Групирането е важна функция, която помага за организиране и подреждане на данните. Има много начини да го направите и един от най-ефективните методи е клаузата SQL GROUP BY.
Можете да използвате SQL GROUP BY, за да разделите редовете в резултатите на групи с обобщаваща функция . Звучи лесно да сумирате, осредните или преброите записи с него.
Но правиш ли го правилно?
„Дясно“ може да бъде субективно. Когато работи без критични грешки с правилен изход, се счита за добре. Трябва обаче също да е бързо.
В тази статия скоростта също ще бъде взета предвид. Ще видите много анализ на заявки, използвайки логически четения и планове за изпълнение във всички точки.
Да започнем.
1. Филтрирайте рано
Ако сте объркани кога да използвате WHERE и HAVING, това е за вас. Защото в зависимост от условието, което предоставяте, и двете може да дадат един и същ резултат.
Но те са различни.
HAVING филтрира групите, използвайки колоните в клаузата на SQL GROUP BY. WHERE филтрира редовете преди групирането и агрегирането. Така че, ако филтрирате с помощта на клаузата HAVING, групирането се извършва за всички върнати редове.
И това е лошо.
Защо? Краткият отговор е:това е бавно. Нека докажем това с 2 заявки. Вижте кода по-долу. Преди да го стартирате в SQL Server Management Studio, натиснете първо Ctrl-M.
SET STATISTICS IO ON
GO
-- using WHERE
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
ORDER BY Product, OrderYear, OrderMonth;
-- using HAVING
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
HAVING YEAR(soh.OrderDate) = 2012
ORDER BY Product, OrderYear, OrderMonth;
SET STATISTICS IO OFF
GO
Анализ
2-те оператора SELECT по-горе ще върнат същите редове. И двете са правилни при връщането на поръчки на продукти по месеци през 2012 г. Но първият SELECT отне 136 мс. да работи на моя лаптоп, докато друг отне 764 мс.!
Защо?
Нека първо проверим логическите показания на фигура 1. STATISTICS IO върна тези резултати. След това го поставих в StatisticsParser.com за форматирания изход.
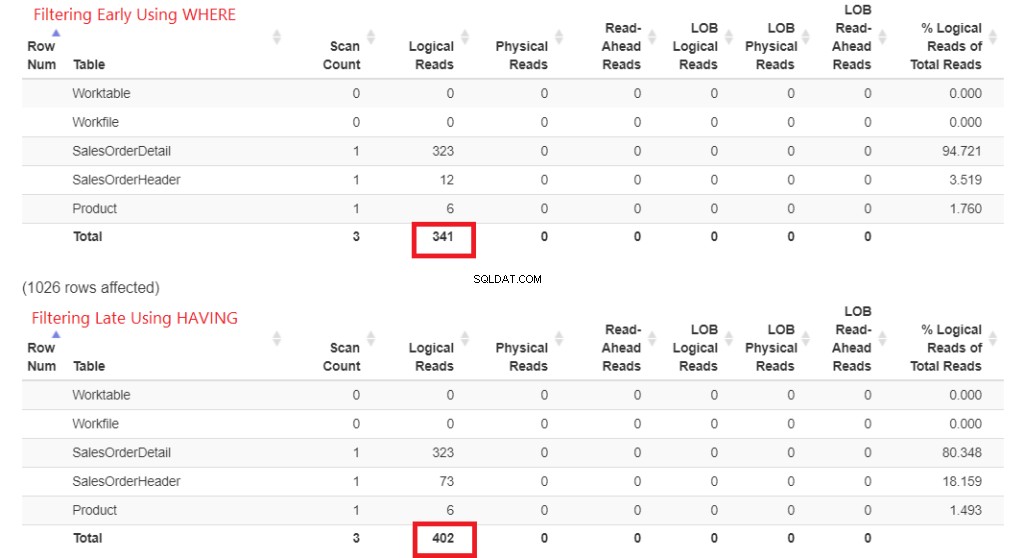
Фигура 1 . Логически четения на ранно филтриране с помощта на WHERE срещу късно филтриране чрез HAVING.
Вижте общия логически прочит на всеки. За да се разберат тези числа, колкото по-логични четения са необходими, толкова по-бавна ще бъде заявката. Така че това доказва, че използването на HAVING е по-бавно, а ранното филтриране с WHERE е по-бързо.
