Този блог е кратка презентация за Дженкинс и ви показва как да използвате този инструмент, за да ви помогне с някои от ежедневните ви задачи за администриране и управление на PostgreSQL.
Относно Дженкинс
Jenkins е софтуер с отворен код за автоматизация. Той е разработен на java и е един от най-популярните инструменти за непрекъсната интеграция (CI) и непрекъсната доставка (CD).
През 2010 г., след придобиването на Sun Microsystems от Oracle, софтуерът "Hudson" беше в спор със своята общност с отворен код. Този спор стана основата за стартирането на проекта Дженкинс.
В днешно време „Hudson“ (публичен лиценз на Eclipse) и „Jenkins“ (лиценз на MIT) са два активни и независими проекта с много сходна цел.
Jenkins има хиляди плъгини, които можете да използвате, за да ускорите фазата на разработка чрез автоматизация за целия жизнен цикъл на разработка; изграждане, документиране, тестване, пакетиране, етап и внедряване.
Какво прави Дженкинс?
Въпреки че основната употреба на Jenkins може да бъде непрекъсната интеграция (CI) и непрекъсната доставка (CD), този отворен код има набор от функционалности и може да се използва без никакъв ангажимент или зависимост от CI или CD, така че Jenkins представя някои интересни функционалности за изследвайте:
- Задачи за период на планиране (вместо да използвате традиционния crontab )
- Наблюдение на задания, техните регистрационни файлове и дейности чрез чист изглед (тъй като имат опция за групиране)
- Поддръжката на работните места може да се извършва лесно; ако приемем, че Дженкинс има набор от опции за това
- Настройте и насрочете инсталиране на софтуер (чрез използване на Puppet) в същия хост или в друг.
- Публикуване на отчети и изпращане на известия по имейл
Изпълнение на PostgreSQL задачи в Jenkins
Има три често срещани задачи, които разработчикът на PostgreSQL или администраторът на база данни трябва да изпълнява ежедневно:
- Планиране и изпълнение на PostgreSQL скриптове
- Изпълнение на PostgreSQL процес, съставен от три или повече скрипта
- Непрекъсната интеграция (CI) за PL/pgSQL разработки
За изпълнението на тези примери се приема, че сървърите на Jenkins и PostgreSQL (поне версия 9.5) са инсталирани и работят правилно.
Планиране и изпълнение на PostgreSQL скрипт
В повечето случаи внедряването на ежедневни (или периодични) PostgreSQL скриптове за изпълнение на обичайна задача като...
- Генериране на резервни копия
- Тествайте възстановяването на резервно копие
- Изпълнение на заявка за целите на отчитането
- Почистване и архивиране на регистрационни файлове
- Извикване на PL/pgSQL процедура за изчистване на таблици
t е дефиниран в crontab :
0 5,17 * * * /filesystem/scripts/archive_logs.sh
0 2 * * * /db/scripts/db_backup.sh
0 6 * * * /db/data/scripts/backup_client_tables.sh
0 4 * * * /db/scripts/Test_db_restore.sh
*/10 * * * * /db/scripts/monitor.sh
0 4 * * * /db/data/scripts/queries.sh
0 4 * * * /db/scripts/data_extraction.sh
0 5 * * * /db/scripts/data_import.sh
0 */4 * * * /db/data/scripts/report.shКато crontab не е най-добрият удобен за потребителя инструмент за управление на този вид планиране, може да се направи на Jenkins със следните предимства...
- Много удобен интерфейс за наблюдение на техния напредък и текущо състояние
- Регистратурите са достъпни незабавно и няма нужда от специално разрешение за достъп до тях
- Заданието може да бъде изпълнено ръчно на Jenkins, вместо да има график
- За някакъв вид задачи няма нужда да дефинирате потребители и пароли в обикновени текстови файлове, тъй като Дженкинс го прави по сигурен начин
- Заданията могат да бъдат дефинирани като изпълнение на API
Така че може да е добро решение да мигрирате работните места, свързани със задачите на PostgreSQL, към Дженкинс вместо crontab.
От друга страна, повечето администратори и разработчици на бази данни имат силни умения в скриптовите езици и за тях би било лесно да разработят малки интерфейси, за да се справят с тези скриптове, за да внедрят автоматизираните процеси с цел подобряване на задачите си. Но не забравяйте, че Дженкинс най-вероятно вече има набор от функции, за да го направи и тези функции могат да улеснят живота на разработчиците, които решат да ги използват.
