Един от случаите на използване на филтриран индекс, споменати в Books Online, се отнася до колона, която съдържа предимно NULLs стойности. Идеята е да се създаде филтриран индекс, който изключва NULLs , което води до по-малък неклъстериран индекс, който изисква по-малко поддръжка от еквивалентния нефилтриран индекс. Друго популярно използване на филтрирани индекси е филтрирането на NULLs от UNIQUE индекс, даващ поведението, което потребителите на други машини за бази данни могат да очакват от UNIQUE по подразбиране индекс или ограничение:уникалността се прилага само за не-NULLs стойности.
За съжаление, оптимизаторът на заявки има ограничения по отношение на филтрираните индекси. Тази публикация разглежда няколко по-малко известни примера.
Примерни таблици
Ще използваме две таблици (A и B), които имат една и съща структура:сурогатен клъстериран първичен ключ, предимно NULLs колона, която е уникална (без внимание на NULLs ) и колона за допълване, която представлява другите колони, които може да са в реална таблица.
Колоната, която представлява интерес е предимно-NULLs един, който съм декларирал като SPARSE . Рядката опция не е задължителна, просто я включвам, защото нямам много шанс да я използвам. Във всеки случай SPARSE вероятно има смисъл в много сценарии, при които се очаква данните в колоната да бъдат предимно NULLs . Чувствайте се свободни да премахнете атрибута sparse от примерите, ако желаете.
CREATE TABLE dbo.TableA( pk integer IDENTITY PRIMARY KEY, data bigint SPARSE NULL, padding binary(250) NOT NULL DEFAULT 0x); CREATE TABLE dbo.TableB( pk integer IDENTITY PRIMARY KEY, data bigint SPARSE NULL, padding binary(250) NOT NULL DEFAULT 0x);
Всяка таблица съдържа числата от 1 до 2000 в колоната с данни с допълнителни 40 000 реда, където колоната с данни е NULLs :
-- Числа 1 - 2,000 INSERT dbo.TableA WITH (TABLOCKX) (data)SELECT TOP (2000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL))FROM sys.columns КАТО cCROSS JOIN sys.columns КАТО c2ORDERBY ROW_NUMBER() НАД (ПОРЪЧАЙТЕ ПО (ИЗБЕРЕТЕ NULL)); -- NULLsINSERT TOP (40000) dbo.TableA WITH (TABLOCKX) (data)SELECT CONVERT(bigint, NULL)FROM sys.columns КАТО cCROSS JOIN sys.columns КАТО c2; -- Копирайте в TableBINSERT dbo.TableB WITH (TABLOCKX) (data)SELECT ta.dataFROM dbo.TableA AS ta;
И двете таблици получават UNIQUE филтриран индекс за 2000 не-NULLs стойности на данните:
СЪЗДАЙТЕ УНИКАЛЕН НЕКЛУСТРИРАН ИНДЕКС uqAON dbo.TableA (данни) КЪДЕТО данните НЕ СА NULL; СЪЗДАЙТЕ УНИКАЛЕН НЕКЛУСТРИРАН ИНДЕКС uqBON dbo.TableB (данни), КЪДЕТО данните НЕ СА NULL;
Изходът на DBCC SHOW_STATISTICS обобщава ситуацията:
DBCC SHOW_STATISTICS (TableA, uqA) С STAT_HEADER;DBCC SHOW_STATISTICS (TableB, uqB) С STAT_HEADER;

Примерна заявка
Заявката по-долу извършва просто свързване на двете таблици – представете си, че таблиците са в някаква връзка родител-дете и много от външните ключове са NULL. Все пак нещо в този смисъл.
ИЗБЕРЕТЕ ta.data, tb.dataFROM dbo.TableA КАТО taJOIN dbo.TableB AS tb ON ta.data =tb.data;
План за изпълнение по подразбиране
С SQL Server в неговата конфигурация по подразбиране, оптимизаторът избира план за изпълнение, включващ присъединяване на паралелно вложени цикли:
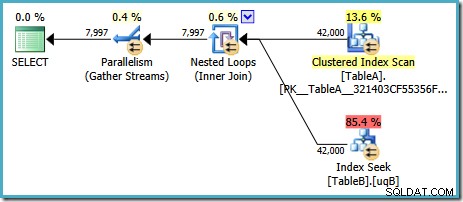
Този план е с приблизителна цена от 7,7768 magic optimizer units™.
