Релационните бази данни представляват данните на организацията в таблици, които използват колони с различни типове данни, което им позволява да съхраняват валидни стойности. Разработчиците и администраторите на данни трябва да знаят и разбират подходящия тип данни за всяка колона за по-добра производителност на заявката.
Тази статия ще се занимава с популярните типове данни VARCHAR() и NVARCHAR(), тяхното сравнение и прегледи на производителността в SQL Server.
VARCHAR [ ( n | макс. ) ] в SQL
VARCHAR типът данни представлява не-Unicode тип данни низ с променлива дължина. Можете да съхранявате букви, цифри и специални знаци в него.
- N представлява размер на низа в байтове.
- Колоната тип данни VARCHAR съхранява максимум 8000 знака, различни от Unicode.
- Типът данни VARCHAR отнема 1 байт на знак. Ако не посочите изрично стойността за N, това отнема 1-байт за съхранение.
Забележка:Не бъркайте N със стойност, представляваща броя на знаците в низ.
Следната заявка дефинира тип данни VARCHAR със 100 байта данни.
DECLARE @text AS VARCHAR(100) ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Връща дължината като 17 поради 1 байт на знак, включително символ за интервал.
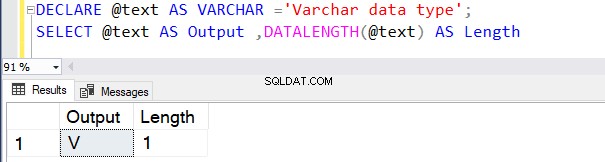
Следната заявка дефинира тип данни VARCHAR без стойност на N . Следователно SQL Server счита стойността по подразбиране като 1 байт, както е показано по-долу.
DECLARE @text AS VARCHAR ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
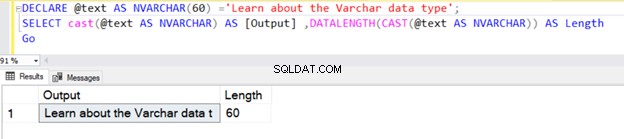
Можем също да използваме VARCHAR с помощта на функцията CAST или CONVERT. Например в двата примера по-долу сме декларирали променлива с дължина 100 байта и по-късно използвахме оператора CAST.
Първата заявка връща дължината като 30, тъй като не сме посочили N в типа данни на оператора CAST VARCHAR. Дължината по подразбиране е 30.
DECLARE @text AS VARCHAR(100) ='Learn about the VARCHAR data type';
SELECT cast(@text AS VARCHAR) AS [Output] ,DATALENGTH(CAST(@text AS VARCHAR)) AS Length
Go
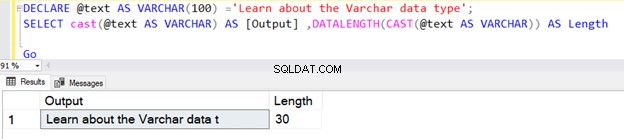
Въпреки това, ако дължината на низа е по-малка от 30, тя приема действителния размер на низа.

NVARCHAR [ ( n | макс. ) ] в SQL
NVARCHAR типът данни е за Unicode тип данни за символи с променлива дължина. Тук N се отнася до набора от символи на националния език и се използва за дефиниране на Unicode низ. Можете да съхранявате както не-Unicode, така и Unicode знаци (японски канджи, корейски хангул и др.).
- N представлява размер на низа в байтове.
- Може да съхранява максимум 4000 Unicode и не-Unicode знака.
- Типът данни VARCHAR отнема 2 байта на знак. Отнема 2 байта съхранение, ако не посочите никаква стойност за N.
Следната заявка дефинира типа данни VARCHAR със 100 байта данни.
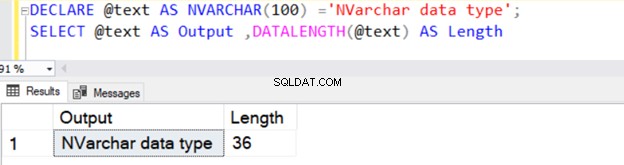
DECLARE @text AS NVARCHAR(100) ='NVARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Връща дължината на низа от 36, тъй като NVARCHAR отнема 2 байта на символ за съхранение.
