Тук сме. Почти две десетилетия в 21-ви век и необходимостта от повече изчислителна мощност все още е проблем. Технологичните компании удрят тротоара, за да се справят директно с този огромен проблем. Хардуерните инженери са намерили решение, като променят начина, по който проектират и произвеждат централния процесор (CPU) на компютъра. Сега те съдържат множество ядра, което позволява да се осъществи паралелност. От своя страна разработчиците на софтуер са коригирали начина, по който пишат програми, за да се адаптират към тази промяна в хардуера.
Общността на PostgreSQL се възползва напълно от тези многоядрени процесори, за да подобри производителността на заявките. Просто като актуализирате до версии 9.6 или по-високи, можете да използвате функция, наречена паралелизъм на заявки, за да изпълнявате различни операции. Той разделя задачите на по-малки части и разпределя всяка задача между множество процесорни ядра. Всяко ядро може да обработва задачите едновременно. Поради хардуерни ограничения, това е единственият начин да подобрим производителността на компютъра, докато се движим в бъдещето.
Преди да използвате функцията за паралелизъм в базата данни PostgreSQL, важно е да разпознаете как прави заявка паралелна. Ще можете да отстраните грешки и да разрешите всички възникнали проблеми.
Как работи паралелизъм на заявки?
За да разберете по-добре как се изпълнява паралелизмът, е добра идея да започнете на ниво клиент. За достъп до PostgreSQL клиентът трябва да изпрати заявка за връзка към сървъра на базата данни, наречен пощенски администратор. Пощенският администратор ще завърши удостоверяването и след това ще създаде нов сървърен процес за всяка връзка. Той също така е отговорен за създаването на област на споделена памет, която съдържа буферен пул. Буферният пул контролира трансфера на данни между споделената памет и паметта. Следователно, в момента, в който се установи връзка, буферният пул ще прехвърли данни и ще позволи да се осъществи паралелизъм на заявки.
Не е необходимо всички заявки да са паралелни. Има случаи, когато е необходимо само малко количество данни и те могат да бъдат бързо обработени само от едно ядро. Тази функция се използва само когато една заявка ще отнеме значително време за завършване. Оптимизаторът на базата данни определя дали трябва да се изпълнява паралелизъм. Ако е необходимо, базата данни ще използва допълнителна част от паметта, наречена динамична споделена памет (DSM). Това позволява на водещия процес и на паралелните работни процеси да разделят заявката между множество ядра и да събират подходящи данни.
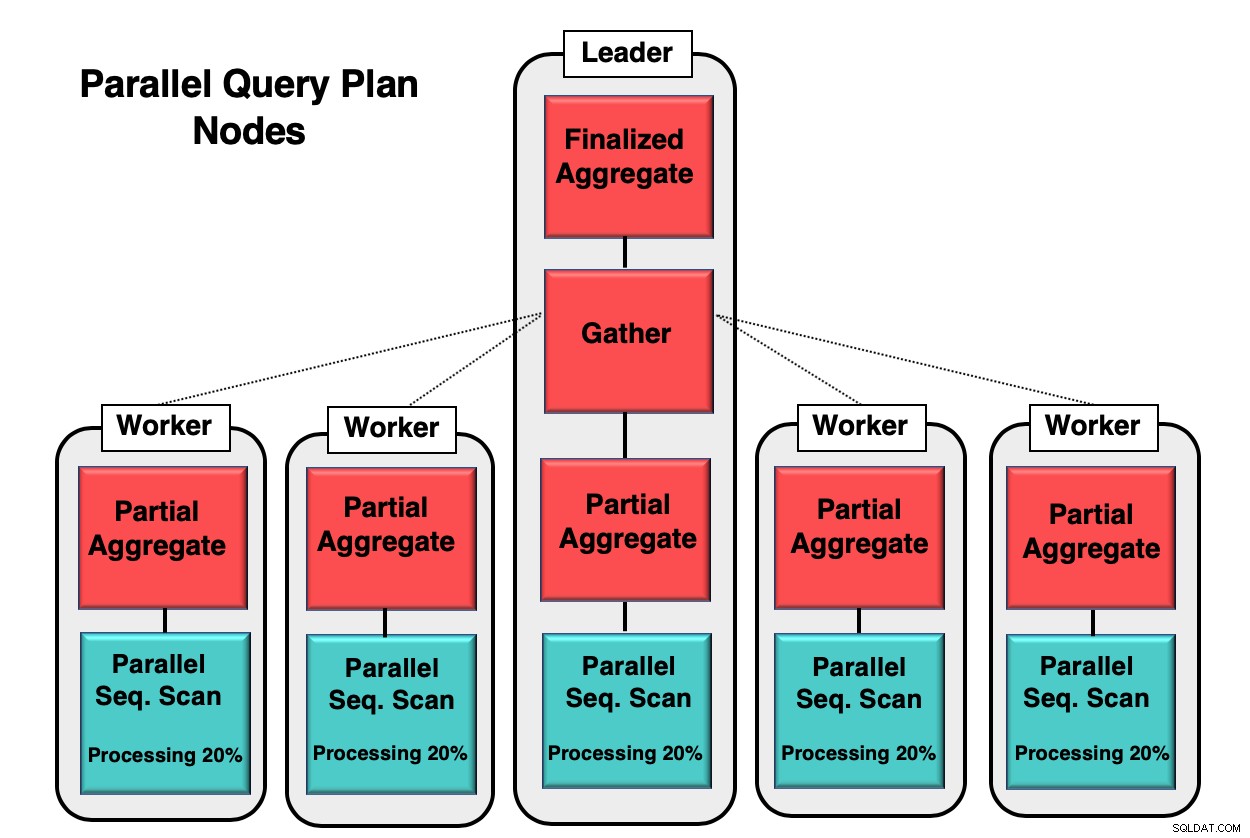