В този план обаче има някои странни неща. Търсенето на индекс използва нашия филтриран индекс в таблица B, но заявката се управлява от клъстерирано индексно сканиране на таблица A. Предикатът за присъединяване е тест за равенство на колоните с данни, който отхвърля NULLs (независимо от ANSI_NULLS настройка). Може да се надяваме, че оптимизаторът ще изпълни някои разширени разсъждения въз основа на това наблюдение, но не. Този план чете всеки ред от таблица А (включително 40 000 NULLs) ), извършва търсене във филтрирания индекс на таблица B за всеки от тях, разчитайки на факта, че NULLs няма да съответства на NULLs в това търсене. Това е огромна загуба на усилия.
Странното е, че оптимизаторът трябва да е осъзнал, че присъединяването отхвърля NULLs за да избере филтрирания индекс за търсене на таблица B, но не се сети да филтрира NULLs първо от таблица А – или още по-добре, просто да сканирате NULLs -безплатен филтриран индекс в таблица А. Може да се чудите дали това е решение, базирано на разходите, може би статистиката не е много добра? Може би трябва да принудим използването на филтрирания индекс с намек? Намекването на филтрирания индекс в таблица A просто води до същия план с обърнати роли – сканиране на таблица B и търсене в таблица A. Принудителното използване на филтрирания индекс за двете таблици води до грешка 8622 :процесорът на заявки не може да създаде план за заявка.
Добавяне на предикат NOT NULL
Подозрения, че причината е нещо общо с подразбиращото се NULLs -отхвърляне на предиката за присъединяване, добавяме изрично NOT NULL предикат към ON клауза (или WHERE клауза, ако предпочитате, тук става дума за същото):
ИЗБЕРЕТЕ ta.data, tb.dataFROM dbo.TableA КАТО taJOIN dbo.TableB AS tb ON ta.data =tb.data И ta.data НЕ Е NULL;
Добавихме NOT NULL проверете колоната на таблица А, защото първоначалният план сканира клъстерирания индекс на тази таблица, вместо да използва нашия филтриран индекс (търсенето в таблица Б беше добре – използваше филтрирания индекс). Новата заявка е семантично същата като предишната, но планът за изпълнение е различен:
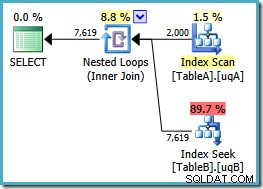
Сега имаме очакваното сканиране на филтрирания индекс в таблица А, което дава 2000 не-NULLs редове за задвижване на вложения цикъл търси в таблица Б. И двете таблици използват нашите филтрирани индекси очевидно оптимално сега:новият план струва само 0,362835 единици (надолу от 7,7768). Можем обаче да се справим по-добре.
Добавяне на два предиката NOT NULL
Излишният NOT NULL предикат за таблица А направи чудеса; какво ще стане, ако добавим и за таблица Б?
ИЗБЕРЕТЕ ta.data, tb.dataFROM dbo.TableA КАТО taJOIN dbo.TableB AS tb ON ta.data =tb.data И ta.data НЕ Е NULL И tb.data НЕ Е NULL;
Тази заявка все още е логически същата като двете предишни усилия, но планът за изпълнение отново е различен:
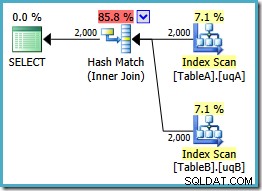
Този план изгражда хеш таблица за 2000-те реда от таблица А, след което проверява съвпаденията, използвайки 2000-те реда от таблица Б. Приблизителният брой върнати редове е много по-добър от предишен план (забелязахте ли оценката от 7 619 там?) и прогнозната цена за изпълнение отново спадна от 0,362835 на 0,0772056 .
