Доста често се срещат бази данни, разпределени в множество географски местоположения. Един сценарий за извършване на този тип настройка е за възстановяване след бедствие, където вашият център за данни в готовност се намира на място, различно от основния ви център за данни. Може също така да се изисква базите данни да са разположени по-близо до потребителите.
Основното предизвикателство за постигане на тази настройка е чрез проектиране на базата данни по начин, който намалява вероятността от проблеми, свързани с разделянето на мрежата. Едно от решенията може да бъде използването на Galera Cluster вместо редовно асинхронно (или полусинхронно) репликация. В този блог ще обсъдим плюсовете и минусите на този подход. Това е първата част от поредица от два блога. Във втората част ще проектираме георазпределения клъстер Galera и ще видим как ClusterControl може да ни помогне да разгърнем такава среда.
Защо Galera Cluster вместо асинхронна репликация за гео-разпределени клъстери?
Нека разгледаме основните разлики между Galera и обикновената репликация. Редовната репликация ви предоставя само един възел за запис, това означава, че всяко записване от отдалечен център за данни ще трябва да бъде изпратено през Wide Area Network (WAN), за да достигне до главния. Това също така означава, че всички прокси сървъри, разположени в отдалечения център за данни, ще трябва да могат да наблюдават цялата топология, обхващаща всички включени центрове за данни, тъй като те трябва да могат да разберат кой възел в момента е главен.
Това води до редица проблеми. Първо, трябва да се установят множество връзки през WAN, това добавя латентност и забавя всички проверки, които може да се изпълняват от проксито. В допълнение, това добавя ненужни разходи за прокси сървърите и базите данни. През повечето време се интересувате само от маршрутизиране на трафик към възлите на локалната база данни. Единственото изключение е главният и само поради това прокситата са принудени да наблюдават цялата инфраструктура, а не само частта, разположена в локалния център за данни. Разбира се, можете да опитате да преодолеете това, като използвате прокси сървъри за насочване само на SELECT, докато използвате някакъв друг метод (специализирано име на хост за главен, управляван от DNS), за да насочите приложението към master, но това добавя ненужни нива на сложност и движещи се части, които може сериозно да повлияе на способността ви да се справяте с множество възли и повреди в мрежата, без да губите последователност на данните.
Galera Cluster може да поддържа множество писатели. Закъснението също е фактор, тъй като всички възли в клъстера Galera трябва да координират и комуникират, за да сертифицират набори за запис, това дори може да бъде причината да решите да не използвате Galera, когато латентността е твърде висока. Това също е проблем в клъстерите за репликация - в клъстерите за репликация латентността засяга само записите от отдалечените центрове за данни, докато връзките от центъра за данни, където се намира главният, биха се възползвали от ангажиментите с ниска латентност.
В MySQL репликация също трябва да вземете предвид най-лошия сценарий и да се уверите, че приложението е наред със забавени записи. Главният винаги може да се промени и не можете да сте сигурни, че през цялото време ще пишете на локален възел.
Друга разлика между репликацията и Galera Cluster е обработката на забавянето на репликацията. Георазпределените клъстери могат да бъдат сериозно засегнати от забавяне:латентност, ограничена пропускателна способност на WAN връзката, всичко това ще повлияе на способността на репликирания клъстер да бъде в крак с репликацията. Моля, имайте предвид, че репликацията генерира един към целия трафик.