Фигура 1 ви дава пример за това как се извършва паралелизъм в базата данни. Водещият процес изпълнява първоначалната заявка, докато отделните работни процеси инициират копие на същия процес. Частичният агрегатен възел или ядрото на процесора е отговорен за прилагането на паралелното последователно сканиране на таблицата на базата данни.
В този случай всеки възел за последователно сканиране обработва 20% от данните в блокове от 8 kb. Същите тези възли могат да координират своята дейност, като използват техника, наречена паралелно осъзнаване. Всеки възел има пълно познаване на това какви данни вече са били обработени и какви данни трябва да бъдат сканирани в таблицата, за да завърши заявката. След като кортежите бъдат събрани изцяло, те се изпращат до възела за събиране, за да бъдат компилирани и финализирани.
Паралелни операции
Могат да се използват различни типове заявки за извличане на данни от база данни за създаване на набори от резултати. Ето конкретни операции, които ви дават възможност да използвате ефективно използването на множество ядра.
Последователно сканиране
Тази операция чете данни в таблица от началото до края за събиране на данни. Той разпределя равномерно натоварването между множество ядра, за да увеличи скоростта на обработка на заявките. Той е наясно с всяка основна дейност, което го прави по-лесно да се определи дали цялата заявка е завършена. След това възелът за събиране получава данните, извлечени въз основа на заявката.
Агрегация
Стандартна операция, която взема голямо количество данни и ги кондензира в по-малък брой редове. Това се случва по време на паралелната обработка само чрез извличане от таблица или индекси на съответната информация въз основа на заявката. Извършването на средна стойност на конкретни данни е отличен пример за агрегиране.
Присъединяване към хеш
Техника, която се използва за обединяване на данните между две таблици. Това е най-бързият алгоритъм за присъединяване, който обикновено се изпълнява с малка маса и голяма. Първо създавате хеш таблица и зареждате всички данни от една таблица в нея. След това можете да сканирате всички данни от хеша и втората таблица, като използвате паралелно последователно сканиране. Всеки кортеж, който е извлечен от сканирането, се сравнява с хеш таблицата, за да се види дали има съвпадение. Ако се установи съвпадение, данните се обединяват. С пускането на PostgreSQL 11 използването на паралелизъм за завършване на хеш присъединяване отнема около една трета от предишното време за обработка.
Сливане на присъединяване
Ако оптимизаторът определи, че хеш присъединяването ще надхвърли капацитета на паметта, вместо това ще извърши обединяване за сливане. Процесът включва сканиране през два сортирани списъка по едно и също време и съединяване на едни и същи елементи. Ако елементите не са равни, данните няма да бъдат обединени.
