Заявките трябва да се кешират във всяка силно натоварена база данни, просто няма начин база данни да обработва целия трафик с разумна производителност. Има различни механизми, в които може да се реализира кеш на заявки. Започвайки от кеша на заявките на MySQL, който работеше добре за предимно работни натоварвания само за четене с нисък паралел и който няма място при високи едновременни работни натоварвания (до степента, в която Oracle го премахна в MySQL 8.0), до външни магазини ключ-стойност като Redis, memcached или CouchBase.
Основният проблем с използването на външно специализирано хранилище за данни (тъй като не бихме препоръчали да използвате MySQL кеша на заявки на никого) е, че това е още едно хранилище за данни за управление. Това е още една среда за поддръжка, проблеми с мащабирането, които да се справят, грешки за отстраняване на грешки и т.н.
Така че защо не убиете две птици с един удар, като използвате проксито си? Предположението тук е, че използвате прокси във вашата производствена среда, тъй като той помага на заявките за балансиране на натоварването между екземпляри и маскира основната топология на базата данни, като предоставя проста крайна точка на приложенията. ProxySQL е чудесен инструмент за работа, тъй като може допълнително да функционира като кеширащ слой. В тази публикация в блога ще ви покажем как да кеширате заявки в ProxySQL с помощта на ClusterControl.
Как работи кешът на заявките в ProxySQL?
На първо място, малко предистория. ProxySQL управлява трафика чрез правила за заявка и може да осъществи кеширане на заявки, използвайки същия механизъм. ProxySQL съхранява кеширани заявки в структура на паметта. Кешираните данни се изхвърлят чрез настройка за време на живот (TTL). TTL може да бъде дефиниран за всяко правило за заявка поотделно, така че потребителят трябва да реши дали правилата за заявка да бъдат дефинирани за всяка отделна заявка, с отделен TTL или просто трябва да създаде няколко правила, които ще съответстват на по-голямата част от трафика.
