В част 5 от моята серия за таблични изрази предоставих следното решение за генериране на поредица от числа с помощта на CTE, конструктор на стойност на таблицата и кръстосани съединения:
DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Има много практически случаи на използване на такъв инструмент, включително генериране на поредица от стойности за дата и час, създаване на примерни данни и др. Признавайки общата необходимост, някои платформи предоставят вграден инструмент, като функцията generate_series на PostgreSQL. Към момента на писане, T-SQL не предоставя такъв вграден инструмент, но винаги може да се надяваме и да гласуваме такъв инструмент да бъде добавен в бъдеще.
В коментар към моята статия Маркос Кирхнер спомена, че е тествал моето решение с различни мощности на конструктора на стойности на таблицата и е получил различни времена на изпълнение за различните мощности.
 Винаги използвах решението си с мощност на конструктора на базова таблица на стойност 2, но коментарът на Маркос ме накара да се замисля. Този инструмент е толкова полезен, че ние като общност трябва да обединим усилията си, за да опитаме да създадем възможно най-бързата версия. Тестването на различни мощности на базовата таблица е само едно измерение, което трябва да опитате. Може да има много други. Ще представя тестовете за производителност, които направих с моето решение. Основно експериментирах с различни мощности на конструктора на стойности на таблицата, със серийна срещу паралелна обработка и с режим на ред срещу обработка в пакетен режим. Възможно е обаче съвсем различно решение да е дори по-бързо от най-добрата ми версия. И така, предизвикателството е в сила! Призовавам всички джедаи, падауани, магьосници и чираци. Кое е най-ефективното решение, което можете да измислите? Имате ли в себе си, за да победите най-бързото решение, публикувано досега? Ако е така, споделете вашето като коментар към тази статия и не се колебайте да подобрите всяко решение, публикувано от други.
Винаги използвах решението си с мощност на конструктора на базова таблица на стойност 2, но коментарът на Маркос ме накара да се замисля. Този инструмент е толкова полезен, че ние като общност трябва да обединим усилията си, за да опитаме да създадем възможно най-бързата версия. Тестването на различни мощности на базовата таблица е само едно измерение, което трябва да опитате. Може да има много други. Ще представя тестовете за производителност, които направих с моето решение. Основно експериментирах с различни мощности на конструктора на стойности на таблицата, със серийна срещу паралелна обработка и с режим на ред срещу обработка в пакетен режим. Възможно е обаче съвсем различно решение да е дори по-бързо от най-добрата ми версия. И така, предизвикателството е в сила! Призовавам всички джедаи, падауани, магьосници и чираци. Кое е най-ефективното решение, което можете да измислите? Имате ли в себе си, за да победите най-бързото решение, публикувано досега? Ако е така, споделете вашето като коментар към тази статия и не се колебайте да подобрите всяко решение, публикувано от други.
Изисквания:
- Приложете решението си като функция с вградена стойност на таблица (iTVF) с име dbo.GetNumsYourName с параметри @low AS BIGINT и @high AS BIGINT. Като пример вижте тези, които изпращам в края на тази статия.
- Можете да създадете поддържащи таблици в потребителската база данни, ако е необходимо.
- Можете да добавяте подсказки, ако е необходимо.
- Както споменахме, решението трябва да поддържа разделители от типа BIGINT, но можете да приемете максимална мощност на серията от 4 294 967 296.
- За да оценя производителността на вашето решение и да го сравня с други, ще го тествам с диапазона от 1 до 100 000 000, като в SSMS е активирано Отхвърляне на резултатите след изпълнение.
Успех на всички ни! Нека най-добрата общност победи.;)
Различни мощности за конструктора на стойностите на основната таблица
Експериментирах с различни мощности на основния CTE, започвайки с 2 и напредвайки в логаритмична скала, възвеждайки на квадрат предишната мощност във всяка стъпка:2, 4, 16 и 256.
Преди да започнете да експериментирате с различни основни мощности, може да е полезно да имате формула, която, като се има предвид основната мощност и максималният обхват, ще ви каже колко нива на CTEs имате нужда. Като предварителна стъпка е по-лесно първо да излезете с формула, която като се има предвид основната мощност и броя на нивата на CTE, изчислява каква е максималната резултантна мощност на обхвата. Ето такава формула, изразена в T-SQL:
DECLARE @basecardinality AS INT = 2, @levels AS INT = 5; SELECT POWER(1.*@basecardinality, POWER(2., @levels));
С горните примерни входни стойности този израз дава максимален обхват от 4,294,967,296.
