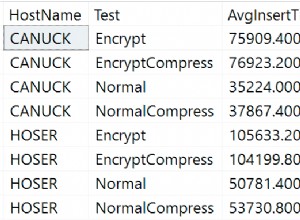
Тази статия е втората от поредицата за грешки в T-SQL, клопки и най-добри практики. Този път се фокусирам върху класическите грешки, включващи подзаявки. По-специално разглеждам грешките при заместване и тризначните логически проблеми. Няколко от темите, които обхващам в поредицата, бяха предложени от колеги MVP в дискусия, която проведохме по темата. Благодарим на Ерланд Сомарског, Аарон Бертран, Алехандро Меса, Умачандар Джаячандран (UC), Фабиано Невес Аморим, Милош Радивоевич, Саймън Сабин, Адам Мачаник, Томас Гросер, Чан Минг Ман и Пол Уайт за вашите предложения!
Грешка при заместване
За да демонстрирам класическата грешка при заместване, ще използвам прост сценарий за поръчки на клиенти. Изпълнете следния код, за да създадете помощна функция, наречена GetNums, и да създадете и попълните таблиците с клиенти и поръчки:
SET NOCOUNT ON;
USE tempdb;
GO
DROP TABLE IF EXISTS dbo.Orders;
DROP TABLE IF EXISTS dbo.Customers;
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
CREATE TABLE dbo.Customers
(
custid INT NOT NULL
CONSTRAINT PK_Customers PRIMARY KEY,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100);
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
customerid INT NOT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (customerid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_customerid ON dbo.Orders(customerid); В момента таблицата „Клиенти“ има 100 клиенти с последователни идентификатори на клиенти в диапазона от 1 до 100. 98 от тези клиенти имат съответни поръчки в таблицата „Поръчки“. Клиенти с идентификационни номера 17 и 59 все още не са направили никакви поръчки и следователно нямат присъствие в таблицата с поръчки.
Търсите само клиенти, които са направили поръчки и се опитвате да постигнете това, като използвате следната заявка (наречете я Заявка 1):
SET NOCOUNT OFF; SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT custid FROM dbo.Orders);
Би трябвало да върнете 98 клиенти, но вместо това получавате всичките 100 клиенти, включително тези с идентификационни номера 17 и 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 17 Cust 17 18 Cust 18 ... 58 Cust 58 59 Cust 59 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (100 rows affected)
Можете ли да разберете какво не е наред?
За да добавите объркването, разгледайте плана за заявка 1, както е показано на фигура 1.
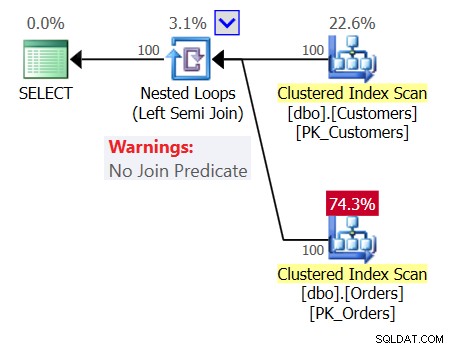 Фигура 1:План за заявка 1
Фигура 1:План за заявка 1
Планът показва оператор с вложени цикли (ляво полуприсъединяване) без предикат за присъединяване, което означава, че единственото условие за връщане на клиент е да имате непразна таблица с поръчки, сякаш заявката, която сте написали, е следната:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Вероятно сте очаквали план, подобен на този, показан на фигура 2.
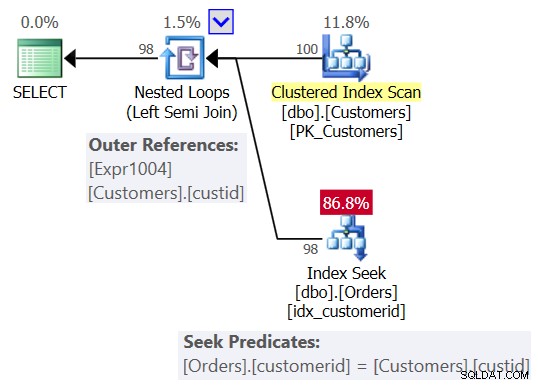 Фигура 2:Очакван план за заявка 1
Фигура 2:Очакван план за заявка 1
В този план виждате оператор Nested Loops (Left Semi Join), със сканиране на клъстерирания индекс на Клиенти като външен вход и търсене в индекса в колоната customerid в Поръчките като вътрешен вход. Също така виждате външна препратка (корелиран параметър) въз основа на колоната custid в Customers и предиката за търсене Orders.customerid =Customers.custid.