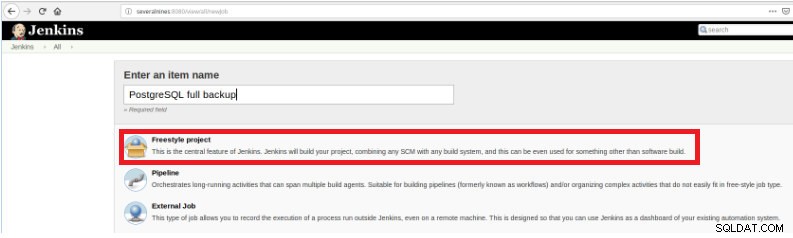
По този начин, за да дефинирате изпълнението на скрипта, е необходимо да създадете нова работа, като изберете опцията „Нов елемент“.
 Фигура 1 – „Нов елемент“, за да се дефинира задача за изпълнение на PostgreSQL скрипт
Фигура 1 – „Нов елемент“, за да се дефинира задача за изпълнение на PostgreSQL скрипт След това, след като го наименувате, изберете типа „Проекти FreeStyle“ и щракнете върху OK.
 Фигура 2 – Избор на типа задание (артикул)
Фигура 2 – Избор на типа задание (артикул) За да завършите създаването на това ново задание, в секцията “Build” трябва да изберете опцията “Execute script” и в полето на командния ред пътя и параметризацията на скрипта, който ще бъде изпълнен:
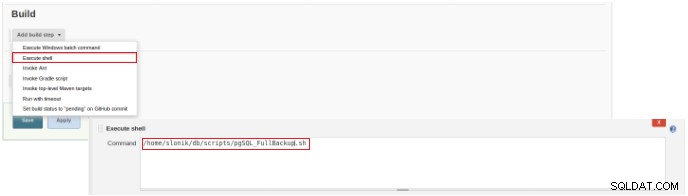 Фигура 3 – Спецификация на командата за изпълнение
Фигура 3 – Спецификация на командата за изпълнение За този вид работа е препоръчително да проверите разрешенията на скрипта, защото поне изпълнението за групата, към която принадлежи файлът, и за всички трябва да бъде зададено.
В този пример скриптът query.sh има разрешения за четене и изпълнение за всички, разрешения за четене и изпълнение за групата и четене за запис и изпълнение за потребителя:
example@sqldat.com:~/db/scripts$ ls -l query.sh
-rwxr-xr-x 1 slonik slonik 365 May 11 20:01 query.sh
example@sqldat.com:~/db/scripts$ Този скрипт има много прост набор от изрази, основно извиква само помощната програма psql, за да изпълни заявки:
#!/bin/bash
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl" > /home/slonik/db/scripts/appl.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_users" > /home/slonik/db/scripts/appl_user.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_rights" > /home/slonik/db/scripts/appl_rights.datИзпълнение на процес на PostgreSQL, съставен от три или повече скрипта
В този пример ще опиша какво е необходимо, за да изпълните три различни скрипта, за да скриете чувствителни данни и за това ще следваме стъпките по-долу...
- Импортирайте данни от файлове
- Подгответе данни за маскиране
- Архивиране на база данни с маскирани данни
Така че, за да дефинирате тази нова работа, е необходимо да изберете опцията „Нов елемент“ в главната страница на Jenkins и след това, след като зададете име, трябва да изберете опцията „Pipeline“:
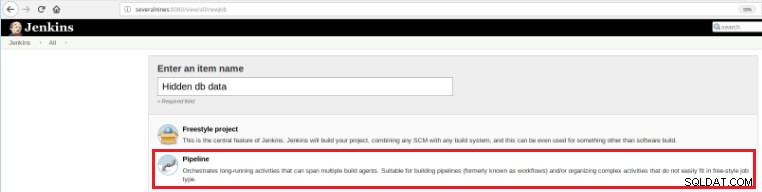 Фигура 5 – Елемент на тръбопровода в Jenkins
Фигура 5 – Елемент на тръбопровода в Jenkins След като заданието бъде запазено в секцията „Pipeline“, в раздела „Разширени опции на проекта“, полето „Definition“ трябва да бъде зададено на „Pipeline script“, както е показано по-долу:
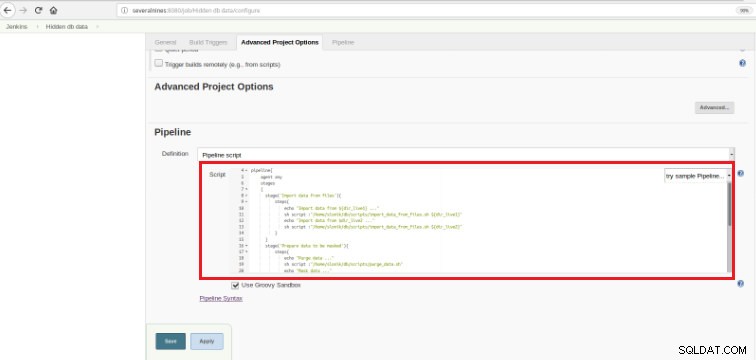 Фигура 6 - Groovy скрипт в секцията на конвейера
Фигура 6 - Groovy скрипт в секцията на конвейера Както споменах в началото на главата, използваният Groovy скрипт е съставен от три етапа, това означава три отделни части (етапи), както е представено в следния скрипт:
def dir_live1='/data/ftp/server1'
def dir_live2='/data/ftp/server2'
pipeline{
agent any
stages
{
stage('Import data from files'){
steps{
echo "Import data from ${dir_live1} ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live1}"
echo "Import data from $dir_live2 ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live2}"
}
}
stage('Prepare data to be masked'){
steps{
echo "Purge data ..."
