Това е втората част от поредица от пет части, която се потапя дълбоко в начина, по който стартират паралелните планове в режим на ред на SQL Server. До края на първата част бяхме създали нулев контекст на изпълнение за родителската задача. Този контекст съдържа цялото дърво от изпълними оператори, но те все още не са готови за итеративния модел на изпълнение на машината за обработка на заявки.
Итеративно изпълнение
SQL Server изпълнява заявка чрез процес, известен като сканиране на заявка . Инициализацията на плана започва от корена от процесора на заявки, извикващ Open на коренния възел. Open повикванията преминават през дървото от итератори, рекурсивно извиквайки Open на всяко дете, докато се отвори цялото дърво.
Процесът на връщане на редове с резултати също е рекурсивен, задействан от процесора на заявки, извикващ GetRow в корена. Всяко основно извикване връща ред по ред. Процесорът на заявки продължава да извиква GetRow на основния възел, докато няма повече налични редове. Изпълнението се изключва с окончателно рекурсивно Close обадете се. Тази подредба позволява на процесора на заявки да инициализира, изпълнява и затваря всеки произволен план, като извиква същите интерфейсни методи само в основата.
За да трансформира дървото на изпълними оператори в подходящо за обработка ред по ред, SQL Server добавя сканиране на заявка обвивка за всеки оператор. Сканирането на заявка обектът предоставя Open , GetRow и Close методи, необходими за итеративно изпълнение.
Обектът за сканиране на заявка също поддържа информация за състоянието и разкрива други специфични за оператора методи, необходими по време на изпълнение. Например обектът за сканиране на заявка за оператор на Start-Up Filter (CQScanStartupFilterNew ) разкрива следните методи:
OpenGetRowClosePrepRecomputeGetScrollLockSetMarkerGotoMarkerGotoLocationReverseDirectionDormant
Допълнителните методи за този итератор се използват предимно в плановете на курсора.
Инициализиране на сканирането на заявката
Процесът на обвиване се нарича инициализиране на сканирането на заявката . Извършва се чрез извикване от процесора на заявки към CQueryScan::InitQScanRoot . Задачата-родител изпълнява този процес за целия план (съдържа се в нулев контекст на изпълнение). Самият процес на превод е рекурсивен по своята същност, като започва от корена и върви надолу по дървото.
По време на този процес всеки оператор е отговорен за инициализиране на собствените си данни и създаване на всякакви изпълнителни ресурси има нужда. Това може да включва създаване на допълнителни обекти извън процесора на заявки, например структурите, необходими за комуникация с механизма за съхранение за извличане на данни от постоянно хранилище.
Напомняне за плана за изпълнение, с добавени номера на възли (щракнете, за да увеличите):
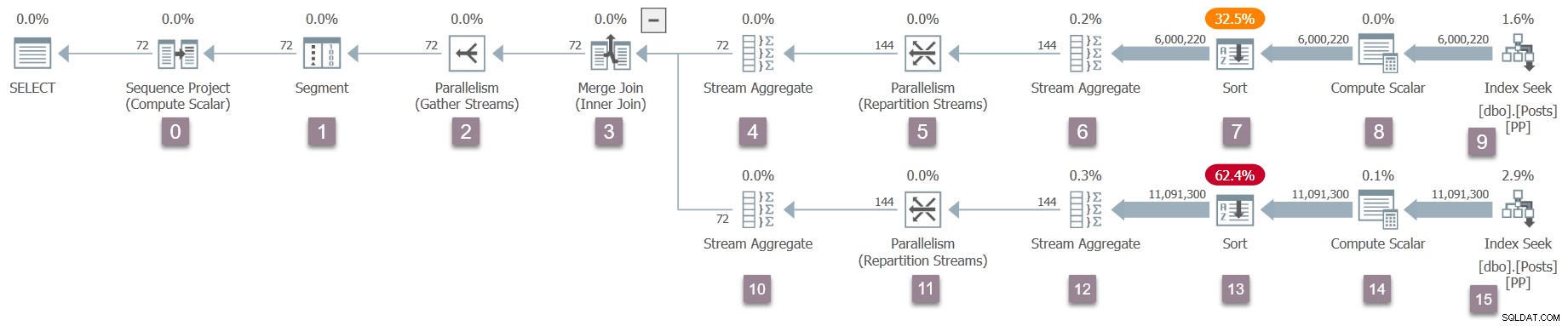
Операторът вкорена (възел 0) на дървото на изпълнимия план е проект на последователност . Той е представен от клас с име CXteSeqProject . Както обикновено, тук започва рекурсивната трансформация.