Така че защо получавате плана на фигура 1, а не този на фигура 2? Ако все още не сте го разбрали, разгледайте отблизо дефинициите на двете таблици – по-специално имената на колоните – и имената на колоните, използвани в заявката. Ще забележите, че таблицата Customers съдържа идентификатори на клиенти в колона, наречена custid, а таблицата Orders съдържа идентификатори на клиенти в колона, наречена customerid. Въпреки това, кодът използва custid както във външните, така и във вътрешните заявки. Тъй като препратката към custid във вътрешната заявка е неквалифицирана, SQL Server трябва да реши от коя таблица идва колоната. Съгласно стандарта на SQL, SQL Server трябва да търси първо колоната в таблицата, която е запитана в същия обхват, но тъй като в поръчките няма колона, наречена custid, след това трябва да я търси в таблицата във външната обхват и този път има съвпадение. Така неволно препратката към custid става имплицитно свързана препратка, сякаш сте написали следната заявка:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT Customers.custid FROM dbo.Orders);
При условие, че Orders не е празен и че външната custid стойност не е NULL (не може да бъде в нашия случай, тъй като колоната е дефинирана като NOT NULL), винаги ще получите съвпадение, защото сравнявате стойността със себе си . Така заявка 1 става еквивалентна на:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Ако външната таблица поддържа NULL в колоната custid, заявка 1 би била еквивалентна на:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders) AND custid IS NOT NULL;
Сега разбирате защо заявка 1 е оптимизирана с плана на фигура 1 и защо сте върнали всичките 100 клиенти.
Преди време посетих клиент, който имаше подобен бъг, но за съжаление с оператор DELETE. Помислете за момент какво означава това. Всички редове в таблицата бяха изтрити, а не само тези, които първоначално възнамеряваха да изтрият!
Що се отнася до най-добрите практики, които могат да ви помогнат да избегнете подобни грешки, има две основни. Първо, доколкото можете да го контролирате, уверете се, че използвате последователни имена на колони в таблиците за атрибути, които представляват едно и също нещо. Второ, уверете се, че таблиците квалифицирани препратки към колони в подзаявки, включително в самостоятелни такива, където това не е обичайна практика. Разбира се, можете да използвате псевдоним на таблица, ако предпочитате да не използвате пълни имена на таблици. Прилагайки тази практика към нашата заявка, да предположим, че първоначалният ви опит е използвал следния код:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.custid FROM dbo.Orders AS O);
Тук не позволявате неявно разрешаване на имена на колони и следователно SQL Server генерира следната грешка:
Msg 207, Level 16, State 1, Line 108 Invalid column name 'custid'.
Отивате и проверявате метаданните за таблицата Orders, разбирате, че сте използвали грешно име на колона, и коригирате заявката (наречете тази заявка 2), така:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.customerid FROM dbo.Orders AS O);
Този път получавате правилния резултат с 98 клиенти, с изключение на клиентите с идентификационни номера 17 и 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 18 Cust 18 .. 58 Cust 58 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (98 rows affected)
Получавате и очаквания план, показан по-рано на Фигура 2.
Като настрана е ясно защо Customers.custid е външна препратка (корелиран параметър) в оператора Nested Loops (Left Semi Join) на Фигура 2. Това, което е по-малко очевидно, е защо Expr1004 се появява в плана и като външна препратка. Колегата на SQL Server MVP, Пол Уайт, теоретизира, че това може да бъде свързано с използване на информация от листа на външния вход, за да намекне механизма за съхранение, за да се избегне дублиране на усилия от механизмите за четене напред. Можете да намерите подробности тук.
