Индексите са ускорители на скоростта в SQL бази данни. Те могат да бъдат групирани или негрупирани. Но какво означава това и къде трябва да приложите всеки?
Познавам това чувство. Бил съм там. Новите често са объркани кой индекс да използват за кои колони. Въпреки това, дори експертите трябва да обмислят този въпрос, преди да вземат решение, а различните ситуации изискват различни решения. Както ще видите по-късно, има заявки, при които клъстериран индекс ще свети в сравнение с неклъстериран индекс и обратно.
Все пак, първо, трябва да опознаем всеки един от тях. Ако търсите същата информация, днес е вашият щастлив ден.
Тази статия ще ви каже какви са тези индекси и кога да използвате всеки. Разбира се, ще има примерни кодове, които да опитате на практика. Така че, вземете си чипса или пицата и малко сода или кафе и се пригответе да се потопите в това проницателно пътешествие.
Готови ли сте?
Какво е клъстериран индекс
Клъстерираният индекс е индекс, който дефинира физическия ред на сортиране на редовете в таблица или изглед.
За да видим това в реална форма, нека вземем Служител таблица в AdventureWorks2017 база данни.
Първичният ключ също е клъстериран индекс, а ключът се основава на BusinessEntityID колона. Когато направите SELECT на тази таблица без ORDER BY, ще видите, че тя е сортирана по първичния ключ.
Опитайте сами, като използвате кода по-долу:
USE AdventureWorks2017
GO
SELECT TOP 10 * FROM HumanResources.Employee
GO
Сега вижте резултата на Фигура 1:
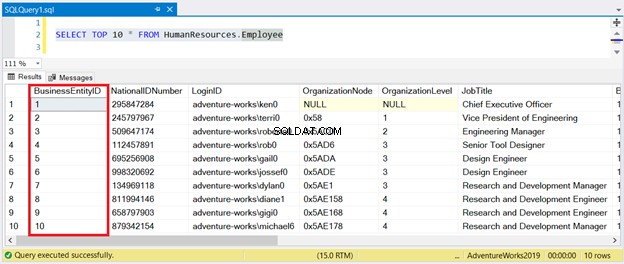
Както можете да видите, не е необходимо да сортирате набора от резултати с BusinessEntityID . Клъстерираният индекс се грижи за това.
За разлика от неклъстерираните индекси, можете да имате само 1 клъстериран индекс на таблица. Ами ако опитаме това на Служител маса?
CREATE CLUSTERED INDEX IX_Employee_NationalID
ON HumanResources.Employee (NationalIDNumber)
GO
Имаме подобна грешка по-долу:
Msg 1902, Level 16, State 3, Line 4
Cannot create more than one clustered index on table 'HumanResources.Employee'. Drop the existing clustered index 'PK_Employee_BusinessEntityID' before creating another.
Кога да използваме клъстериран индекс?
Колоната е най-добрият кандидат за клъстериран индекс, ако едно от следните е вярно:
- Използва се в голям брой заявки в клаузата WHERE и присъединява.
- Той ще се използва като външен ключ към друга таблица и в крайна сметка за присъединяване.
- Уникални стойности на колоните.
- Стойността ще се промени по-малко.
- Тази колона се използва за заявка за диапазон от стойности. Оператори като>, <,>=, <=или BETWEEN се използват с колоната в клаузата WHERE.
Но клъстерираните индекси не са добри, ако колоната или колоните
- често променяйте
- са широки клавиши или комбинация от колони с голям ключ.
Примери
Клъстерираните индекси могат да бъдат създадени с помощта на T-SQL код или всеки инструмент за GUI на SQL Server. Можете да го направите в T-SQL при създаване на таблица, както следва:
CREATE TABLE [Person].[Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)
GO
Или можете да направите това, като използвате ALTER TABLE след създаване на таблицата без клъстериран индекс:
ALTER TABLE Person.Person ADD CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED (BusinessEntityID)
GO
Друг начин е да използвате CREATE CLUSTERED INDEX:
CREATE CLUSTERED INDEX [PK_Person_BusinessEntityID] ON Person.Person (BusinessEntityID)
GO
Друга алтернатива е използването на инструмент за SQL Server като SQL Server Management Studio или dbForge Studio за SQL Server.
