Има множество методи за разглеждане на лошо представящи се заявки в SQL Server, по-специално хранилище на заявки, разширени събития и динамични изгледи за управление (DMV). Всяка опция има плюсове и минуси. Разширените събития предоставят данни за индивидуалното изпълнение на заявките, докато Съхранението на заявки и DMV обобщават данни за ефективността. За да използвате хранилище на заявки и разширени събития, трябва да ги конфигурирате предварително – или да активирате хранилището на заявки за вашата база данни, или да настроите XE сесия и да я стартирате. DMV данните са винаги налични, така че много често това е най-лесният метод да получите бърз първи поглед върху ефективността на заявката. Това е мястото, където DMV заявките на Glenn са полезни – в неговия скрипт той има множество заявки, които можете да използвате, за да намерите най-добрите заявки за екземпляра въз основа на CPU, логически вход/изход и продължителност. Насочването към заявки с най-висока консумация на ресурси често е добро начало при отстраняване на неизправности, но не можем да забравим за сценария „смърт от хиляда порязвания“ – заявката или наборът от заявки, които се изпълняват МНОГО често – може би стотици или хиляди пъти на минута. Глен има заявка в своя набор, която изброява най-популярните заявки за база данни въз основа на броя на изпълненията, но според моя опит това не ви дава пълна картина на вашето работно натоварване.
Основният DMV, който се използва за разглеждане на показателите за ефективност на заявката, е sys.dm_exec_query_stats. Допълнителни данни, специфични за съхранените процедури (sys.dm_exec_procedure_stats), функции (sys.dm_exec_function_stats) и тригери (sys.dm_exec_trigger_stats), също са налични, но помислете за натоварване, което не е чисто съхранени процедури, функции и тригери. Помислете за смесено работно натоварване, което има някои ad hoc заявки или може би е изцяло ad hoc.
Примерен сценарий
Заемайки и адаптирайки код от предишна публикация, Изследване на въздействието върху производителността на Adhoc работно натоварване, първо ще създадем две съхранени процедури. Първият, dbo.RandomSelects, генерира и изпълнява ad hoc израз, а вторият, dbo.SPRandomSelects, генерира и изпълнява параметризирана заявка.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT c.CustomerID, c.AccountOpenedDate, COUNT(ct.CustomerTransactionID)
