрегатите трябва да бъдат внедрени в Stream Aggregate или Eager Hash Aggregate оператор (Flow Distinct Hash Match Aggregate не произвежда грешка).
Един от начините да насърчите оптимизатора да избере Stream Aggregate вместо Отлично сортиране е да добавите клъстериран индекс, за да осигурите подреждане по колона c1 :
CREATE CLUSTERED INDEX c ON #Data (c1);
След тази промяна планът за изпълнение става:

ANY агрегатите се виждат в Свойства прозорец, когато Агрегат на потока е избран оператор:

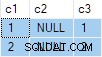
Резултатът от заявката е:
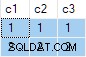
Това е грешно . SQL Server върна редове, които не съществуват в изходните данни. Няма изходни редове, където c2 = 1 и c3 = 1 например. Като напомняне, изходните данни са:
Планът за изпълнение погрешно изчислява отделно ANY агрегати за c2 и c3 колони, пренебрегвайки нулевите стойности. Всеки агрегат независимо връща първия не-нула стойност, която среща, давайки резултат, където стойностите за c2 и c3 идват от различни изходни редове . Това не е искано от оригиналната спецификация на SQL заявка.
Същият грешен резултат може да се получи с или без клъстерирания индекс чрез добавяне на OPTION (HASH GROUP) намек за създаване на план с Eager Hash Aggregate вместо Stream Aggregate .
Условия
Този проблем може да възникне само при няколко ANY присъстват агрегати, а обобщените данни съдържат нулеви стойности. Както бе отбелязано, проблемът засяга само Stream Aggregate и Eager Hash Aggregate оператори; Различно сортиране и Различен поток не са засегнати.
SQL Server 2016 нататък полага усилия да избегне въвеждането на множество ANY агрегати за модела на заявка за номериране на всеки един ред на група, когато изходните колони са нулеви. Когато това се случи, планът за изпълнение ще съдържа Сегмент , Проект за последователност и Филтър оператори вместо агрегат. Тази форма на план винаги е безопасна, тъй като няма ANY се използват агрегати.
Възпроизвеждане на грешката в SQL Server 2016+
Оптимизаторът на SQL Server не е перфектен при откриване кога колона първоначално е ограничена да бъде NOT NULL може все пак да генерира нулева междинна стойност чрез манипулации на данни.
За да възпроизведем това, ще започнем с таблица, където всички колони са декларирани като NOT NULL :
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;
CREATE TABLE #Data
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL
);
CREATE CLUSTERED INDEX c ON #Data (c1);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, 1, 1),
(1, 2, 2),
(1, 3, 3),
-- Group 2
(2, 1, 1),
(2, 2, 2),
(2, 3, 3);
Можем да произвеждаме нулеви стойности от този набор от данни по много начини, повечето от които оптимизаторът може успешно да открие, и така избягваме въвеждането на ANY агрегати по време на оптимизация.
Един от начините за добавяне на нули, които се случват да се изплъзнат под радара, е показан по-долу:
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2; Тази заявка произвежда следния изход:
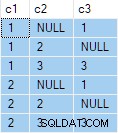
Следващата стъпка е да използвате тази спецификация на заявката като изходни данни за стандартната заявка „всеки един ред на група“:
WITH
SneakyNulls AS
(
-- Introduce nulls the optimizer can't see
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2
),
Numbered AS
(
SELECT
D.c1,
D.c2,
D.c3,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM SneakyNulls AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; На всяка версия на SQL Server, което създава следния план:
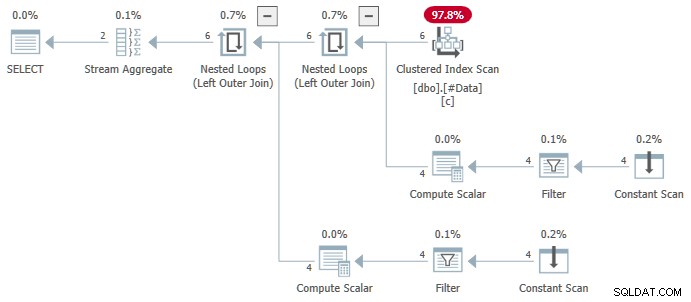
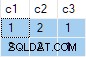
Агрегатът на потока съдържа множество ANY агрегати, а резултатът е грешен . Нито един от върнатите редове не се появява в изходния набор от данни:
db<>fiddle онлайн демонстрация
Заобиколно решение
Единственото напълно надеждно решение, докато тази грешка не бъде отстранена, е да се избегне моделът, при който ROW_NUMBER има същата колона в ORDER BY клауза, както е в PARTITION BY клауза.
