Ако управлявате производствена база данни, има големи шансове да се наложи да клонирате базата си данни на друг сървър, различен от производствения. Основният метод за създаване на клонинг е възстановяване на база данни от скорошен архив на друг сървър на база данни. Друг метод е чрез репликиране от изходна база данни, докато тя все още работи, като в този случай е важно оригиналната база данни да не бъде засегната от каквато и да е процедура за клониране.
Защо ще трябва да клонирате база данни?
Клъстерът от клонирана база данни е полезен в редица сценарии:
- Отстранете неизправности във вашия клониран производствен клъстер в безопасността на вашата тестова среда, докато извършвате разрушителни операции върху базата данни.
- Тест за корекция/надстройка на клонирана база данни, за да се потвърди процеса на надстройка, преди да се приложи към производствения клъстер.
- Проверете архивиране и възстановяване на производствен клъстер с помощта на клониран клъстер.
- Проверете или тествайте нови приложения в клониран производствен клъстер, преди да го разположите в активния производствен клъстер.
- Бързо клонирайте базата данни за одит или изисквания за съответствие на информацията, например до края на тримесечие или година, когато съдържанието на базата данни не трябва да се променя.
- База данни за отчети може да се създава на интервали, за да се избегнат промени в данните по време на генерирането на отчети.
- Мигрирайте база данни към нови сървъри, нова среда за внедряване или нов център за данни.
Когато вашата инфраструктура на база данни работи в облака, цената за притежаване на хост (споделена или специална виртуална машина) е значително по-ниска в сравнение с традиционния начин за наемане на пространство в център за данни или притежаване на физически сървър. Освен това, по-голямата част от внедряването в облака може лесно да се автоматизира чрез API на доставчика, клиентски софтуер и скриптове. Следователно клонирането на клъстер може да бъде често срещан начин за дублиране на вашата среда за внедряване, например, от разработчик към стадия към производство или обратно.
Не сме виждали тази функция да се предлага от някой на пазара, затова е наша привилегия да покажем как работи с ClusterControl.
Клониране на MySQL Galera клъстер
Една от страхотните функции в ClusterControl е, че ви позволява бързо да клонирате съществуващ MySQL Galera Cluster, така че да имате точно копие на набора от данни в другия клъстер. ClusterControl извършва операцията по клониране онлайн, без никакво заключване или прекъсване на съществуващия клъстер. Това е като операция за мащабиране на клъстер, освен че и двата клъстера са независими един от друг след приключване на синхронизирането. Клонираният клъстер не е задължително да има същия размер на клъстера като съществуващия. Можем да започнем с клъстер с един възел и да го разширим с повече възли на база данни на по-късен етап.
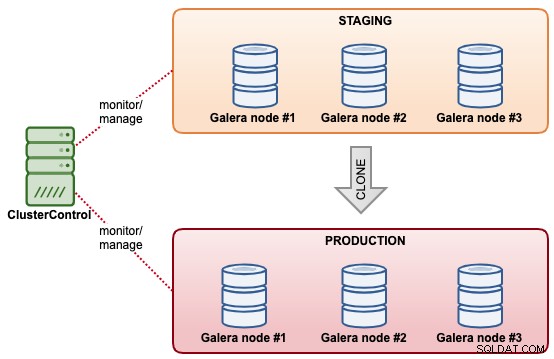
В този пример имаме клъстер, наречен "Staging", който бихме искали да клонираме като друг клъстер, наречен "Производство". Предпоставката е, че етапният клъстер вече съхранява необходимите данни, които скоро ще бъдат в производство. Производственият клъстер се състои от още 3 възела с производствени спецификации.
Следната диаграма обобщава окончателната архитектура на това, което искаме да постигнем:
Първото нещо, което трябва да направите, е да настроите SSH без парола от сървъра на ClusterControl към производствените сървъри. На сървъра на ClusterControl изпълнете следното:
$ whoami
root
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.comВъведете root паролата на целевия сървър, ако бъдете подканени.