Тризначна логическа грешка
Често срещана грешка, включваща подзаявки, е свързана със случаите, когато външната заявка използва предиката NOT IN и подзаявката може потенциално да върне NULL сред своите стойности. Например, да предположим, че трябва да можете да съхранявате поръчки в нашата таблица с поръчки с NULL като идентификатор на клиента. Такъв случай би представлявал поръчка, която не е свързана с нито един клиент; например поръчка, която компенсира несъответствията между действителния брой продукти и броя, записани в базата данни.
Използвайте следния код, за да пресъздадете таблицата „Поръчки“ с custid колоната, позволяваща NULL, и засега я попълнете със същите примерни данни, както преди (с поръчки по идентификационни номера на клиенти от 1 до 100, с изключение на 17 и 59):
DROP TABLE IF EXISTS dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
custid INT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (custid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_custid ON dbo.Orders(custid); Забележете, че докато сме на това, следвах най-добрата практика, обсъдена в предишния раздел, за да използвам последователни имена на колони в таблиците за едни и същи атрибути и наименувах колоната в таблицата „Поръчки“ custid точно както в таблицата „Клиенти“.
Да предположим, че трябва да напишете заявка, която връща клиенти, които не са направили поръчки. Вие измисляте следното опростено решение, използвайки предиката NOT IN (наречете го Query 3, първо изпълнение):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Тази заявка връща очаквания изход с клиенти 17 и 59:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
В склада на фирмата се прави инвентаризация и се установява несъответствие между действителното количество на даден продукт и количеството, записано в базата данни. Така че добавяте фиктивна компенсационна поръчка, за да отчетете несъответствието. Тъй като няма реален клиент, свързан с поръчката, използвате NULL като идентификатор на клиента. Изпълнете следния код, за да добавите такава заглавка на поръчката:
INSERT INTO dbo.Orders(custid) VALUES(NULL);
Изпълнете заявка 3 за втори път:
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Този път получавате празен резултат:
custid companyname ------- ------------ (0 rows affected)
Ясно е, че нещо не е наред. Знаете, че клиенти 17 и 59 не са направили никакви поръчки и наистина те се появяват в таблицата с клиенти, но не и в таблицата с поръчки. И все пак резултатът от заявката твърди, че няма клиент, който да не е направил никакви поръчки. Можете ли да разберете къде е грешката и как да я поправите?
Грешката е свързана с NULL в таблицата Orders, разбира се. За SQL NULL е маркер за липсваща стойност, която може да представлява приложим клиент. SQL не знае, че за нас NULL представлява липсващ и неприложим (неуместен) клиент. За всички клиенти в таблицата Клиенти, които присъстват в таблицата Поръчки, предикатът IN намира съвпадение, което дава TRUE и частта NOT IN го прави FALSE, поради което клиентският ред се отхвърля. Дотук добре. Но за клиенти 17 и 59 предикатът IN дава UNKNOWN, тъй като всички сравнения със стойности, различни от NULL, дават FALSE, а сравнението с NULL дава UNKNOWN. Не забравяйте, че SQL приема, че NULL може да представлява всеки приложим клиент, така че логическата стойност UNKNOWN показва, че не е известно дали външният идентификатор на клиента е равен на вътрешния NULL клиентски ID. НЕВЕЖНО ИЛИ НЕИЗВЕСТНО... ИЛИ НЕИЗВЕСТНО е НЕИЗВЕСТНО. Тогава частта NOT IN, приложена към UNKNOWN, все още води до UNKNOWN.
Казано по-просто на английски, вие поискахте да върнете клиенти, които не са направили поръчки. Така че естествено, заявката отхвърля всички клиенти от таблицата Клиенти, които присъстват в таблицата Поръчки, защото се знае със сигурност, че са направили поръчки. Що се отнася до останалите (17 и 59 в нашия случай) заявката ги отхвърля, тъй като към SQL, точно както не е известно дали са направили поръчки, също толкова неизвестно е дали не са направили поръчки, а филтърът се нуждае от сигурност (TRUE) в за да върнете ред. Каква туршия!
