В секцията за коментари на един от нашите блогове читател попита за въздействието на wsrep_slave_threads върху I/O производителността и мащабируемостта на Galera Cluster. По това време не можехме лесно да отговорим на този въпрос и да го архивираме с повече данни, но накрая успяхме да настроим средата и да проведем някои тестове.
Нашият читател посочи сравнителни показатели, които показаха, че увеличаването на wsrep_slave_threads не оказва никакво влияние върху производителността на клъстера Galera.
За да обясним какво е въздействието на тази настройка, създадохме малък клъстер от три възела (m5d.xlarge). Това ни позволи да използваме директно прикачен nvme SSD за директорията с данни на MySQL. По този начин намалихме до минимум шанса съхранението да се превърне в пречка в нашата настройка.
Настроихме InnoDB буферен пул на 8GB и повторихме регистрационните файлове до два файла, по 1GB всеки. Също така увеличихме innodb_io_capacity до 2000 и innodb_io_capacity_max до 10 000. Това също имаше за цел да гарантираме, че нито една от тези настройки няма да повлияе на производителността ни.
Целият проблем с такива бенчмаркове е, че има толкова много тесни места, че трябва да ги елиминирате един по един. Само след като направите някои настройки на конфигурацията и след като се уверите, че хардуерът няма да е проблем, човек може да има надежда, че ще се появят някои по-фини ограничения.
Генерирахме ~90GB данни с помощта на sysbench:
sysbench /usr/share/sysbench/oltp_write_only.lua --threads=16 --events=0 --time=600 --mysql-host=172.30.4.245 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=3306 --tables=28 --report-interval=1 --skip-trx=off --table-size=10000000 --db-ps-mode=disable --mysql-db=sbtest_large prepareСлед това бенчмаркът беше изпълнен. Тествахме две настройки:wsrep_slave_threads=1 и wsrep_slave_threads=16. Хардуерът не беше достатъчно мощен, за да се възползва от увеличаването на тази променлива още повече. Моля, имайте предвид също, че не направихме подробен сравнителен анализ, за да определим дали wsrep_slave_threads трябва да бъде настроен на 16, 8 или може би 4 за най-добра производителност. Интересувахме се дали можем да покажем въздействие върху клъстера. И да, въздействието беше ясно видимо. За начало, някои графики за контрол на потока.
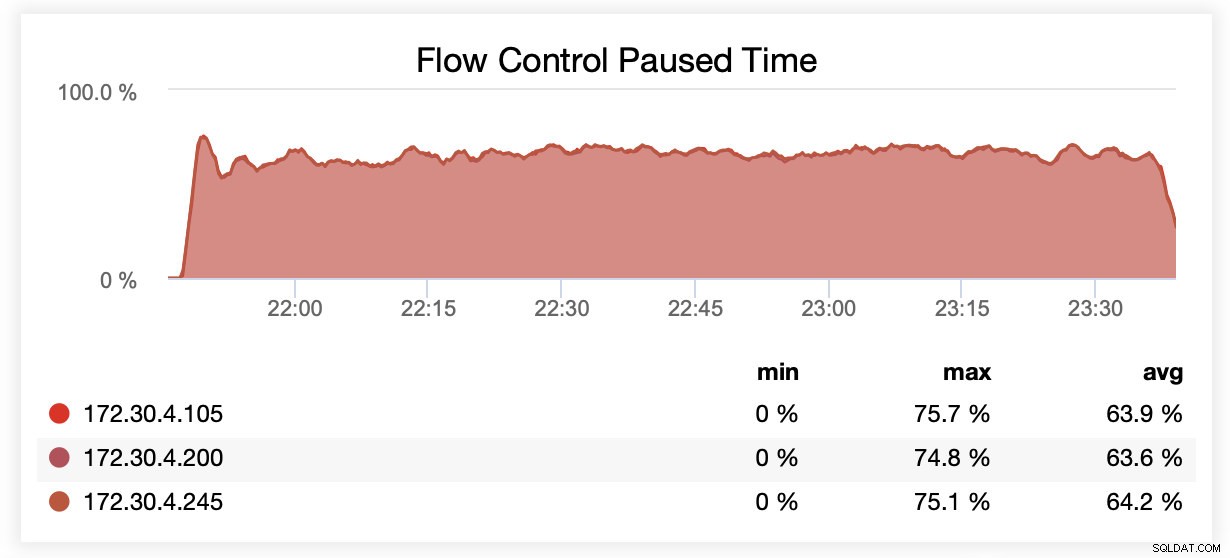
Докато се изпълняваше с wsrep_slave_threads=1, средно възлите бяха поставени на пауза поради контрол на потока в ~64% от времето.
