Въведение
Постигане на минимално регистриране с помощта на INSERT...SELECT впразно целта на клъстерирания индекс не е толкова проста, колкото е описана в Ръководството за зареждане на производителността на данните .
Тази публикация предоставя нови подробности относно изискванията за минимална сеч когато целта за вмъкване е празен традиционен клъстериран индекс. (Думата „традиционен“ там изключва columnstore и оптимизирани за памет („Хекатон“) групирани таблици). За условията, които се прилагат, когато целевата таблица е купчина, вижте предишната статия от тази серия.
Резюме за клъстерирани таблици
Ръководството за ефективност при зареждане на данни съдържа обобщение на високо ниво на условията, необходими за минимално регистриране в клъстерирани таблици:
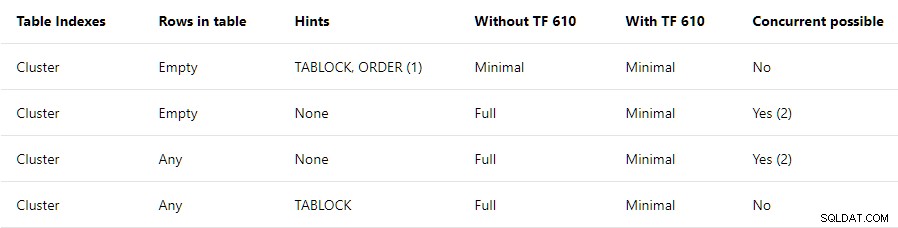
Тази публикация се отнася само до горния ред . Посочва, че TABLOCK и ORDER са необходими съвети, с бележка, която гласи:
Ако използвате BULK INSERT, трябва да се използва подсказката за поръчка.
Празна цел със заключване на таблица
Горният ред на обобщението предполага, че всички вмъкванията към празен клъстериран индекс ще бъдат минимално регистрирани стига TABLOCK и ORDER са посочени съвети. TABLOCK е необходим намек за активиране на RowSetBulk съоръжение, което се използва за насипни товари на маса. ORDER е необходим намек, за да се гарантира, че редовете пристигат в вмъкване на клъстериран индекс план оператор в целевия индекс ключов ред . Без тази гаранция SQL Server може да добави индексни редове, които не са сортирани правилно, което не би било добре.
За разлика от други методи за групово зареждане, това еневъзможно за да посочите необходимия ORDER намек за INSERT...SELECT изявление. Този намекне е същият като използване на ORDER BY клауза на INSERT...SELECT изявление. ORDER BY клауза за INSERT гарантира само начина, по който всяка идентичност се задават стойности, а не ред на вмъкване на ред.
За INSERT...SELECT , SQL Server прави своето собствено определение дали да се гарантира, че редовете се представят в вмъкване на клъстериран индекс оператор в ключов ред или не. Резултатът от тази оценка е видим в плановете за изпълнение чрез DMLRequestSort свойство на Insert оператор. DMLRequestSort имотзат да бъде зададено на true за INSERT...SELECT в индекс, който да бъде минимално регистриран . Когато е зададено на false , минимално регистриране не може да се случи.
Имате DMLRequestSort зададено на true е единствената приемлива гаранция на подреждането на вмъкване на вход за SQL Server. Човек може да провери плана за изпълнение и да предскаже че редовете трябва/ще/трябва да пристигат в клъстериран индексен ред, но без специфичните вътрешни гаранции предоставено от DMLRequestSort , тази оценка не се брои за нищо.
Когато DMLRequestSort е вярно , SQL Server може въведе изрично Сортиране оператор в плана за изпълнение. Ако може вътрешно да гарантира поръчка по други начини, Сортиране може да бъде пропуснат. Ако са налични и двете алтернативи за сортиране и без сортиране, оптимизаторът ще направи базирана на разходите избор. Анализът на разходите не отчита минимално регистриране директно; той се задвижва от очакваните ползи от последователното I/O и избягването на разделяне на страници.
Условия на DMLRequestSort
И двата от следните теста трябва да преминат, за да може SQL Server да избере да зададе DMLRequestSort до вярно при вмъкване в празен клъстериран индекс с посочено заключване на таблица:
- Приблизителна оценка за повече от 250 реда на входната страна на Клъстеризирано вмъкване на индекс оператор; и
- Прогнозно размер на данните от повече от 2 страници . Прогнозният размер на данните не е цяло число, така че резултат от 2001 страници ще отговаря на това условие.
(Това може да ви напомня за условията за минимално регистриране на хийп , но задължителната приблизителна размерът на данните тук е две страници, а не осем.)
Изчисляване на размера на данните
Прогнозният размер на данните изчисляването тук е предмет на същите странности, описани в предишната статия за купища, с изключение на това, че 8-байтовият RID не присъства.
