В предишната си статия започнах нова серия за ключалки, като обясних какво представляват, защо са необходими и механиката на това как работят, и силно препоръчвам да прочетете тази статия преди тази. В тази статия ще обсъдя ключалката FGCB_ADD_REMOVE и ще покажа как тя може да бъде пречка.
Какво е ключалката FGCB_ADD_REMOVE?
Повечето имена на фиксиращи класове са обвързани директно със структурата на данните, която защитават. Резето FGCB_ADD_REMOVE защитава структура от данни, наречена FGCB или контролен блок на файлова група и ще има едно от тези ключалки за всяка онлайн файлова група от всяка онлайн база данни в екземпляр на SQL Server. Всеки път, когато файл във файлова група се добавя, пуска, увеличава или свива, фиксаторът трябва да бъде придобит в режим EX и когато се измисля следващия файл, от който да се разпредели, фиксаторът трябва да бъде придобит в режим SH, за да се предотвратят всякакви промени в файловата група. (Не забравяйте, че разпределянето на обхват за файлова група се извършва на кръгова база чрез файловете във файловата група и също така вземете предвид пропорционалното запълване , което обяснявам тук.)
Как резето се превръща в тесно място?
Най-често срещаният сценарий, когато това ключалка се превърне в тесно място, е както следва:
- Има еднофайлова база данни, така че всички разпределения трябва да идват от този един файл с данни
- Настройката за автоматично нарастване за файла е настроена да бъде много малка (не забравяйте, че преди SQL Server 2016 настройката за автоматично нарастване по подразбиране за файловете с данни беше 1 MB!)
- Има много едновременни операции, изискващи разпределяне на пространство (напр. постоянно натоварване за вмъкване от много клиентски връзки)
В този случай, въпреки че има само един файл, нишка, изискваща разпределение, все още трябва да придобие ключалката FGCB_ADD_REMOVE в режим SH. След това ще се опита да разпредели от единичния файл с данни, ще разбере, че няма място, и след това ще придобие ключалката в режим EX, за да може след това да увеличи файла.
Нека си представим, че осем нишки, работещи на осем отделни планировчици, се опитват да разпределят едновременно и всички осъзнават, че няма място във файла, така че трябва да го разширят. Всеки от тях ще се опита да придобие ключалката в режим EX. Само един от тях ще може да го получи и той ще продължи да увеличава файла, а останалите ще трябва да изчакат, с тип на изчакване LATCH_EX и описание на ресурса FGCB_ADD_REMOVE плюс адреса на паметта на ключалката.
Седемте чакащи нишки са в опашката за изчакване „първи влязъл-първи излязъл“ (FIFO) на ключалката. Когато нишката, извършваща растежа на файла, приключи, тя освобождава фиксатора и го предоставя на първата чакаща нишка. Този нов собственик на ключалката отива да разшири файла и открива, че той вече е нараснал и няма какво да прави. Така той освобождава фиксатора и го предоставя на следващата чакаща нишка. И така нататък.
Всичките седем чакащи нишки чакаха фиксатора в режим EX, но в крайна сметка не правеха нищо, след като им беше предоставено фиксаторът, така че всичките седем нишки по същество губиха изминало време, като количеството на губеното време се увеличава малко за всяка нишка по-надолу опашката за изчакване на FIFO беше.
Показва се тесното място
Сега ще ви покажа точния сценарий по-горе, използвайки разширени събития. Създадох база данни с един файл с малка настройка за автоматично нарастване и стотици едновременни връзки, които просто вмъкват данни в таблица.
Мога да използвам следната разширена сесия за събитие, за да видя какво се случва:
-- Drop the session if it exists.
IF EXISTS
(
SELECT * FROM sys.server_event_sessions
WHERE [name] = N'FGCB_ADDREMOVE'
)
BEGIN
DROP EVENT SESSION [FGCB_ADDREMOVE] ON SERVER;
END
GO
CREATE EVENT SESSION [FGCB_ADDREMOVE] ON SERVER
ADD EVENT [sqlserver].[database_file_size_change]
(WHERE [file_type] = 0), -- data files only
ADD EVENT [sqlserver].[latch_suspend_begin]
(WHERE [class] = 48 AND [mode] = 4), -- EX mode
ADD EVENT [sqlserver].[latch_suspend_end]
(WHERE [class] = 48 AND [mode] = 4) -- EX mode
ADD TARGET [package0].[ring_buffer]
WITH (TRACK_CAUSALITY = ON);
GO
-- Start the event session
ALTER EVENT SESSION [FGCB_ADDREMOVE]
ON SERVER STATE = START;
GO Сесията се проследява, когато нишка навлезе в опашката за изчакване на ключалката, кога напусне опашката (т.е. когато й е предоставено заключване) и когато настъпи нарастване на файла с данни. Използването на проследяване на причинно-следствената връзка означава, че можем да видим времева линия на действията от всяка нишка.