След това обратната формула за изчисляване на броя на необходимите нива на CTE включва влагане на две лог функции, като така:
DECLARE @basecardinality AS INT = 2, @seriescardinality AS BIGINT = 4294967296; SELECT CEILING(LOG(LOG(@seriescardinality, @basecardinality), 2));
С горните примерни входни стойности този израз дава 5. Имайте предвид, че това число е в допълнение към базовия CTE, който има конструктора на стойността на таблицата, който нарекох L0 (за ниво 0) в моето решение.
Не ме питайте как стигнах до тези формули. Историята, на която се придържам, е, че Гандалф ми ги е произнесъл на елфийски в сънищата ми.
Нека преминем към тестване на производителността. Уверете се, че сте активирали Отхвърляне на резултатите след изпълнение в диалоговия прозорец Опции на SSMS заявка под Решетка, Резултати. Използвайте следния код, за да изпълните тест с основна CTE мощност от 2 (изисква 5 допълнителни нива на CTE):
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Получих плана, показан на фигура 1 за това изпълнение.
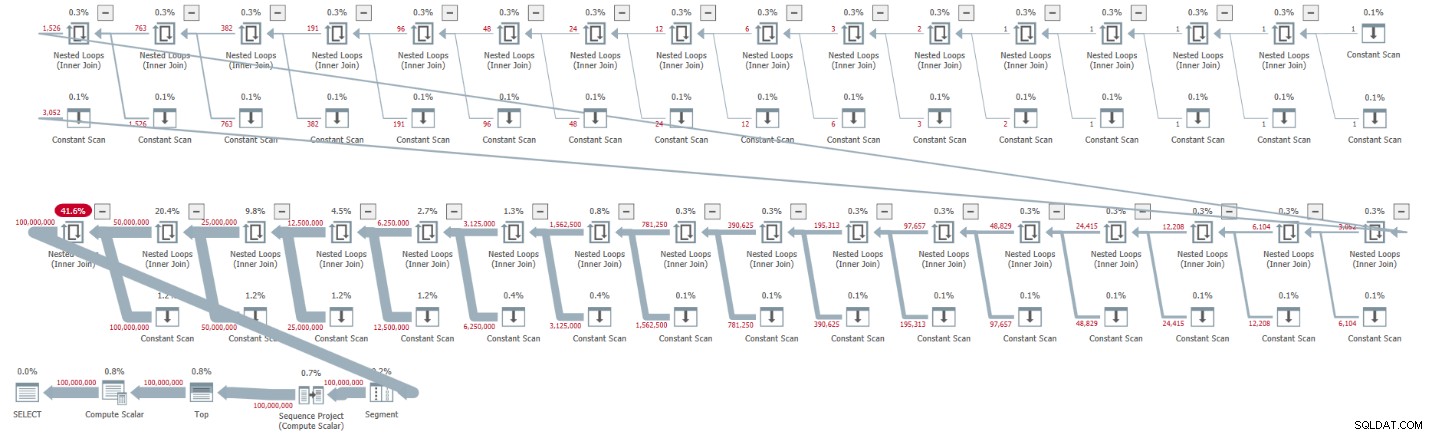 Фигура 1:План за базова CTE мощност от 2
Фигура 1:План за базова CTE мощност от 2
Планът е сериен и всички оператори в плана използват обработка в режим на ред по подразбиране. Ако получавате паралелен план по подразбиране, например, когато капсулирате решението в iTVF и използвате голям обхват, засега принудете сериен план с MAXDOP 1 намек.
Наблюдавайте как разопаковането на CTE е довело до 32 екземпляра на оператора Constant Scan, всеки от които представлява таблица с два реда.
Получих следните статистически данни за производителността за това изпълнение:
CPU time = 30188 ms, elapsed time = 32844 ms.
Използвайте следния код, за да тествате решението с основна CTE мощност от 4, което според нашата формула изисква четири нива на CTE:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L4 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Получих плана, показан на фигура 2 за това изпълнение.