FROM Sales.Customers c
JOIN Sales.CustomerTransactions ct
ON c.CustomerID = ct.CustomerID
WHERE c.CustomerName = @ConcatString
GROUP BY c.CustomerID, c.AccountOpenedDate;
SELECT @RowLoop = @RowLoop + 1;
END
GO Сега ще изпълним и двете съхранени процедури 1000 пъти, като използваме същия метод, описан в предишната ми публикация с .cmd файлове, извикващи .sql файлове със следните изрази:
Съдържание на файла Adhoc.sql:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 1000;
Съдържание на Parameterized.sql файл:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 1000;
Примерен синтаксис в .cmd файл, който извиква .sql файла:
sqlcmd -S WIN2016\SQL2017 -i"Adhoc.sql" exit
Ако използваме вариация на заявката за най-доброто работно време на Glenn, за да разгледаме най-добрите заявки въз основа на работното време (CPU):
-- Get top total worker time queries for entire instance (Query 44) (Top Worker Time Queries) SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.total_worker_time AS [Total Worker Time], qs.execution_count AS [Execution Count], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);
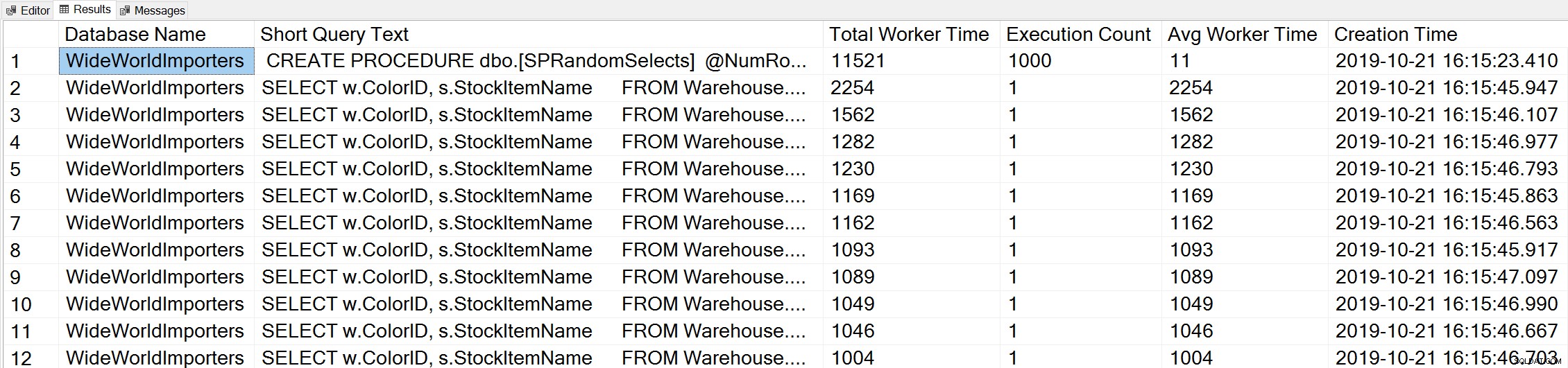
Виждаме изявлението от нашата съхранена процедура като заявката, която се изпълнява с най-голямо количество кумулативен процесор.
Ако изпълним вариация на заявката на Glenn's Query Execution Counts спрямо базата данни WideWorldImporters:
USE [WideWorldImporters]; GO -- Get most frequently executed queries for this database (Query 57) (Query Execution Counts) SELECT TOP(50) LEFT(t.[text], 50) AS [Short Query Text], qs.execution_count AS [Execution Count], qs.total_logical_reads AS [Total Logical Reads], qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads], qs.total_worker_time AS [Total Worker Time], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.total_elapsed_time AS [Total Elapsed Time], qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp WHERE t.dbid = DB_ID() ORDER BY qs.execution_count DESC OPTION (RECOMPILE);
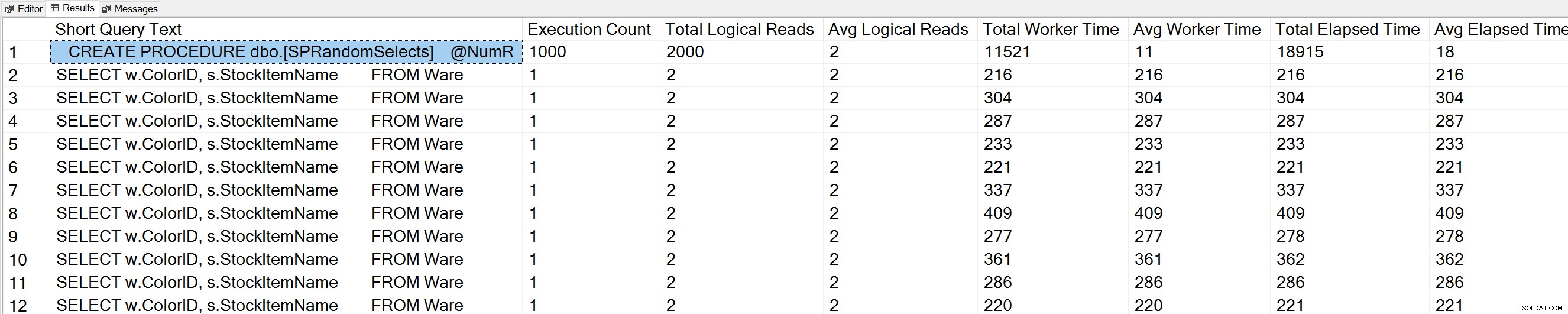
Виждаме и нашия оператор за съхранена процедура в горната част на списъка.