Разбира се, това не означава, че ИМАНЕТО е безполезно. Едно изключение е, когато използвате HAVING с агрегат като HAVING SUM(sod.Linetotal)> 100 000 . Можете да комбинирате клауза WHERE и клауза HAVING в една заявка.
Вижте плана за изпълнение на фигура 2.
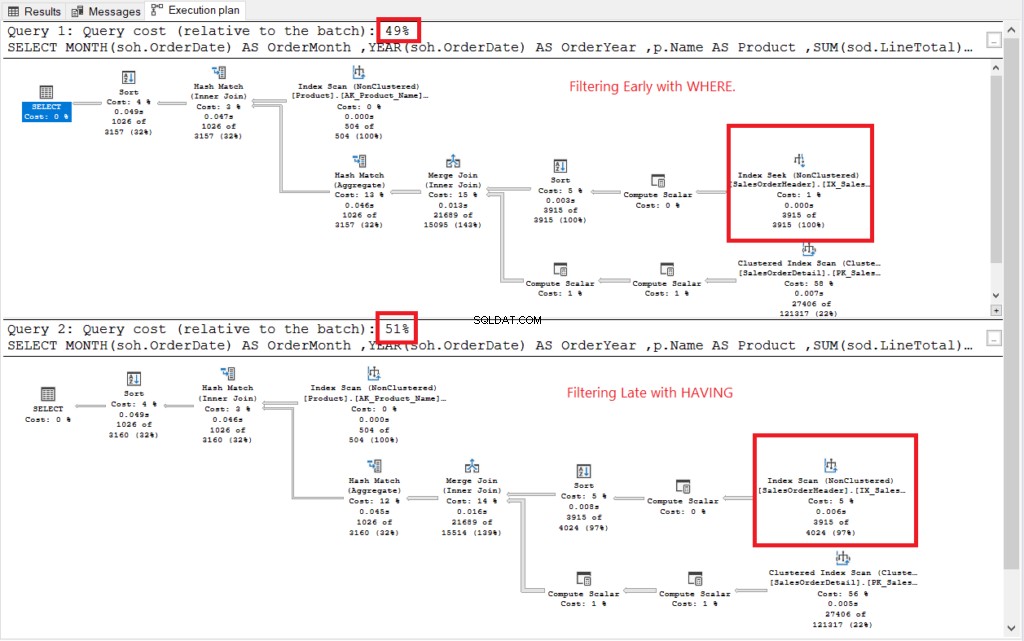
Фигура 2 . Планове за изпълнение на ранно филтриране срещу късно филтриране.
И двата плана за изпълнение изглеждаха сходни, с изключение на тези, поставени в червено. Ранното филтриране използва оператора Index Seek, докато друго използва Index Scan. Търсенето е по-бързо от сканирането в големи таблици.
Не те: Ранното филтриране има по-малко разходи от късното филтриране. Така че най-важното филтриране на редовете по-рано може да подобри производителността.
2. Първо група, присъединяване по-късно
Присъединяването към някои от таблиците, от които се нуждаете по-късно, също може да подобри производителността.
Да приемем, че искате да имате месечни продажби на продукти. Също така трябва да получите името на продукта, номера и подкатегорията в една и съща заявка. Тези колони са в друга таблица. И всички те трябва да бъдат добавени в клаузата GROUP BY, за да имат успешно изпълнение. Ето кода.
SET STATISTICS IO ON
GO
SELECT
p.Name AS Product
,p.ProductNumber
,ps.Name AS ProductSubcategory
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.name, p.ProductNumber, ps.Name
ORDER BY Product
SET STATISTICS IO OFF
GO
Това ще работи добре. Но има по-добър и по-бърз начин. Това няма да изисква от вас да добавяте 3-те колони за име на продукт, номер и подкатегория в клаузата GROUP BY. Това обаче ще изисква малко повече натискания на клавиши. Ето го.
SET STATISTICS IO ON
GO
;WITH Orders2012 AS
(
SELECT
sod.ProductID
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY sod.ProductID
)
SELECT
P.Name AS Product
,P.ProductNumber
,ps.Name AS ProductSubcategory
,o.ProductSales
FROM Orders2012 o
INNER JOIN Production.Product p ON o.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
ORDER BY Product;
SET STATISTICS IO OFF
GO
Анализ
Защо това е по-бързо? Обединяванията към Продукт и Подкатегория на продукта се правят по-късно. И двете не са включени в клаузата GROUP BY. Нека докажем това с числа в STATISTICS IO. Вижте Фигура 4.