Когато не ни интересува кое по един ред е избран от всяка група, жалко е, че ORDER BY клаузата изобщо е необходима. Един от начините да избегнете проблема е да използвате константа за време на изпълнение като ORDER BY @@SPID във функцията прозорец.
2. Недетерминирана актуализация
Проблемът с няколко ANY агрегатите на входове с нулеви стойности не е ограничено до всеки един ред на групова заявка. Оптимизаторът на заявки може да въведе вътрешен ANY съвкупност при редица обстоятелства. Един от тези случаи е недетерминирана актуализация.
недетерминиран update е мястото, където изразът не гарантира, че всеки целеви ред ще бъде актуализиран най-много веднъж. С други думи, има множество изходни реда за поне един целеви ред. Документацията изрично предупреждава за това:
Бъдете внимателни, когато посочвате клаузата FROM, за да предоставите критериите за операцията за актуализиране.Резултатите от оператор UPDATE са недефинирани, ако изразът включва клауза FROM, която не е посочена по такъв начин, че да е налична само една стойност за всяка поява на колона, която се актуализира, че е, ако изразът UPDATE не е детерминистичен.
За да се справи с недетерминирана актуализация, оптимизаторът групира редовете по ключ (индекс или RID) и прилага ANY агрегати към останалите колони. Основната идея там е да изберете един ред от множество кандидати и да използвате стойности от този ред, за да извършите актуализацията. Има очевидни паралели с предишния ROW_NUMBER проблем, така че не е изненада, че е доста лесно да се демонстрира неправилна актуализация.
За разлика от предишния проблем, SQL Server понастоящем не предприема специални стъпки за да избегнете множество ANY агрегати върху колони с нулеви стойности при извършване на недетерминирана актуализация. Следователно следното се отнася до всички версии на SQL Server , включително SQL Server 2019 CTP 3.0.
Пример
DECLARE @Target table
(
c1 integer PRIMARY KEY,
c2 integer NOT NULL,
c3 integer NOT NULL
);
DECLARE @Source table
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL,
INDEX c CLUSTERED (c1)
);
INSERT @Target
(c1, c2, c3)
VALUES
(1, 0, 0);
INSERT @Source
(c1, c2, c3)
VALUES
(1, 2, NULL),
(1, NULL, 3);
UPDATE T
SET T.c2 = S.c2,
T.c3 = S.c3
FROM @Target AS T
JOIN @Source AS S
ON S.c1 = T.c1;
SELECT * FROM @Target AS T; db<>fiddle онлайн демонстрация
Логично, тази актуализация винаги трябва да генерира грешка:Таблицата на целевата таблица не позволява нулеви стойности в нито една колона. Който и съвпадащ ред е избран от изходната таблица, опит за актуализиране на колона c2 или c3 до нула трябва възникне.
За съжаление, актуализацията е успешна и крайното състояние на целевата таблица не е в съответствие с предоставените данни:
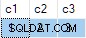
Съобщих за това като за грешка. Работата е да се избегне писането на недетерминиран UPDATE изрази, така че ANY не са необходими агрегати за разрешаване на неяснотата.
Както споменахме, SQL Server може да въведе ANY агрегати при повече обстоятелства от двата примера, дадени тук. Ако това се случи, когато обобщената колона съдържа нулеви стойности, има потенциал за грешни резултати.