Така че веднага щом първото NULL попадне в таблицата Orders, от този момент винаги получавате празен резултат обратно от заявката NOT IN. Какво ще кажете за случаите, когато всъщност нямате NULL в данните, но колоната позволява NULL? Както видяхте при първото изпълнение на заявка 3, в такъв случай получавате правилния резултат. Може би си мислите, че приложението никога няма да въведе NULL в данните, така че няма за какво да се притеснявате. Това е лоша практика по няколко причини. От една страна, ако колона е дефинирана като позволяваща NULL, е почти сигурно, че NULL в крайна сметка ще стигнат до там, дори и да не се предполага; въпрос на време е. Това може да е резултат от импортиране на лоши данни, грешка в приложението и други причини. От друга страна, дори ако данните не съдържат NULL, ако колоната ги позволява, оптимизаторът трябва да отчете възможността NULL да присъстват, когато създава плана на заявката, а в нашата заявка НЕ ВЪВ това води до намаляване на производителността . За да демонстрирате това, разгледайте плана за първото изпълнение на заявка 3, преди да добавите реда с NULL, както е показано на фигура 3.
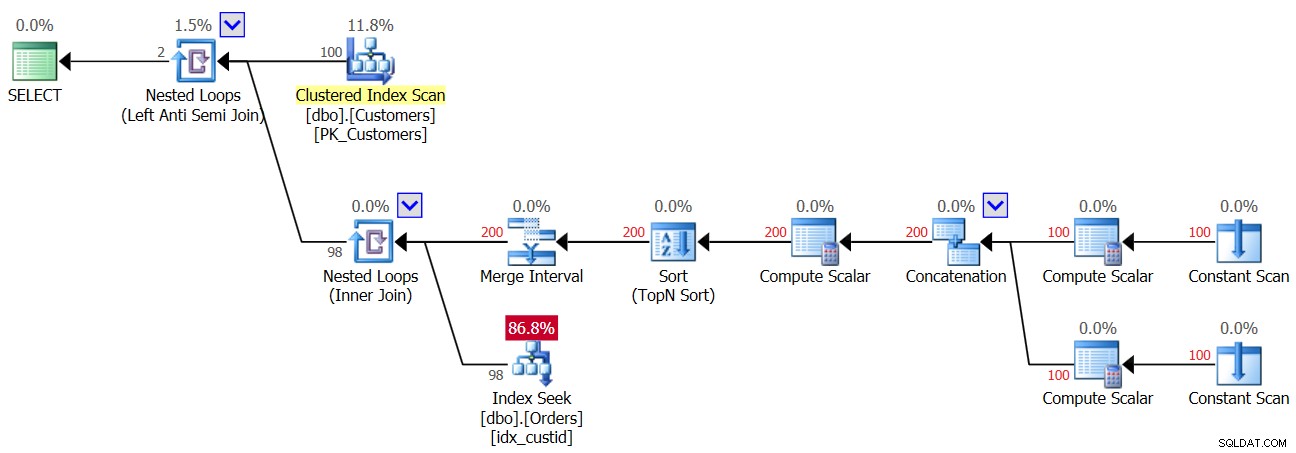 Фигура 3:План за първо изпълнение на заявка 3
Фигура 3:План за първо изпълнение на заявка 3
Най-горният оператор Nested Loops обработва логиката на Left Anti Semi Join. Това по същество е за идентифициране на несъответствия и късо съединение на вътрешната дейност веднага щом бъде намерено съвпадение. Външната част на цикъла изтегля всичките 100 клиента от таблицата Клиенти, следователно вътрешната част на цикъла се изпълнява 100 пъти.