sh script :"/home/slonik/db/scripts/purge_data.sh"
echo "Mask data ..."
sh script :"/home/slonik/db/scripts/mask_data.sh"
}
}
stage('Backup of database with data masked'){
steps{
echo "Backup database after masking ..."
sh script :"/home/slonik/db/scripts/backup_db.sh"
}
}
}
}Groovy е съвместим със синтаксис Java обектно ориентиран език за програмиране за платформата Java. Това е едновременно статичен и динамичен език с функции, подобни на тези на Python, Ruby, Perl и Smalltalk.
Лесно е за разбиране, тъй като този вид скрипт се основава на няколко изявления...
Етап
Означава 3-те процеса, които ще бъдат изпълнени:„Импортиране на данни от файлове“, „Подготовка на данни за маскиране“
и „Архивиране на база данни с маскирани данни“.
Стъпка
„Стъпка“ (често наричана „стъпка на изграждане“) е отделна задача, която е част от последователност. Всеки етап може да се състои от няколко стъпки. В този пример първият етап има две стъпки.
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server1'
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server2'Данните се импортират от два различни източника.
В предишния пример е важно да се отбележи, че има две променливи, дефинирани в началото и с глобален обхват:
dir_live1
dir_live2Скриптовете, използвани в тези три стъпки, извикват psql , pg_restore и pg_dump комунални услуги.
След като задачата е дефинирана, е време да я изпълните и за това е необходимо само да кликнете върху опцията „Създаване сега“:
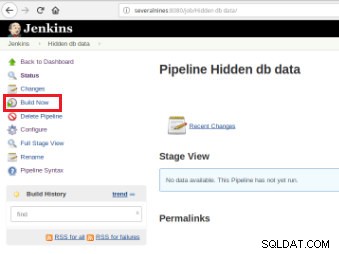 Фигура 7 – Задача за изпълнение
Фигура 7 – Задача за изпълнение След стартиране на изграждането е възможно да проверите напредъка му.
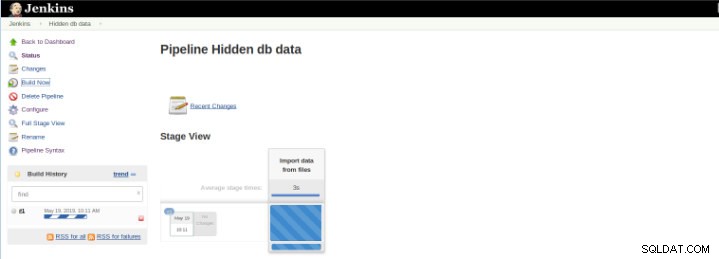 Фигура 8 – Стартиране на „Build“
Фигура 8 – Стартиране на „Build“ Плъгинът Pipeline Stage View включва разширена визуализация на историята на изграждане на Pipeline на индексната страница на проект на поток под Stage View. Този изглед се създава веднага щом задачите бъдат завършени и всяка задача е представена от колона отляво надясно и е възможно да видите и сравните изминалото време за изпълненията на сервала (известно като Build в Jenkins).
След като изпълнението (наричано още Build) приключи, е възможно да получите допълнителни подробности, като щракнете върху завършената нишка (червено поле).
