Автор на гост:Michael J Swart (@MJSwart)
Прекарвам много време, превеждайки софтуерните изисквания в схеми и заявки. Тези изисквания понякога са лесни за изпълнение, но често са трудни. Искам да говоря за избора на дизайн на потребителския интерфейс, който води до модели за достъп до данни, които са неудобни за прилагане с помощта на SQL Server.
Сортиране по колона
Сортирането по колона е толкова познат модел, че можем да го приемем за даденост. Всеки път, когато взаимодействаме със софтуер, който показва таблица, можем да очакваме колоните да бъдат сортирани по следния начин:
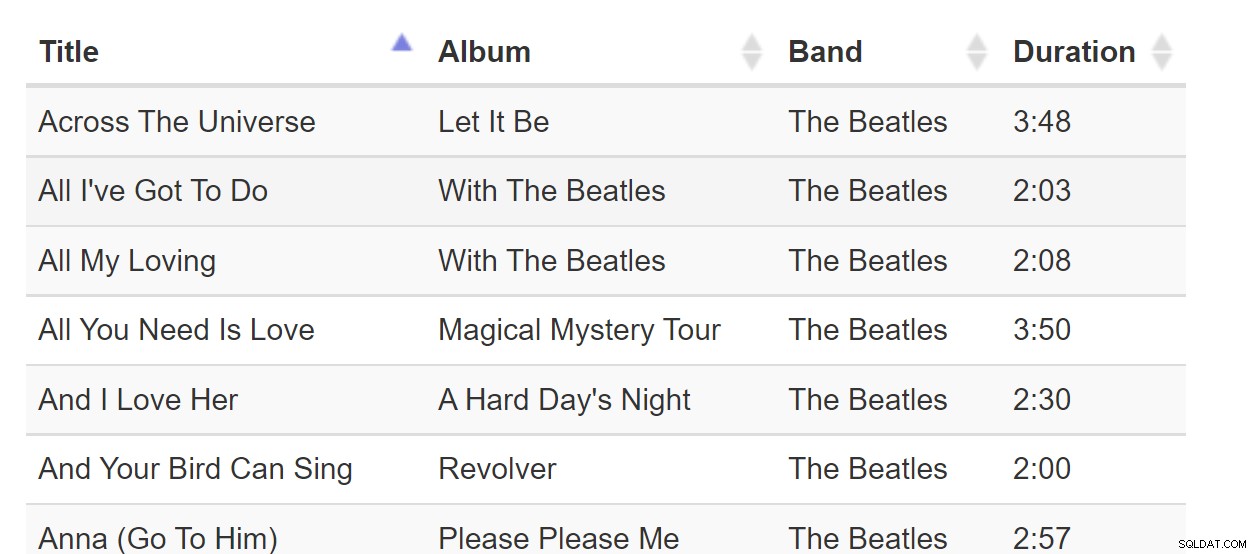
Sort-By-Colunn е страхотен модел, когато всички данни могат да се поберат в браузъра. Но ако наборът от данни е с милиарди редове, това може да стане неудобно, дори ако уеб страницата изисква само една страница с данни. Помислете за тази таблица с песни:
CREATE TABLE Songs
(
Title NVARCHAR(300) NOT NULL,
Album NVARCHAR(300) NOT NULL,
Band NVARCHAR(300) NOT NULL,
DurationInSeconds INT NOT NULL,
CONSTRAINT PK_Songs PRIMARY KEY CLUSTERED (Title),
);
CREATE NONCLUSTERED INDEX IX_Songs_Album
ON dbo.Songs(Album)
INCLUDE (Band, DurationInSeconds);
CREATE NONCLUSTERED INDEX IX_Songs_Band
ON dbo.Songs(Band); И разгледайте тези четири заявки, сортирани по всяка колона:
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Title; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Album; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Band; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY DurationInSeconds;
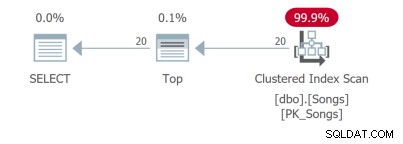
Дори за толкова проста заявка има различни планове за заявка. Първите две заявки използват покриващи индекси:
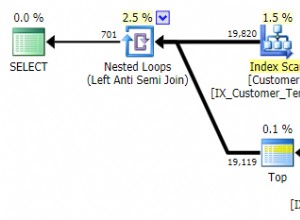
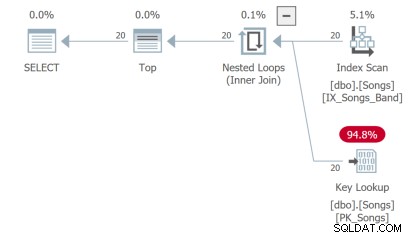
Третата заявка трябва да направи ключово търсене, което не е идеално:
Но най-лошата е четвъртата заявка, която трябва да сканира цялата таблица и да извърши сортиране, за да върне първите 20 реда:
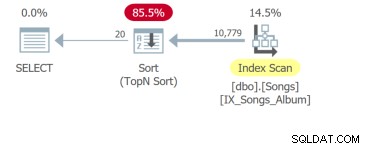
Въпросът е, че въпреки че единствената разлика е клаузата ORDER BY, тези заявки трябва да се анализират отделно. Основната единица на настройката на SQL е заявката. Така че, ако ми покажете изискванията на потребителския интерфейс с десет колони за сортиране, ще ви покажа десет заявки за анализ.