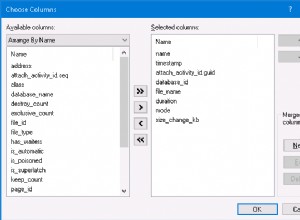
В Object Explorer , разширете базата данни и възлите на таблицата. След това щракнете с десния бутон върху желаната таблица и изберете Дизайн . Накрая щракнете с десния бутон върху колоната, която искате да бъде първичен ключ> Задаване на първичен ключ > Запазете промените в таблицата.
Фигура 2 по-долу показва къде BusinessEntityID е зададен като първичен ключ.
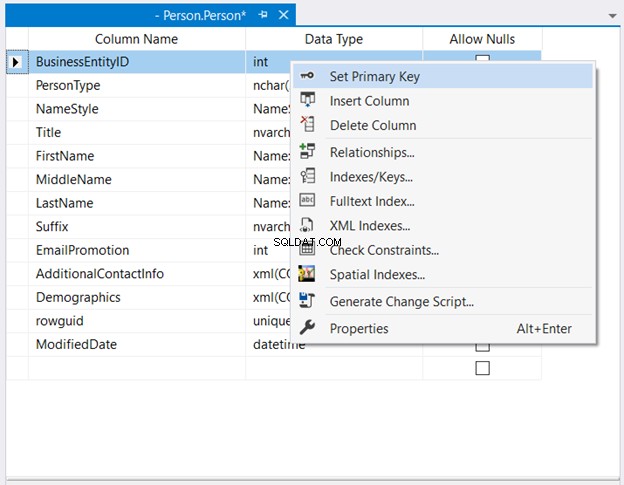
Освен създаването на клъстериран индекс с една колона, можете да използвате множество колони. Вижте пример в T-SQL:
CREATE CLUSTERED INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC
)
GO
След създаването на този клъстериран индекс, Лицето таблицата ще бъде физически сортирана по Фамилия , Име и MiddleName .
Едно от предимствата на този подход е подобрената производителност на заявката въз основа на името. Освен това сортира резултатите по име, без да указва ORDER BY. Но имайте предвид, че ако името се промени, таблицата ще трябва да бъде пренаредена. Въпреки че това няма да се случва всеки ден, въздействието може да бъде огромно, ако таблицата е много голяма.
Какво е неклъстериран индекс
Неклъстериран индекс е индекс с ключ и указател към редовете или клъстерираните индексни ключове. Този индекс може да се прилага както за таблици, така и за изгледи.
За разлика от клъстерираните индекси, тук структурата е отделна от таблицата. Тъй като е отделен, той се нуждае от указател към редовете на таблицата, наричан също локатор на редове. По този начин всеки запис в неклъстериран индекс съдържа локатор и ключова стойност.
Неклъстерираните индекси не сортират физически таблицата въз основа на ключа.
Индексните ключове за неклъстерирани индекси имат максимален размер от 1700 байта. Можете да заобиколите това ограничение, като добавите включени колони. Този метод е добър, ако вашата заявка трябва да покрие повече колони, без да увеличава размера на ключа.
Можете също да създадете филтрирани неклъстерирани индекси. Това ще намали разходите за поддръжка и съхранение на индекса, като същевременно ще подобри производителността на заявката.
Кога да използваме неклъстериран индекс?
Една колона или колони са добри кандидати за неклъстерирани индекси, ако е вярно следното:
- Колоната или колоните се използват в клауза WHERE или присъединяване.
- Заявката няма да върне голям набор от резултати.
- Необходимо е точното съвпадение в клаузата WHERE с помощта на оператора за равенство.
Примери
Тази команда ще създаде уникален, неклъстериран индекс в Служител таблица:
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON [HumanResources].[Employee]
(
[NationalIDNumber] ASC
)
GO
Освен таблица, можете да създадете неклъстериран индекс за изглед:
CREATE NONCLUSTERED INDEX [IDX_vProductAndDescription_ProductModel] ON [Production].[vProductAndDescription]
(
[ProductModel] ASC
)
GO
Други често задавани въпроси и удовлетворяващи отговори
Какви са разликите между клъстериран и неклъстериран индекс?
