Тази статия е осмата част от поредица за изрази на таблици. Досега предоставих фон на табличните изрази, покрих както логическите, така и оптимизационните аспекти на извлечените таблици, логическите аспекти на CTE и някои от аспектите на оптимизация на CTE. Този месец продължавам да отразявам аспектите на оптимизация на CTE, по-специално да се занимавам с това как се обработват множество CTE препратки.
Тази статия е осмата част от поредица за изрази на таблици. Досега предоставих фон на табличните изрази, покрих както логическите, така и оптимизационните аспекти на извлечените таблици, логическите аспекти на CTE и някои от аспектите на оптимизация на CTE. Този месец продължавам да отразявам аспектите на оптимизация на CTE, по-специално да се занимавам с това как се обработват множество CTE препратки.
В моите примери ще продължа да използвам примерната база данни TSQLV5. Можете да намерите скрипта, който създава и попълва TSQLV5 тук, и неговата ER диаграма тук.
Множество препратки и недетерминизъм
Миналия месец обясних и демонстрирах, че CTE се отменят, докато временните таблици и променливите на таблицата всъщност запазват данни. Дадох препоръки по отношение на това кога има смисъл да се използват CTE спрямо кога има смисъл да се използват временни обекти от гледна точка на производителността на заявката. Но има друг важен аспект на CTE оптимизацията или физическата обработка, който трябва да се вземе предвид извън производителността на решението – как се обработват множество препратки към CTE от външна заявка. Важно е да осъзнаете, че ако имате външна заявка с множество препратки към една и съща CTE, всяка от тях се отменя отделно. Ако имате недетерминистични изчисления във вътрешната заявка на CTE, тези изчисления могат да имат различни резултати в различните препратки.
Кажете например, че извиквате функцията SYSDATETIME във вътрешната заявка на CTE, създавайки колона с резултати, наречена dt. Като цяло, ако приемем, че няма промяна във входните данни, вградената функция се оценява веднъж на заявка и препратка, независимо от броя на участващите редове. Ако се позовавате на CTE само веднъж от външна заявка, но взаимодействате с колоната dt няколко пъти, всички препратки трябва да представляват една и съща оценка на функцията и да връщат едни и същи стойности. Въпреки това, ако се позовавате на CTE няколко пъти във външната заявка, било то с множество подзаявки, отнасящи се до CTE или свързване между множество екземпляри на един и същи CTE (да речем с псевдоним C1 и C2), препратките към C1.dt и C2.dt представлява различни оценки на основния израз и може да доведе до различни стойности.
За да демонстрирате това, разгледайте следните три партиди:
-- Пакет 1 ДЕКЛАРИРАНЕ @i КАТО INT =1; WHILE @@ROWCOUNT =1 SELECT @i +=1 WHERE SYSDATETIME() =SYSDATETIME(); ПЕЧАТ @i;GO -- Пакет 2 ДЕКЛАРИРАНЕ @i КАТО INT =1; ДОКАТО @@ROWCOUNT =1 С C AS ( ИЗБЕРЕТЕ SYSDATETIME() КАТО dt ) ИЗБЕРЕТЕ @i +=1 ОТ C КЪДЕТО dt =dt; ПЕЧАТ @i;GO -- Пакет 3 ДЕКЛАРИРАНЕ @i КАТО INT =1; WHILE @@ROWCOUNT =1 С C КАТО ( ИЗБЕРЕТЕ SYSDATETIME() КАТО dt ) ИЗБЕРЕТЕ @i +=1 КЪДЕ (ИЗБЕРЕТЕ dt ОТ C) =(ИЗБЕРЕТЕ dt ОТ C); ПЕЧАТ @i;GO
Въз основа на това, което току-що обясних, можете ли да идентифицирате кои от партидите имат безкраен цикъл и кой ще спре в някакъв момент поради двата компаранда на предиката, оценяващи различни стойности?