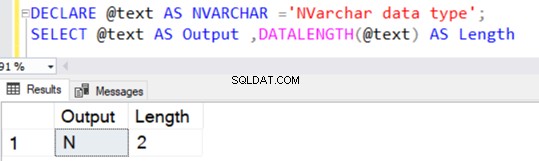
Подобно на типа данни VARCHAR, NVARCHAR също има стойност по подразбиране от 1 знак (2 байта), без да посочва изрична стойност за N.
Ако приложим NVARCHAR преобразуването с помощта на функцията CAST или CONVERT без изрична стойност на N, стойността по подразбиране е 30 знака, т.е. 60 байта.
Съхранение на Unicode и не-Unicode стойности във VARCHAR тип данни
Да предположим, че имаме таблица, която записва отзиви на клиенти от портал за електронно пазаруване. За тази цел имаме SQL таблица със следната заявка.
CREATE TABLE UserComments
(
ID int IDENTITY (1,1),
[Language] VARCHAR(50),
[comment] VARCHAR(200),
[NewComment] NVARCHAR(200)
)
Вмъкваме няколко примерни записа в тази таблица на английски, японски и хинди. Типът данни за [Коментар] е VARCHAR и [Нов коментар] е NVARCHAR() .
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('English','Hello World', N'Hello World')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Japanese','こんにちは世界', N'こんにちは世界')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Hindi','नमस्ते दुनिया', N'नमस्ते दुनिया')
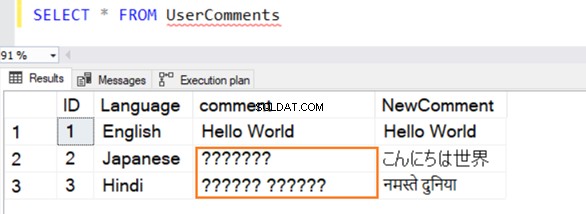
Заявката се изпълнява успешно и дава следните редове, докато избира стойност от нея. За ред 2 и 3 той не разпознава данни, ако не са на английски.
Типове данни VARCHAR и NVARCHAR:Сравнение на производителността
Не трябва да смесваме използването на типове данни VARCHAR и NVARCHAR в предикатите JOIN или WHERE. Той обезсилва съществуващите индекси, тъй като SQL Server изисква едни и същи типове данни от двете страни на JOIN. SQL Server се опитва да извърши неявното преобразуване с помощта на функцията CONVERT_IMPLICIT() в случай на несъответствие.
SQL Server използва приоритета на типа данни, за да определи кой е целевият тип данни. NVARCHAR има по-висок приоритет от типа данни VARCHAR. Следователно, по време на преобразуването на типа данни, SQL Server преобразува съществуващите стойности VARCHAR в NVARCHAR.
CREATE TABLE #PerformanceTest
(
[ID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Col1] VARCHAR(50) NOT NULL,
[Col2] NVARCHAR(50) NOT NULL
)
CREATE INDEX [ix_performancetest_col] ON #PerformanceTest (col1)
CREATE INDEX [ix_performancetest_col2] ON #PerformanceTest (col2)
INSERT INTO #PerformanceTest VALUES ('A',N'C')
Сега нека изпълним два оператора SELECT, които извличат записи според техните типове данни.
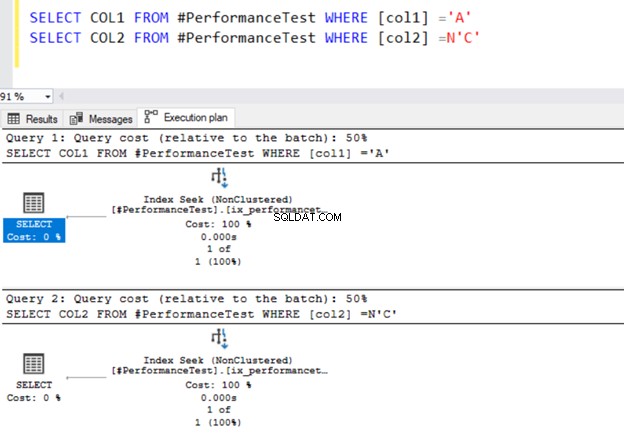
SELECT COL1 FROM #PerformanceTest WHERE [col1] ='A'
SELECT COL2 FROM #PerformanceTest WHERE [col2] =N'C'
И двете заявки използват оператора за търсене на индекс и индексите, които дефинирахме по-рано.