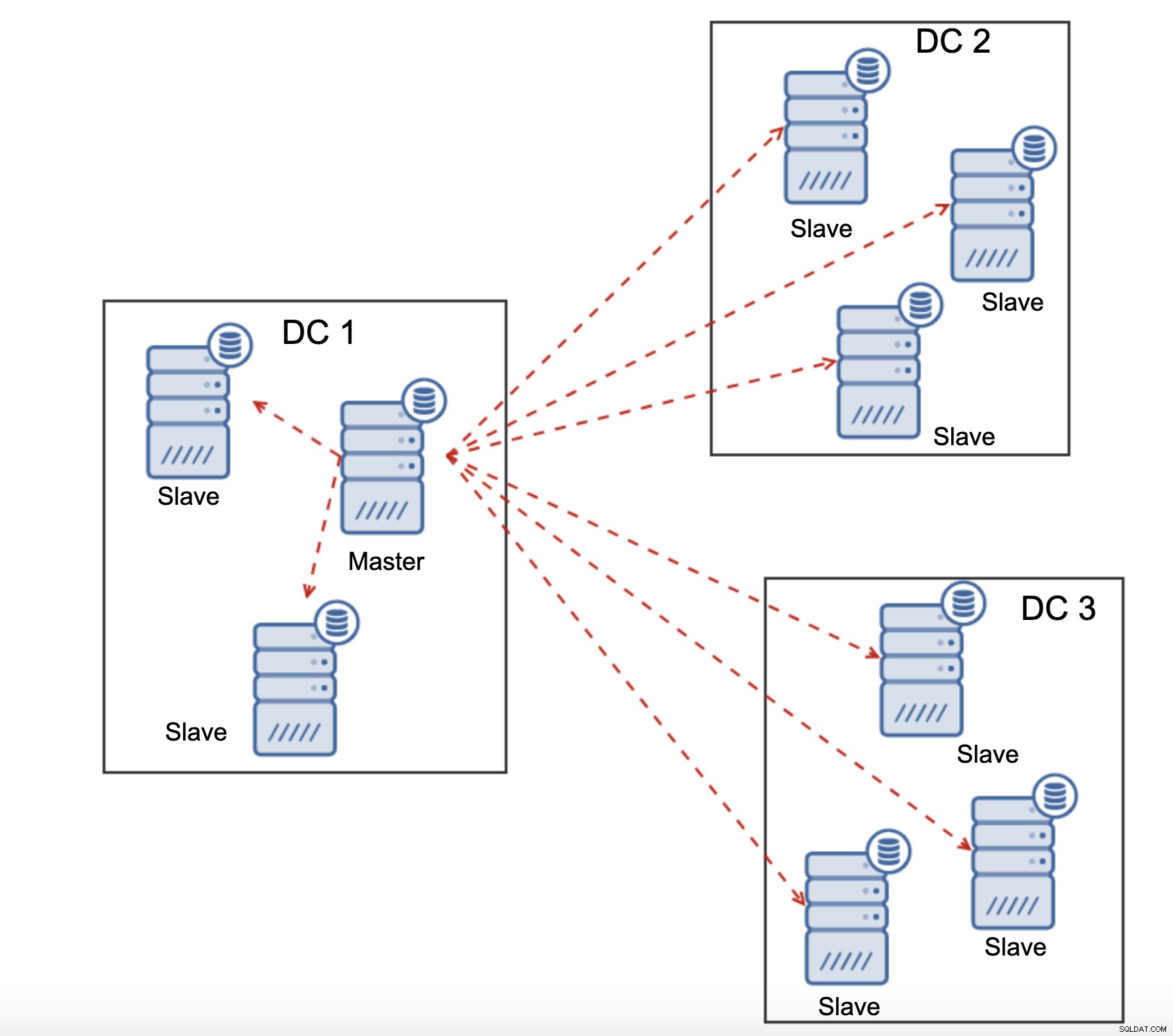
Всички подчинени устройства трябва да получават целия трафик за репликация - количеството данни, което имате за изпращане до отдалечени подчинени устройства през WAN се увеличава с всяко отдалечено подчинено устройство, което добавяте. Това може лесно да доведе до насищане на WAN връзката, особено ако правите много модификации и WAN връзката няма добра пропускателна способност. Както можете да видите на диаграмата по-горе, с три центъра за данни и три възли във всеки от тях, главният трябва да изпрати 6 пъти трафика за репликация през WAN връзка.
