Понякога е трудно да се управлява голямо количество данни в една компания, особено с експоненциалното увеличение на анализа на данни и използването на интернет на нещата. В зависимост от размера, това количество данни може да повлияе на производителността на вашите системи и вероятно ще трябва да мащабирате своите бази данни или да намерите начин да поправите това. Има различни начини за мащабиране на вашите PostgreSQL бази данни и един от тях е Sharding. В този блог ще видим какво представлява Sharding и как да го конфигурирате в PostgreSQL с помощта на ClusterControl за опростяване на задачата.
Какво е Sharding?
Разделянето е действието по оптимизиране на база данни чрез разделяне на данни от голяма таблица на множество малки. По-малките таблици са сегменти (или дялове). Разделянето и разделянето са подобни понятия. Основната разлика е, че разделянето предполага, че данните се разпространяват между множество компютри, докато разделянето е свързано с групиране на подмножества от данни в рамките на един екземпляр на базата данни.
Има два типа раздробяване:
-
Хоризонтално разделяне:Всяка нова таблица има същата схема като голямата таблица, но уникални редове. Полезно е, когато заявките са склонни да връщат подмножество от редове, които често са групирани заедно.
-
Вертикално разделяне:Всяка нова таблица има схема, която е подмножество от схемата на оригиналната таблица. Полезно е, когато заявките връщат само подмножество от колони от данни.
Нека видим пример:
Оригинална таблица
| ID | Име | Възраст | Държава |
|---|---|---|---|
| 1 | Джеймс Смит | 26 | САЩ |
| 2 | Мери Джонсън | 31 | Германия |
| 3 | Робърт Уилямс | 54 | Канада |
| 4 | Дженифър Браун | 47 | Франция |
Вертикално разделяне
| Shard1 | Shard2 | |||
|---|---|---|---|---|
| ID | Име | Възраст | ID | Държава |
| 1 | Джеймс Смит | 26 | 1 | САЩ |
| 2 | Мери Джонсън | 31 | 2 | Германия |
| 3 | Робърт Уилямс | 54 | 3 | Канада |
| 4 | Дженифър Браун | 47 | 4 | Франция |
Хоризонтално разделяне
| Shard1 | Shard2 | ||||||
|---|---|---|---|---|---|---|---|
| ID | Име | Възраст | Държава | ИД | Име | Възраст | Държава |
| 1 | Джеймс Смит | 26 | САЩ | 3 | Робърт Уилямс | 54 | Канада |
| 2 | Мери Джонсън | 31 | Германия | 4 | Дженифър Браун | 47 | Франция |
Сега, когато прегледахме някои концепции за разделяне, нека преминем към следващата стъпка.
Как да внедря PostgreSQL клъстер?
Ще използваме ClusterControl за тази задача. Ако все още не използвате ClusterControl, можете да го инсталирате и да разположите или импортирате текущата си PostgreSQL база данни, като изберете опцията „Импортиране“ и следвайте стъпките, за да се възползвате от всички функции на ClusterControl като архивиране, автоматично преминаване при отказ, сигнали, наблюдение и др. .
За да извършите внедряване от ClusterControl, просто изберете опцията „Внедряване“ и следвайте инструкциите, които се появяват.
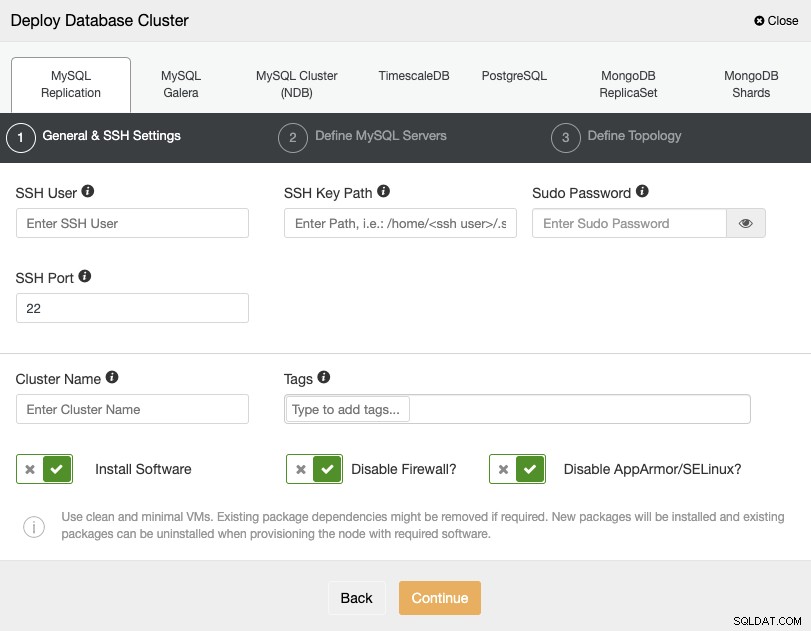
Когато избирате PostgreSQL, трябва да посочите своя потребител, ключ или парола и Порт за свързване чрез SSH към вашите сървъри. Можете също да добавите име за новия си клъстер и ако желаете, можете също да използвате ClusterControl, за да инсталирате съответния софтуер и конфигурации вместо вас.