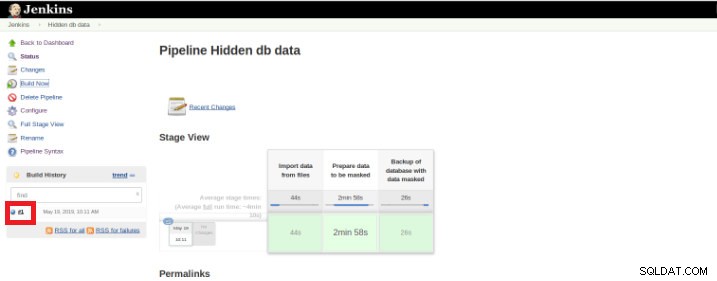 Фигура 9 – Стартиране на „Build“
Фигура 9 – Стартиране на „Build“ и след това в опцията „Изход на конзолата“.
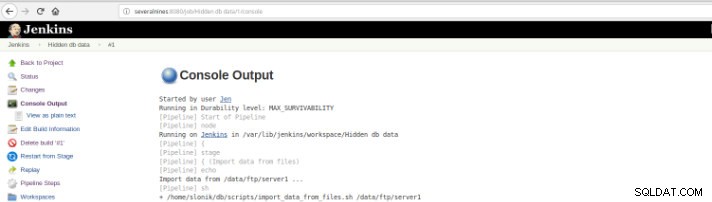 Фигура 10 – Изход на конзолата
Фигура 10 – Изход на конзолата Предишните изгледи са изключително полезни, тъй като позволяват да имаме представа за времето на изпълнение, необходимо за всеки етап.
Pipelines, известен също като работен поток, това е плъгин, който позволява дефинирането на жизнения цикъл на приложението и е функционалност, използвана в Jenkins за непрекъсната доставка (CD).v Този плъгин е създаден с изисквания за гъвкава, разширяема и базирана на скрипт способност за CD работен поток предвид.
Този пример е за скриване на чувствителни данни, но със сигурност има много други примери на ежедневна база за PostgreSQL администратор на база данни, които могат да бъдат изпълнени на конвейерна задача.
Pipeline е наличен на Jenkins от версия 2.0 и това е невероятно решение!

Непрекъсната интеграция (CI) за PL/pgSQL разработки
Непрекъснатата интеграция за разработване на база данни не е толкова лесна, колкото в други езици за програмиране, поради данните, които могат да бъдат загубени, така че не е лесно да поддържате базата данни в контрол на източника и да я разгръщате на специален сървър, особено след като има скриптове които съдържат DDL (език за дефиниране на данни) и DML (език за манипулиране на данни) изрази. Това е така, защото тези видове изрази променят текущото състояние на базата данни и за разлика от други езици за програмиране няма изходен код за компилиране.
От друга страна, има набор от изрази за база данни, за които е възможна непрекъсната интеграция, както за други езици за програмиране.
Този пример се основава само на разработването на процедури и ще илюстрира задействането на набор от тестове (написани на Python) от Дженкинс, след като PostgreSQL скриптове, на които се съхранява кодът на следните функции, са заети в хранилище на кодове.
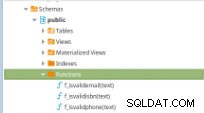 Фигура 11 – PLpg/SQL функции
Фигура 11 – PLpg/SQL функции Тези функции са прости и съдържанието им има само няколко логики или заявка в PLpg/SQL или plperlu език като функцията f_IsValidEmail :
CREATE OR REPLACE FUNCTION f_IsValidEmail(email text) RETURNS bool
LANGUAGE plperlu
AS $$
use Email::Address;
my @addresses = Email::Address->parse($_[0]);
return scalar(@addresses) > 0 ? 1 : 0;
$$;Всички функции, представени тук, не зависят една от друга и тогава няма предимство нито в неговото развитие, нито в неговото разгръщане. Освен това, тъй като ще бъде проверено предварително, няма зависимост от техните валидации.