Не забравяйте, че казах, че извикване на вградена недетерминистична функция като SYSDATETIME се оценява веднъж на заявка и препратка. Това означава, че в пакет 1 имате две различни оценки и след достатъчно повторения на цикъла те ще доведат до различни стойности. Опитай. Колко повторения отчита кодът?
Що се отнася до партида 2, кодът има две препратки към колоната dt от един и същи CTE екземпляр, което означава, че и двете представляват една и съща оценка на функцията и трябва да представляват една и съща стойност. Следователно, партида 2 има безкраен цикъл. Стартирайте го за произволен период от време, но в крайна сметка ще трябва да спрете изпълнението на кода.
Що се отнася до пакет 3, външната заявка има две различни подзаявки, взаимодействащи с CTE C, като всяка представлява различен екземпляр, който преминава през процес на разместване поотделно. Кодът не присвоява изрично различни псевдоними на различните екземпляри на CTE, тъй като двете подзаявки се появяват в независими обхвати, но за да го улесните разбирането, можете да мислите за двата като за използване на различни псевдоними като C1 в една подзаявка и C2 в другия. Така че сякаш едната подзаявка взаимодейства с C1.dt, а другата с C2.dt. Различните препратки представляват различни оценки на основния израз и следователно могат да доведат до различни стойности. Опитайте да стартирате кода и вижте, че той спира в някакъв момент. Колко повторения отне, докато спре?
Интересно е да се опитате да идентифицирате случаите, в които имате една срещу множество оценки на основния израз в плана за изпълнение на заявката. Фигура 1 показва графичните планове за изпълнение за трите партиди (щракнете, за да увеличите).
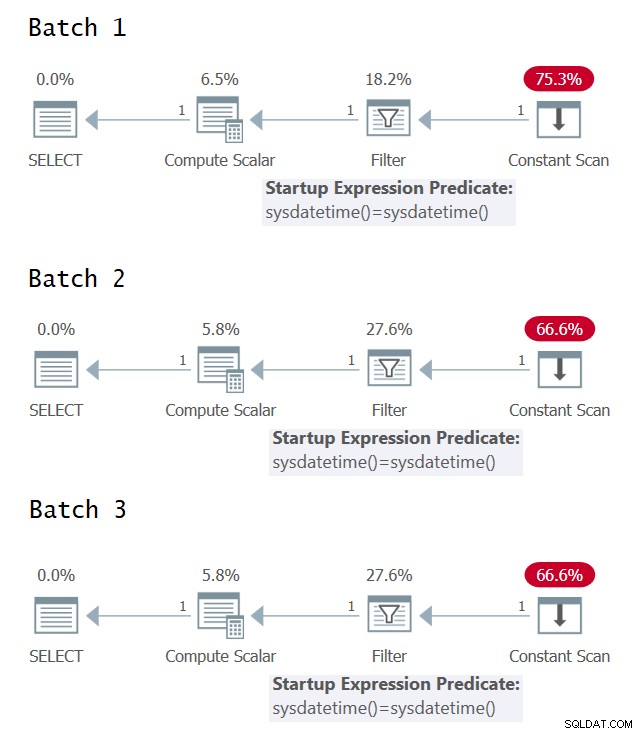 Фигура 1:Графични планове за изпълнение за партида 1, партида 2 и партида 3
Фигура 1:Графични планове за изпълнение за партида 1, партида 2 и партида 3
За съжаление, никаква радост от графичните планове за изпълнение; всички те изглеждат идентични, въпреки че семантично трите партиди нямат идентични значения. Благодарение на @CodeRecce и Forrest (@tsqladdict), като общност успяхме да стигнем до дъното на това с други средства.
Както @CodeRecce откри, XML плановете съдържат отговора. Ето съответните части от XML за трите партиди:
−− Пакет 1
<Предикат>
…
…
−− Пакет 2
<Предикат>
…
<Идентификатор>
<Идентификатор>
…
−− Пакет 3
<Предикат>
…
<Идентификатор>
<Идентификатор>
…
Можете ясно да видите в XML плана за пакет 1, че предикатът на филтъра сравнява резултатите от две отделни директни извиквания на присъщата функция SYSDATETIME.