Вътрешната част на горния цикъл изпълнява оператор Nested Loops (Inner Join). Външната част на долния цикъл създава два реда на клиент – един за NULL случай и друг за текущия клиентски идентификатор, в този ред. Не позволявайте на оператора Merge Interval да ви обърква. Обикновено се използва за сливане на припокриващи се интервали, например предикат като col1 МЕЖДУ 20 И 30 ИЛИ col1 МЕЖДУ 25 И 35 се преобразува в col1 МЕЖДУ 20 И 35. Тази идея може да бъде обобщена за премахване на дубликати в предикат IN. В нашия случай наистина не може да има дубликати. Опростено, както споменахме, мислете за външната част на цикъла като създаване на два реда на клиент – първият за NULL случай, а вторият за текущия клиентски идентификатор. Тогава вътрешната част на цикъла първо извършва търсене в индекса idx_custid при поръчки, за да търси NULL. Ако бъде намерено NULL, това не активира второто търсене на текущия клиентски идентификатор (запомнете късото съединение, управлявано от горния цикъл Anti Semi Join). В такъв случай външният клиент се отхвърля. Но ако NULL не бъде намерено, долният цикъл активира второ търсене за търсене на текущия клиентски идентификатор в Поръчки. Ако бъде намерен, външният клиент се отхвърля. Ако не бъде намерен, външният клиент се връща. Това означава, че когато NULL не присъстват в поръчките, този план извършва две търсения на клиент! Това може да се наблюдава в плана като броя на редовете 200 във външния вход на долния цикъл. Следователно, ето статистическите данни за I/O, които се отчитат за първото изпълнение:
Table 'Orders'. Scan count 200, logical reads 603
Планът за второто изпълнение на заявка 3, след като към таблицата Orders е добавен ред с NULL, е показан на фигура 4.
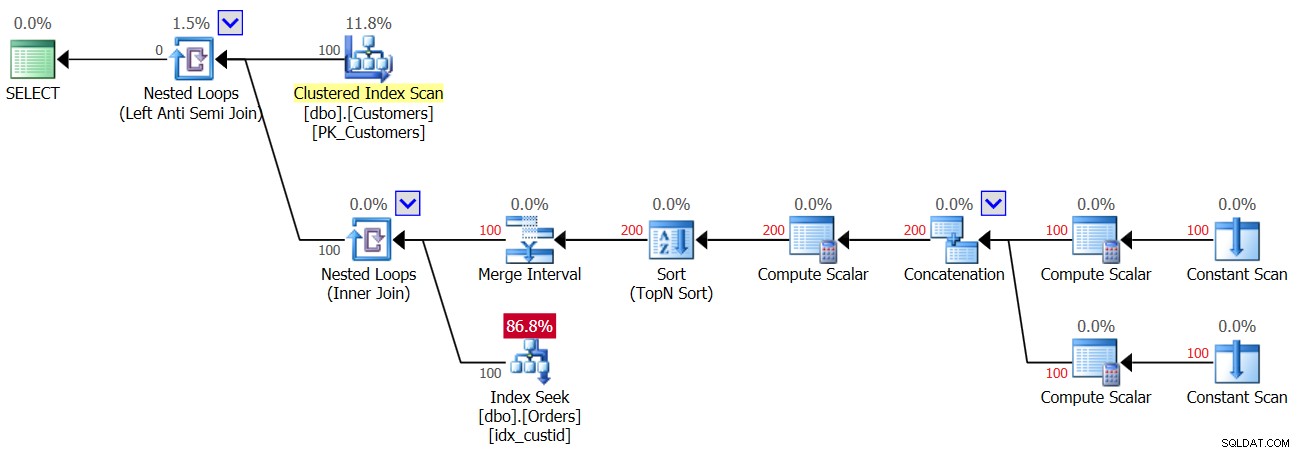 Фигура 4:План за второ изпълнение на заявка 3
Фигура 4:План за второ изпълнение на заявка 3
Тъй като в таблицата присъства NULL, за всички клиенти, първото изпълнение на оператора Index Seek намира съвпадение и следователно всички клиенти се отхвърлят. Така че, да, ние правим само едно търсене на клиент, а не две, така че този път получавате 100 търсения, а не 200; но в същото време това означава, че получавате празен резултат!