Така че, за да се изпълни набор от скриптове за валидиране, след като комитът се извърши в хранилище на код, е необходимо създаването на задача за изграждане (нов елемент) в Jenkins:
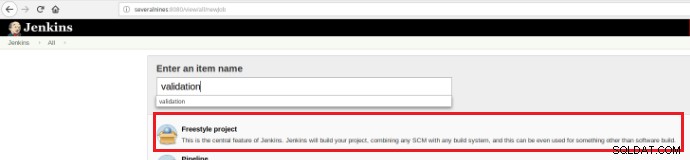 Фигура 12 – Проект "Freestyle" за непрекъсната интеграция
Фигура 12 – Проект "Freestyle" за непрекъсната интеграция Това ново задание за изграждане трябва да бъде създадено като проект „Freestyle“ и в секцията „Хранилище на изходен код“ трябва да бъде дефиниран URL адресът на хранилището и неговите идентификационни данни (оранжево поле):
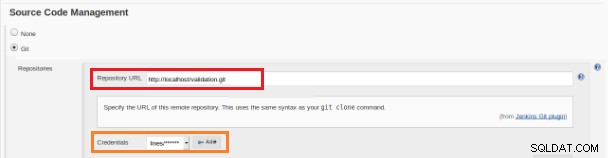 Фигура 13 – Хранилище на изходен код
Фигура 13 – Хранилище на изходен код В секцията „Build Triggers“ трябва да бъде отметната опцията „GitHub hook trigger за GITScm polling“:
 Фигура 14 – Раздел „Създаване на тригери“
Фигура 14 – Раздел „Създаване на тригери“ Накрая, в секцията „Build“ трябва да бъде избрана опцията „Execute Shell“ и в командното поле скриптовете, които ще направят валидирането на разработените функции:
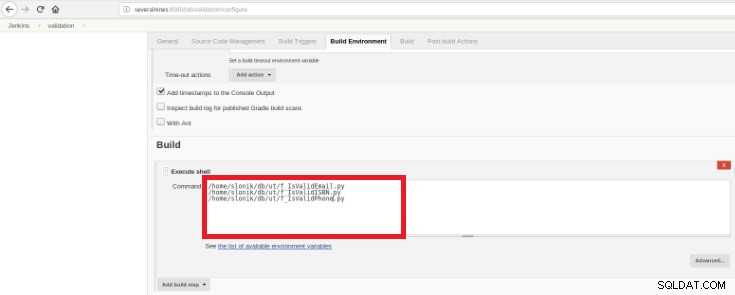 Фигура 15 – Раздел „Среда за изграждане“
Фигура 15 – Раздел „Среда за изграждане“ Целта е да има един скрипт за валидиране за всяка разработена функция.
Този скрипт на Python има прост набор от изрази, които ще извикат тези процедури от база данни с някои предварително дефинирани очаквани резултати:
#!/usr/bin/python
import psycopg2
con = psycopg2.connect(database="db_deploy", user="postgres", password="postgres10", host="localhost", port="5432")
cur = con.cursor()
email_list = { 'example@sqldat.com' : True,
'tintinmail.com' : False,
'example@sqldat.com' : False,
'director#mail.com': False,
'example@sqldat.com' : True
}
result_msg= "f_IsValidEmail -> OK"
for key in email_list:
cur.callproc('f_IsValidEmail', (key,))
row = cur.fetchone()
if email_list[key]!=row[0]:
result_msg= "f_IsValidEmail -> Nok"
print result_msg
cur.close()
con.close()Този скрипт ще тества представения PLpg/SQL или plperlu функции и ще се изпълнява след всеки комит в кодовото хранилище, за да се избегнат регресии на разработките.
След като тази компилация на заданието бъде изпълнена, изпълнението на регистрационния файл може да бъде проверено.
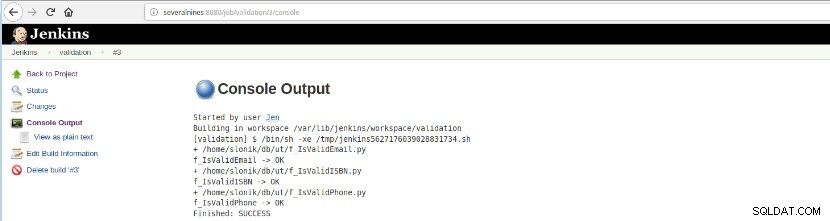 Фигура 16 – „Изход на конзолата“
Фигура 16 – „Изход на конзолата“ Тази опция представя крайното състояние:УСПЕХ или НЕУСПЕХА, работното пространство, изпълнените файлове/скриптове, създадените временни файлове и съобщенията за грешки (за неуспешните)!
Заключение
В обобщение, Дженкинс е известен като страхотен инструмент за непрекъсната интеграция (CI) и непрекъсната доставка (CD), но може да се използва за различни функции като,
- Задачи за планиране
- Изпълнение на скриптове
- Процеси за наблюдение
За всички тези цели при всяко изпълнение (надграждане на речника на Дженкинс) могат да се анализират регистрационните файлове и изминалото време.
Поради големия брой налични плъгини може да избегне някои разработки с конкретна цел, вероятно има плъгин, който прави точно това, което търсите, просто е въпрос на търсене в центъра за актуализиране или Управление на Jenkins>>Управление на плъгини вътре уеб приложението.