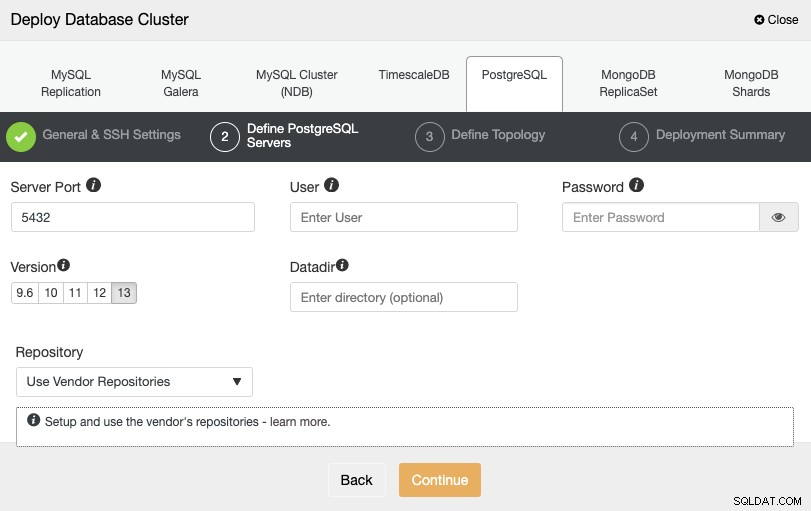
След като настроите информацията за SSH достъп, трябва да дефинирате идентификационните данни за базата данни , версия и datadir (по избор). Можете също да посочите кое хранилище да използвате.
За следващата стъпка трябва да добавите вашите сървъри към клъстера, който ще създадете, използвайки IP адреса или името на хоста.
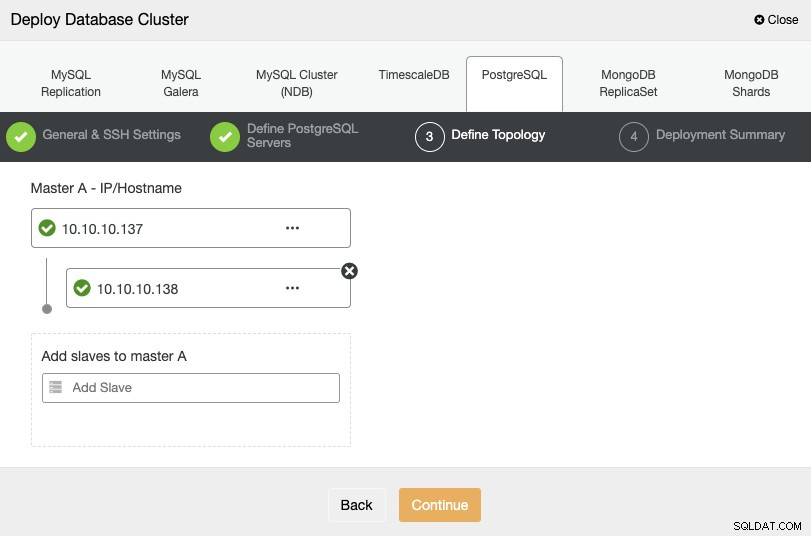
В последната стъпка можете да изберете дали репликацията ви ще бъде синхронна или Асинхронно и след това просто натиснете „Разгръщане“.
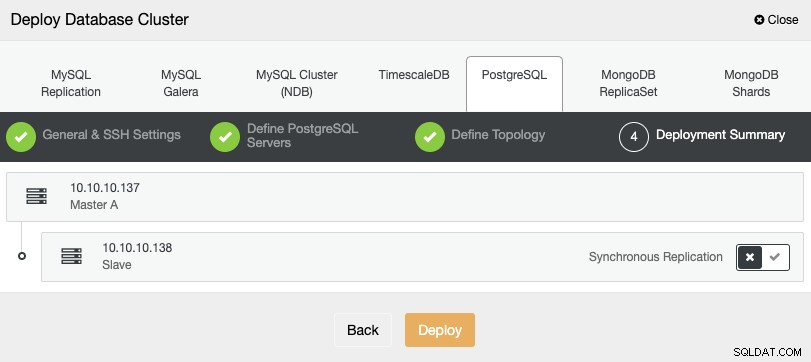
След като задачата приключи, ще видите новия си PostgreSQL клъстер в главен екран на ClusterControl.