От списъка с клъстери на база данни ClusterControl щракнете върху бутона Cluster Action и изберете Clone Cluster. Ще се появи следният съветник:
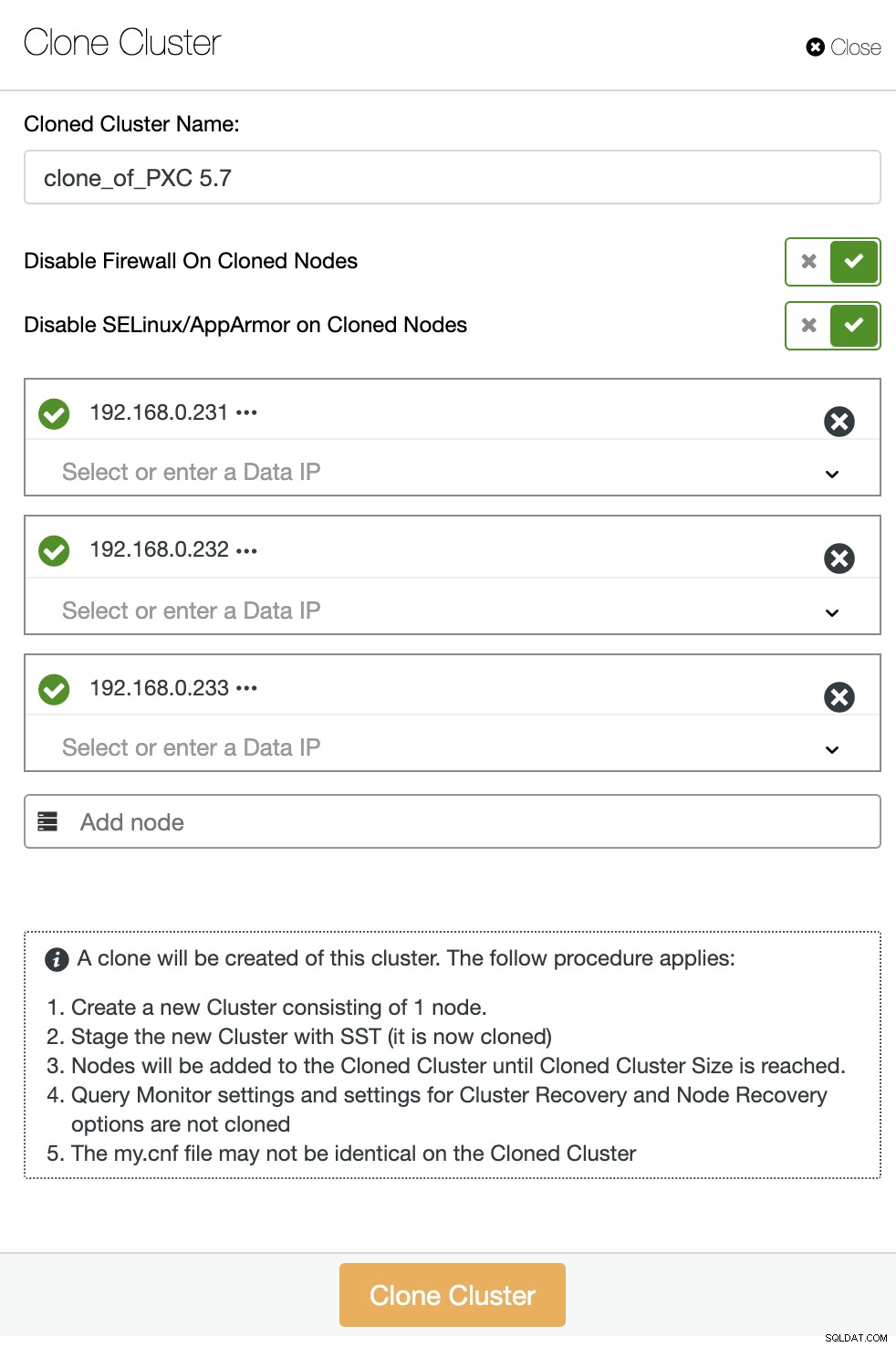
Посочете IP адресите или имената на хостове на новия клъстер и се уверете, че получавате цялата икона на зелена отметка до посочения хост. Зелената икона означава, че ClusterControl може да се свърже с хоста чрез SSH без парола. Кликнете върху бутона „Клониране на клъстер“, за да започнете внедряването.