От това, което видяхте по-рано, вече можете да формирате идеи за това колко различни са клъстерирани и неклъстерни индекси. Но нека го поставим на маса за лесна справка.
| Информация | Клъстериран индекс | Неклъстериран индекс |
| Отнася се за | Таблици и изгледи | Таблици и изгледи |
| Разрешено за таблица | 1 | 999 |
| Размер на ключа | 900 байта | 1700 байта |
| Колони на индексен ключ | 32 | 32 |
| Добре за | Заявки за диапазон (>,<,>=, <=, МЕЖДУ) | Точни съвпадения (=) |
| Колони, които не са включени в ключ | Не е позволено | Разрешено |
| Филтър с условие | Не е позволено | Разрешено |
Трябва ли първичните ключове да бъдат групирани или неклъстерирани индекси?
Първичният ключ е ограничение. След като направите колона първичен ключ, от нея автоматично се създава клъстериран индекс, освен ако вече не е налице съществуващ клъстериран индекс.
Не бъркайте първичен ключ с клъстериран индекс! Първичен ключ може също да бъде клъстерираният индексен ключ. Но клъстериран индексен ключ може да бъде друга колона, различна от първичния ключ.
Да вземем друг пример. В Лице таблица на AdventureWorks201 7, имаме BusinessEntityID първичен ключ. Това също е клъстериран индексен ключ. Можете да пуснете този клъстериран индекс. След това създайте клъстериран индекс въз основа на Фамилия , Име , и Биско име . Първичният ключ все още е BusinessEntityID колона.
Но трябва ли вашите първични ключове винаги да бъдат групирани?
Зависи. Прегледайте отново въпроса кога да използвате клъстериран индекс.
Ако колона или колони се появяват във вашата клауза WHERE в много заявки, това е кандидат за клъстериран индекс. Но друго съображение е колко широк е клъстерираният индексен ключ. Твърде широк – и размерът на всеки неклъстериран индекс ще се увеличи, ако съществуват. Не забравяйте, че неклъстерираните индекси също използват ключът за клъстериран индекс като указател. Така че, поддържайте своя клъстериран индексен ключ възможно най-тесен.
Ако голям брой заявки използват първичния ключ в клаузата WHERE, оставете го също като клъстериран индексен ключ. Ако не, създайте своя първичен ключ като неклъстериран индекс.
Но какво ще стане, ако все още не сте сигурни? След това можете да оцените ползата от производителността на колона, когато е клъстерирана или негрупирана. Така че, настройте се на следващия раздел за това.
Кое е по-бързо:клъстериран или неклъстериран индекс?
Добър въпрос. Няма общо правило. Трябва да проверите логическите показания и плана за изпълнение на вашите заявки.
Нашият кратък експеримент ще включва копия на следните таблици от AdventureWorks2017 база данни:
- Лице
- BusinessEntityAddress
- Адрес
- Тип адрес
Ето скрипта:
IF NOT EXISTS(SELECT name FROM sys.databases WHERE name = 'TestDatabase')
BEGIN
CREATE DATABASE TestDatabase
END
USE TestDatabase
GO
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkClustered FROM AdventureWorks2017.Person.Person
ALTER TABLE Person_pkClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID2] PRIMARY KEY CLUSTERED (BusinessEntityID)
CREATE NONCLUSTERED INDEX [IX_Person_Name2] ON Person_pkClustered (LastName, FirstName, MiddleName, Suffix)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkNonClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkNonClustered FROM AdventureWorks2017.Person.Person
CREATE CLUSTERED INDEX [IX_Person_Name1] ON Person_pkNonClustered (LastName, FirstName, MiddleName, Suffix)
ALTER TABLE Person_pkNonClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID1] PRIMARY KEY NONCLUSTERED (BusinessEntityID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'AddressType')
BEGIN
SELECT * INTO AddressType FROM AdventureWorks2017.Person.AddressType
ALTER TABLE AddressType
ADD CONSTRAINT [PK_AddressType] PRIMARY KEY CLUSTERED (AddressTypeID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Address')
BEGIN
SELECT * INTO Address FROM AdventureWorks2017.Person.Address
ALTER TABLE Address
ADD CONSTRAINT [PK_Address] PRIMARY KEY CLUSTERED (AddressID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'BusinessEntityAddress')
BEGIN
SELECT * INTO BusinessEntityAddress FROM AdventureWorks2017.Person.BusinessEntityAddress
ALTER TABLE BusinessEntityAddress
ADD CONSTRAINT [PK_BusinessEntityAddress] PRIMARY KEY CLUSTERED (BusinessEntityID, AddressID, AddressTypeID)
END
GO
Използвайки структурата по-горе, ще сравним скоростите на заявки за клъстерирани и неклъстерни индекси.
