Една от страхотните функции в Galera е автоматичното осигуряване на възли и контрол на членството. Ако възелът не успее или загуби комуникация, той автоматично ще бъде изгонен от клъстера и ще остане неработоспособен. Докато по-голямата част от възлите все още комуникират (Galera нарича този компютър - основен компонент), има много голям шанс неуспешният възел да може автоматично да се присъедини отново, да синхронизира отново и да възобнови репликацията, след като връзката се върне.
Като цяло всички възли на Galera са равни. Те притежават същия набор от данни и същата роля като главните, способни да обработват едновременно четене и запис, благодарение на груповата комуникация на Galera и базираната на сертифициране приставка за репликация. Следователно, всъщност няма отказ от гледна точка на базата данни поради това равновесие. Само от страна на приложението, което би изисквало отказ, за да пропуснете неработещите възли, докато клъстерът е разделен.
В тази публикация в блога ще разгледаме как Galera Cluster извършва възстановяване на възли и клъстери в случай, че се случи мрежов дял. Само като странична бележка, ние разгледахме подобна тема в тази публикация в блога преди известно време. Codership обясни концепцията за възстановяване на Galera в много подробности в страницата с документация, Отказ и възстановяване на възел.
Неизправност и изгонване на възел
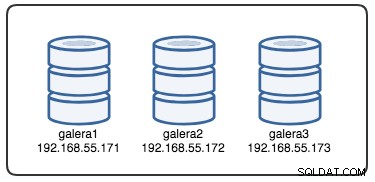
За да разберем възстановяването, трябва да разберем как Galera открива първо повредата на възела и процеса на изгонване. Нека поставим това в контролиран тестов сценарий, за да можем да разберем по-добре процеса на изгонване. Да предположим, че имаме клъстер Galera с три възела, както е илюстрирано по-долу:
Следната команда може да се използва за извличане на опциите на нашия доставчик на Galera:
mysql> SHOW VARIABLES LIKE 'wsrep_provider_options'\GТова е дълъг списък, но просто трябва да се съсредоточим върху някои от параметрите, за да обясним процеса:
evs.inactive_check_period = PT0.5S;
evs.inactive_timeout = PT15S;
evs.keepalive_period = PT1S;
evs.suspect_timeout = PT5S;
evs.view_forget_timeout = P1D;
gmcast.peer_timeout = PT3S;На първо място, Galera следва форматиране по ISO 8601, за да представи продължителност. P1D означава, че продължителността е един ден, докато PT15S означава, че продължителността е 15 секунди (обърнете внимание на обозначението на времето, T, което предхожда стойността на времето). Например, ако някой иска да увеличи evs.view_forget_timeout до 1 ден и половина, човек ще зададе P1DT12H или PT36H.
Като се има предвид, че всички хостове не са конфигурирани с никакви правила за защитна стена, ние използваме следния скрипт, наречен block_galera.sh на galera2 за симулиране на мрежова повреда към/от този възел:
#!/bin/bash
# block_galera.sh
# galera2, 192.168.55.172
iptables -I INPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I INPUT -m tcp -p tcp --dport 3306 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 3306 -j REJECT
# print timestamp
dateЧрез изпълнение на скрипта получаваме следния изход:
$ ./block_galera.sh
Wed Jul 4 16:46:02 UTC 2018Отчетеното времеви печат може да се счита за начало на разделянето на клъстера, при което губим galera2, докато galera1 и galera3 все още са онлайн и достъпни. В този момент нашата архитектура на Galera Cluster изглежда така:
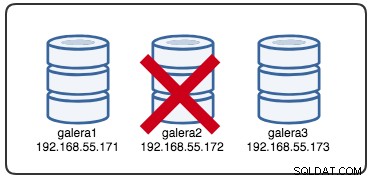
От гледна точка на разделения възел
На galera2 ще видите някои разпечатки в дневника за грешки на MySQL. Нека ги разделим на няколко части. Прекъсването е започнало около 16:46:02 UTC и след gmcast.peer_timeout=PT3S , се появява следното:
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 8b2041d6 with addr tcp://192.168.55.173:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.173:4567
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 737422d6 with addr tcp://192.168.55.171:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 0Тъй като премина evs.suspect_timeout =PT5S , и двата възела galera1 и galera3 са заподозрени като мъртви от galera2:
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 8b2041d6
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactive
2018-07-04 16:46:07 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 0
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspecting node: 737422d6
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveСлед това Galera ще преразгледа текущия изглед на клъстера и позицията на този възел:
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,54) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,55) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})С новия изглед на клъстер, Galera ще извърши изчисляване на кворума, за да реши дали този възел е част от основния компонент. Ако новият компонент види "primary =no", Galera ще понижи състоянието на локалния възел от SYNCED до OPEN:
2018-07-04 16:46:09 140454288942848 [Note] WSREP: New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Flow-control interval: [16, 16]
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Trying to continue unpaused monitor
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Received NON-PRIMARY.