Кога това става неудобно?
Функцията за сортиране по колона е страхотен модел на потребителския интерфейс, но може да стане неудобно, ако данните идват от огромна растяща таблица с много, много колони. Може да е изкушаващо да създадете покриващи индекси за всяка колона, но това има други компромиси. Индексите на Columnstore могат да помогнат при някои обстоятелства, но това въвежда друго ниво на неудобство. Не винаги има лесна алтернатива.
Странични резултати
Използването на страници с резултати е добър начин да не затрупвате потребителя с твърде много информация наведнъж. Това също е добър начин да не претоварвате сървърите на базата данни ... обикновено.
Помислете за този дизайн:

Данните зад този пример изискват преброяване и обработка на целия набор от данни, за да се отчете броят на резултатите. Заявката за този пример може да използва синтаксис като този:
... ORDER BY LastModifiedTime OFFSET @N ROWS FETCH NEXT 25 ROWS ONLY;
Това е удобен синтаксис и заявката произвежда само 25 реда. Но само защото наборът от резултати е малък, това не означава непременно, че е евтин. Точно както видяхме с модела за сортиране по колона, ТОП операторът е евтин само ако не трябва първо да сортира много данни.
Асинхронни заявки за страници
Докато потребителят се придвижва от една страница с резултати до следващата, съответните уеб заявки могат да бъдат разделени от секунди или минути. Това води до проблеми, които приличат много на клопките, които се виждат при използване на NOLOCK. Например:
SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY; -- wait a little bit SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 25 ROWS FETCH NEXT 25 ROWS ONLY;
Когато се добави ред между двете заявки, потребителят може да види същия ред два пъти. И ако един ред бъде премахнат, потребителят може да пропусне ред, докато навигира в страниците. Този модел на страници с резултати е еквивалентен на „Дайте ми редове 26-50“. Когато истинският въпрос трябва да бъде „Дайте ми следващите 25 реда“. Разликата е фина.
По-добри шаблони
С Paged-Results това „ОТМЕСТВАНЕ @N ROWS“ може да отнеме повече и повече време с нарастването на @N. Вместо това помислете за бутоните за зареждане на повече или безкрайно превъртане. С Load-More пейджинг има поне шанс за ефективно използване на индекс. Заявката ще изглежда така:
SELECT [Some Columns] FROM [Some Table] WHERE [Sort Value] > @Bookmark ORDER BY [Sort Value] FETCH NEXT 25 ROWS ONLY;
Той все още страда от някои от капаните на асинхронните заявки за страници, но поради отметката потребителят ще продължи откъдето е спрял.