Има две настройки за конфигурация, които определят как трябва да се използва кешът на заявката. Първо, mysql-query_cache_size_MB което дефинира меко ограничение за размера на кеша на заявката. Това не е твърдо ограничение, така че ProxySQL може да използва малко повече памет от това, но е достатъчно, за да поддържа използването на паметта под контрол. Втората настройка, която можете да настроите, е mysql-query_cache_stores_empty_result . Той определя дали празен набор от резултати се кешира или не.
Кешът на заявките на ProxySQL е проектиран като магазин ключ-стойност. Стойността е резултатният набор от заявка, а ключът е съставен от конкатенирани стойности като:потребител, схема и текст на заявката. След това се създава хеш от този низ и този хеш се използва като ключ.
Настройване на ProxySQL като кеш на заявки с помощта на ClusterControl
Като първоначална настройка имаме клъстер за репликация от един главен и един подчинен. Имаме и един ProxySQL.
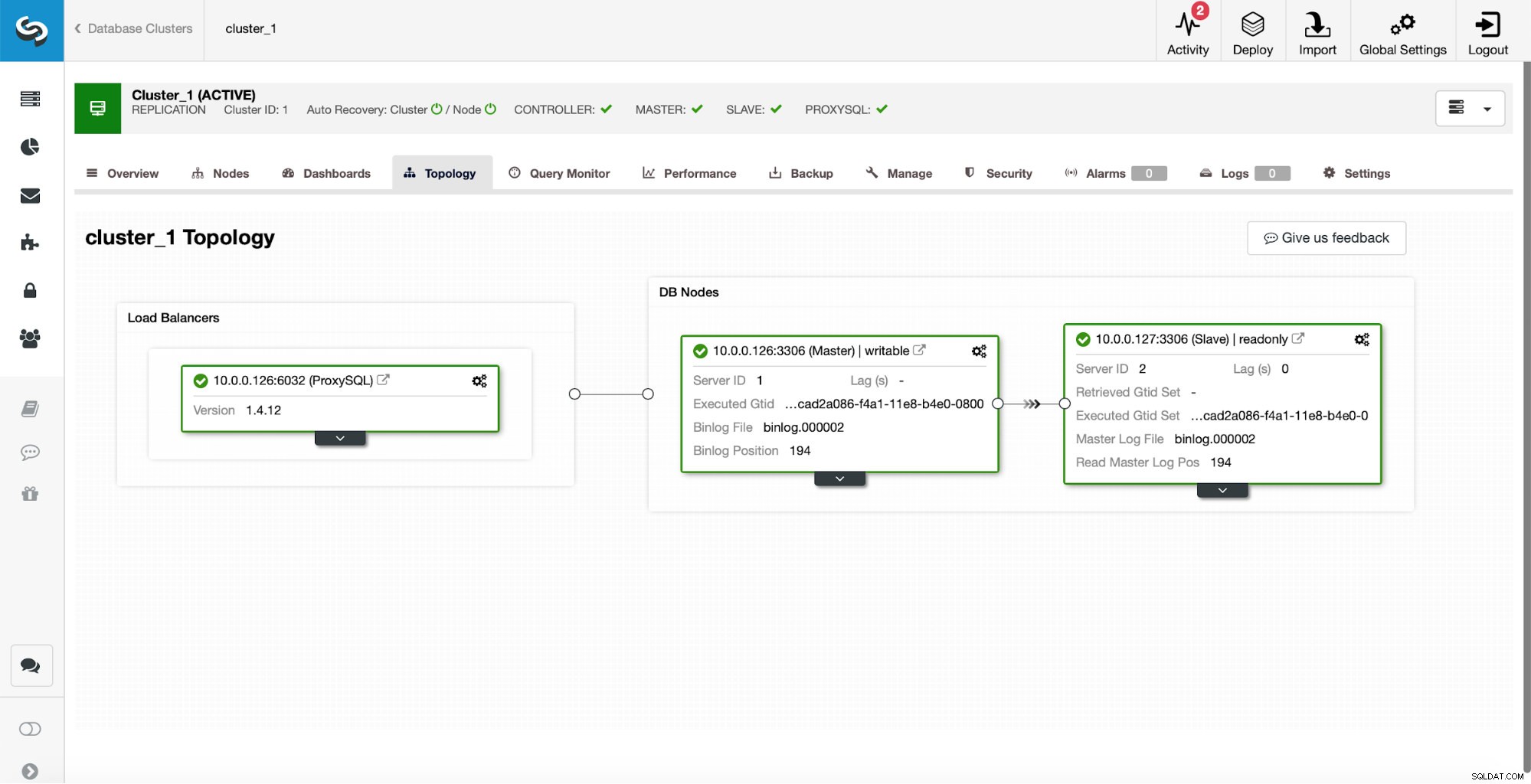
Това в никакъв случай не е настройка от производствен клас, тъй като ще трябва да внедрим някакъв вид висока наличност за прокси слоя (например чрез разгръщане на повече от един екземпляр на ProxySQL и след това поддържане на активност върху тях за плаващ виртуален IP), но ще бъде повече от достатъчно за нашите тестове.
Първо, ще проверим конфигурацията на ProxySQL, за да се уверим, че настройките на кеша на заявките са това, което искаме да бъдат.
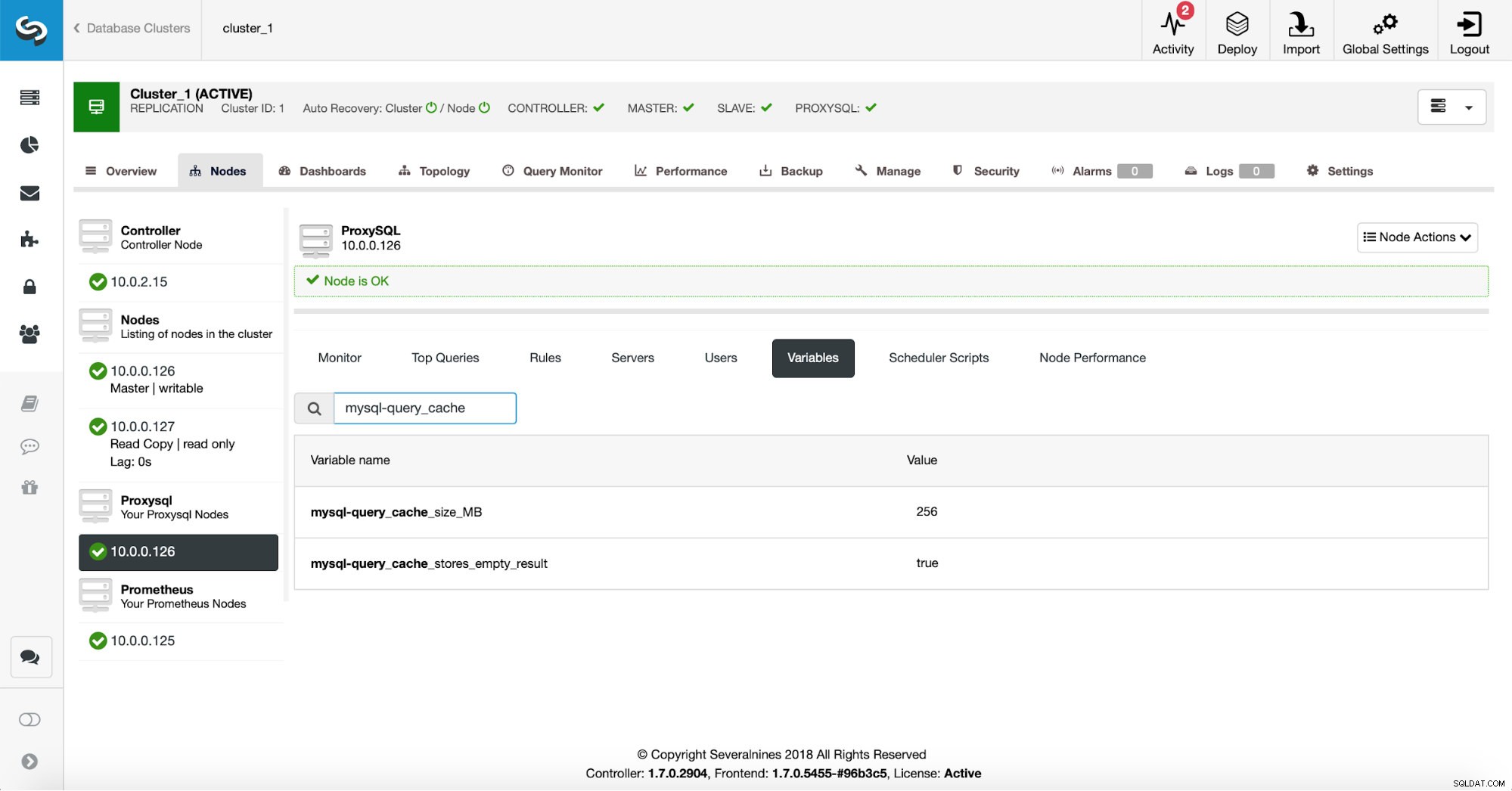
256 MB кеш на заявките би трябвало да са подходящи и ние искаме да кешираме и празните набори от резултати - понякога заявка, която не връща данни, все още трябва да свърши много работа, за да провери, че няма какво да върне.