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Shifting SYNCED -> OPEN (TO: 2753699)С последната промяна в изгледа на клъстера и състоянието на възела, Galera връща изгледа на клъстера след изгонване и глобалното състояние, както е по-долу:
2018-07-04 16:46:09 140454222194432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753699, view# -1: non-Primary, number of nodes: 1, my index: 0, protocol version 3
2018-07-04 16:46:09 140454222194432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.Можете да видите следното глобално състояние на galera2 да се е променило през този период:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 1 |
| WSREP_CLUSTER_STATUS | non-Primary |
| WSREP_EVS_DELAYED | 737422d6-7db3-11e8-a2a2-bbe98913baf0:tcp://192.168.55.171:4567:1,8b2041d6-7f62-11e8-87d5-12a76678131f:tcp://192.168.55.173:4567:2 |
| WSREP_LOCAL_STATE_COMMENT | Initialized |
| WSREP_READY | OFF |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+В този момент MySQL/MariaDB сървърът на galera2 все още е достъпен (базата данни слуша на 3306 и Galera на 4567) и можете да направите заявка към системните таблици на mysql и да изброите базите данни и таблиците. Когато обаче скочите в несистемните таблици и направите проста заявка като тази:
mysql> SELECT * FROM sbtest1;
ERROR 1047 (08S01): WSREP has not yet prepared node for application useВеднага ще получите грешка, показваща, че WSREP е зареден, но не е готов за използване от този възел, както се съобщава от wsrep_ready статус. Това се дължи на това, че възелът губи връзката си с първичния компонент и влиза в неработно състояние (статусът на локалния възел е променен от SYNCED на OPEN). Прочетените данни от възли в неработещо състояние се считат за остарели, освен ако не зададете wsrep_dirty_reads=ON за разрешаване на четения, въпреки че Galera все още отхвърля всяка команда, която модифицира или актуализира базата данни.
И накрая, Galera ще продължи да слуша и да се свързва отново с други членове във фонов режим безкрайно:
2018-07-04 16:47:12 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 30
2018-07-04 16:47:13 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 30
2018-07-04 16:48:20 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 60
2018-07-04 16:48:22 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 60Потокът на процеса на изгонване от груповата комуникация на Galera за разделения възел по време на проблем с мрежата може да бъде обобщен по-долу:
- Прекъсва връзката с клъстера след gmcast.peer_timeout .
- Подозира други възли след evs.suspect_timeout .
- Извлича новия клъстерен изглед.
- Извършва изчисляване на кворума, за да определи състоянието на възела.
- Понижава възела от SYNCED до OPEN.
- Опити за повторно свързване с основния компонент (други възли на Galera) във фонов режим.