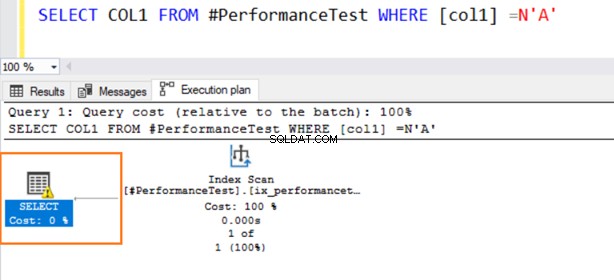
Сега превключваме стойностите на типа данни за сравнение към предиката WHERE. Колона 1 има тип данни VARCHAR, но ние указваме N’A’, за да го поставим като тип данни NVARCHAR.
По същия начин, col2 е типът данни NVARCHAR и ние посочваме стойността „C“, която се отнася до типа данни VARCHAR.
SELECT COL2 FROM #PerformanceTest WHERE [col2] ='C'В плана за действително изпълнение на заявката получавате индексно сканиране, а изразът SELECT има предупредителен символ.
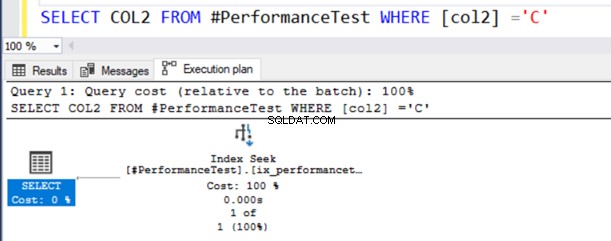
Тази заявка работи добре, защото типът данни NVARCHAR() може да има както Unicode, така и стойности, различни от Unicode.
Сега втората заявка използва индексно сканиране и издава предупредителен символ на оператора SELECT.
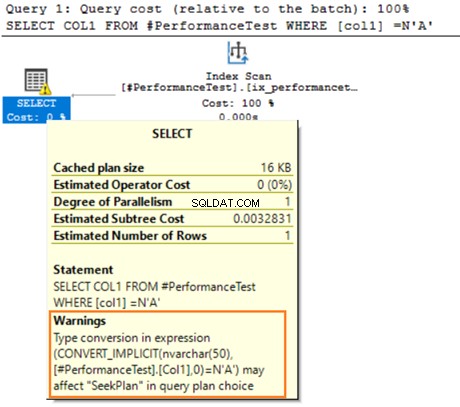
Задръжте курсора на мишката върху оператора SELECT, който издава предупреждение за имплицитното преобразуване. SQL Server не можа да използва правилно съществуващия индекс. Това се дължи на различните алгоритми за сортиране на данни както за VARCHAR, така и за NVARCHAR типове данни.
Ако таблицата има милиони редове, SQL Server трябва да извърши допълнителна работа и да преобразува данни, използвайки имплицитно преобразуване на данни. Това може да повлияе негативно на ефективността на заявката ви. Следователно, трябва да избягвате смесването и съпоставянето на тези типове данни при оптимизирането на заявките.
Заключение
Трябва да прегледате изискванията си за данни, докато проектирате по подходящ начин таблици на база данни и техните колони. Обикновено сървърите от тип данни VARCHAR обслужват повечето от вашите изисквания за данни. Въпреки това, ако трябва да съхранявате както Unicode, така и не-Unicode типове данни в колона, можете да помислите за използването на NVARCHAR. Въпреки това, трябва да прегледате неговото въздействие върху производителността, размера на съхранение, преди да вземете окончателното решение.