Но ad hoc заявката, която изпълнихме, въпреки че има различни буквални стойности, по същество беше същата оператор, изпълняван многократно, както можем да видим, като погледнем query_hash:
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.query_hash AS [query_hash], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY [Short Query Text];
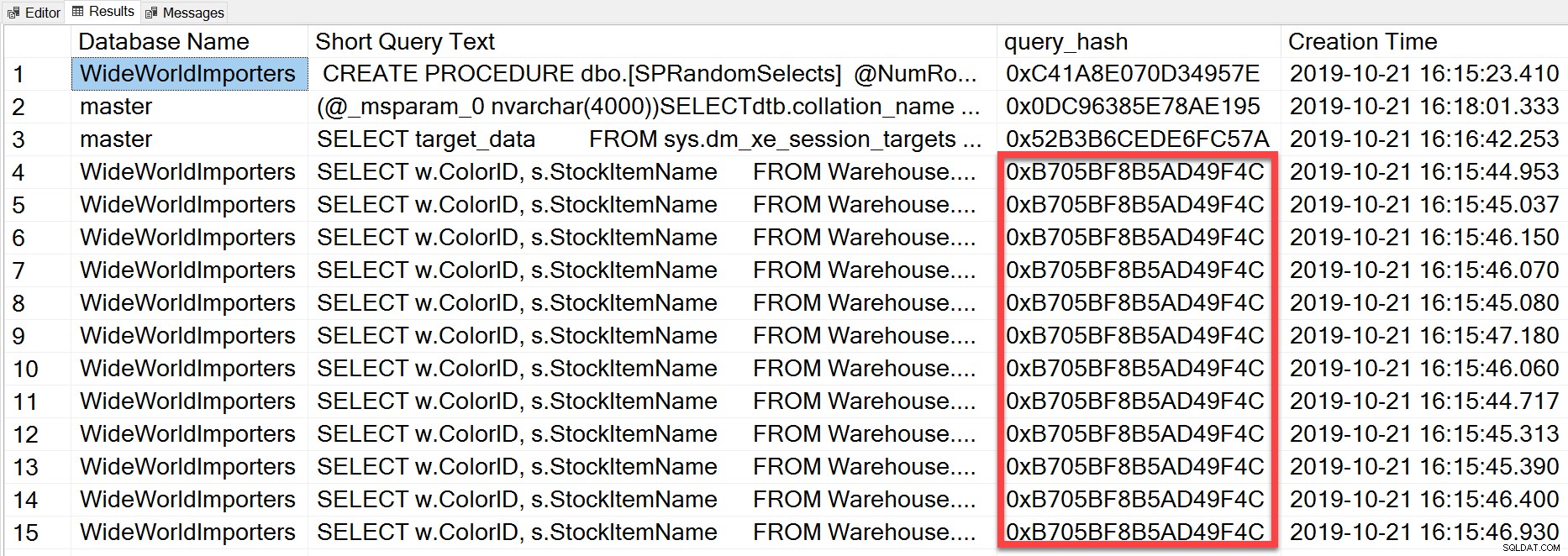
query_hash е добавен в SQL Server 2008 и се основава на дървото на логическите оператори, генерирани от оптимизатора на заявки за текста на израза. Заявките, които имат подобен текст на израза, които генерират едно и също дърво от логически оператори, ще имат същия query_hash, дори ако литералните стойности в предиката на заявката са различни. Докато литералните стойности могат да бъдат различни, обектите и техните псевдоними трябва да са еднакви, както и подсказките за заявка и евентуално опциите SET. Съхранената процедура RandomSelects генерира заявки с различни литерални стойности:
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1005451175198';
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1006416358897'; Но всяко изпълнение има точно същата стойност за query_hash, 0xB705BF8B5AD49F4C. За да разберем колко често се изпълнява една ad hoc заявка – и тези, които са еднакви по отношение на query_hash – трябва да групираме по реда на query_hash на този брой, вместо да гледаме execution_count в sys.dm_exec_query_stats (което често показва стойност 1).