За SQL Server 2012 и по-стари това означава 5 допълнителни байта на ред са включени в изчисляването на размера на данните:един байт за вътрешен бит флаг и четири байта за uniquifier (използва се при изчислението дори за уникални индекси, които не съхраняват uniquifier ).
За SQL Server 2014 и по-нови, унификатор е правилно пропуснат за уникален индекси, но един допълнителен байт за вътрешния бит флагът се запазва.
Демо
Следният скрипт трябва да се изпълни на екземпляр на SQL Server за разработка в нова тестова база данни настроен да използва SIMPLE или BULK_LOGGED модел за възстановяване.
Демонстрацията зарежда 268 реда в чисто нова клъстерирана таблица с помощта на INSERT...SELECT с TABLOCK и отчети за генерираните записи в регистъра на транзакциите.
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (268)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
(Ако стартирате скрипта на SQL Server 2012 или по-стара версия, променете TOP клауза в сценария от 268 до 252 по причини, които ще бъдат обяснени след малко.)
Резултатът показва, че всички вмъкнати редове са напълно регистрирани въпреки чената целева клъстерирана таблица и TABLOCK намек:
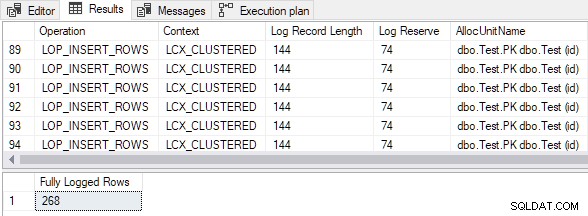
Изчислен размер на данните за вмъкване
Свойствата на плана за изпълнение на Клъстерирана индексна вмъкна оператор показва, че DMLRequestSort е зададен на false . Това е така, защото въпреки че приблизителният брой редове за вмъкване е повече от 250 (отговарящи на първото изискване), изчисленият размерът на даннитене надвишава две страници от 8 КБ.
Подробностите за изчисление (за SQL Server 2014 нататък) са както следва:
- Обща фиксирана дължина размер на колоната =54 байта :
- Въведете идентификатор 104
bit=1 байт (вътрешен). - Въведете идентификатор 56
integer=4 байта (idколона). - Въведете идентификатор 56
integer=4 байта (c1колона). - Въведете идентификатор 175
char(45)=45 байта (paddingколона).
- Въведете идентификатор 104
- Нулева растерна карта =3 байта .
- Заглавка на ред служебни =4 байта .
- Изчислен размер на реда =54 + 3 + 4 =61 байта .
- Изчислен размер на данните =61 байта * 268 реда =16 348 байта .
- Страници с изчислени данни =16 384 / 8192 =1,99560546875 .
Изчисленият размер на ред (61 байта) се различава от истинския размер на паметта на ред (60 байта) с допълнителния един байт вътрешни метаданни, присъстващи във вмъкнатия поток. Изчислението също така не отчита 96-те байта, използвани на всяка страница от заглавката на страницата, или други неща като служебно управление на версиите на редове. Същото изчисление на SQL Server 2012 добавя още 4 байта на ред за uniquifier (което не присъства в уникалните индекси, както беше споменато по-горе). Допълнителните байтове означават, че се очаква по-малко редове да се поберат на всяка страница:
- Изчислен размер на реда =61 + 4 =65 байта .
- Изчислен размер на данните =65 байта * 252 реда =16 380 байта
- Страници с изчислени данни =16 380 / 8192 =1,99951171875 .
Промяна на TOP клауза от 268 реда до 269 (или от 252 до 253 за 2012 г.) прави изчисляването на очаквания размер на данните просто бакшиш над минималния праг от 2 страници:
- SQL Server 2014
- 61 байта * 269 реда =16 409 байта.
- 16 409 / 8192 =2,0030517578125 страници.
- SQL Server 2012
- 65 байта * 253 реда =16 445 байта.
- 16 445 / 8192 =2,0074462890625 страници.
След като второто условие вече също е изпълнено, DMLRequestSort е зададен на true , иминимално регистриране се постига, както е показано в изхода по-долу:
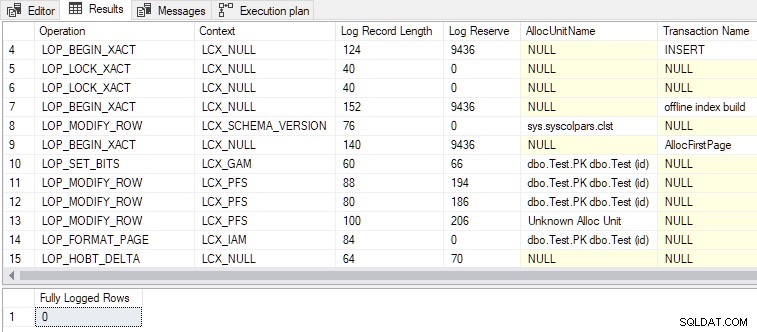
Някои други интересни точки:
- Общо 79 регистрационни записа са генерирани в сравнение с 328 за напълно регистрираната версия. По-малко регистрационни записи са очакваният резултат от минимално регистриране.