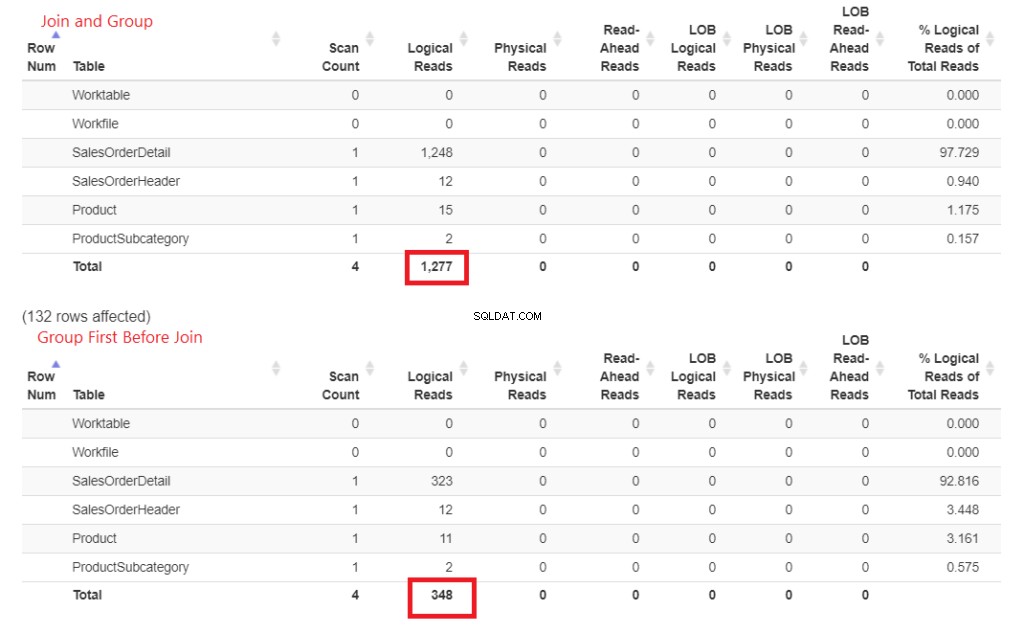
Фигура 3 . Присъединяването по-рано след групирането изисква повече логично четене, отколкото по-късното присъединяване.
Виждате ли тези логични показания? Разликата е далеч, а победителят е очевиден.
Нека сравним плана за изпълнение на 2-те заявки, за да видим причината зад числата по-горе. Първо, вижте Фигура 4 за плана за изпълнение на заявката с всички таблици, обединени, когато са групирани.
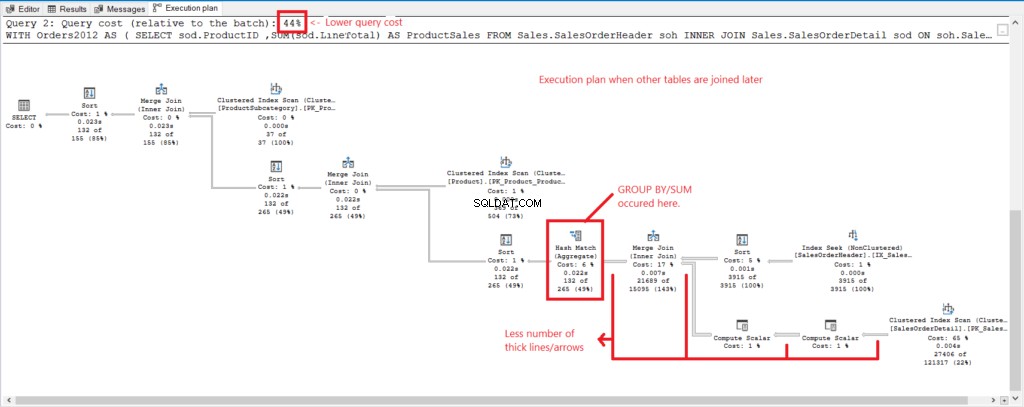
Фигура 4 . План за изпълнение, когато всички таблици са обединени.