Следващата стъпка е да създадете правила за заявка, които ще съответстват на заявките, които искате да кеширате. Има два начина да направите това в ClusterControl.
Ръчно добавяне на правила за заявка
Първият начин изисква малко повече ръчни действия. С помощта на ClusterControl можете лесно да създадете всяко правило за заявка, което искате, включително правила за заявка, които извършват кеширането. Първо, нека да разгледаме списъка с правила:
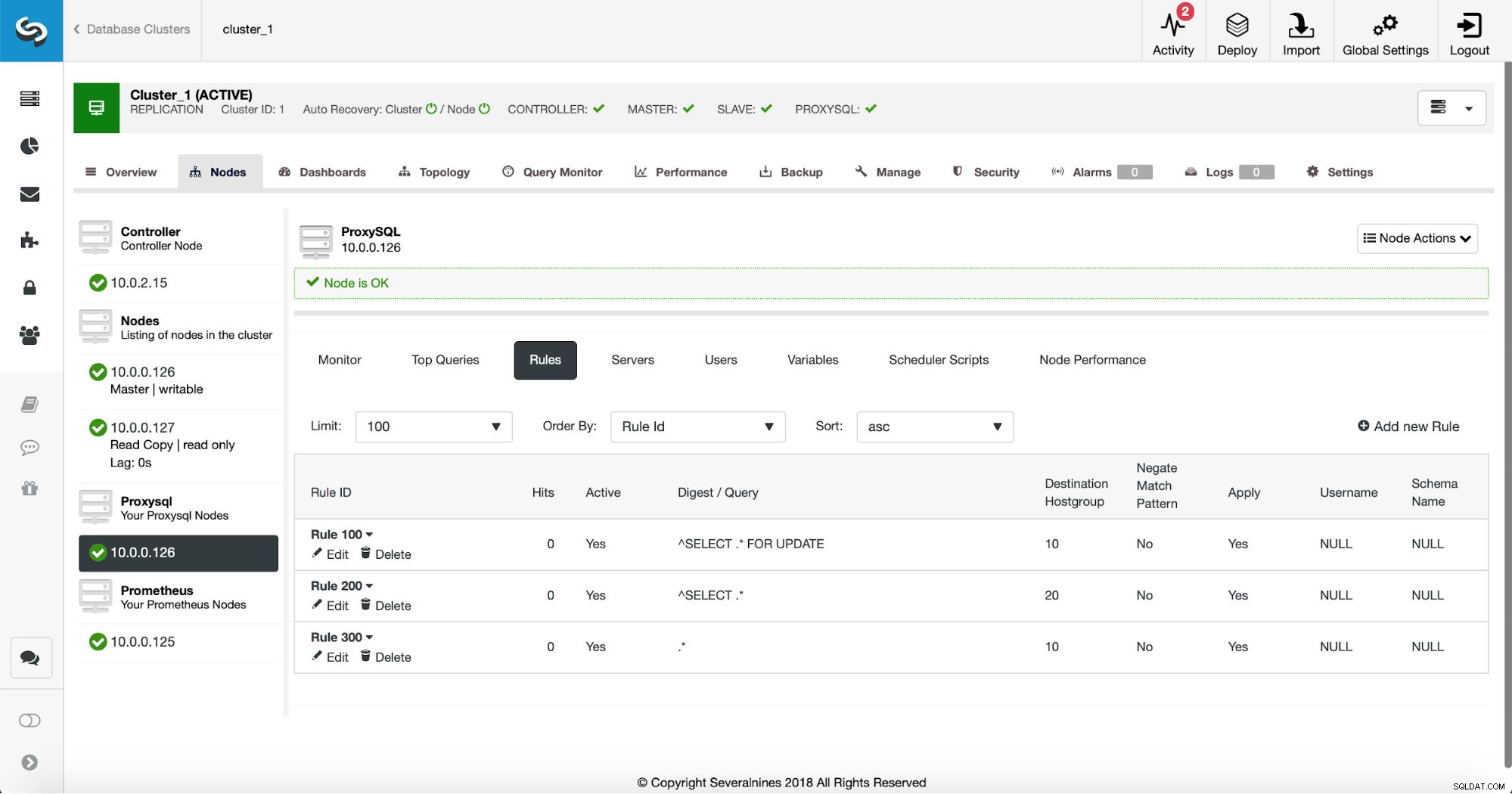
В този момент имаме набор от правила за заявка за извършване на разделянето на четене/запис. Първото правило има идентификатор 100. Новото ни правило за заявка трябва да бъде обработено преди това, така че ще използваме по-нисък идентификатор на правилото. Нека създадем правило за заявка, което ще извършва кеширане на заявки, подобно на това:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY c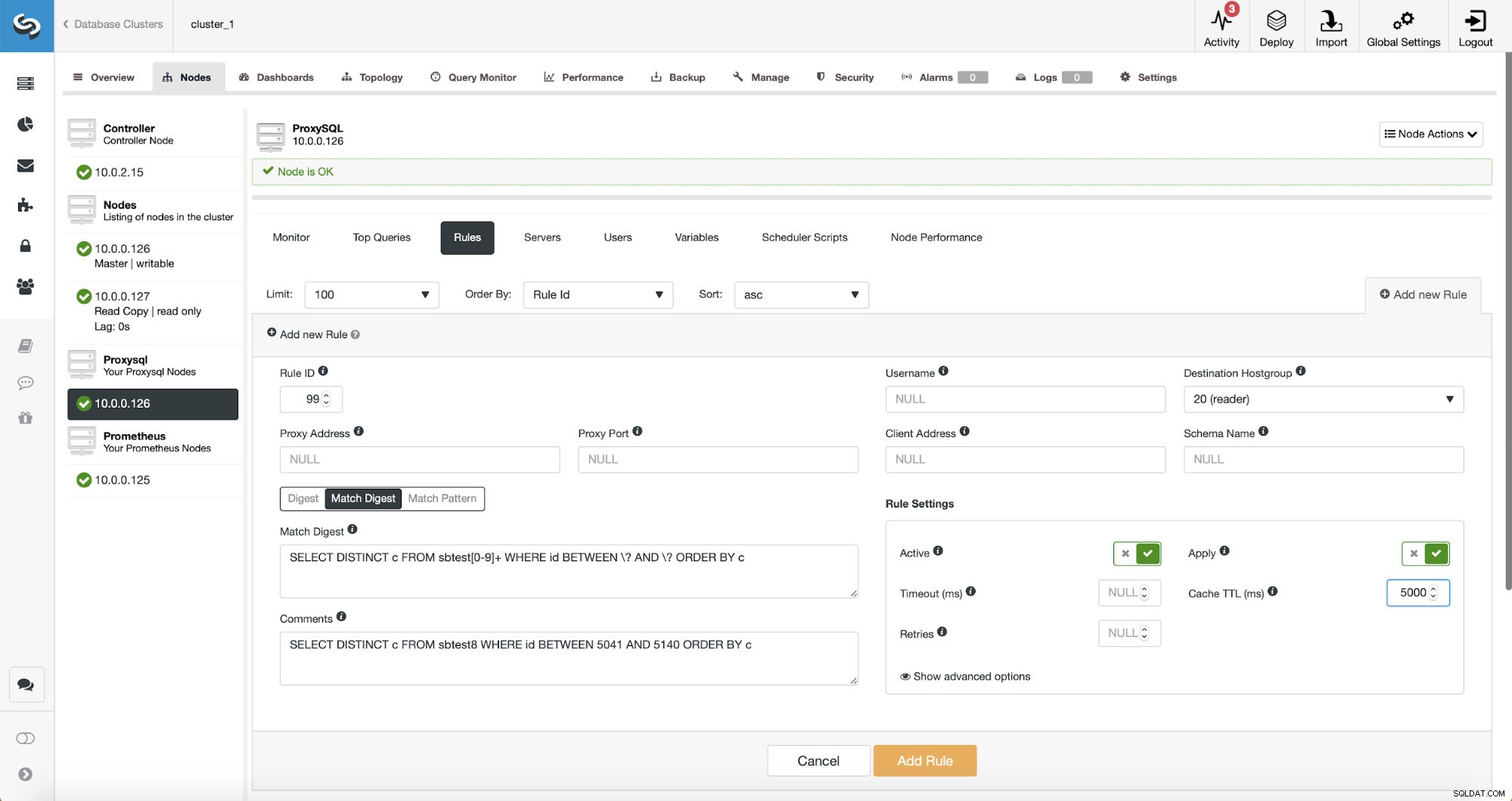
Има три начина за съвпадение на заявката:Digest, Match Digest и Match Pattern. Нека поговорим малко за тях тук. Първо, сборник за мачове. Тук можем да зададем регулярен израз, който ще съответства на обобщен низ на заявка, който представлява някакъв тип заявка. Например за нашата заявка:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cОбщото представяне ще бъде:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN ? AND ? ORDER BY cКакто можете да видите, той премахна аргументите на клаузата WHERE, поради което всички заявки от този тип са представени като един низ. Тази опция е доста приятна за използване, защото съответства на целия тип заявка и, което е още по-важно, премахва всякакви бели интервали. Това прави много по-лесно писането на регулярен израз, тъй като не е нужно да отчитате странни прекъсвания на редове, бели интервали в началото или края на низа и така нататък.