Обвивки за сканиране на заявки
Както споменахме, CXteSeqProject обектът не е оборудван да участва в итеративното сканиране на заявка процес — той няма необходимия Open , GetRow и Close методи. Процесорът на заявки се нуждае от обвивка около изпълнимия оператор, за да предостави този интерфейс.
За да получи тази обвивка за сканиране на заявка, родителската задача извиква CXteSeqProject::QScanGet за връщане на обект от тип CQScanSeqProjectNew . Свързаната карта от операторите, създадени по-рано, се актуализира, за да се позовава на новия обект за сканиране на заявка, а неговите методи на итератор са свързани с корена на плана.
Дъщето на проекта за последователност е сегмент оператор (възел 1). Извикване на CXteSegment::QScanGet връща обект на обвивка за сканиране на заявка от тип CQScanSegmentNew . Свързаната карта отново се актуализира и указателите на функцията на итератора са свързани към сканирането на заявка за проект на родителска последователност.
Половин обмен
Следващият оператор е събиране на потоци обмен (възел 2). Извикване на CXteExchange::QScanGet връща CQScanExchangeNew както може би очаквате досега.
Това е първият оператор в дървото, който трябва да извърши значителна допълнителна инициализация. Това създава потребителската страна на обмена чрез CXTransport::CreateConsumerPart . Това създава порта (CXPort ) — структура от данни в споделена памет, използвана за синхронизация и обмен на данни — и канал (CXPipe ) за пакетен транспорт. Имайте предвид, че производителя страна на борсатане е създадена по това време. Имаме само половин размяна!
Още обвиване
След това процесът на настройка на сканирането на процесора на заявки продължава с сливане (възел 3). Няма винаги да повтарям QScanGet и CQScan* обаждания от този момент нататък, но те следват установения модел.
Обединението за сливане има две деца. Настройката за сканиране на заявка продължава както преди с външния (горен) вход — агрегат на потока (възел 4), след това преразпределение потоци обмен (възел 5). Преразпределянето на потоци отново създава само потребителската страна на обмена, но този път има създадени два канала, защото DOP е два. Потребителската страна на този тип обмен има DOP връзки към своя родителски оператор (по една на нишка).
След това имаме още единагрегат на потока (възел 6) и сортт (възел 7). Сортирането има дъщерно, което не се вижда в плановете за изпълнение — набор от редове на механизма за съхранение, използван за прилагане на разливане към tempdb . Очакваният CQScanSortNew следователно е придружен от дете CQScanRowsetNew във вътрешното дърво. Не се вижда в изхода на showplan.
Профилиране на I/O и отложени операции
Сортита Операторът също е първият, който инициализирахме досега, който може да е отговорен за I/O . Ако приемем, че изпълнението е поискало данни за I/O профилиране (например чрез заявка за „действителен“ план), сортирането създава обект за запис на тези данни за профилиране по време на изпълнение чрез CProfileInfo::AllocProfileIO .
Следващият оператор е изчислителен скалар (възел 8), наречен проект вътрешно. Извикването за настройка на сканиране на заявка до CXteProject::QScanGet нене връща обект за сканиране на заявка, тъй като изчисленията, извършени от този изчислителен скалар, са отложени до първия родителски оператор, който се нуждае от резултата. В този план този оператор е такъв. Сортирането ще свърши цялата работа, възложена на скалара за изчисляване, така че проектът на възел 8 не е част от дървото за сканиране на заявка. Изчислителният скалар наистина не се изпълнява по време на изпълнение. За повече подробности относно отложените изчислителни скалари вижте Изчисляване на скалари, изрази и ефективност на плана за изпълнение.
Паралелно сканиране
Крайният оператор след скалара за изчисляване на този клон на плана е търсене на индекс (CXteRange ) на възел 9. Това създава очаквания оператор за сканиране на заявка (CQScanRangeNew ), но също така изисква сложна последователност от инициализации, за да се свърже с механизма за съхранение и да се улесни паралелно сканиране на индекса.