Имаме 2 копия на Лицето маса. Първият ще използва BusinessEntityID като първичен и клъстериран индексен ключ. Вторият все още използва BusinessEntityID като първичен ключ. Клъстерираният индекс се основава на Фамилно име , Име , Биско име и Суфикс .
Да започнем.
ЗАПЪРВАНЕ НА ТОЧНИ СЪВПАДЕНИЯ ВЪЗДЕЙСТВИЕ НА ФАМИЛНОТО ИМЕ
Първо, нека направим проста заявка. Също така трябва да включите STATISTICS IO. След това поставяме резултатите в statisticsparser.com за таблично представяне.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, p.Title
FROM Person_pkClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SET STATISTICS IO OFF
GO
Очакванията са, че първият SELECT ще бъде по-бавен, защото клаузата WHERE не съвпада с клъстерирания индексен ключ. Но нека проверим логическите показания.
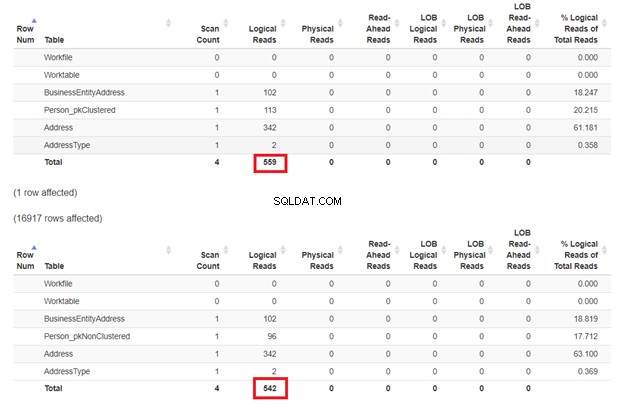
Както се очаква на фигура 3, Person_pkClustered имаше по-логични прочити. Следователно, заявката се нуждае от повече I/O. Причината? Таблицата е сортирана по BusinessEntityID . И все пак, втората таблица има клъстериран индекс, базиран на името. Тъй като заявката иска резултат въз основа на името, Person_pkNonClustered печели. Колкото по-малко логично четене, толкова по-бърза е заявката.
Какво друго става? Вижте фигура 4.
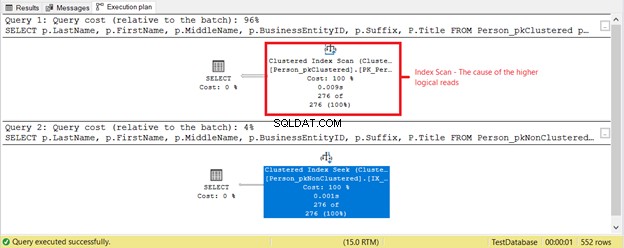
Нещо друго се случи на базата на плана за изпълнение на фигура 4. Защо сканирането на клъстериран индекс е в първия SELECT вместо търсене на индекс? Виновникът е Заглавието колона в SELECT. Той не е обхванат от нито един от съществуващите индекси. Оптимизаторът на SQL Server прецени, че е по-бързо да използва клъстерирания индекс въз основа на BusinessEntityID. След това SQL Server го сканира за правилните фамилни имена и получи първото име, бащиното име и титлата.
Премахнете Заглавието колона, а използваният оператор ще бъде Търсене в индекс . Защо? Тъй като останалите полета са покрити от неклъстерирания индекс въз основа на Фамилия , Име , Биско име и Суфикс . Той също така включва BusinessEntityID като ключов локатор на клъстериран индекс.