Ето статистическите данни за I/O, които се отчитат за второто изпълнение:
Table 'Orders'. Scan count 100, logical reads 300
Едно решение на тази задача, когато сред върнатите стойности в подзаявката са възможни NULL, е просто да ги филтрирате, като така (наречете го Решение 1/Запитване 4):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O WHERE O.custid IS NOT NULL);
Този код генерира очаквания изход:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Недостатъкът на това решение е, че трябва да запомните да добавите филтъра. Предпочитам решение, използващо предиката NOT EXISTS, където подзаявката има изрична корелация, сравняваща клиентския идентификатор на поръчката с идентификатора на клиента на клиента, като така (наречете го Решение 2/Запитване 5):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE NOT EXISTS (SELECT * FROM dbo.Orders AS O WHERE O.custid = C.custid);
Не забравяйте, че базирано на равенство сравнение между NULL и всичко дава UNKNOWN, а UNKNOWN се изхвърля от филтър WHERE. Така че, ако NULL съществуват в поръчките, те се елиминират от филтъра на вътрешната заявка, без да е необходимо да добавяте изрично третиране с NULL и следователно не е нужно да се притеснявате дали NULL съществуват или не в данните.
Тази заявка генерира очаквания изход:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Плановете и за двете решения са показани на Фигура 5.
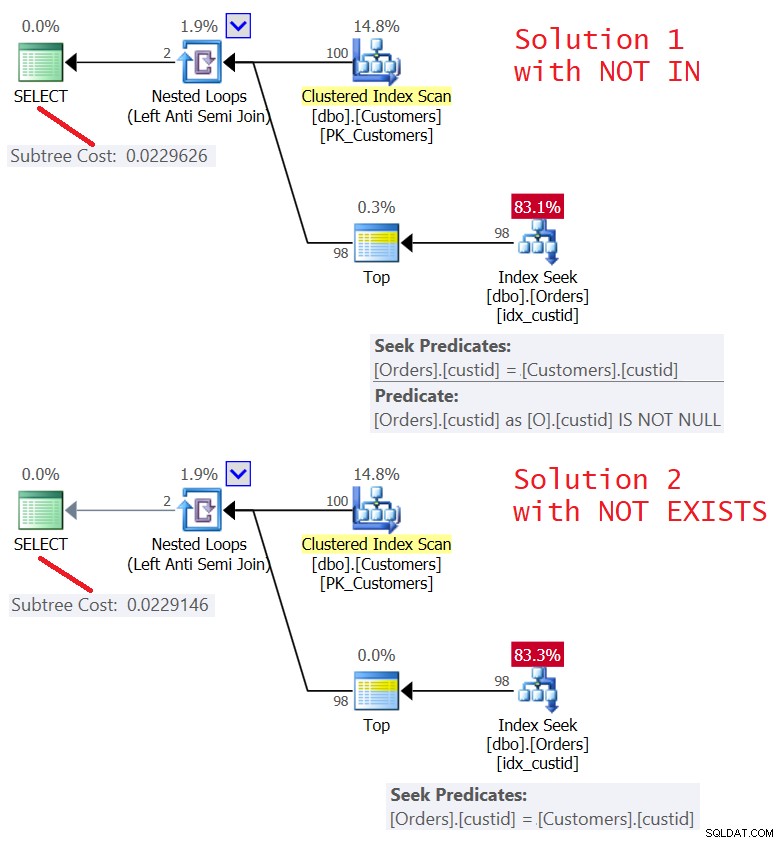 Фигура 5:Планове за заявка 4 (решение 1) и заявка 5 (решение 2 )
Фигура 5:Планове за заявка 4 (решение 1) и заявка 5 (решение 2 )
Както виждате, плановете са почти идентични. Те също са доста ефективни, като използват оптимизация на лявото полусъединяване с късо съединение. И двете извършват само 100 търсения в индекса idx_custid за поръчки и с оператора Top прилагат късо съединение след докосване на един ред в листа.
I/O статистиката и за двете заявки е една и съща:
Table 'Orders'. Scan count 100, logical reads 348
Едно нещо, което трябва да се има предвид обаче, е дали има някакъв шанс външната таблица да има NULL в корелираната колона (custid в нашия случай). Малко вероятно е да бъде уместно в сценарий като поръчки на клиенти, но може да бъде уместно в други сценарии. Ако това наистина е така, и двете решения обработват външно NULL неправилно.