От гледна точка на първичния компонент
На galera1 и galera3 съответно след gmcast.peer_timeout=PT3S , в регистъра на грешките на MySQL се появява следното:
2018-07-04 16:46:05 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.172:4567
2018-07-04 16:46:06 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') reconnecting to 62116b35 (tcp://192.168.55.172:4567), attempt 0След като премина evs.suspect_timeout =PT5S , galera2 се подозира като мъртъв от galera3 (и galera1):
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 62116b35
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveGalera проверява дали другите възли отговарят на груповата комуникация на galera3, открива, че galera1 е в първично и стабилно състояние:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-04 16:46:11 139955510687488 [Note] WSREP: Node 737422d6 state primGalera ревизира изгледа на клъстера на този възел (galera3):
2018-07-04 16:46:11 139955510687488 [Note] WSREP: view(view_id(PRIM,737422d6,55) memb {
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
62116b35,0
})
2018-07-04 16:46:11 139955510687488 [Note] WSREP: save pc into diskСлед това Galera премахва разделения възел от първичния компонент:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: forgetting 62116b35 (tcp://192.168.55.172:4567)Новият първичен компонент вече се състои от два възела, galera1 и galera3:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 1, memb_num = 2Първичният компонент ще обменя състоянието помежду си, за да се договори за новия изглед на клъстера и глобалното състояние:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-07-04 16:46:11 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: sent state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 0 (192.168.55.171)
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 1 (192.168.55.173)Galera изчислява и проверява кворума на държавния обмен между онлайн членове:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 27,
members = 2/2 (joined/total),
act_id = 2753703,
last_appl. = 2753606,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Flow-control interval: [23, 23]
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Trying to continue unpaused monitorGalera актуализира новия изглед на клъстера и глобалното състояние след изгонването на galera2:
2018-07-04 16:46:11 139955214169856 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753703, view# 28: Primary, number of nodes: 2, my index: 1, protocol version 3
2018-07-04 16:46:11 139955214169856 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-04 16:46:11 139955214169856 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-04 16:46:11 139955214169856 [Note] WSREP: Assign initial position for certification: 2753703, protocol version: 3
2018-07-04 16:46:11 139956691814144 [Note] WSREP: Service thread queue flushed.
Clean up the partitioned node (galera2) from the active list:
2018-07-04 16:46:14 139955510687488 [Note] WSREP: cleaning up 62116b35 (tcp://192.168.55.172:4567)В този момент и galera1, и galera3 ще отчитат подобно глобално състояние:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 2 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | 1491abd9-7f6d-11e8-8930-e269b03673d8:tcp://192.168.55.172:4567:1 |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+------------------------------------------------------------------+Те изброяват проблемния член в wsrep_evs_delayed статус. Тъй като локалното състояние е "Синхронизирано", тези възли работят и можете да пренасочите клиентските връзки от galera2 към всеки от тях. Ако тази стъпка е неудобна, помислете за използването на балансьор на натоварването, разположен пред базата данни, за да опростите крайната точка на връзката от клиентите.
Възстановяване и присъединяване на възел
Разделен възел на Galera ще продължи да се опитва да установи връзка с първичния компонент безкрайно. Нека изчистим правилата на iptables на galera2, за да го оставим да се свърже с останалите възли:
# on galera2
$ iptables -FСлед като възелът е в състояние да се свърже с един от възлите, Galera ще започне автоматично да възстановява груповата комуникация:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 8b2041d6 tcp://192.168.55.173:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 8b2041d6 at tcp://192.168.55.173:4567 stableСлед това възел galera2 ще се свърже с един от първичните компоненти (в този случай е galera1, идентификатор на възел 737422d6), за да получи текущия изглед на клъстера и състоянието на възлите:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: Node 737422d6 state prim
2018-07-09 10:46:34 140075962705664 [Note] WSREP: view(view_id(PRIM,1491abd9,142) memb {
1491abd9,0
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
})
2018-07-09 10:46:34 140075962705664 [Note] WSREP: save pc into diskСлед това Galera ще извърши обмен на състояние с останалите членове, които могат да формират Първичния компонент:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 0, memb_num = 3