В XML плана за пакет 2 предикатът на филтъра сравнява константния израз ConstExpr1002, представляващ едно извикване на функцията SYSDATETIME със себе си.
В XML плана за пакет 3 предикатът на филтъра сравнява два различни константни израза, наречени ConstExpr1005 и ConstExpr1006, като всеки представлява отделно извикване на функцията SYSDATETIME.
Като друга опция, Forrest (@tsqladdict) предложи използването на флаг за проследяване 8605, който показва първоначалното представяне на дървото на заявките, създадено от SQL Server, след активиране на флаг за проследяване 3604, което кара изходът на TF 8605 да бъде насочен към SSMS клиента. Използвайте следния код, за да активирате и двата флага за проследяване:
DBCC TRACEON(3604); -- директен изход към clientGO DBCC TRACEON(8605); -- показване на първоначалното дърво на заявкатаGO
След това стартирате кода, за който искате да получите дървото на заявката. Ето съответните части от изхода, който получих от TF 8605 за трите партиди:
−− Пакет 1
*** Преобразувано дърво:***
LogOp_Project COL:Expr1000
LogOp_Select
LogOp_ConstTableGet (1) [празна]
ScaOp_Comp x_cmpEq
ScaOp_Intrinsic sysdatetime
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1)
−− Пакет 2
*** Преобразувано дърво:***
LogOp_Project COL:Expr1001
LogOp_Select
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [празна]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
ScaOp_Comp x_cmpEq
ScaOp_Identifier COL:Expr1000
ScaOp_Identifier COL:Expr1000
AncOp_PrjList
AncOp_PrjEl COL:Expr1001
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1)
−− Пакет 3
*** Преобразувано дърво:***
LogOp_Project COL:Expr1004
LogOp_Select
LogOp_ConstTableGet (1) [празна]
ScaOp_Comp x_cmpEq
ScaOp_Subquery COL:Expr1001
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [празна]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1001
ScaOp_Identifier COL:Expr1000
ScaOp_Subquery COL:Expr1003
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [празна]
AncOp_PrjList
AncOp_PrjEl COL:Expr1002
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1003
ScaOp_Identifier COL:Expr1002
AncOp_PrjList
AncOp_PrjEl COL:Expr1004
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,не притежава,стойност=1)
В пакет 1 можете да видите сравнение между резултатите от две отделни оценки на присъщата функция SYSDATETIME.
В партида 2 виждате една оценка на функцията, която води до колона, наречена Expr1000, и след това сравнение между тази колона и самата нея.
В пакет 3 виждате две отделни оценки на функцията. Една в колона, наречена Expr1000 (по-късно проектирана от колоната на подзаявката, наречена Expr1001). Друга в колона, наречена Expr1002 (по-късно проектирана от колоната на подзаявката, наречена Expr1003). След това имате сравнение между Expr1001 и Expr1003.
Така че, с малко повече копаене извън това, което излага графичният план за изпълнение, всъщност можете да разберете кога основният израз се оценява само веднъж спрямо няколко пъти. След като вече разбирате различните случаи, можете да развиете своите решения въз основа на желаното поведение, което търсите.
Прозоречни функции с недетерминиран ред
Има друг клас изчисления, които могат да ви доведат до проблеми, когато се използват в решения с множество препратки към един и същ CTE. Това са прозоречни функции, които разчитат на недетерминистично подреждане. Вземете за пример функцията на прозореца ROW_NUMBER. Когато се използва с частична поръчка (подреждане по елементи, които не идентифицират уникално реда), всяка оценка на основната заявка може да доведе до различно присвояване на номерата на редовете, дори ако основните данни не са се променили. С множество CTE препратки, не забравяйте, че всяка се отменя отделно и можете да получите различни набори от резултати. В зависимост от това какво прави външната заявка с всяка препратка, напр. с кои колони от всяка препратка взаимодейства и как, оптимизаторът може да реши да получи достъп до данните за всеки от екземплярите, използвайки различни индекси с различни изисквания за подреждане.