Просто покривам акцентите, инициализирайки търсенето на индекс:
- Създава обект за профилиране за I/O (
CProfileInfo::AllocProfileIO). - Създава паралелен набор от редове сканиране на заявка (
CQScanRowsetNew::ParallelGetRowset). - Настройва синхронизация обект за координиране на паралелното сканиране по време на изпълнение (
CQScanRangeNew::GetSyncInfo). - Създава курсор на таблица на машината за съхранение и само за четене дескриптор на транзакция .
- Отваря родителския набор от редове за четене (достъп до HoBt и вземане на необходимите ключалки).
- Задава времето за изчакване на заключване.
- Настройва предварително извличане (включително свързаните буфери на паметта).
Добавяне на оператори за профилиране в режим на ред
Вече достигнахме нивото на листа на този клон на плана (търсенето на индекса няма дъщерно). След като току-що създадохте обекта за сканиране на заявка за търсене на индекс, следващата стъпка е да обвиете сканирането на заявката с клас за профилиране (ако приемем, че сме поискали действителен план). Това става чрез извикване на sqlmin!PqsWrapQScan . Обърнете внимание, че профилиращите програми се добавят след създаването на сканирането на заявката, когато започваме да се изкачваме по дървото на итератора.
PqsWrapQScan създава нов оператор за профилиране като родител на търсенето на индекс, чрез извикване на CProfileInfo::GetOrCreateProfileInfo . Операторът за профилиране (CQScanProfileNew ) има обичайните методи за интерфейс за сканиране на заявки. Освен че събират данните, необходими за действителните планове, данните за профилиране се излагат и чрез DMV sys.dm_exec_query_profiles .
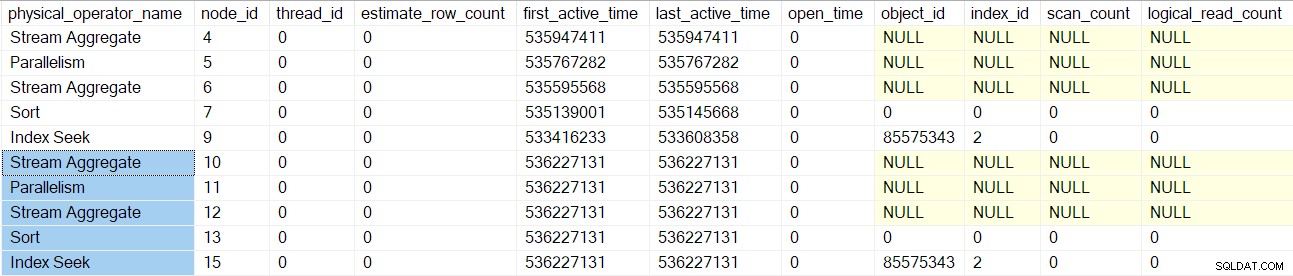
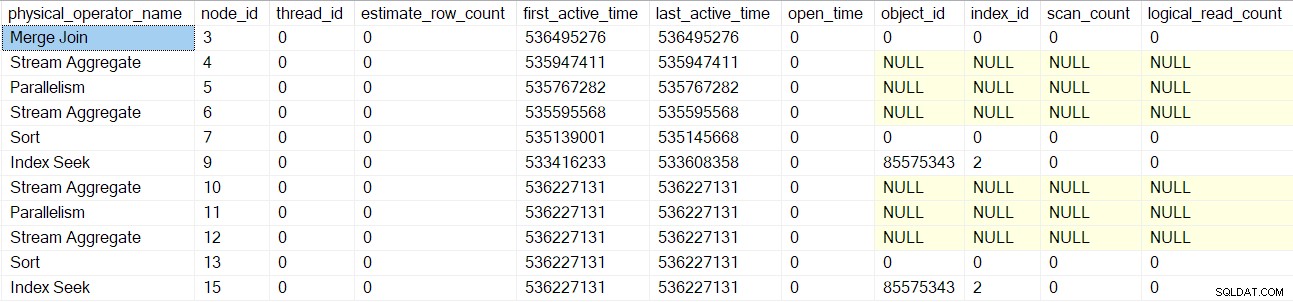
Запитването на този DMV в този точен момент от времето за текущата сесия показва, че съществува само един оператор на план (възел 9) (което означава, че той е единственият, обвит от профайлър):

Тази екранна снимка показва пълния набор от резултати от DMV към настоящия момент (не е редактиран).
Следва, CQScanProfileNew извиква API на брояча на заявката (KERNEL32!QueryPerformanceCounterStub ) предоставена от операционната система за записване на първото и последното активно време на профилирания оператор:

Последното активно време ще се актуализира с помощта на API на брояча на заявката всеки път, когато се изпълнява кодът за този итератор.