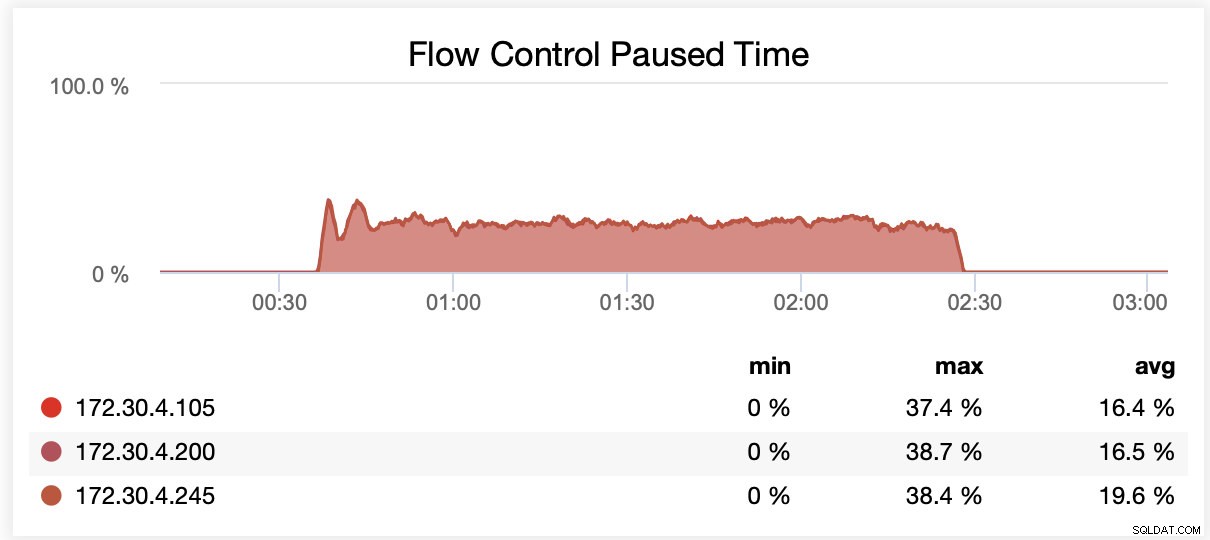
Докато се изпълняваше с wsrep_slave_threads=16, възлите бяха поставени на пауза средно поради контрол на потока в ~20% от времето.
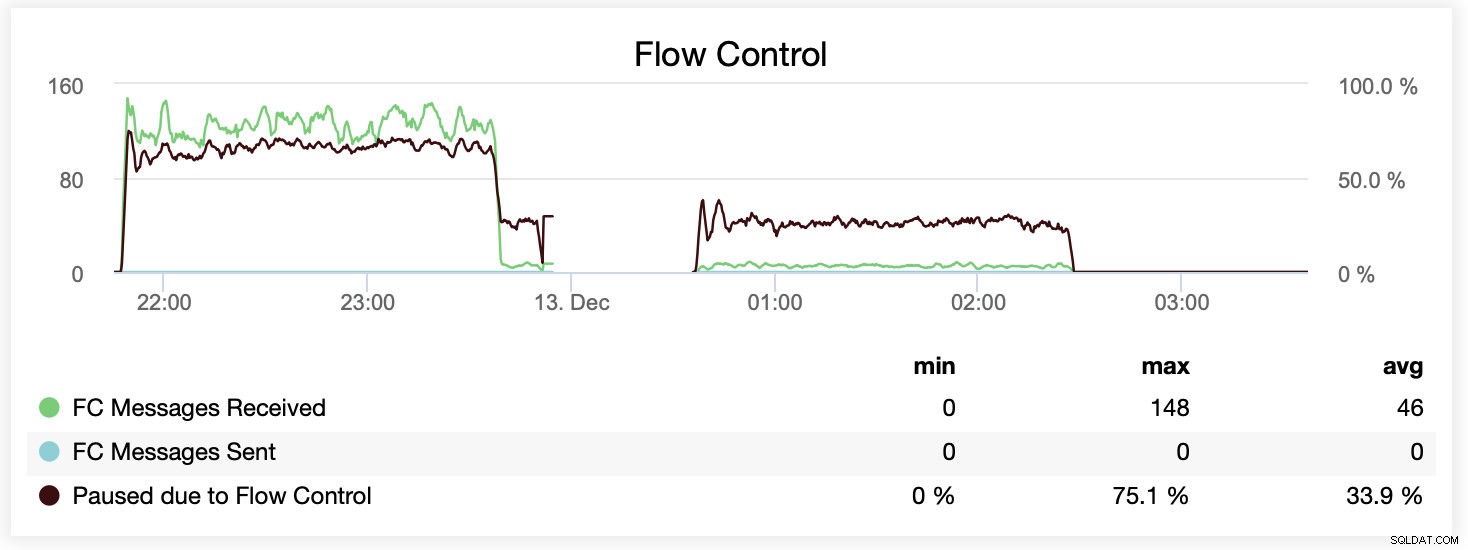
Можете също да сравните разликата на една графика. Отпадането в края на първата част е първият опит за изпълнение с wsrep_slave_threads=16. Сървърите изчерпаха дисковото пространство за двоични регистрационни файлове и трябваше да изпълним този сравнителен тест още веднъж по-късно.