И имаме следните наблюдения:
- GROUP BY и SUM бяха направени късно в процеса след присъединяване на всички таблици.
- Много по-дебели линии и стрелки – това обяснява 1277-те логически показания.
- Комбинираните 2 заявки формират 100% от цената на заявката. Но планът на тази заявка има по-висока цена на заявката (56%).
Сега, ето план за изпълнение, когато първо се групираме и се присъединим към Продукта и Подкатегория на продукта маси по-късно. Вижте фигура 5.
Фигура 5 . Планът за изпълнение, когато първо групата, присъединяване по-късно, е готово.
И имаме следните наблюдения на фигура 5.
- GROUP BY и SUM приключиха по-рано.
- По-малък брой дебели линии и стрелки – това обяснява само 348-те логически четения.
- По-ниска цена на заявката (44%).
3. Групиране на индексирана колона
Всеки път, когато SQL GROUP BY се извършва върху колона, тази колона трябва да има индекс. Ще увеличите скоростта на изпълнение, след като групирате колоната с индекс. Нека променим предишната заявка и да използваме датата на доставка вместо датата на поръчката. Колоната за дата на доставка няма индекс в SalesOrderHeader .
SET STATISTICS IO ON
GO
SELECT
MONTH(soh.ShipDate) AS ShipMonth
,YEAR(soh.ShipDate) AS ShipYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.ShipDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.ShipDate), MONTH(soh.ShipDate)
ORDER BY Product, ShipYear, ShipMonth;
SET STATISTICS IO OFF
GO
Натиснете Ctrl-M, след което изпълнете заявката по-горе в SSMS. След това създайте неклъстериран индекс на ShipDate колона. Обърнете внимание на логическите четения и плана за изпълнение. Накрая изпълнете отново заявката по-горе в друг раздел за заявка. Обърнете внимание на разликите в логическите четения и плановете за изпълнение.
Ето сравнението на логическите показания на фигура 6.
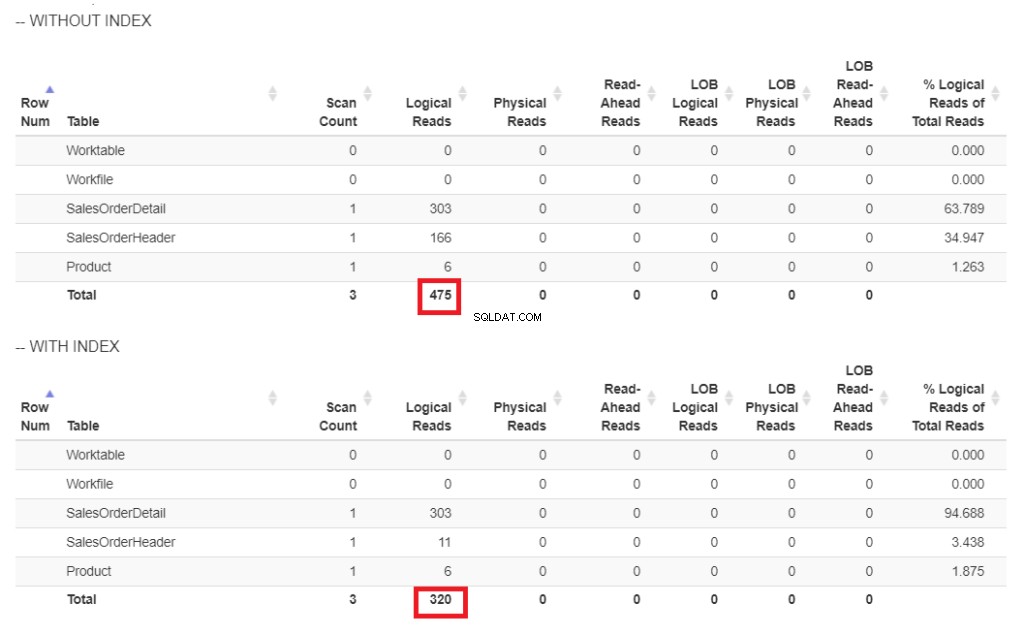
Фигура 6 . Логически четения на нашия пример за заявка със и без индекс на ShipDate.
На фигура 6 има по-високи логически четения на заявката без индекс на ShipDate .