Стъпките за внедряване са:
- Създаване на нов клъстер се състои от един възел.
- Синхронизиране на новия клъстер с един възел чрез SST. Донорът е един от изходните сървъри.
- Останалите нови възли ще се присъединят към клъстера, след като донорът на клонирания клъстер бъде синхронизиран с клъстера.
След като бъде готово, нов MySQL Galera Cluster ще бъде посочен в таблото за управление на клъстера ClusterControl, след като задачата за внедряване приключи.
Обърнете внимание, че клонирането на клъстера клонира само сървърите на базата данни, а не целия стек на клъстера. Това означава, че други поддържащи компоненти, свързани с клъстера, като балансьори на натоварване, виртуален IP адрес, арбитър на Galera или асинхронен подчинен, няма да бъдат клонирани от ClusterControl. Независимо от това, ако искате да клонирате като точно копие на съществуващата си инфраструктура на база данни, можете да постигнете това с ClusterControl, като разположите тези компоненти отделно, след като операцията по клониране на базата данни приключи.
Създаване на клъстер от база данни от резервно копие
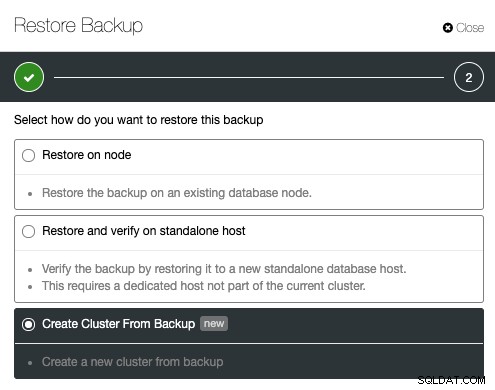
Друга подобна функция, предлагана от ClusterControl, е „Създаване на клъстер от резервно копие“. Тази функция е въведена в ClusterControl 1.7.1, специално за Galera Cluster и PostgreSQL клъстери, където човек може да създаде нов клъстер от съществуващия архив. Противно на клонирането на клъстер, тази операция не носи допълнително натоварване на изходния клъстер, като компромисът на клонирания клъстер няма да бъде в текущото състояние като изходния клъстер.
За да създадете клъстер от резервно копие, трябва да създадете работещ архив. За Galera Cluster всички методи за архивиране се поддържат, докато за PostgreSQL само pgbackrest не се поддържа за внедряване на нов клъстер. От ClusterControl може лесно да се създаде или планира архивиране в ClusterControl -> Архивиране -> Създаване на архив. От списъка на създаденото архивно копие щракнете върху Възстановяване на архива, изберете архива от списъка и изберете „Създаване на клъстер от резервно копие“ от опцията за възстановяване:
В този пример ще внедрим нов клъстер за поточно репликация на PostgreSQL за етапна среда, въз основа на съществуващото архивиране, което имаме в производствения клъстер. Следната диаграма илюстрира крайната архитектура:
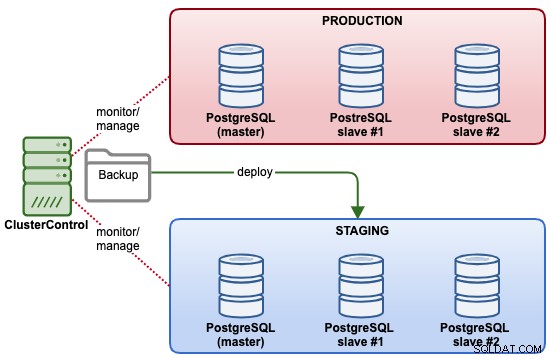
Първото нещо, което трябва да направите, е да настроите SSH без парола от сървъра на ClusterControl към производствените сървъри. На сървъра на ClusterControl изпълнете следното:
$ whoami
root
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.comКогато изберете Създаване на клъстер от архивиране, ClusterControl ще отвори диалогов прозорец на съветника за внедряване, за да ви помогне да настроите новия клъстер:
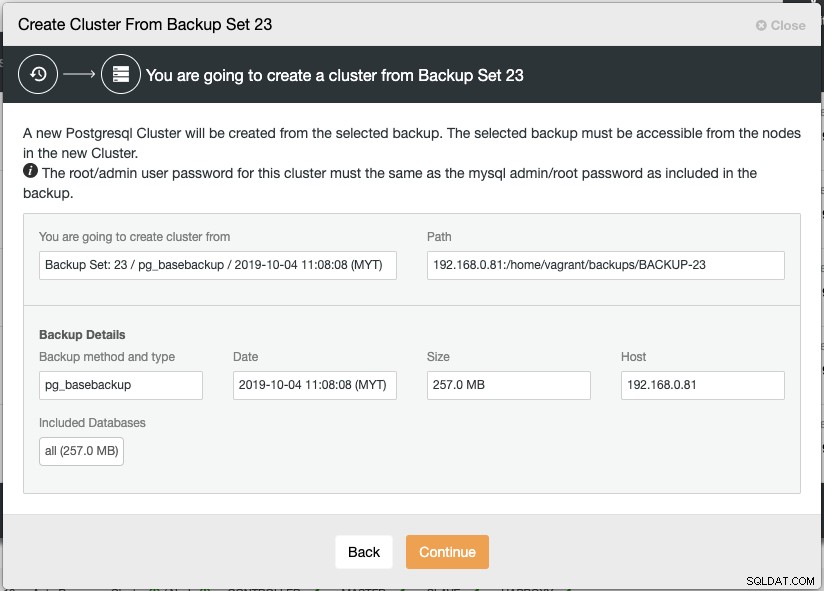
Нов екземпляр на PostgreSQL Streaming Replication ще бъде създаден от избрания архив, който ще се използва като основен набор от данни за новия клъстер. Избраното архивиране трябва да бъде достъпно от възлите в новия клъстер или да се съхранява в хоста ClusterControl.
Щракването върху „Продължи“ ще отвори стандартния съветник за внедряване на клъстер от база данни:
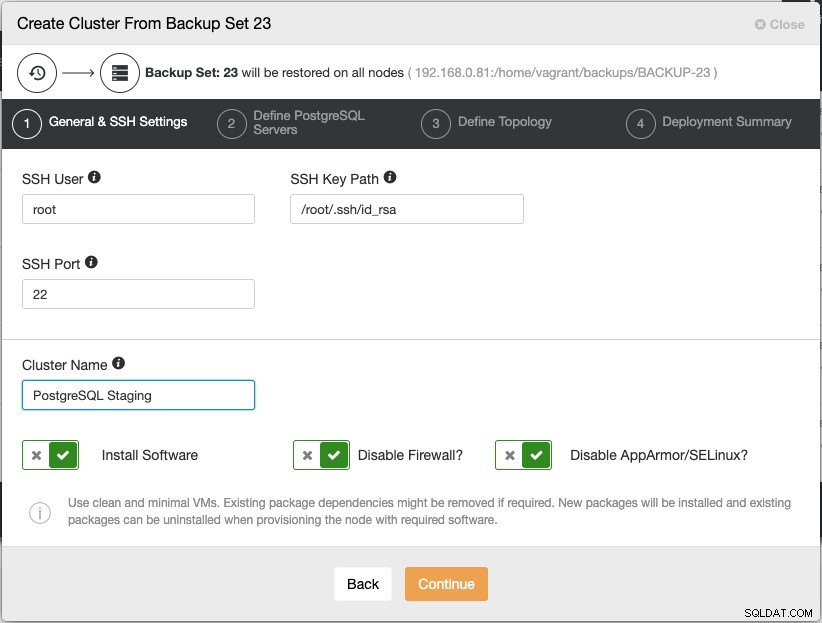
Обърнете внимание, че паролата на root/admin потребител за този клъстер трябва да е същата като паролата за администратор/рут на PostgreSQL, както е включено в архива. Следвайте съответно съветника за конфигурация и ClusterControl след това извършете разполагането в следния ред:
- Инсталирайте необходимия софтуер и зависимости на всички PostgreSQL възли.
- Стартирайте първия възел.
- Предаване и възстановяване на архивно копие на първия възел.
- Конфигурирайте и добавете останалите възли.
След като приключите, нов клъстер за репликация на PostgreSQL ще бъде посочен под таблото за управление на клъстера ClusterControl, след като задачата за внедряване приключи.