Разгледайте следния код като пример:
ИЗПОЛЗВАЙТЕ TSQLV5; С C AS( SELECT *, ROW_NUMBER() НАД (ПОРЪЧКА ПО дата на поръчка) КАТО rownum ОТ Продажби.Поръчки)ИЗБЕРЕТЕ C1.orderid, C1.shipcountry, C2.orderidFROM C КАТО C1 ВЪТРЕШНО ПРИСЪЕДИНЕНИЕ C КАТО C2 НА C1.rownum =C2. rownumWHERE C1.orderid <> C2.orderid;
Може ли тази заявка някога да върне непразен набор от резултати? Може би първоначалната ви реакция е, че не може. Но помислете върху това, което току-що обясних малко по-внимателно и ще разберете, че поне на теория, поради двата отделни процеса на разглобяване на CTE, които ще се случат тук – един от C1 и друг от C2 – е възможно. Едно е обаче да теоретизираш, че нещо може да се случи, а друго е да го демонстрираш. Например, когато стартирах този код, без да създавам нови индекси, непрекъснато получавах празен набор от резултати:
orderid shipcountry orderid---------------- --------------- -----------(0 засегнати реда)Получих плана, показан на фигура 23 за тази заявка.
Фигура 2:Първи план за заявка с две CTE препратки
Това, което е интересно да се отбележи тук, е, че оптимизаторът е избрал да използва различни индекси, за да обработва различните CTE препратки, защото това е, което смята за оптимално. В крайна сметка всяка препратка във външната заявка се отнася до различно подмножество от CTE колоните. Едната препратка доведе до подредено напред сканиране на индекса idx_nc_orderedate, а другата до неподредено сканиране на клъстерирания индекс, последвано от операция за сортиране по нарастваща дата на поръчка. Въпреки че индексът idx_nc_orderedate е изрично дефиниран само в колоната за дата на поръчка като ключ, на практика той е дефиниран на (orderdate, orderid) като свои ключове, тъй като orderid е ключът на клъстерния индекс и е включен като последен ключ във всички неклъстерирани индекси. Така че подреденото сканиране на индекса всъщност излъчва редовете, подредени по дата на поръчка, orderid. Що се отнася до неподреденото сканиране на клъстерирания индекс, на нивото на машината за съхранение данните се сканират в ред на ключ на индекса (въз основа на orderid), за да се отговори на очакванията за минимална последователност на прочетеното ниво на изолация по подразбиране. Следователно операторът Sort поглъща данните, подредени по orderid, сортира редовете по дата на поръчка и на практика в крайна сметка излъчва редовете, подредени по orderdate, orderid.
Отново, на теория няма гаранция, че двете препратки винаги ще представляват един и същ набор от резултати, дори ако основните данни не се променят. Лесен начин да се демонстрира това е да се подредят два различни оптимални индекса за двете препратки, но единият да подреди данните по дата на поръчка ASC, подредена ASC, а другата да подреди данните по дата на поръчка DESC, orderid ASC (или точно обратното). Вече разполагаме с предишния индекс. Ето код за създаване на последното:
СЪЗДАВАЙТЕ ИНДЕКС idx_nc_odD_oid_I_sc НА Sales.Orders(orderdate DESC, orderid) INCLUDE(shipcountry);Изпълнете кода втори път след създаване на индекса:
С C AS( SELECT *, ROW_NUMBER() НАД (ПОРЪЧКА ПО дата на поръчка) КАТО rownum ОТ Sales.Orders)ИЗБЕРЕТЕ C1.orderid, C1.shipcountry, C2.orderidFROM C КАТО C1 ВЪТРЕШНО ПРИСЪЕДИНЕНИЕ C КАТО C2 НА C1.rownum =C2.rownumWHERE C1.orderid <> C2.orderid;Получих следния изход, когато стартирах този код след създаването на новия индекс:
orderid shipcountry orderid----------- ---------------- -----------10251 Франция 1025010250 Бразилия 1025110261 Бразилия 1026010260 Германия 1026110271 САЩ 10270...11070 Германия 1107311077 САЩ 1107411076 Франция 1107511075 Швейцария 1107611074 Дания 11077 (засегнати 546 реда)Ами сега.