Сега нека имаме плана за изпълнение, когато няма индекс на ShipDate съществува на фигура 7.
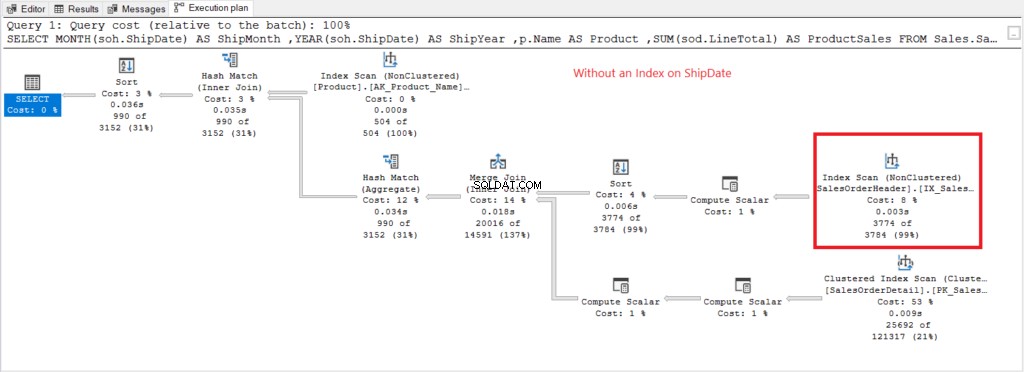
Фигура 7 . План за изпълнение при използване на GROUP BY на ShipDate неиндексиран.
Индексното сканиране Операторът, използван в плана на Фигура 7, обяснява по-високите логически показания (475). Ето план за изпълнение след индексиране на ShipDate колона.
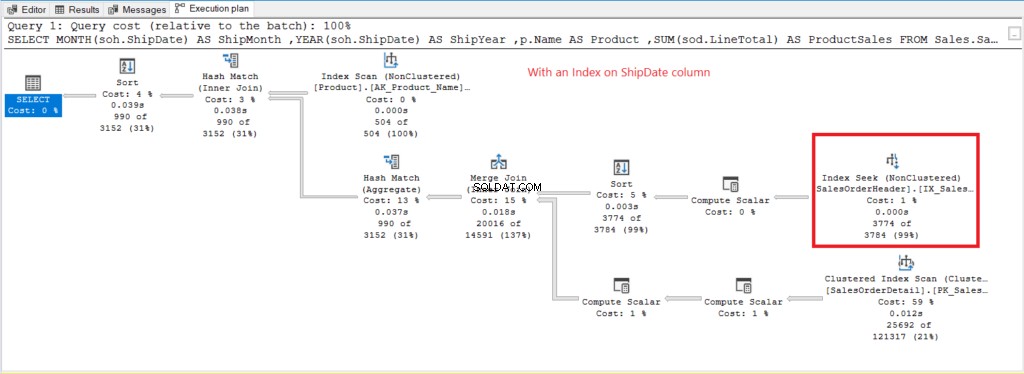
Фигура 8 . План за изпълнение при използване на GROUP BY на индексиран ShipDate.
Вместо индексно сканиране се използва търсене на индекс след индексиране на ShipDate колона. Това обяснява долните логически показания на фигура 6.
Така че, за да подобрите производителността, когато използвате GROUP BY, помислете за индексиране на колоните, които сте използвали за групиране.
Изводи при използването на SQL GROUP BY
SQL GROUP BY е лесен за използване. Но трябва да направите следващата стъпка, за да надхвърлите обобщаването на данните за отчети. Ето отново точките:
- Филтрирайте рано . Премахнете редовете, които не е необходимо да обобщавате, като използвате клаузата WHERE вместо клаузата HAVING.
- Първо групирайте, присъединете се по-късно . Понякога ще има колони, които трябва да добавите освен колоните, които групирате. Вместо да ги включвате в клаузата GROUP BY, разделете заявката с CTE и присъединете други таблици по-късно.
- Използвайте GROUP BY с индексирани колони . Това основно нещо може да е полезно, когато базата данни е бърза като охлюв.
Надяваме се това да ви помогне да повишите нивото на играта си в групирането на резултатите.
Ако ви харесва тази публикация, моля, споделете я в любимите си социални медийни платформи.