Как се преведе това от гледна точка на производителност? Разликата е видима, но определено не е толкова грандиозна.
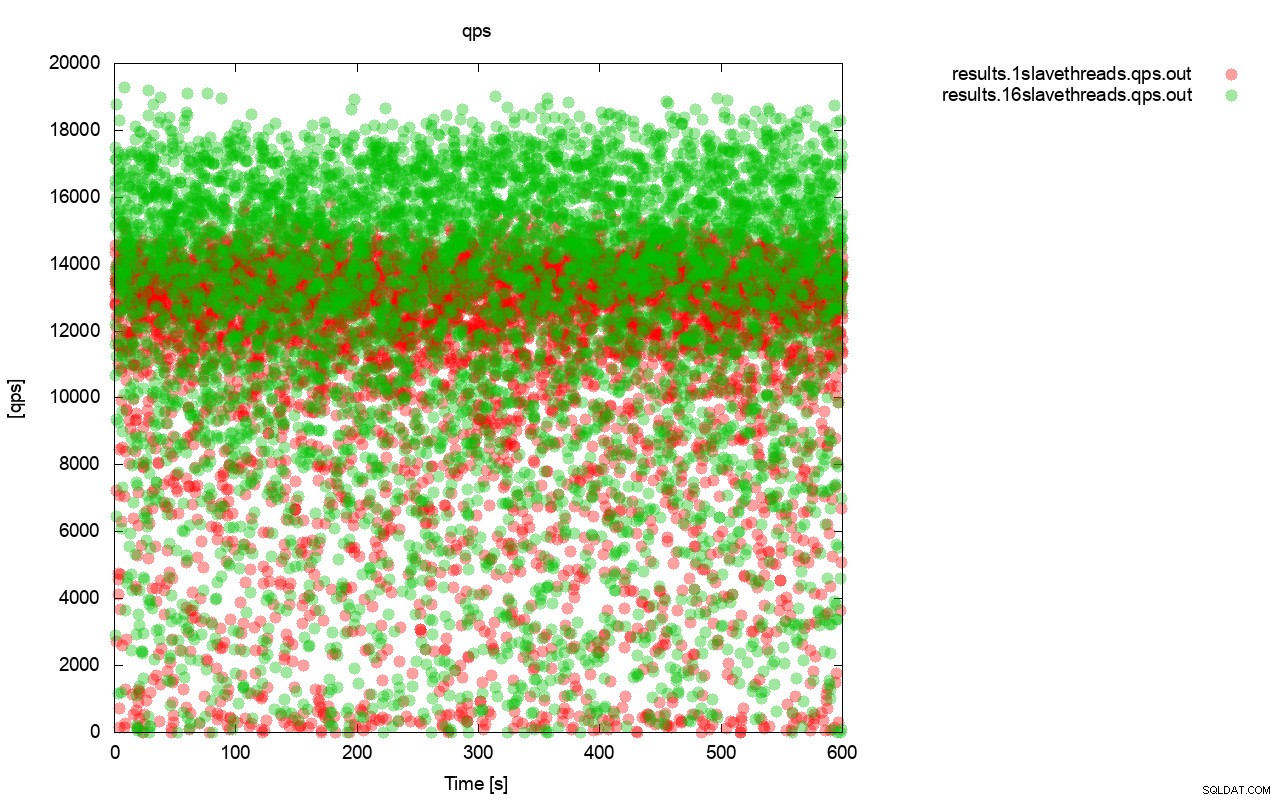
Първо, графиката на заявката за секунда. На първо място, можете да забележите, че и в двата случая резултатите са навсякъде. Това е свързано най-вече с нестабилната производителност на I/O съхранението и контрола на потока, който се включва произволно. Все още можете да видите, че производителността на „червения“ резултат (wsrep_slave_threads=1) е доста по-ниска от „зелената“ ( wsrep_slave_threads=16).