Можете да опитате да наложите хеш присъединяване, като използвате намек за оригинала или единичен NOT NULL запитвания, но няма да получите евтиния план, показан по-горе. Оптимизаторът просто няма способността да разсъждава напълно за NULLs -отхвърляне на поведението на присъединяването, тъй като то се прилага към нашите филтрирани индекси без двата излишни предиката.
Позволено е да бъдете изненадани от това – дори ако това е само идеята, че един излишен предикат не е достатъчен (със сигурност ако ta.data е NOT NULL и ta.data = tb.data , следва, че tb.data също е NOT NULL , нали?)
Все още не е перфектно
Малко е изненадващо да видите хеш присъединяване там. Ако сте запознати с основните разлики между трите оператора за физическо свързване, вероятно знаете, че хеш присъединяването е най-добрият кандидат, където:
- Не е налично предварително сортирано въвеждане
- Входът за изграждане на хеш е по-малък от входния сонда
- Входът на сондата е доста голям
Нито едно от тези неща не е вярно тук. Нашето очакване би било, че най-добрият план за тази заявка и набор от данни ще бъде обединяване за сливане, което използва подредените входни данни, налични от нашите два филтрирани индекса. Можем да опитаме да намекнем за обединяване за сливане, като запазим двете допълнителни ON предикати на клауза:
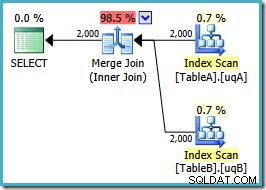
ИЗБЕРЕТЕ ta.data, tb.dataFROM dbo.TableA КАТО taJOIN dbo.TableB AS tb ON ta.data =tb.data И ta.data НЕ СА NULL И tb.data НЕ СА NULLOPTION (MERGE JOIN);Формата на плана е такава, каквато се надявахме:
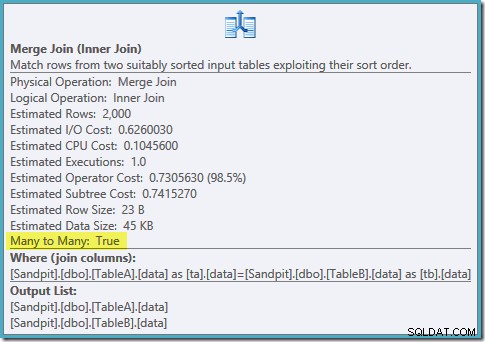
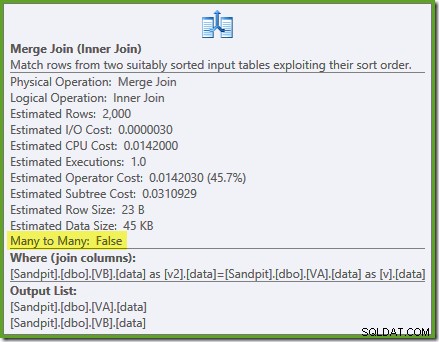
Поръчано сканиране на двата филтрирани индекса, страхотни оценки за мощността, фантастично. Само един малък проблем:този план за изпълнение е много по-лош; прогнозната цена е скочила от 0,0772056 на 0,741527 . Причината за скока в прогнозните разходи се разкрива чрез проверка на свойствата на оператора за свързване на сливане:
Това е скъпо присъединяване много към много, при което машината за изпълнение трябва да следи дубликатите от външния вход в работна таблица и да пренавива, ако е необходимо. Дубликати? Сканираме уникален индекс! Оказва се, че оптимизаторът не знае, че филтриран уникален индекс произвежда уникални стойности (свържете елемента тук). Всъщност това е едно към едно присъединяване, но оптимизаторът го струва, сякаш е много към много, обяснявайки защо предпочита плана за хеш присъединяване.
Алтернативна стратегия
Изглежда, че продължаваме да се сблъскваме с ограничения на оптимизатора, когато използваме филтрирани индекси тук (въпреки че това е подчертан случай на употреба в Books Online). Какво ще стане, ако вместо това се опитаме да използваме изгледи?