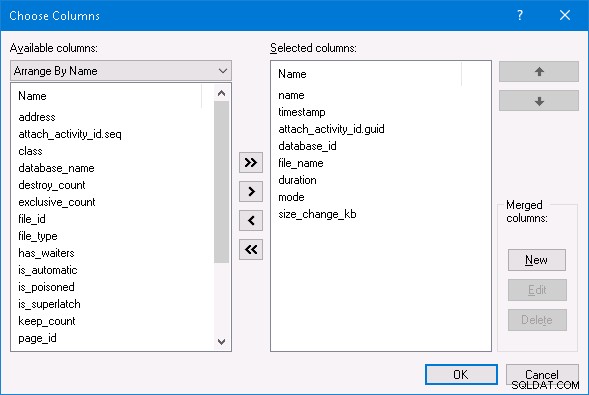
Използвайки SQL Server Management Studio, мога да избера опцията Гледайте данни на живо за разширената сесия на събитието и да видя цялата разширена активност на събитията. Ако искате да направите същото, в прозореца Live Data щракнете с десния бутон върху едно от имената на колоните в горната част и променете избраните колони, за да бъдат както следва:
Оставих натоварването да работи за няколко минути, за да достигне стабилно състояние и след това видях перфектен пример за сценария, който описах по-горе:
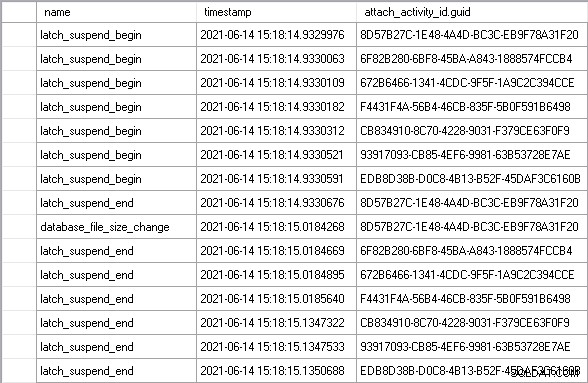
Използване на attach_activity_id.guid стойности за идентифициране на различни нишки, можем да видим, че седем нишки започват да чакат за фиксатор в рамките на 61,5 микросекунди. Нишката със стойността на GUID, започваща 8D57, придобива фиксатора в режим EX (latch_suspend_end събитие) и след това незабавно увеличава файла (database_file_size_change събитие). След това нишката 8D57 освобождава фиксатора и го предоставя в режим EX на нишката 6F82, която изчака 85 милисекунди. Той няма нищо общо, така че предоставя ключалката на нишката 672B. И така нататък, докато нишката EDB8 не получи фиксатор, след като изчака 202 милисекунди.
Общо шестте нишки, които чакаха без причина, чакаха почти 1 секунда. Част от това време е времето за изчакване на сигнала, при което въпреки че на нишката е предоставено заключване, тя все още трябва да се придвижи до върха на опашката за изпълнение на планировчика, преди да може да влезе в процесора и да изпълни код. Може да кажете, че това не е справедлива мярка за времето, прекарано в чакане на ключалката, но е абсолютно така, защото времето за изчакване на сигнала нямаше да бъде настъпило, ако нишката не беше трябвало да чака на първо място.
Освен това може да си помислите, че забавянето от 200 милисекунди не е толкова много, но всичко зависи от споразуменията за ниво на обслужване на производителността за въпросното работно натоварване. Имаме множество клиенти с голям обем, при които ако изпълнението на партида отнема повече от 200 милисекунди, това не е разрешено в производствената система!
Резюме
Ако наблюдавате изчакванията на вашия сървър и забележите, че LATCH_EX е едно от най-големите изчаквания, можете да използвате кода в тази публикация, така че вижте дали FGCB_ADD_REMOVE е един от виновниците.
Най-лесният начин да се уверите, че работното ви натоварване не удря тесното място на FGCB_ADD_REMOVE, е да се уверите, че няма настройки за автоматично нарастване на файлове с данни, които са конфигурирани с помощта на настройките по подразбиране преди SQL Server 2016. В sys.master_files изглед, 1MB по подразбиране ще се покаже като файл с данни (type_desc колона, зададена на ROWS) с is_percent_growth колоната е зададена на 0, а колоната за растеж е зададена на 128.
Даването на препоръка за това какво трябва да бъде автоматичното нарастване е съвсем друга дискусия, но сега знаете за потенциално въздействие върху производителността от непромяната на настройките по подразбиране в по-ранните версии.