LOP_BEGIN_XACTзаписи в минимално регистриран записите запазват сравнително голямо количество дневник (9436 байта всеки).- Едно от имената на транзакциите, изброени в регистрационните записи, е „офлайн изграждане на индекс“ . Въпреки че не поискахме индекс да бъде създаден като такъв, груповото зареждане на редове в празен индекс е по същество същата операция.
- Напълно регистриран insert приема изключително заключване на ниво таблица (
Tab-X), докато минимално регистриран вмъкването изисква промяна на схемата (Sch-M) точно както прави „реалното“ изграждане на офлайн индекс. - Групово зареждане на празна клъстерирана таблица с помощта на
INSERT...SELECTсTABLOCKиDMRequestSortзададено на true използваRowsetBulkмеханизъм, точно както минимално регистриран heap loads направиха в предишната статия.
Оценки за кардиналност
Внимавайте за ниски оценки на кардиналите в Вмъкване на клъстериран индекс оператор. Ако някой от праговете, необходими за задаване на DMLRequestSort до вярно не се достигне поради неточна оценка на кардиналитета, вмъкването ще бъде напълно регистрирано , независимо от действителния брой редове и общия размер на данните, срещани по време на изпълнение.
Например промяна на TOP клауза в демонстрационния скрипт за използване на променлива води до фиксирана мощност предположение от 100 реда, което е под минимума от 251 реда:
-- Insert rows
DECLARE @NumRows bigint = 269;
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (@NumRows)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV; Кеширане на план
DMLRequestSort свойството се запазва като част от кеширания план. Когато кеширан план се използва повторно , стойността на DMLRequestSort ене се преизчисляват по време на изпълнение, освен ако не настъпи прекомпилиране. Имайте предвид, че прекомпилации не се извършват за TRIVIAL планове, базирани на промени в статистическите данни или мощността на таблицата.
Един от начините да избегнете неочаквано поведение поради кеширане е да използвате OPTION (RECOMPILE) намек. Това ще осигури подходящата настройка за DMLRequestSort се преизчислява с цената на компилиране при всяко изпълнение.
Флаг за проследяване
Възможно е да се принуди DMLRequestSort да бъде зададен на true като зададете недокументирано и неподдържано флаг за проследяване 2332, както написах в Оптимизиране на T-SQL заявки, които променят данните. За съжаление, товане засягат минимално регистриране допустимост за празни групирани таблици — вложката все още трябва да бъде оценена на повече от 250 реда и 2 страници. Този флаг за проследяване засяга други минимални записвания сценарии, които са разгледани в последната част на тази поредица.
Резюме
Групово зареждане напразно клъстериран индекс с помощта на INSERT...SELECT използва повторно RowsetBulk механизъм, използван за насипно натоварване на купчини маси. Това изисква заключване на таблицата (обикновено се постига с TABLOCK намек) и ORDER намек. Няма начин да добавите ORDER намек за INSERT...SELECT изявление. В резултат на това се постига минимално сечване в празна клъстерирана таблица изисква DMLRequestSort свойство на Клъстеризирано вмъкване на индекс операторът е настроен на true . Това гарантира към SQL Server, че редовете са представени на Insert операторът ще пристигне в целевия индексен ключов ред. Ефектът е същият като при използване на ORDER подсказка, налична за други методи за групово вмъкване като BULK INSERT и bcp .
За DMLRequestSort да бъде зададен на true , трябва да има:
- Повече от 250 реда приблизително да се вмъкне; и
- Прогнозно вмъкнете данни с размер над две страници .
Прогнозното вмъкване на изчисляване на размера на данни не съвпада с резултата от умножаването на плана за изпълнение прогнозен брой редове и приблизителен размер на ред свойства на входа на Вмъкване оператор. Вътрешното изчисление (неправилно) включва една или повече вътрешни колони в потока за вмъкване, които не се запазват в крайния индекс. Вътрешното изчисление също не отчита заглавките на страниците или други допълнителни разходи, като версия на редове.
При тестване или отстраняване на грешки минимално регистриране проблеми, пазете се от оценките с ниска кардиналност и не забравяйте, че настройката на DMLRequestSort се кешира като част от плана за изпълнение.
Последната част от тази поредица подробно описва условията, необходими за постигане на минимална сеч без да използвате RowsetBulk механизъм. Те съответстват директно на новите съоръжения, добавени под флаг за проследяване 610 към SQL Server 2008, след което са променени да бъдат включени по подразбиране от SQL Server 2016 нататък.