С клъстера Galera нещата са малко по-различни. Като за начало Galera използва контрол на потока, за да поддържа възлите в синхрон. Ако един от възлите започне да изостава, той има способността да поиска от останалата част от клъстера да се забави и да я остави да навакса. Разбира се, това намалява производителността на целия клъстер, но все пак е по-добре, отколкото когато наистина не можете да използвате подчинени за SELECTs, тъй като те са склонни да изостават от време на време - в такива случаи резултатите, които ще получите, може да са остарели и неправилни.
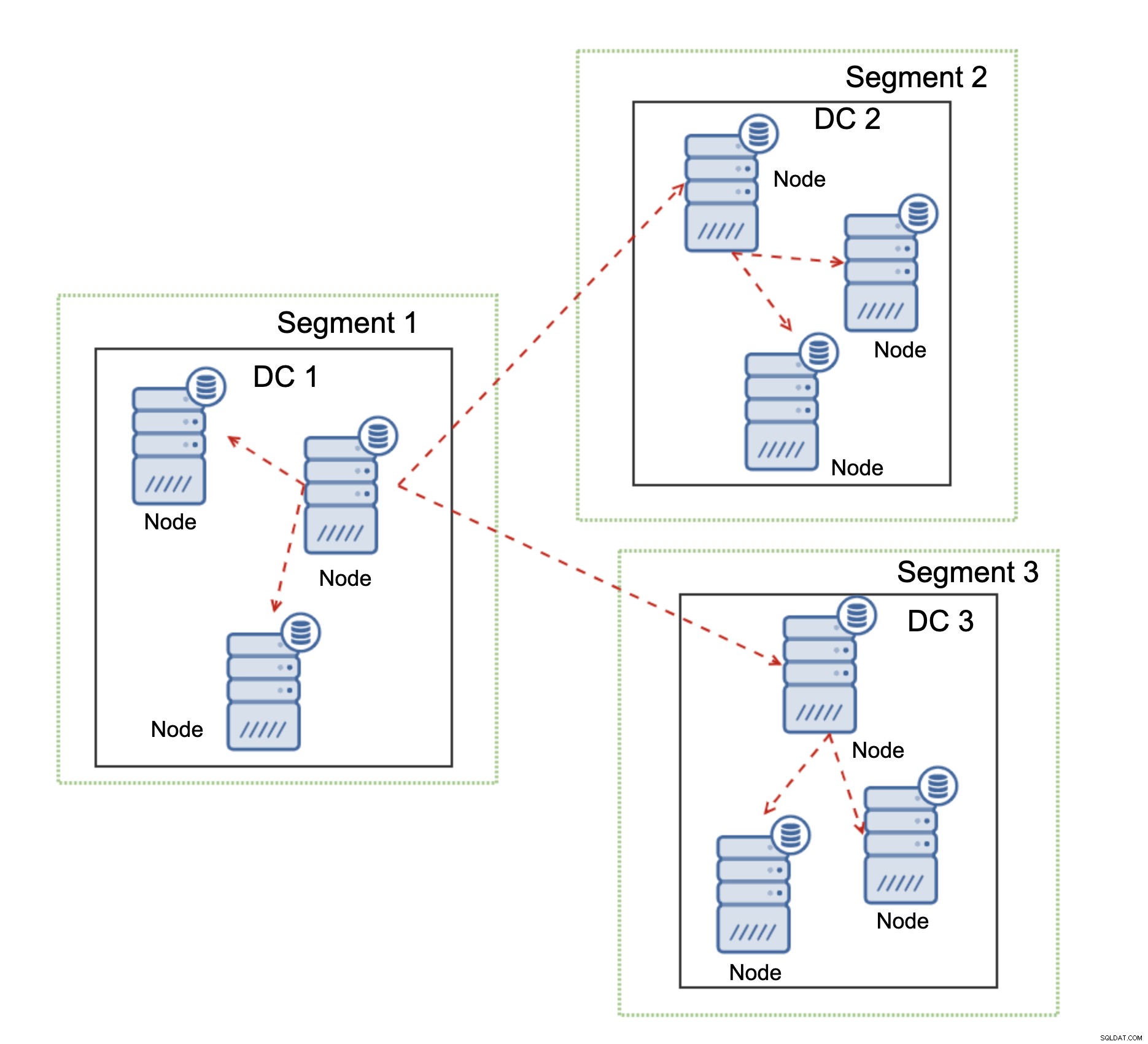
Друга функция на Galera Cluster, която може значително да подобри производителността му, когато се използва над WAN, са сегменти. По подразбиране Galera използва всички за всички комуникации и всеки набор за запис се изпраща от възела до всички други възли в клъстера. Това поведение може да се промени с помощта на сегменти. Сегментите позволяват на потребителите да разделят клъстера Galera на няколко части. Всеки сегмент може да съдържа множество възли и избира един от тях като релеен