Търсене на текст за подниз
Търсенето е навсякъде в интернет. Но какво решение трябва да се използва на гърба? Искам да предупредя да не се търси подниз с помощта на филтър LIKE на SQL Server със заместващи знаци като този:
SELECT Title, Category FROM MyContent WHERE Title LIKE '%' + @SearchTerm + '%';
Това може да доведе до неудобни резултати като този:
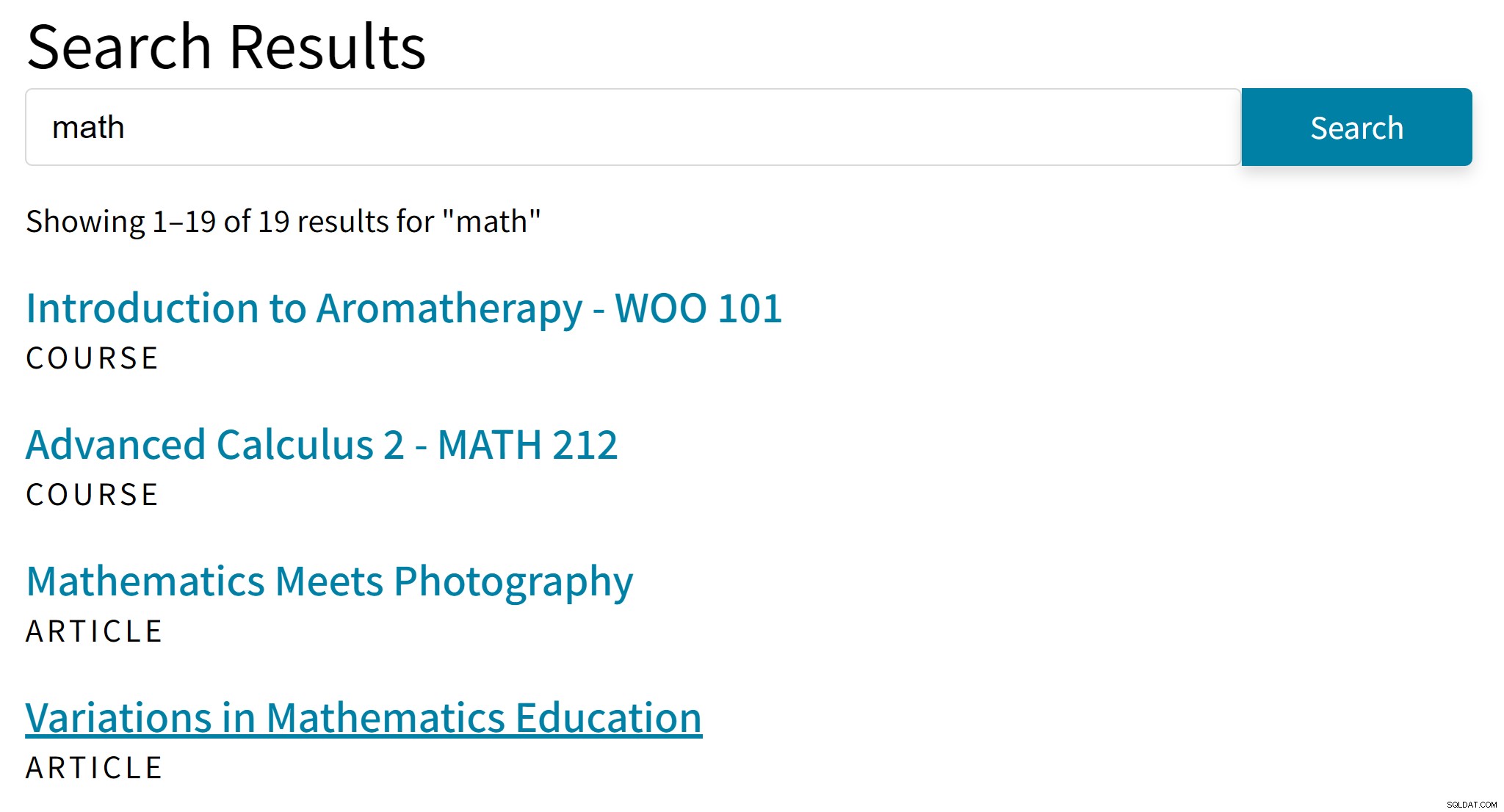
„Ароматерапия“ вероятно не е добър хит за термина за търсене „математика“. Междувременно в резултатите от търсенето липсват статии, които споменават само алгебра или тригонометрия.
Също така може да бъде много трудно да се направи ефективно с помощта на SQL Server. Няма ясен индекс, който да поддържа този вид търсене. Пол Уайт даде едно сложно решение с Trigram Wildcard String Search в SQL Server. Съществуват и трудности, които могат да възникнат при съпоставянето и Unicode. Може да се превърне в скъпо решение за не толкова добро потребителско изживяване.
Какво да използвате вместо това
Търсенето в пълен текст на SQL Server изглежда може да помогне, но аз лично никога не съм го използвал. На практика съм виждал успех само в решения извън SQL Server (например Elasticsearch).
Заключение
В моя опит открих, че софтуерните дизайнери често са много възприемчиви към обратната връзка, че техните дизайни понякога ще бъдат неудобни за изпълнение. Когато не са, намерих за полезно да подчертая клопките, разходите и времето за доставка. Този вид обратна връзка е необходима, за да помогне за изграждането на поддържащи се, мащабируеми решения.
За автора
 Майкъл Джей Суорт е страстен професионалист по база данни и блогър, който се фокусира върху разработването на бази данни и софтуерната архитектура. Той обича да говори за всичко, свързано с данни, като допринася за обществени проекти. Майкъл води блог като „Шептач на база данни“ в michaeljswart.com.
Майкъл Джей Суорт е страстен професионалист по база данни и блогър, който се фокусира върху разработването на бази данни и софтуерната архитектура. Той обича да говори за всичко, свързано с данни, като допринася за обществени проекти. Майкъл води блог като „Шептач на база данни“ в michaeljswart.com.