Ако променим контекста към базата данни WideWorldImporters и потърсим водещи заявки въз основа на броя на изпълненията, където групираме по query_hash, вече можем да видим както съхранената процедура и нашата ad hoc заявка:
;WITH qh AS
(
SELECT TOP (25) query_hash, COUNT(*) AS COUNT
FROM sys.dm_exec_query_stats
GROUP BY query_hash
ORDER BY COUNT(*) DESC
),
qs AS
(
SELECT obj = COALESCE(ps.object_id, fs.object_id, ts.object_id),
db = COALESCE(ps.database_id, fs.database_id, ts.database_id),
qs.query_hash, qs.query_plan_hash, qs.execution_count,
qs.sql_handle, qs.plan_handle
FROM sys.dm_exec_query_stats AS qs
INNER JOIN qh ON qs.query_hash = qh.query_hash
LEFT OUTER JOIN sys.dm_exec_procedure_stats AS [ps]
ON [qs].[sql_handle] = [ps].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_function_stats AS [fs]
ON [qs].[sql_handle] = [fs].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_trigger_stats AS [ts]
ON [qs].[sql_handle] = [ts].[sql_handle]
)
SELECT TOP (50)
OBJECT_NAME(qs.obj, qs.db),
query_hash,
query_plan_hash,
SUM([qs].[execution_count]) AS [ExecutionCount],
MAX([st].[text]) AS [QueryText]
FROM qs
CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st]
CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp]
GROUP BY qs.obj, qs.db, qs.query_hash, qs.query_plan_hash
ORDER BY ExecutionCount DESC;

Забележка:DMV sys.dm_exec_function_stats беше добавен в SQL Server 2016. Изпълнението на тази заявка на SQL Server 2014 и по-стари изисква премахване на препратка към този DMV.
Този изход предоставя много по-изчерпателно разбиране за това кои заявки наистина се изпълняват най-често, тъй като се обобщава въз основа на query_hash, а не като просто разглежда execution_count в sys.dm_exec_query_stats, който може да има множество записи за един и същ query_hash, когато са различни литерални стойности използван. Изходът на заявката включва също query_plan_hash, който може да бъде различен за заявки със същия query_hash. Тази допълнителна информация е полезна при оценка на ефективността на плана за заявка. В примера по-горе всяка заявка има един и същ query_plan_hash, 0x299275DD475C4B17, демонстрирайки, че дори с различни входни стойности, оптимизаторът на заявки генерира един и същ план – той е стабилен. Когато съществуват множество стойности на query_plan_hash за един и същ query_hash, съществува променливост на плана. В сценарий, при който една и съща заявка, базирана на query_hash, се изпълнява хиляди пъти, обща препоръка е да параметризирате заявката. Ако можете да потвърдите, че не съществува променливост на плана, тогава параметризирането на заявката премахва времето за оптимизация и компилация за всяко изпълнение и може да намали общия процесор. В някои сценарии параметризирането на 5 до 10 ad hoc заявки може да подобри производителността на системата като цяло.
Резюме
За всяка среда е важно да разберете кои заявки са най-скъпи по отношение на използването на ресурси и кои заявки се изпълняват най-често. Същият набор от заявки може да се покаже и за двата типа анализ, когато се използва DMV скрипта на Glenn, което може да бъде подвеждащо. Поради това е важно да се установи дали работното натоварване е предимно процедурно, предимно ad hoc или смесено. Въпреки че има много документи за предимствата на съхранените процедури, намирам, че смесените или силно ad hoc работни натоварвания са много често срещани, особено при решения, които използват обектно-релационни карти (ORMs), като Entity Framework, NHibernate и LINQ to SQL. Ако не сте наясно с типа на натоварването на сървъра, изпълнението на горната заявка за преглед на най-изпълнените заявки въз основа на query_hash е добро начало. Когато започнете да разбирате работното натоварване и това, което съществува както за тежките нападатели, така и за смъртта от хиляда заявки за намаляване, можете да преминете към истинско разбиране на използването на ресурсите и въздействието, което тези заявки имат върху производителността на системата, и да насочите усилията си за настройка.