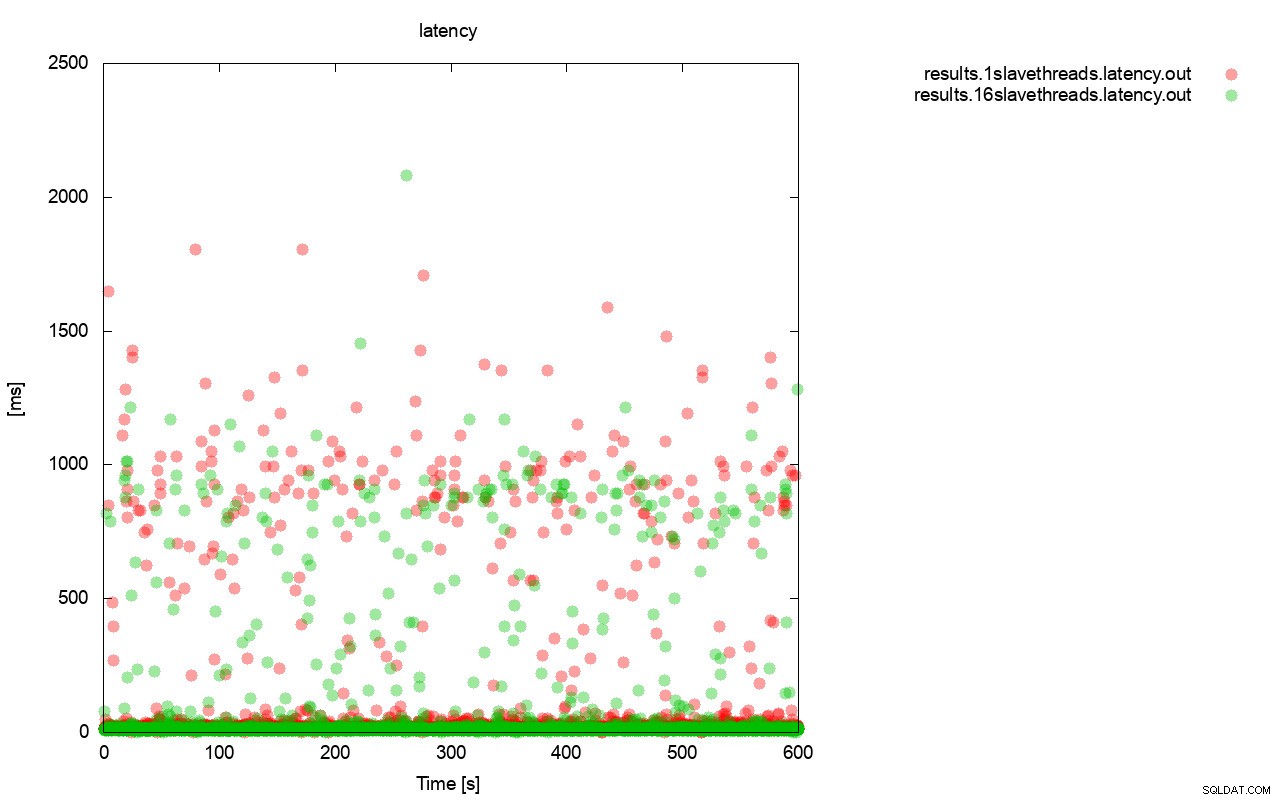
Съвсем подобна картина е, когато погледнем латентността. Можете да видите повече (и обикновено по-дълбоки) застой за тичане с wsrep_slave_thread=1.