Профилизаторът след това задава приблизителния брой редове в този момент в плана (CProfileInfo::SetCardExpectedRows ), като се отчита всяка цел на ред (CXte::CardGetRowGoal ). Тъй като това е паралелен план, той разделя резултата на броя на нишките (CXte::FGetRowGoalDefinedForOneThread ) и записва резултата в контекста на изпълнение.
Прогнозният брой редовене се вижда чрез DMV в този момент, тъй като родителската задача няма да изпълни този оператор. Вместо това оценката за нишка ще бъде изложена по-късно в контексти на паралелно изпълнение (които все още не са създадени). Независимо от това, номерът за всяка нишка се запазва в профайлъра на родителската задача – просто не се вижда през DMV.
Приятелското име на оператора на плана („Index Seek“) след това се задава чрез извикване на CXteRange::GetPhysicalOp :

Преди това може да сте забелязали, че запитването на DMV показва името като „???“. Това е постоянното име, което се показва за невидими оператори (напр. предварително извличане на вложени цикли, пакетно сортиране), които нямат дефинирано приятелско име.
И накрая, индексирайте метаданните и текущите статистически данни за I/O за обвития индекс за търсене се добавят чрез извикване към CQScanRowsetNew::GetIoCounters :

Броячите са нула в момента, но ще бъдат актуализирани, тъй като търсенето на индекс извършва I/O по време на изпълнение на завършения план.
Още обработка на сканиране на заявки
С оператора за профилиране, създаден за търсенето на индекс, обработката на сканиране на заявки се премества обратно нагоре в дървото към родителското сортиране (възел 7).
Сортирането изпълнява следните задачи за инициализация:
- Регистрира използването на паметта си със заявката диспечер на паметта (
CQryMemManager::RegisterMemUsage) - Изчислява необходимата памет за въвеждане на сортиране (
CQScanIndexSortNew::CbufInputMemory) и изход (CQScanSortNew::CbufOutputMemory). - Таблицата за сортиране се създава заедно със свързания набор от редове на механизма за съхранение (
sqlmin!RowsetSorted). - Самостоятелна системна транзакция (не е ограничен от потребителската транзакция) се създава за сортиране на разпределения на дискове, заедно с фалшива работна таблица (
sqlmin!CreateFakeWorkTable). - Услугата за изрази е инициализирана (
sqlTsEs!CEsRuntime::Startup) за оператора за сортиране, за да извърши изчисленията отложено от изчислителния скалар. - Предварително извличане за всякакъв вид работи, прехвърлени към tempdb след това се създава чрез (
CPrefetchMgr::SetupPrefetch).
И накрая, сканирането на заявката за сортиране е обвито от оператор за профилиране (включително I/O), точно както видяхме за търсенето на индекс:

Забележете, че изчислителният скалар (възел 8) липсва от DMV. Това е така, защото работата му се отлага до сортирането, не е част от дървото за сканиране на заявки и следователно няма обвиващ обект за профилиране.
Придвижване до родителския елемент на сортирането, агрегата на потока Операторът за сканиране на заявка (възел 6) инициализира своите изрази и броячите по време на изпълнение (например броя на редовете в текущата група). Агрегатът на потока е обвит с оператор за профилиране, записващ първоначалните му времена:

Родителското преразпределение на потоци обмен (възел 5) е обвит от профайлър (не забравяйте, че в този момент съществува само потребителската страна на този обмен):

Същото се прави и за неговия родител агрегат на поток (възел 4), който също се инициализира, както е описано по-горе:

Обработката на сканиране на заявка се връща към родителското сливане (възел 3), но все още не го инициализира. Вместо това се движим надолу по вътрешната (долната) страна на обединяването за сливане, изпълнявайки същите подробни задачи за тези оператори (възли от 10 до 15), както е направено за горния (външния) клон:
След като тези оператори бъдат обработени, присъединяването за сливане сканирането на заявка се създава, инициализира и обвива с профилиращ обект. Това включва I/O броячи, тъй като много-много обединяване използва работна таблица (въпреки че текущото обединяване е едно-много):
Същият процес се следва за обмена на родителските потоци за събиране (възел 2) само от страна на потребителя, сегмент (възел 1) и проект на последователност (възел 0) оператори. Няма да ги описвам подробно.