Присъединяване на вложен цикъл
Тази операция се използва, когато трябва да обедините две таблици, съдържащи различни езици за програмиране, като Quick Basic, Python и т.н. Всяка таблица се сканира и обработва чрез използване на множество ядра. Ако данните съвпадат, те се изпращат до възела за събиране, за да бъдат присъединени. Индексите също се сканират, поради което този процес съдържа множество цикли за извличане на данните. Средно ще отнеме само една трета от времето, за да завършите присъединяването чрез паралелния процес.
Сканиране на индекс на B-дърво
Тази операция сканира през дърво от сортирани данни, за да намери конкретна информация. Този процес отнема повече време от типичното последователно сканиране, защото има много чакане, докато се търсят записи. Въпреки това, работата по сканирането за подходящите данни е разделена между множество процесори.
Сканиране на растерна памет
Можете да обедините множество индекси с помощта на тази операция. Първо искате да създадете еквивалентен брой растерни изображения, тъй като имате индекси. Например, ако имате три индекса, първо трябва да създадете три растерни изображения. Всяка растерна карта ще извлича и компилира кортежи въз основа на заявката.
Изтеглете Бялата книга днес Управление и автоматизация на PostgreSQL с ClusterControl Научете какво трябва да знаете, за да внедрите, наблюдавате, управлявате и мащабирате PostgreSQLD Изтеглете Бялата книгаПаралелизъм на дялове
Има друга форма на паралелизъм, която може да се осъществи в базата данни на PostgreSQL. Това обаче не идва от сканиране на таблици и разбиване на задачите. Можете да разделите или разделите данните по конкретни стойности. Например, можете да вземете купувачите на стойност и да имате едно ядро да обработва данните само в рамките на тази стойност. По този начин вие знаете точно какво обработва всяко ядро в даден момент.
Разделяне на хеш
Тази операция се използва чрез разпределяне на редовете на таблицата в подтаблици. Отново, разделението обикновено се определя от отделна стойност или списък със стойности от таблица. Това е отличен метод за използване, ако нямате ефективна техника за управление на съхранение на всичките си устройства. Бихте искали да използвате разделяне, за да разпределите произволно данните, за да предотвратите I/O тесни места.
Присъединяване по дял
Техника, използвана за разбиване на таблици по дялове и свързването им чрез съпоставяне на подобни дялове. Например, може да имате голяма маса с купувачи от всички Съединени щати. Можете първо да разбиете таблицата по различни градове и след това да свържете някои градове заедно въз основа на региона във всеки щат. Съединяването на дялове опростява вашите данни и позволява манипулирането на таблици.
Паралелно небезопасно
PostgreSQL 11 автоматично изпълнява паралелизъм на заявката, ако оптимизаторът определи, че това е най-бързият начин за завършване на заявката. Колкото по-висока е версията на PostgreSQL, която използвате, толкова по-паралелни възможности ще има вашата база данни. За съжаление, не всички заявки трябва да се изпълняват паралелно, дори ако има възможност. Типът заявка, която изпълнявате, може да има специфични ограничения и ще изисква само едно ядро да завърши цялата обработка. Това ще забави производителността на вашата система, но ще гарантира, че получените данни са цели.
За да гарантират, че вашите заявки никога не са изложени на риск, разработчиците са създали функция, наречена parallel unsafe. Можете ръчно да замените оптимизатора на база данни и да поискате заявката никога да не бъде паралелна. Процесът на паралелизъм няма да се извърши.
Паралелизмът в базата данни PostgreSQL е функция, която става все по-добра с всяка версия на базата данни. Въпреки че бъдещето на технологиите е несигурно, изглежда, че използването на тази функция ще остане тук.
За повече информация можете да разгледате следното...
- https://www.postgresql.org/docs/10/parallel-query.html
- https://www.postgresql.org/docs/10/how-parallel-query-works.html
- https://www.bbc.com/news/business-42797846
- https://www.technologyreview.com/s/421186/why-cpus-arent-getting-any-faster/
- https://www.percona.com/blog/2019/02/21/parallel-queries-in-postgresql/
- https://malisper.me/postgres-merge-joins/
- https://www.enterprisedb.com/blog/partition-wise-joins-“divide-and-conquer-joins-between-partitioned-table