ЗАЯВКА ЗА ДИАПАЗОН, БАЗА НА ИДЕНТИФИКАЦИЯ НА БИЗНЕС СУБЕКТ
Клъстерираните индекси могат да бъдат добри за заявки за диапазон. Винаги ли е така? Нека разберем, като използваме кода по-долу.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SET STATISTICS IO OFF
GO
Списъкът се нуждае от редове въз основа на диапазон от BusinessEntityID от 285 до 290. Отново, клъстерираните и неклъстерираните индекси на 2-те таблици са непокътнати. Сега, нека имаме логическите показания на фигура 5. Очакваният победител е Person_pkClustered тъй като първичният ключ е и клъстерният индексен ключ.

Виждате ли по-ниски логически показания на Person_pkClustered ? Клъстерираните индекси доказаха своята стойност при заявки за диапазон в този сценарий. Нека видим какво повече ще разкрие планът за изпълнение на фигура 6.
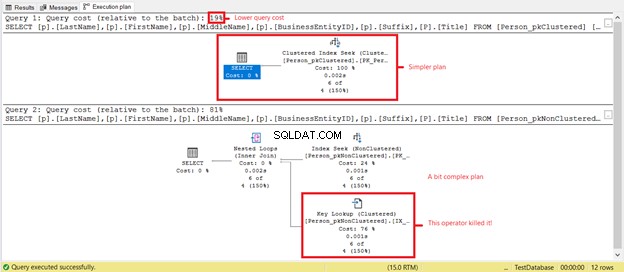
Първият SELECT има по-опростен план и по-ниска цена на заявката въз основа на Фигура 7. Това също така поддържа по-ниски логически четения. Междувременно вторият SELECT има оператор Key Lookup, който забавя заявката. Виновникът? Отново това е Заглавието колона. Премахнете колоната в заявката или я добавете като Включена колона в неклъстерирания индекс. Тогава ще имате по-добър план и по-ниски логически показания.
ЗАПЪРВАНЕ НА ТОЧНИ СЪВПАДЕНИЯ С ПРИСЪЕДИНЯВАНЕ
Много оператори SELECT включват съединения. Нека направим някои тестове. Тук започваме с точни съвпадения:
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SET STATISTICS IO OFF
GO
Очакваме втория SELECT от Person_pkNonClustered с клъстериран индекс на името ще има по-малко логично четене. Но дали е така? Вижте Фигура 7.
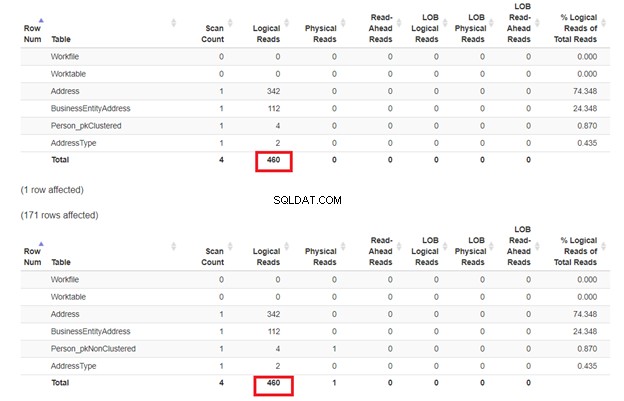
Изглежда, че неклъстерираният индекс на името се справи добре. Логическите показания са еднакви. Ако проверите плана за изпълнение, разликата в операторите е Clustered Index Seek на Person_pkNonClustered и търсенето на индекс на Person_pkClustered .
Така че, трябва да проверим логическите четения и плана за изпълнение, за да сме сигурни.
ЗАЯВКА ЗА ОБХВАТ СЪС СЪЕДИНЕНИЯ
Тъй като очакванията ни могат да се различават от реалността, нека опитаме със заявки за диапазон. Клъстерираните индекси обикновено са добри с него. Но какво ще стане, ако включите присъединяване?