За да демонстрирате това, пуснете и създайте отново таблицата Customers с NULL като един от клиентските идентификатори, като изпълните следния код:
DROP TABLE IF EXISTS dbo.Customers;
GO
CREATE TABLE dbo.Customers
(
custid INT NULL
CONSTRAINT UNQ_Customers_custid UNIQUE CLUSTERED,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT CAST(NULL AS INT) AS custid, 'Cust NULL' AS companyname
UNION ALL
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100); Решение 1 няма да върне външно NULL, независимо дали има вътрешно NULL или не.
Решение 2 ще върне външно NULL, независимо дали има вътрешно NULL или не.
Ако искате да обработвате NULL, както обработвате стойности, различни от NULL, т.е. да върнете NULL, ако присъства в Клиенти, но не и в Поръчки, и да не го връщате, ако присъства и в двете, трябва да промените логиката на решението, за да използвате отличителност -базирано сравнение вместо сравнение, базирано на равенство. Това може да се постигне чрез комбиниране на предиката EXISTS и оператора за набор EXCEPT, като така (наречете това Решение 3/Запитване 6):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Тъй като в момента има NULL както в клиенти, така и в поръчки, тази заявка правилно не връща NULL. Ето изхода от заявката:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Изпълнете следния код, за да премахнете реда с NULL от таблицата Orders и изпълнете отново Решение 3:
DELETE FROM dbo.Orders WHERE custid IS NULL; SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Този път, тъй като NULL присъства в Клиентите, но не и в Поръчките, резултатът включва NULL:
custid companyname ------- ------------ NULL Cust NULL 17 Cust 17 59 Cust 59 (3 rows affected)
Планът за това решение е показан на фигура 6:
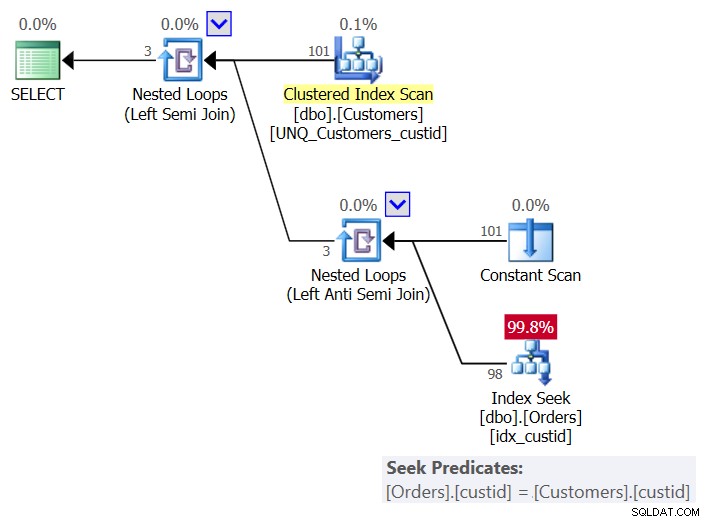 Фигура 6:План за заявка 6 (Решение 3)
Фигура 6:План за заявка 6 (Решение 3)
На клиент планът използва оператор Constant Scan, за да създаде ред с текущия клиент и прилага еднократно търсене в индекса idx_custid към Поръчки, за да провери дали клиентът съществува в Поръчки. В крайна сметка получавате едно търсене на клиент. Тъй като в момента имаме 101 клиента в таблицата, получаваме 101 търсения.
Ето I/O статистиката за тази заявка:
Table 'Orders'. Scan count 101, logical reads 415
Заключение
Този месец разгледах грешки, подводни камъни и най-добри практики, свързани с подзаявки. Покрих грешки при заместване и тризначни логически проблеми. Не забравяйте да използвате последователни имена на колони в таблиците и винаги да квалифицирате колони в подзаявки, дори когато са самостоятелни. Също така не забравяйте да наложите ограничение NOT NULL, когато колоната не трябва да позволява NULL, и винаги да вземете под внимание NULL, когато са възможни във вашите данни. Уверете се, че сте включили NULL в примерните си данни, когато са разрешени, за да можете по-лесно да хванете грешки в кода си, когато го тествате. Внимавайте с предиката NOT IN, когато се комбинира с подзаявки. Ако в резултата на вътрешната заявка са възможни NULL, предикатът NOT EXISTS обикновено е предпочитаната алтернатива.