Дайджестът е основно хеш, който ProxySQL изчислява през формата на Match Digest.
И накрая, моделът на съвпадение съвпада с пълния текст на заявката, тъй като е изпратен от клиента. В нашия случай заявката ще има вид:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cЩе използваме Match Digest, тъй като искаме всички тези заявки да бъдат обхванати от правилото за заявка. Ако искаме да кешираме точно тази конкретна заявка, добър вариант би бил да използваме модел на съвпадение.
Регулярният израз, който използваме е:
SELECT DISTINCT c FROM sbtest[0-9]+ WHERE id BETWEEN \? AND \? ORDER BY cНие съпоставяме буквално точния обобщен низ на заявка с едно изключение - знаем, че тази заявка е ударила множество таблици, затова добавихме регулярен израз, за да съответства на всички тях.
След като това бъде направено, можем да видим дали правилото за заявка е в сила или не.
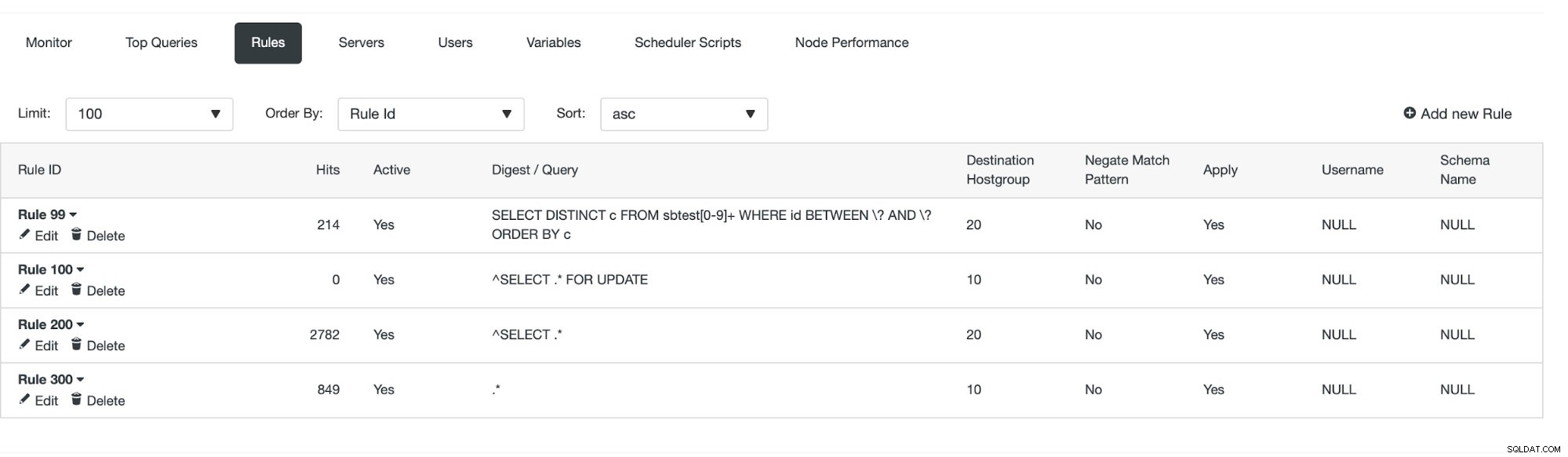
Виждаме, че „посещенията“ се увеличават, което означава, че се използва нашето правило за заявка. След това ще разгледаме друг начин за създаване на правило за заявка.