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE_EXCHANGE: sent state UUID: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: sent state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 0 (192.168.55.172)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 1 (192.168.55.171)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 2 (192.168.55.173)Държавният обмен позволява на galera2 да изчисли кворума и да произведе следния резултат:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 71,
members = 2/3 (joined/total),
act_id = 2836958,
last_appl. = 0,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bcСлед това Galera ще промотира състоянието на локалния възел от ОТВОРЕНО към ОСНОВНО, за да стартира и установи връзката на възела с основния компонент:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Trying to continue unpaused monitor
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting OPEN -> PRIMARY (TO: 2836958)Както се съобщава от горния ред, Galera изчислява разликата за това колко далеч е възелът от клъстера. Този възел изисква прехвърляне на състояние, за да настигне номер на набор за запис 2836958 от 2761994:
2018-07-09 10:46:34 140075929970432 [Note] WSREP: State transfer required:
Group state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
Local state: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994
2018-07-09 10:46:34 140075929970432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958, view# 72: Primary, number of nodes:
3, my index: 0, protocol version 3
2018-07-09 10:46:34 140075929970432 [Warning] WSREP: Gap in state sequence. Need state transfer.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Assign initial position for certification: 2836958, protocol version: 3Galera подготвя IST слушателя на порт 4568 на този възел и моли всеки Синхронизиран възел в клъстера да стане донор. В този случай Galera автоматично избира galera3 (192.168.55.173) или може също да избере донор от списъка под wsrep_sst_donor (ако е дефинирано) за операцията по синхронизиране:
2018-07-09 10:46:34 140075996276480 [Note] WSREP: Service thread queue flushed.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: IST receiver addr using tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Prepared IST receiver, listening at: tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) requested state transfer from '*any*'. Selected 2.0 (192.168.55.173)(SYNCED) as donor.След това ще промени състоянието на локалния възел от PRIMARY на JOINER. На този етап galera2 получава заявка за прехвърляне на състояние и започва да кешира набори за запис:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting PRIMARY -> JOINER (TO: 2836958)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Requesting state transfer: success, donor: 2
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache history reset: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994 -> 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache DEBUG: RingBuffer::seqno_reset(): full resetВъзел galera2 започва да получава липсващите набори за запис от gcache на избрания донор (galera3):
2018-07-09 10:46:34 140075954312960 [Note] WSREP: 2.0 (192.168.55.173): State transfer to 0.0 (192.168.55.172) complete.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Receiving IST: 74964 writesets, seqnos 2761994-2836958
2018-07-09 10:46:34 140075593627392 [Note] WSREP: Receiving IST... 0.0% ( 0/74964 events) complete.
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 2.0 (192.168.55.173) synced with group.
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:41 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-09 10:46:44 140075593627392 [Note] WSREP: Receiving IST... 36.0% (27008/74964 events) complete.
2018-07-09 10:46:54 140075593627392 [Note] WSREP: Receiving IST... 71.6% (53696/74964 events) complete.
2018-07-09 10:47:02 140075593627392 [Note] WSREP: Receiving IST...100.0% (74964/74964 events) complete.
2018-07-09 10:47:02 140075929970432 [Note] WSREP: IST received: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:47:02 140075954312960 [Note] WSREP: 0.0 (192.168.55.172): State transfer from 2.0 (192.168.55.173) complete.След като всички липсващи набори за запис бъдат получени и приложени, Galera ще популяризира galera2 като ПРИСЪЕДИНЕНИ до сек. 2837012:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINER -> JOINED (TO: 2837012)
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) synced with group.Възелът прилага всички кеширани набори за запис в своята подчинена опашка и завършва настигането на клъстера. Неговата подчинена опашка вече е празна. Galera ще популяризира galera2 до SYNCED, което показва, че възелът вече работи и е готов да обслужва клиенти:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINED -> SYNCED (TO: 2837012)
2018-07-09 10:47:02 140076605892352 [Note] WSREP: Synchronized with group, ready for connectionsВ този момент всички възли отново работят. Можете да потвърдите, като използвате следните изявления на galera2:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+----------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+----------------+
| WSREP_CLUSTER_SIZE | 3 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+----------------+wsrep_cluster_size отчетено като 3 и статусът на клъстера е Основен, което показва, че galera2 е част от първичния компонент. wsrep_evs_delayed също е изчистено и местното състояние вече е синхронизирано.