възел. Такъв възел получава набори за запис от други сегменти и ги преразпределя между възлите на Galera, локални за сегмента. В резултат на това, както можете да видите на диаграмата по-горе, е възможно да се намали трафикът за репликация, преминаващ през WAN три пъти - само две „реплика“ на потока за репликация се изпращат през WAN:едно на център за данни в сравнение с едно на подчинен в MySQL репликация.
Обработване на мрежови дялове в клъстер на Galera
Там, където Galera Cluster блести, е обработката на мрежовото разделяне. Galera Cluster постоянно следи състоянието на възлите в клъстера. Всеки възел се опитва да се свърже със своите партньори и да обменя състоянието на клъстера. Ако подмножество от възли не е достъпно, Galera се опитва да предаде комуникацията, така че ако има начин да се достигне до тези възли, те ще бъдат достигнати.

Пример може да се види на диаграмата по-горе:DC 1 загуби връзката с DC2, но DC2 и DC3 могат да се свържат. В този случай един от възлите в DC3 ще се използва за предаване на данни от DC1 към DC2, като се гарантира, че комуникацията в клъстера може да се поддържа.
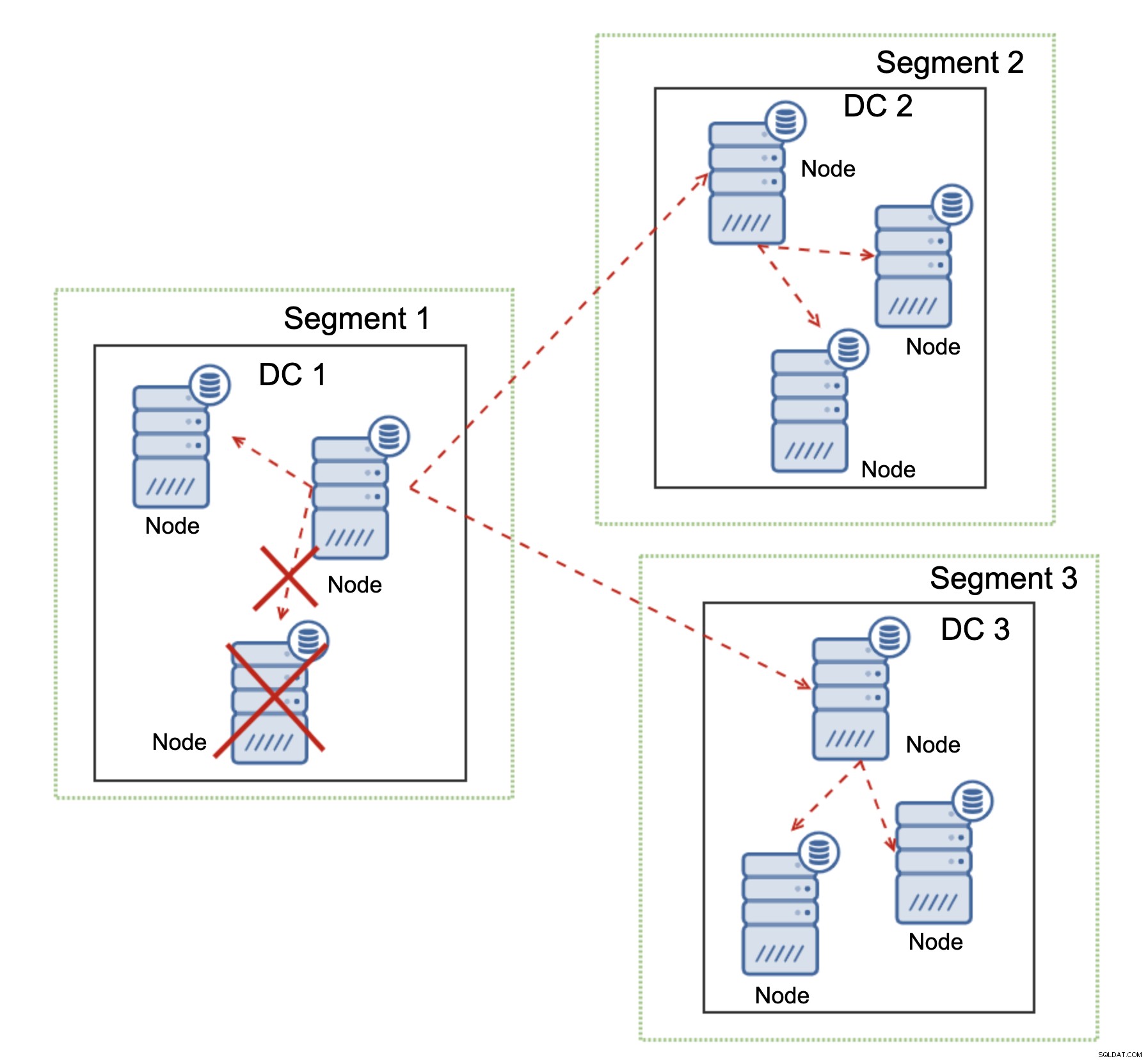
Galera Cluster е в състояние да предприема действия въз основа на състоянието на клъстера. Той реализира кворум - повечето от възлите трябва да са налични, за да може клъстерът да работи. Ако възелът се изключи от клъстера и не може да достигне до друг възел, той ще престане да работи.
Както може да се види на диаграмата по-горе, има частична загуба на мрежовата комуникация в DC1 и засегнатият възел се премахва от клъстера, като се гарантира, че приложението няма да има достъп до остарели данни.
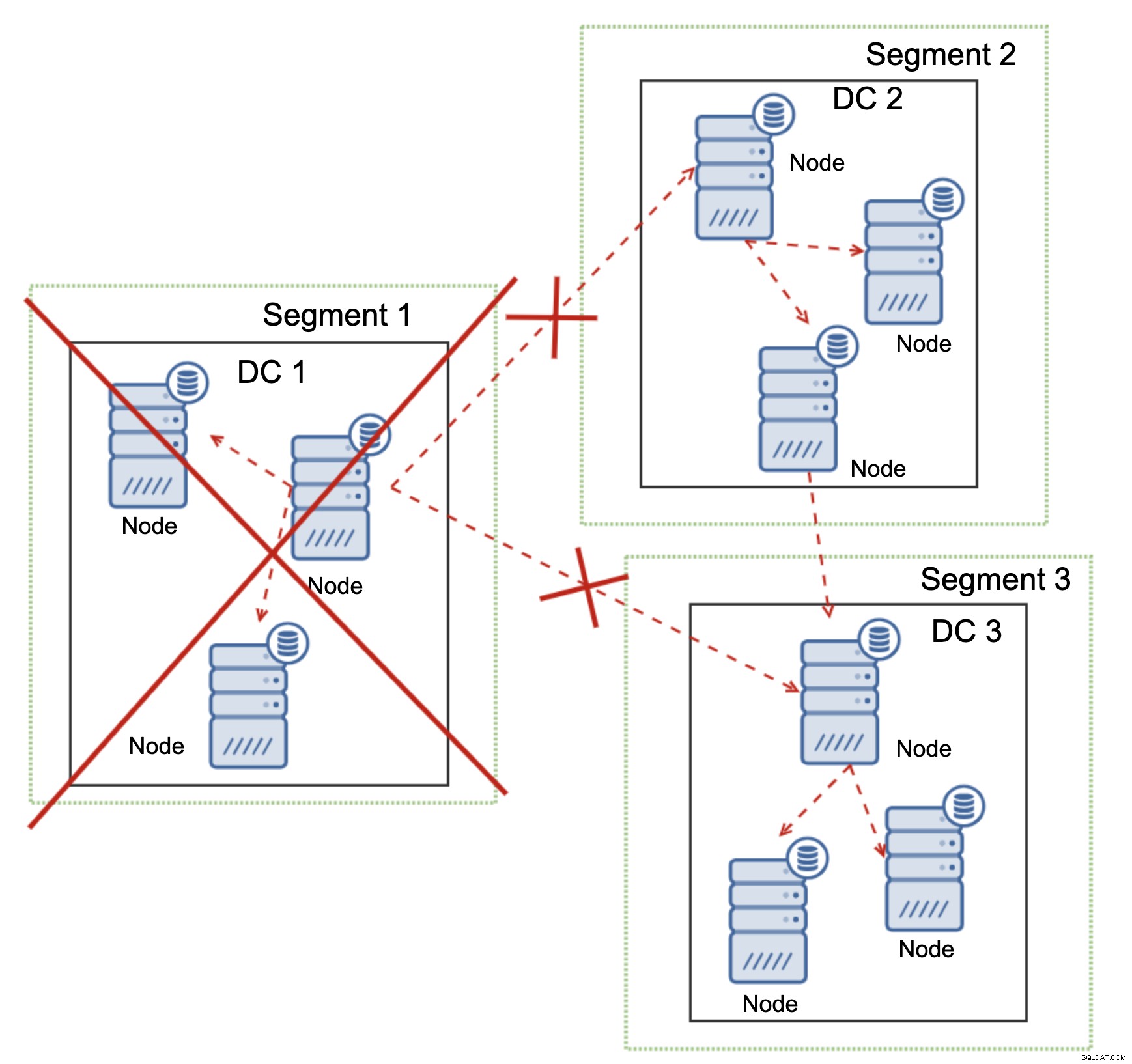
Това е вярно и в по-голям мащаб. DC1 прекъсна цялата си комуникация. В резултат на това целият център за данни е премахнат от клъстера и нито един от неговите възли няма да обслужва трафика. Останалата част от клъстера поддържа мнозинство (6 от 9 възли са налични) и се преконфигурира, за да запази връзката между DC 2 и DC3. В диаграмата по-горе предположихме, че записът удря възела в DC2, но моля, имайте предвид, че Galera може да работи с множество записващи програми.
MySQL репликацията няма никакъв вид клъстерна информираност, което прави проблематично справянето с мрежови проблеми. Той не може да се изключи при загуба на връзка с други възли. Няма лесен начин да предотвратите появата на стария хозяин след разделянето на мрежата.
Единствените възможности са ограничени до прокси слоя или дори по-високо. Трябва да проектирате система, която да се опита да разбере състоянието на клъстера и да предприеме необходимите действия. Един от възможните начини е да се използват инструменти за клъстер като Orchestrator и след това да се изпълняват скриптове, които да проверяват състоянието на Orchestrator RAFT клъстера и въз основа на това състояние да предприемат необходимите действия върху слоя на базата данни. Това далеч не е идеално, тъй като всяко действие, предприето върху слой, по-висок от базата данни, добавя допълнителна латентност:това прави възможно проблемът да се появи и последователността на данните да бъде компрометирана, преди да могат да бъдат предприети правилни действия. Galera, от друга страна, предприема действия на ниво база данни, осигурявайки възможно най-бързата реакция.