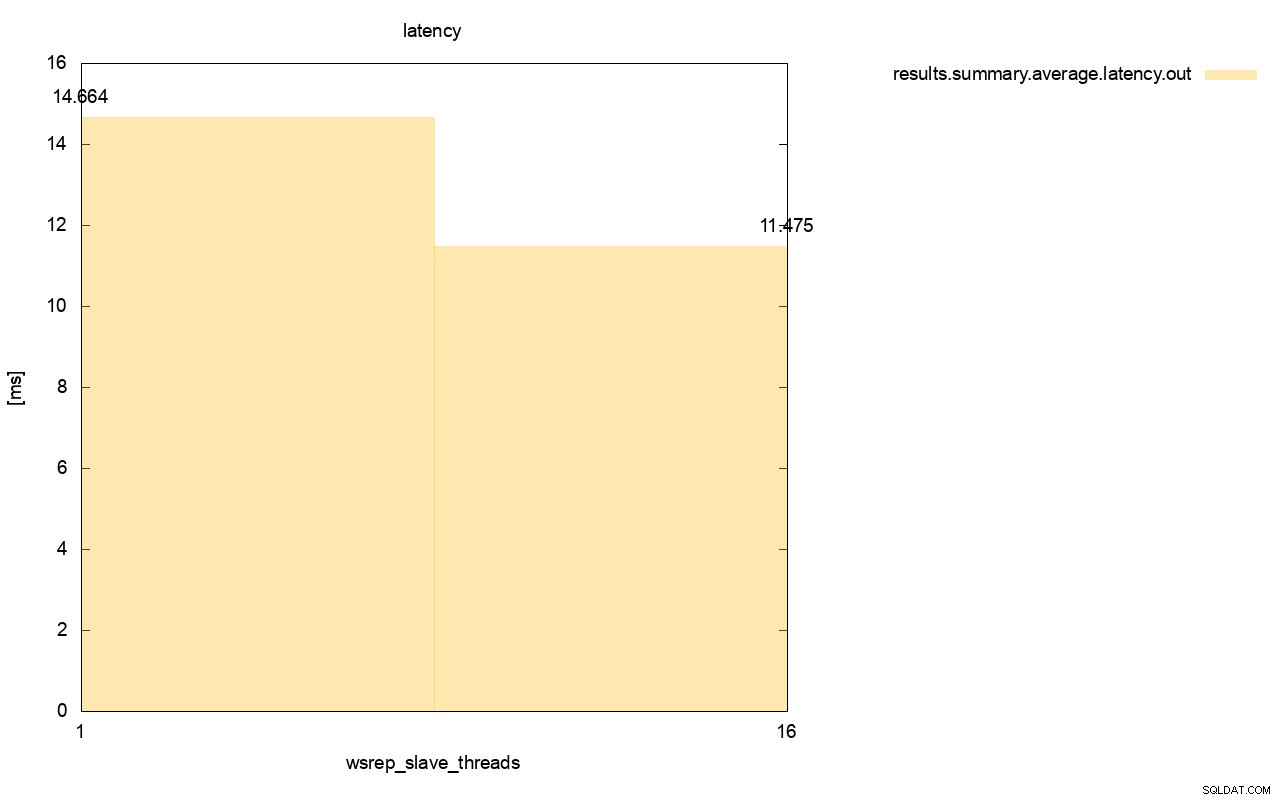
Разликата е още по-видима, когато изчислихме средната латентност за всички изпълнения и можете да видите, че латентността на wsrep_slave_thread=1 е 27% по-висока от латентността с 16 подчинени нишки, което очевидно не е добре, тъй като искаме латентността да бъде по-ниска , не по-високо.