Сега, след като създадете своя клъстер, можете да изпълнявате няколко задачи върху него като добавяне на балансьор на натоварване (HAProxy), пул за свързване (pgBouncer) или нова реплика.
Повторете процеса, за да имате поне два отделни PostgreSQL клъстера, за да конфигурирате Sharding, което е следващата стъпка.
Как да конфигурирам PostgreSQL Sharding?
Сега ще конфигурираме Sharding чрез PostgreSQL дялове и Foreign Data Wrapper (FDW). Тази функционалност позволява на PostgreSQL да има достъп до данни, съхранявани в други сървъри. Това е разширение, достъпно по подразбиране в общата инсталация на PostgreSQL.
Ще използваме следната среда:
Servers: Shard1 - 10.10.10.137, Shard2 - 10.10.10.138
Database User: admindb
Table: customersЗа да активирате разширението FDW, просто трябва да изпълните следната команда във вашия основен сървър, в този случай Shard1:
postgres=# CREATE EXTENSION postgres_fdw;
CREATE EXTENSIONСега нека създадем таблицата, която клиентите са разделени по дата на регистрация:
postgres=# CREATE TABLE customers (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL
)
PARTITION BY RANGE (registered);И следните дялове:
postgres=# CREATE TABLE customers_2021
PARTITION OF customers
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
postgres=# CREATE TABLE customers_2020
PARTITION OF customers
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');Тези дялове са местни. Сега нека вмъкнем някои тестови стойности и да ги проверим:
postgres=# INSERT INTO customers (id, name, registered) VALUES (1, 'James', '2020-05-01');
postgres=# INSERT INTO customers (id, name, registered) VALUES (2, 'Mary', '2021-03-01');Тук можете да направите заявка към главния дял, за да видите всички данни:
postgres=# SELECT * FROM customers;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(2 rows)Или дори потърсете съответния дял:
postgres=# SELECT * FROM customers_2021;
id | name | registered
----+------+------------
2 | Mary | 2021-03-01
(1 row)
postgres=# SELECT * FROM customers_2020;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
(1 row)
Както можете да видите, данните бяха вмъкнати в различни дялове, според датата на регистрация. Сега, в отдалечения възел, в този случай Shard2, нека създадем друга таблица:
postgres=# CREATE TABLE customers_2019 (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL);Трябва да създадете този сървър Shard2 в Shard1 по този начин:
postgres=# CREATE SERVER shard2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '10.10.10.138', dbname 'postgres');И потребителят за достъп до него:
postgres=# CREATE USER MAPPING FOR admindb SERVER shard2 OPTIONS (user 'admindb', password 'Passw0rd');Сега създайте ЧУЖДА ТАБЛИЦА в Shard1:
postgres=# CREATE FOREIGN TABLE customers_2019
PARTITION OF customers
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01')
SERVER shard2;И нека вмъкнем данни в тази нова отдалечена таблица от Shard1:
postgres=# INSERT INTO customers (id, name, registered) VALUES (3, 'Robert', '2019-07-01');
INSERT 0 1
postgres=# INSERT INTO customers (id, name, registered) VALUES (4, 'Jennifer', '2019-11-01');
INSERT 0 1Ако всичко е минало добре, трябва да имате достъп до данните както от Shard1, така и от Shard2:
Shard1:
postgres=# SELECT * FROM customers;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(4 rows)
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Shard2:
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Това е. Сега използвате Sharding във вашия PostgreSQL клъстер.
Заключение
Разделянето и разделянето в PostgreSQL са добри характеристики. Помага ви в случай, че трябва да разделите данните в голяма таблица, за да подобрите производителността или дори да изчистите данните по лесен начин, наред с други ситуации. Важен момент, когато използвате Sharding, е да изберете добър ключ за шард, който разпределя данните между възлите по най-добрия начин. Освен това можете да използвате ClusterControl, за да опростите внедряването на PostgreSQL и да се възползвате от някои функции като наблюдение, предупреждение, автоматично преминаване при отказ, архивиране, възстановяване в момент и други.