Потокът на процеса на възстановяване за разделения възел по време на мрежов проблем може да бъде обобщен по-долу:
- Възстановява груповата комуникация с други възли.
- Извлича изгледа на клъстера от един от основните компоненти.
- Извършва обмен на състояния с основния компонент и изчислява кворума.
- Променя състоянието на локалния възел от ОТВОРЕНО на ОСНОВНО.
- Изчислява разликата между локалния възел и клъстера.
- Променя състоянието на локалния възел от PRIMARY на JOINER.
- Подготвя IST слушател/приемник на порт 4568.
- Заявява прехвърляне на състоянието чрез IST и избира донор.
- Започва да получава и прилага липсващия набор за запис от gcache на избран донор.
- Променя състоянието на локалния възел от JOINER на JOINED.
- Настига клъстера, като прилага кешираните набори за запис в подчинената опашка.
- Променя състоянието на локалния възел от JOINED на SYNCED.
Отказ на клъстера
Galera Cluster се счита за неуспешен, ако няма наличен основен компонент (PC). Помислете за подобен клъстер Galera с три възела, както е показано на диаграмата по-долу:
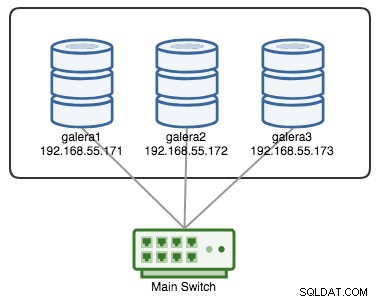
Един клъстер се счита за действащ, ако всички възли или по-голямата част от възлите са онлайн. Онлайн означава, че те могат да се виждат чрез трафика за репликация на Galera или груповата комуникация. Ако не влиза и излиза трафик от възела, клъстерът ще изпрати сигнал за пулсиране на възела, за да отговори своевременно. В противен случай той ще бъде поставен в списъка за забавяне или подозрения в зависимост от това как възелът реагира.
Ако възелът падне, да кажем възел C, клъстерът ще остане оперативен, тъй като възел A и B все още са в кворум с 2 от 3 гласа, за да образуват първичен компонент. Трябва да получите следното състояние на клъстера на A и B:
mysql> SHOW STATUS LIKE 'wsrep_cluster_status';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| wsrep_cluster_status | Primary |
+----------------------+---------+Ако да кажем, че първичният превключвател е бил капут, както е показано на следната диаграма:
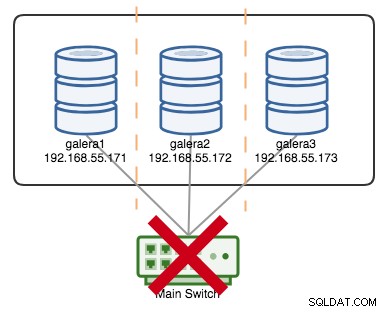
В този момент всеки отделен възел губи комуникация помежду си и състоянието на клъстера ще бъде отчетено като неосновно на всички възли (както се случи с galera2 в предишния случай). Всеки възел ще изчисли кворума и ще открие, че това е малцинството (1 глас от 3), което губи кворума, което означава, че не се формира първичен компонент и следователно всички възли отказват да обслужват каквито и да било данни. Това се счита за повреда на клъстера.