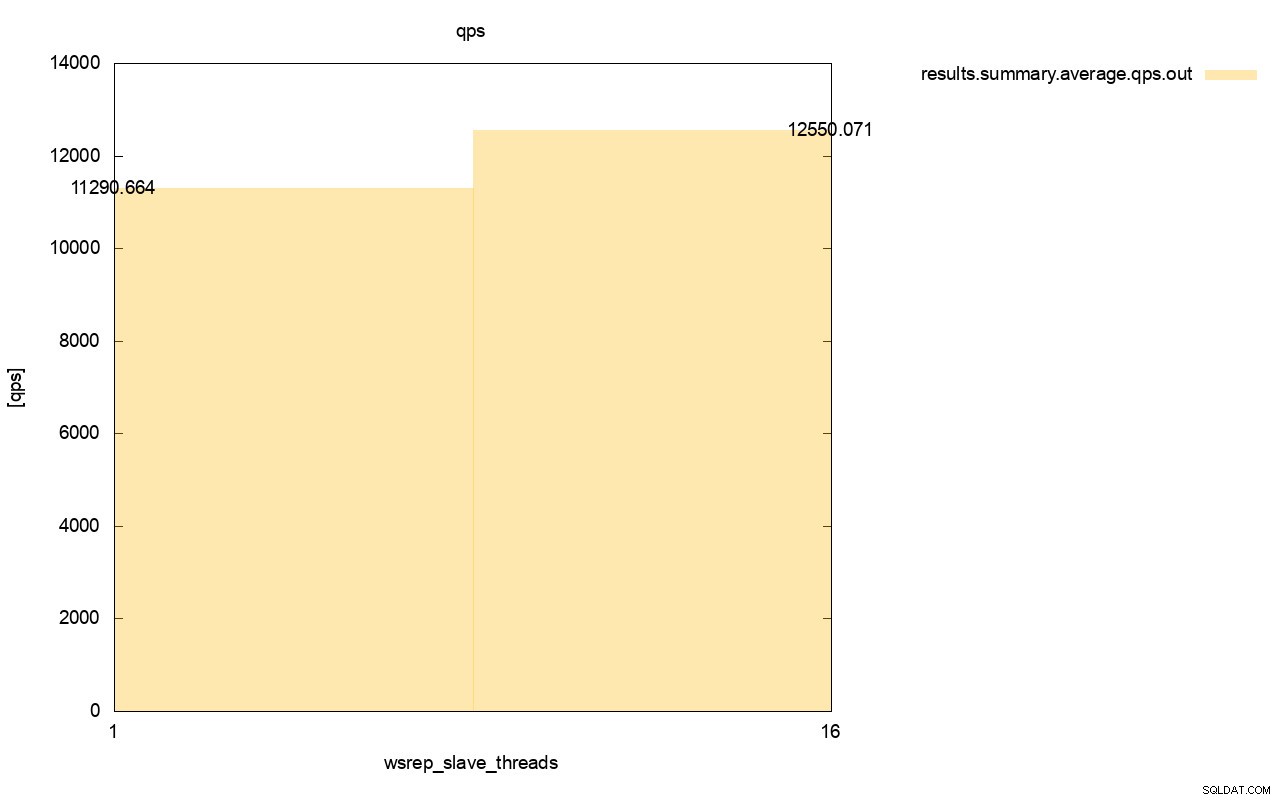
Разликата в пропускателната способност също е видима, около 11% от подобрението, когато добавихме още wsrep_slave_threads.
Както можете да видите, въздействието е налице. Това в никакъв случай не е 16 пъти (дори и ако така увеличихме броя на подчинените нишки в Galera), но определено е достатъчно изпъкнал, за да не можем да го класифицираме като просто статистическа аномалия.
Моля, имайте предвид, че в нашия случай използвахме доста малки възли. Разликата би трябвало да е още по-значителна, ако говорим за големи екземпляри, работещи на EBS томове с хиляди осигурени IOPS.
Тогава ще можем да стартираме sysbench още по-агресивно, с по-голям брой едновременни операции. Това би трябвало да подобри паралелизирането на наборите за запис, подобрявайки още повече печалбата от многонишковостта. Освен това по-бързият хардуер означава, че Galera ще може да използва тези 16 нишки по по-ефективен начин.
Когато провеждате тестове като този, трябва да имате предвид, че трябва да натиснете вашата настройка почти до нейните граници. Еднонишковата репликация може да се справи с доста голямо натоварване и трябва да изпълнявате натоварен трафик, за да го направите не достатъчно производителен, за да се справи със задачата.
Надяваме се, че тази публикация в блога ви дава повече представа за способностите на Galera Cluster да прилага паралелно набори за запис и ограничаващите фактори около това.