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SET STATISTICS IO OFF
GO
Сега проверете логическите показания на тези 2 заявки на фигура 8:
Какво стана? На фигура 9 реалността се захапва в Person_pkClustered . В него се наблюдават повече I/O разходи в сравнение с Person_pkNonClustered . Това е различно от това, което очакваме. Но въз основа на този отговор във форума, търсенето на неклъстериран индекс може да бъде по-бързо от търсенето на клъстериран индекс, когато всички колони в заявката са 100% покрити в индекса. В нашия случай заявката за Person_pkNonClustered покри колоните, използвайки неклъстерирания индекс (BusinessEntityID – ключ; Фамилия , Име , Биско име , Наставка – указател към клъстериран индексен ключ).
ВМЪКНЕТЕ ИЗПЪЛНЕНИЕ
След това опитайте да тествате производителността на INSERT в същите таблици.
SET STATISTICS IO ON
GO
INSERT INTO Person_pkClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
INSERT INTO Person_pkNonClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
SET STATISTICS IO OFF
GO
Фигура 9 показва логическото четене на INSERT:

И двете генерираха един и същ I/O. По този начин и двете направиха едно и също.
ИЗТРИВАНЕ НА ЕФЕКТИВНОСТ
Последният ни тест включва DELETE:
SET STATISTICS IO ON
GO
DELETE FROM Person_pkClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
DELETE FROM Person_pkNonClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
SET STATISTICS IO OFF
GO
Фигура 10 показва логическите показания. Обърнете внимание на разликата.

Защо имаме по-високи логически показания на Person_pkClustered ? Работата е там, че условието на израза DELETE се основава на точно съвпадение на име. Оптимизаторът първо ще трябва да прибегне до неклъстерирания индекс. Това означава повече I/O. Нека потвърдим с помощта на плана за изпълнение на фигура 11.
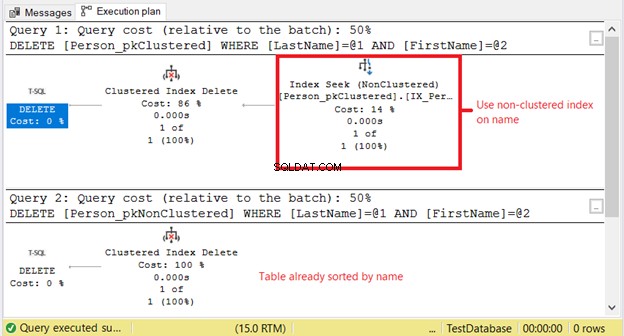
Първият SELECT се нуждае от търсене на индекс на неклъстерирания индекс. Причината е клаузата WHERE в Фамилия и Име . Междувременно Person_pkNonClustered вече е физически сортиран по име поради клъстерирания индекс.
Вземане за вкъщи
Формирането на високоефективни заявки не е свързано с късмет. Не можете просто да поставите клъстериран и неклъстериран индекс и тогава изведнъж вашите заявки имат силата на скорост. Трябва да продължите да използвате инструментите като обектив, за да се фокусирате върху малките детайли, различни от набора от резултати.
Но понякога просто нямате време да направите всичко това. Мисля, че това е нормално. Но стига да не бъркате толкова много, имате работата си на следващия ден и можете да я свършите. Това в началото няма да е лесно. Всъщност ще бъде объркващо. Ще имате и много въпроси. Но с постоянна практика можете да го постигнете. Така че, дръж брадичката си вдигната.
Не забравяйте, че както клъстерираните, така и неклъстерните индекси са за повишаване на заявките. Познаването на ключовите разлики, сценариите на използване и инструментите ще ви помогне в стремежа ви за кодиране на високоефективни заявки.
Надявам се тази публикация да отговори на най-належащите ви въпроси относно клъстерираните и неклъстерирани индекси. Имате ли още нещо да добавите за нашите читатели? Разделът за коментари е отворен.
И ако намирате тази публикация за поучителна, моля, споделете я в любимите си социални медийни платформи.
Повече информация за индексите и ефективността на заявките е в статиите по-долу:
- 22 изящни примера за SQL индекс за ускоряване на вашите заявки
- Оптимизация на SQL заявки:5 основни факта за повишаване на вашите заявки