 Фигура 2:План за базова CTE мощност от 4
Фигура 2:План за базова CTE мощност от 4
Разопаковането на CTE доведе до 16 оператора Constant Scan, всеки от които представлява таблица от 4 реда.
Получих следните статистически данни за производителността за това изпълнение:
CPU time = 23781 ms, elapsed time = 25435 ms.
Това е прилично подобрение от 22,5 процента спрямо предишното решение.
При проверка на статистиката за чакане, отчетена за заявката, доминиращият тип на чакане е SOS_SCHEDULER_YIELD. Всъщност броят на чакането е любопитно спаднал с 22,8 процента в сравнение с първото решение (брой на чакането 15 280 срещу 19 800).
Използвайте следния код, за да тествате решението с основна CTE мощност от 16, което според нашата формула изисква три нива на CTE:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Получих плана, показан на фигура 3 за това изпълнение.
 Фигура 3:План за базова CTE мощност от 16
Фигура 3:План за базова CTE мощност от 16
Този път разопаковането на CTEs доведе до 8 оператора Constant Scan, всеки от които представлява таблица с 16 реда.
Получих следните статистически данни за производителността за това изпълнение:
CPU time = 22968 ms, elapsed time = 24409 ms.
Това решение допълнително намалява изминалото време, макар и само с няколко допълнителни процента, което представлява намаление от 25,7 процента в сравнение с първото решение. Отново броят на чакането от типа SOS_SCHEDULER_YIELD продължава да намалява (12 938).
Напредвайки в нашата логаритмична скала, следващият тест включва основна CTE кардиналност от 256. Дълъг е и грозен, но опитайте:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L2 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Получих плана, показан на фигура 4 за това изпълнение.
 Фигура 4:План за базова CTE мощност от 256
Фигура 4:План за базова CTE мощност от 256
Този път разопаковането на CTEs доведе само до четири оператора Constant Scan, всеки с 256 реда.
Получих следните номера на производителността за това изпълнение:
CPU time = 23516 ms, elapsed time = 25529 ms.
Този път изглежда, че производителността се е влошила малко в сравнение с предишното решение с базова CTE мощност от 16. Всъщност броят на чакането на типа на чакане SOS_SCHEDULER_YIELD се увеличи малко до 13 176. И така, изглежда, че намерихме нашето златно число — 16!
Паралелни спрямо серийни планове
Експериментирах с налагането на паралелен план, използвайки намека ENABLE_PARALLEL_PLAN_PREFERENCE, но в крайна сметка това навреди на производителността. Всъщност, когато внедрявах решението като iTVF, получих паралелен план на моята машина по подразбиране за големи обхвати и трябваше да принудя сериен план с MAXDOP 1 намек, за да получа оптимална производителност.
Пакетна обработка
Основният ресурс, използван в плановете за моите решения, е CPU. Като се има предвид, че пакетната обработка е свързана с подобряване на ефективността на процесора, особено при работа с голям брой редове, струва си да опитате тази опция. Основната дейност тук, която може да се възползва от пакетната обработка, е изчисляването на номера на редове. Тествах решенията си в SQL Server 2019 Enterprise Edition. SQL Server по подразбиране избра обработка в режим на ред за всички по-горе показани решения. Очевидно това решение не премина евристичността, необходима за активиране на пакетен режим в rowstore. Има няколко начина да накарате SQL Server да използва пакетна обработка тук.
Вариант 1 е да включите таблица с индекс на columnstore в решението. Можете да постигнете това, като създадете фиктивна таблица с индекс на columnstore и въведете фиктивно ляво присъединяване в най-външната заявка между нашия Nums CTE и тази таблица. Ето дефиницията на фиктивната таблица:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
След това ревизирайте външната заявка спрямо Nums, за да използвате FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 =0. Ето пример с основна CTE мощност от 16:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Получих плана, показан на фигура 5 за това изпълнение.
 Фигура 5:План с пакетна обработка
Фигура 5:План с пакетна обработка
Наблюдавайте използването на оператора Window Aggregate в пакетния режим за изчисляване на номерата на редовете. Също така имайте предвид, че планът не включва фиктивната маса. Оптимизаторът го оптимизира.