Използване на ClusterControl за създаване на правила за заявка
ProxySQL има полезна функционалност за събиране на статистически данни за пренасочените от него заявки. Можете да проследявате данни като време на изпълнение, колко пъти е била изпълнена дадена заявка и т.н. Тези данни също присъстват в ClusterControl:
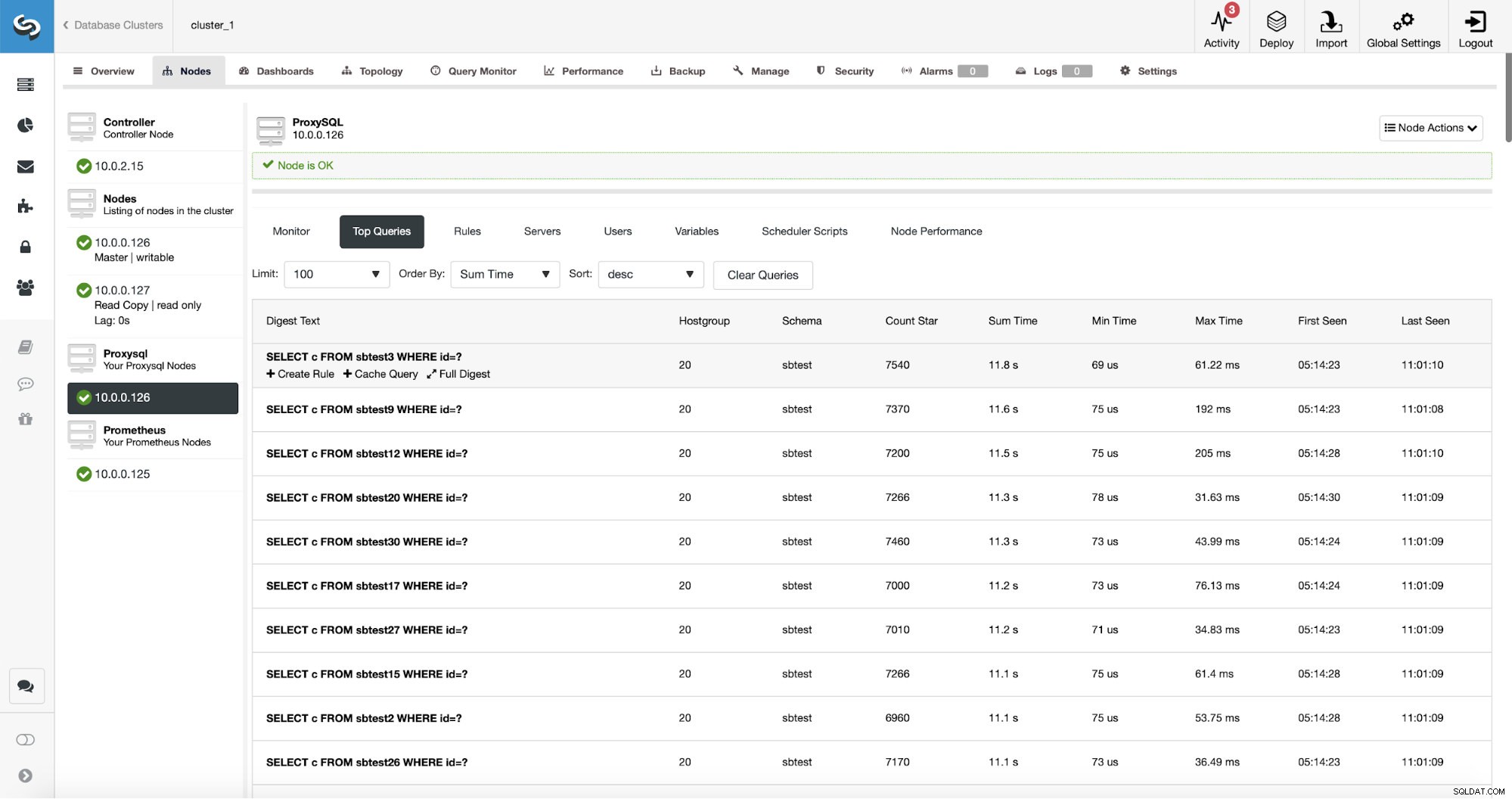
Още по-добре е, че ако посочите даден тип заявка, можете да създадете свързано