Профилите на заявки DMV вече отчитат пълен набор от възли за сканиране на заявки, обвити с профили:
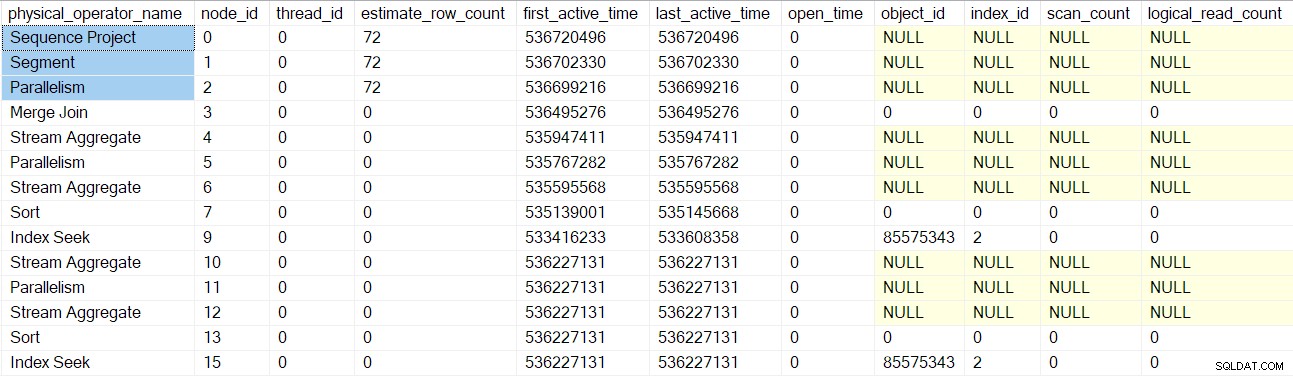
Забележете, че потребителят на потоците на последователност проект, сегмент и събиране имат приблизителен брой редове, защото тези оператори ще се изпълняват от родителската задача , а не чрез допълнителни паралелни задачи (вижте CXte::FGetRowGoalDefinedForOneThread по-рано). Родителската задача няма работа в паралелни разклонения, така че концепцията за приблизителен брой редове има смисъл само за допълнителни задачи.
Показаните по-горе стойности за активно време са донякъде изкривени, защото трябваше да спра изпълнението и да правя екранни снимки на DMV на всяка стъпка. Отделно изпълнение (без изкуствените забавяния, въведени с помощта на дебъгер) доведе до следните времена:
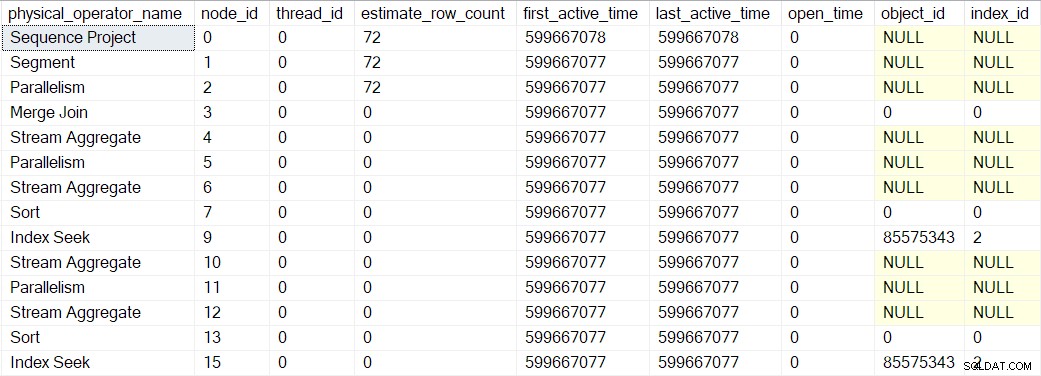
Дървото е изградено в същата последователност, описана по-горе, но процесът е толкова бърз, че има само 1 микросекунда разлика между активното време на първия опакован оператор (търсене на индекса в възел 9) и последния (проект на последователност в възел 0).
Край на част 2
Може да звучи така, сякаш сме свършили много работа, но не забравяйте, че създадохме дърво за сканиране на заявки само за родителската задача , а борсите имат само потребителска страна (все още няма производител). Нашият паралелен план също има само една нишка (както е показано на последната екранна снимка). Част 3 ще види създаването на първите ни допълнителни паралелни задачи.