След като проблемът с мрежата бъде разрешен, Galera автоматично ще възстанови комуникацията между членовете, ще обмени състоянията на възлите и ще определи възможността за реформиране на основния компонент чрез сравняване на състоянието на възела, UUID и seqnos. Ако вероятността е налице, Galera ще обедини основните компоненти, както е показано в следните редове:
2018-06-27 0:16:57 140203784476416 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 2, memb_num = 3
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: sent state msg: 5885911b-795c-11e8-8683-931c85442c7e
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 0 (192.168.55.171)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 1 (192.168.55.172)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 2 (192.168.55.173)
2018-06-27 0:16:57 140203784476416 [Warning] WSREP: Quorum: No node with complete state:
Version : 4
Flags : 0x3
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.171'
Incoming addr: '192.168.55.171:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.172'
Incoming addr: '192.168.55.172:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.173'
Incoming addr: '192.168.55.173:3306'
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Full re-merge of primary 5224a024-791b-11e8-a0ac-8bc6118b0f96 found: 3 of 3.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 5,
members = 3/3 (joined/total),
act_id = 112725,
last_appl. = 112722,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Flow-control interval: [28, 28]
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Trying to continue unpaused monitor
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Restored state OPEN -> SYNCED (112725)
2018-06-27 0:16:57 140202564110080 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:112725, view# 6: Primary, number of nodes: 3, my index: 2, protocol version 3A good indicator to know if the re-bootstrapping process is OK is by looking at the following line in the error log:
[Note] WSREP: Synchronized with group, ready for connectionsClusterControl Auto Recovery
ClusterControl comes with node and cluster automatic recovery features, because it oversees and understands the state of all nodes in the cluster. Automatic recovery is by default enabled if the cluster is deployed using ClusterControl. To enable or disable the cluster, simply clicking on the power icon in the summary bar as shown below:

Green icon means automatic recovery is turned on, while red is the opposite. You can monitor the recovery progress from the Activity -> Jobs dialog, like in this case, galera2 was totally inaccessible due to firewall blocking, thus forcing ClusterControl to report the following:
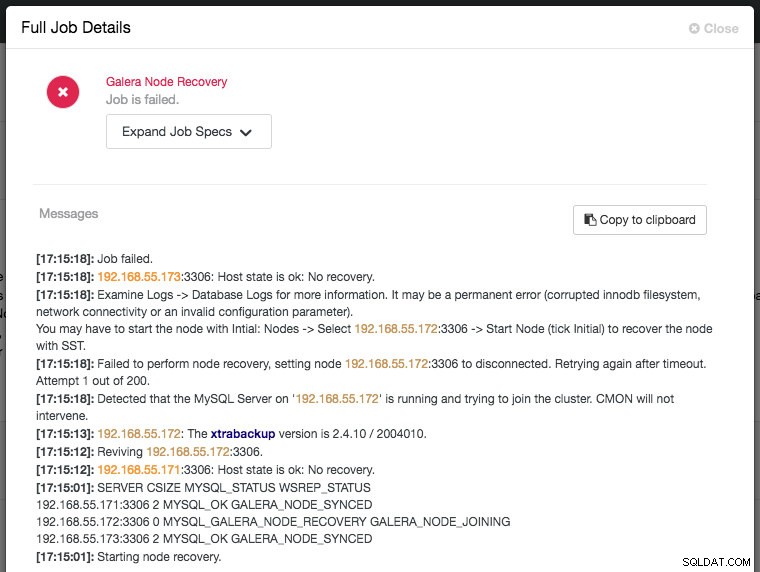
The recovery process will only be commencing after a graceful timeout (30 seconds) to give Galera node a chance to recover itself beforehand. If ClusterControl fails to recover a node or cluster, it will first pull all MySQL error logs from all accessible nodes and will raise the necessary alarms to notify the user via email or by pushing critical events to the third-party integration modules like PagerDuty, VictorOps or Slack. Manual intervention is then required. For Galera Cluster, ClusterControl will keep on trying to recover the failure until you mark the node as under maintenance, or disable the automatic recovery feature.
ClusterControl's automatic recovery is one of most favorite features as voted by our users. It helps you to take the necessary actions quickly, with a complete report on what has been attempted and recommendation steps to troubleshoot further on the issue. For users with support subscriptions, you can look for extra hands by escalating this issue to our technical support team for assistance.
Заключение
Galera automatic node recovery and membership control are neat features to simplify the cluster management, improve the database reliability and reduce the risk of human error, as commonly haunting other open-source database replication technology like MySQL Replication, Group Replication and PostgreSQL Streaming/Logical Replication.