с него правило за заявка. Можете също така лесно да кеширате този конкретен тип заявка.
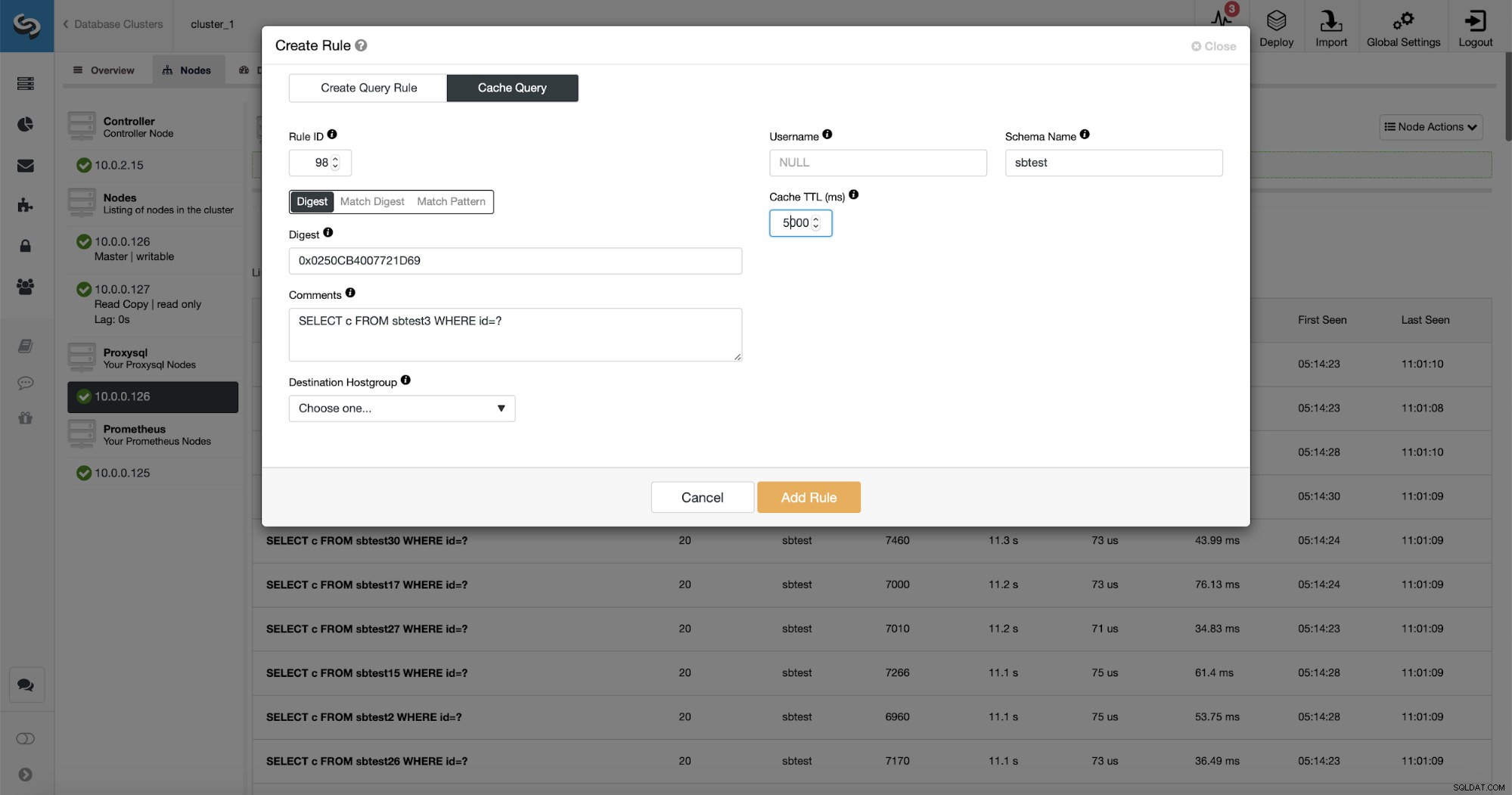
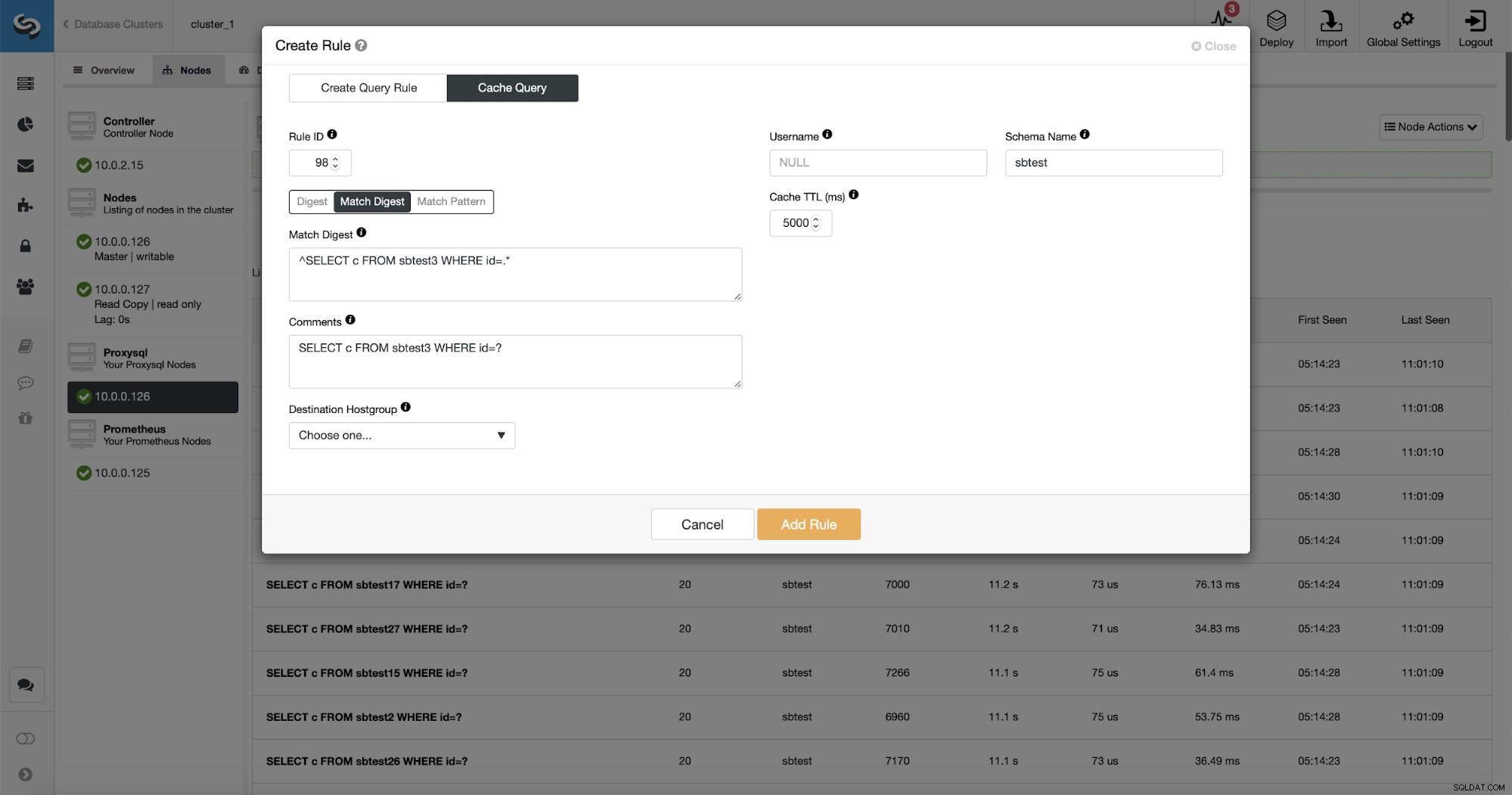
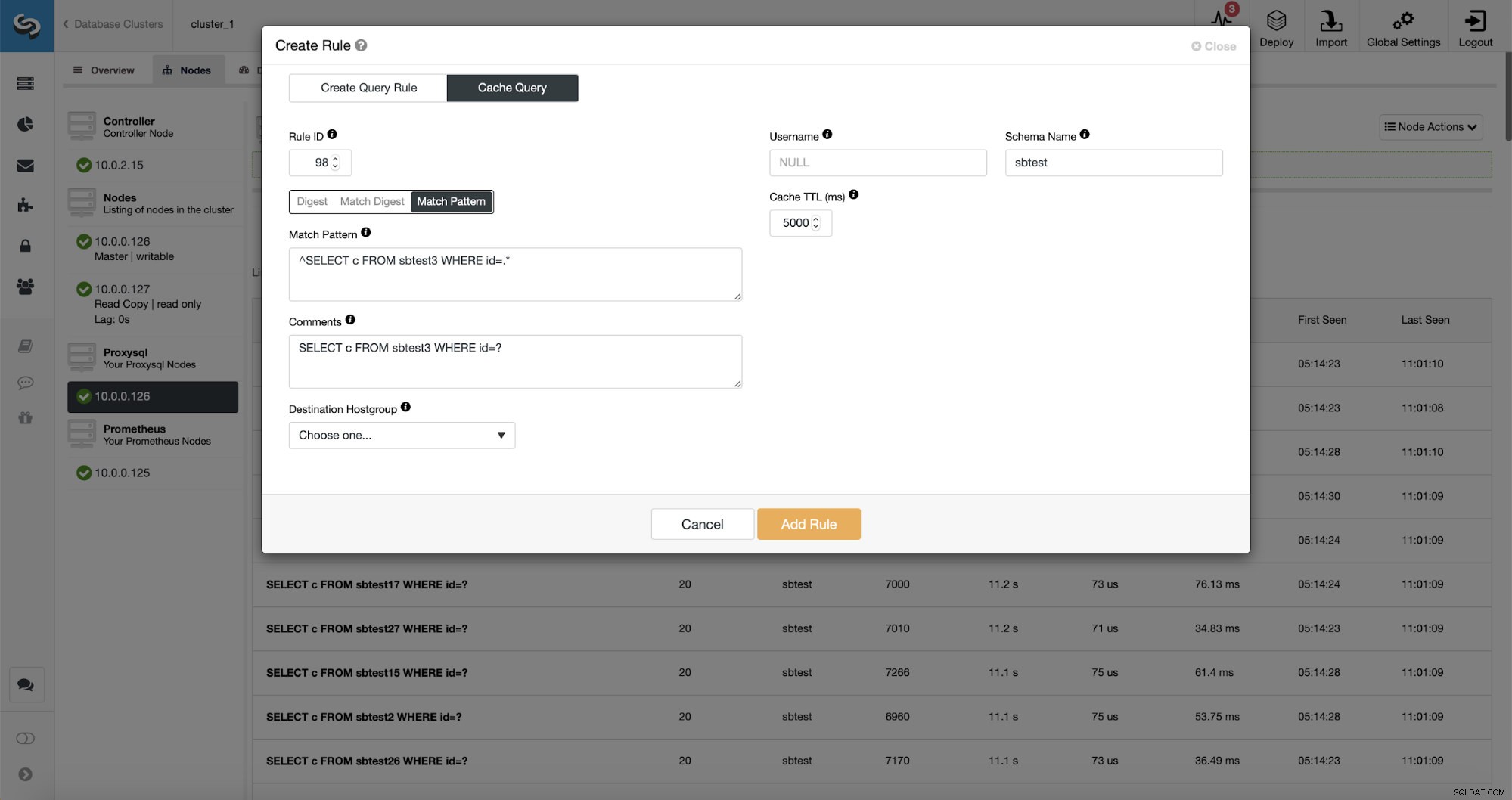
Както можете да видите, някои от данните като правило IP, Cache TTL или име на схема вече са попълнени. ClusterControl също ще попълни данни въз основа на кой механизъм за съвпадение сте решили да използвате. Можем лесно да използваме или хеш за даден тип заявка, или можем да използваме Match Digest или Match Pattern, ако искаме да прецизираме регулярния израз (например да направим същото, както направихме по-рано и да разширим регулярния израз, за да съответства на всички таблици в sbtest схема).
Това е всичко, от което се нуждаете, за да създадете лесно правила за кеширане на заявки в ProxySQL. Изтеглете ClusterControl, за да го изпробвате днес.