Предимството на опция 1 е, че тя работи във всички издания на SQL Server и е уместна в SQL Server 2016 или по-нова версия, тъй като операторът Window Aggregate в пакетен режим беше въведен в SQL Server 2016. Недостатъкът е необходимостта от създаване на фиктивна таблица и включване в разтвора.
Вариант 2, за да получите пакетна обработка за нашето решение, при условие че използвате SQL Server 2019 Enterprise Edition, е да използвате недокументирания самообясним намек OVERRIDE_BATCH_MODE_HEURISTICS (подробности в статията на Дмитрий Пилугин), като така:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum
OPTION(USE HINT('OVERRIDE_BATCH_MODE_HEURISTICS')); Предимството на опция 2 е, че не е необходимо да създавате фиктивна таблица и да я включвате във вашето решение. Недостатъците са, че трябва да използвате Enterprise издание, да използвате минимум SQL Server 2019, където беше въведен пакетен режим в rowstore, а решението включва използване на недокументиран намек. Поради тези причини предпочитам вариант 1.
Ето числата за производителност, които получих за различните основни CTE кардинальности:
Cardinality 2: CPU time = 21594 ms, elapsed time = 22743 ms (down from 32844). Cardinality 4: CPU time = 18375 ms, elapsed time = 19394 ms (down from 25435). Cardinality 16: CPU time = 17640 ms, elapsed time = 18568 ms (down from 24409). Cardinality 256: CPU time = 17109 ms, elapsed time = 18507 ms (down from 25529).
Фигура 6 има сравнение на производителността между различните решения:
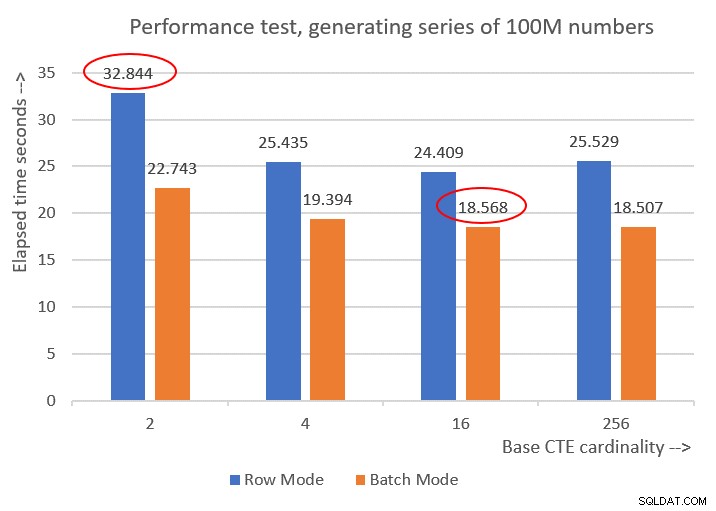 Фигура 6:Сравнение на производителността
Фигура 6:Сравнение на производителността
Можете да наблюдавате прилично подобрение на производителността от 20-30 процента в сравнение с тези в редовия режим.
Любопитното е, че при пакетна обработка решението с основна CTE мощност от 256 се справи най-добре. Въпреки това, това е само малко по-бързо от решението с базова CTE мощност от 16. Разликата е толкова малка, а последното има ясно предимство по отношение на краткостта на кода, че бих се придържал към 16.
И така, моите усилия за настройка в крайна сметка доведоха до подобрение от 43,5 процента от оригиналното решение с основна мощност 2, използвайки обработка в режим на ред.
Предизвикателството е включено!
Представям две решения като мой принос на общността към това предизвикателство. Ако работите на SQL Server 2016 или по-нова версия и можете да създадете таблица в потребителската база данни, създайте следната фиктивна таблица:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
И използвайте следната дефиниция на iTVF:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Използвайте следния код, за да го тествате (уверете се, че има отметка за отхвърляне на резултатите след изпълнение):
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Този код завършва за 18 секунди на моята машина.
Ако по някаква причина не можете да изпълните изискванията на решението за пакетна обработка, представям следната дефиниция на функцията като мое второ решение:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO Използвайте следния код, за да го тествате:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Този код завършва за 24 секунди на моята машина.
Твой ред!