Разгледайте плана на заявката за това изпълнение, както е показано на Фигура 3:
Фигура 3:Втори план за заявка с две CTE препратки
Забележете, че горният клон на плана сканира индекса idx_nc_orderdate по подреден начин напред, карайки оператора Sequence Project, който изчислява номерата на редовете, да поглъща данните на практика, подредени по дата на поръчка ASC, orderid ASC. Долният клон на плана сканира новия индекс idx_nc_odD_oid_I_sc по подреден обратен начин, карайки оператора на Sequence Project да поглъща данните на практика, подредени по дата на поръчка ASC, orderid DESC. Това води до различно подреждане на номерата на редовете за двете CTE препратки винаги, когато има повече от едно появяване на една и съща стойност на датата на поръчка. Следователно, заявката генерира непразен набор от резултати.
Ако искате да избегнете подобни грешки, една очевидна опция е да запазите резултата от вътрешната заявка във временен обект като временна таблица или променлива на таблица. Въпреки това, ако имате ситуация, в която предпочитате да се придържате към използването на CTE, простото решение е да използвате пълен ред във функцията на прозореца чрез добавяне на тайбрейк. С други думи, уверете се, че подреждате по комбинация от изрази, която уникално идентифицира ред. В нашия случай можете просто да добавите orderid изрично като тайбрейк, така:
С C AS( SELECT *, ROW_NUMBER() НАД (ПОРЪЧКА ПО дата на поръчка, идентификатор на поръчка) КАТО rownum ОТ Sales.Orders)ИЗБЕРЕТЕ C1.orderid, C1.shipcountry, C2.orderidFROM C КАТО C1 ВЪТРЕШНО ПРИСЪЕДИНЕНЕ C КАТО C2 НА C1 .rownum =C2.rownumWHERE C1.orderid <> C2.orderid;Получавате празен набор от резултати, както се очаква:
orderid shipcountry orderid---------------- --------------- -----------(0 засегнати реда)Без да добавяте допълнителни индекси, получавате плана, показан на Фигура 4:
Фигура 4:Трети план за заявка с две CTE препратки
Горният клон на плана е същият като за предишния план, показан на фигура 3. Долният клон обаче е малко по-различен. Новият индекс, създаден по-рано, всъщност не е идеален за новата заявка в смисъл, че няма подредените данни, както се нуждае от функцията ROW_NUMBER (orderdate, orderid). Това все още е най-тесният покриващ индекс, който оптимизаторът може да намери за съответната референтна CTE, така че е избран; обаче той е сканиран по подредено:фалшиво. След това изричен оператор за сортиране сортира данните по дата на поръчка, идентификатор на поръчката, както се нуждае от изчисление ROW_NUMBER. Разбира се, можете да промените дефиницията на индекса, така че датата на поръчка и идентификатор на поръчката да използват една и съща посока и по този начин изричното сортиране ще бъде елиминирано от плана. Основният момент обаче е, че като използвате тотална поръчка, вие избягвате да изпадате в проблеми поради тази специфична грешка.
Когато приключите, изпълнете следния код за почистване:
ОТПУСКАНЕ НА ИНДЕКС, АКО СЪЩЕСТВУВА idx_nc_odD_oid_I_sc НА Sales.Orders;Заключение
Важно е да се разбере, че множеството препратки към една и съща CTE от външна заявка водят до отделни оценки на вътрешната заявка на CTE. Бъдете особено внимателни с недетерминистичните изчисления, тъй като различните оценки могат да доведат до различни стойности.
Когато използвате функции на прозорец като ROW_NUMBER и агрегати с рамка, не забравяйте да използвате общ ред, за да избегнете получаването на различни резултати за един и същи ред в различните CTE препратки.