Използване на изгледи
Следните два изгледа просто филтрират базовите таблици, за да покажат редовете, където колоната с данни е
NOT NULL:СЪЗДАВАНЕ НА ИЗГЛЕД dbo.VA С SCEMABINDING ASSELECT pk, data, paddingFROM dbo.TableAWHERE данните НЕ СА NULL;GOCREATE VIEW dbo.VBWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableBWHERE данните НЕ СА NULL;Пренаписването на оригиналната заявка за използване на изгледите е тривиално:
ИЗБЕРЕТЕ v.data, v2.dataFROM dbo.VA КАТО vJOIN dbo.VB AS v2 ON v.data =v2.data;Не забравяйте, че тази заявка първоначално създаде план с паралелни вложени цикли на цена 7,7768 единици. С препратките за изглед получаваме този план за изпълнение:
Това е точно същия план за хеш присъединяване, който трябваше да добавим излишен
NOT NULLпредикати за получаване с филтрираните индекси (цената е 0,0772056 единици както преди). Това се очаква, защото всичко, което по същество направихме тук, е да натиснем допълнителнияNOT NULLпредикати от заявката към изглед.Индексиране на изгледите
Можем също да опитаме да материализираме изгледите, като създадем уникален клъстериран индекс в колоната pk:
СЪЗДАВАНЕ НА УНИКАЛЕН КЛУСТРИРАН ИНДЕКС cuq НА dbo.VA (pk);СЪЗДАВАНЕ НА УНИКАЛЕН КЛУСТРИРАН ИНДЕКС cuq НА dbo.VB (pk);Сега можем да добавяме уникални неклъстерирани индекси към филтрираната колона с данни в индексирания изглед:
СЪЗДАВАНЕ НА УНИКАЛЕН НЕКЛУСТРИРАН ИНДЕКС ix НА dbo.VA (данни); СЪЗДАВАНЕ НА УНИКАЛЕН НЕКЛУСТРИРАН ИНДЕКС ix НА dbo.VB (данни);Забележете, че филтрирането се извършва в изгледа, тези неклъстерирани индекси сами по себе си не се филтрират.
Перфектният план
Вече сме готови да изпълним нашата заявка срещу изгледа, използвайки
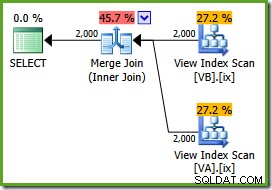
NOEXPANDсъвет за таблица:ИЗБЕРЕТЕ v.data, v2.dataFROM dbo.VA AS v С (NOEXPAND)JOIN dbo.VB AS v2 С (NOEXPAND) ON v.data =v2.data;Планът за изпълнение е:
Оптимизаторът може да види нефилтрираното неклъстерираните индекси на изглед са уникални, така че не е необходимо обединяване много към много. Този окончателен план за изпълнение има приблизителна цена от 0,0310929 единици – дори по-ниско от плана за хеш присъединяване (0,0772056 единици). Това потвърждава очакванията ни, че обединяването за сливане трябва да има най-ниската прогнозна цена за тази заявка и примерен набор от данни.
NOEXPANDса необходими съвети дори в Enterprise Edition, за да се гарантира, че гаранцията за уникалност, предоставена от индексите на изгледите, се използва от оптимизатора.Резюме
Тази публикация подчертава две важни ограничения на оптимизатора с филтрирани индекси:
- Може да са необходими излишни предикати за присъединяване, за да съответстват на филтрирани индекси
- Филтрираните уникални индекси не предоставят информация за уникалността на оптимизатора
В някои случаи може да е практично просто да добавите излишните предикати към всяка заявка. Алтернативата е да се капсулират желаните подразбиращи се предикати в неиндексиран изглед. Планът за хеширане в тази публикация беше много по-добър от плана по подразбиране, въпреки че оптимизаторът би трябвало да може да намери малко по-добрия план за присъединяване при сливане. Понякога може да се наложи да индексирате изгледа и да използвате NOEXPAND съвети (все пак се изискват за екземпляри от Standard Edition). При други обстоятелства нито един от тези подходи няма да е подходящ. Съжалявам за това :)