Машината за изпълнение на заявки на SQL Server има два начина за реализиране на логическа операция „обединяване на всички“, като се използват физическите оператори Concatenation и Merge Join Concatenation. Въпреки че логическата операция е една и съща, има важни разлики между двата физически оператора, които могат да направят огромна разлика в ефективността на вашите планове за изпълнение.
Оптимизаторът на заявки върши разумна работа при избора между двете опции в много случаи, но е далеч от перфектния в тази област. Тази статия описва възможностите за настройка на заявката, предоставени от обединяването на обединяване на присъединяване, и подробно описва вътрешното поведение и съображения, с които трябва да сте наясно, за да се възползвате максимално от това.
Конкатенация

Операторът за конкатенация е сравнително прост:неговият изход е резултат от пълно четене от всеки негов вход в последователност. Операторът за конкатенация е n-ариен физически оператор, което означава, че може да има '2...n' входа. За да илюстрираме, нека да разгледаме отново базирания на AdventureWorks пример от предишната ми статия „Пренаписване на заявки за подобряване на производителността“:
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
Следната заявка изброява идентификатори на продукти и транзакции за шест конкретни продукта:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711;
Той произвежда план за изпълнение, включващ оператор за конкатенация с шест входа, както се вижда в SQL Sentry Plan Explorer:
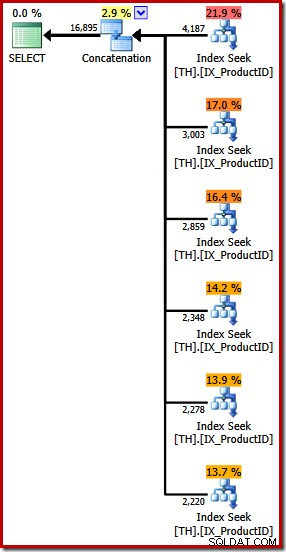
Планът по-горе включва отделно търсене на индекс за всеки изброен идентификатор на продукт в същия ред, както е посочено в заявката (четене отгоре надолу). Най-горното търсене в индекс е за продукт 870, следващото надолу е за продукт 873, след това 921 и така нататък. Нищо от това не е гарантирано поведение, разбира се, просто е нещо интересно за наблюдение.
По-рано споменах, че операторът за конкатенация формира своя изход, като чете последователно от неговите входове. Когато този план се изпълни, има голям шанс резултатният набор да покаже първо редове за продукт 870, след това 873, 921, 712, 707 и накрая продукт 711. Отново, това не е гарантирано, защото не сме посочили ПОРЪЧКА BY клауза, но показва как конкатенацията работи вътрешно.
План за изпълнение на SSIS
По причини, които ще имат смисъл след малко, помислете как можем да проектираме пакет SSIS за изпълнение на същата задача. Със сигурност бихме могли също да напишем цялото нещо като един T-SQL израз в SSIS, но по-интересната опция е да създадем отделен източник на данни за всеки продукт и да използваме компонент SSIS „Union All“ вместо SQL Server Concatenation оператор:
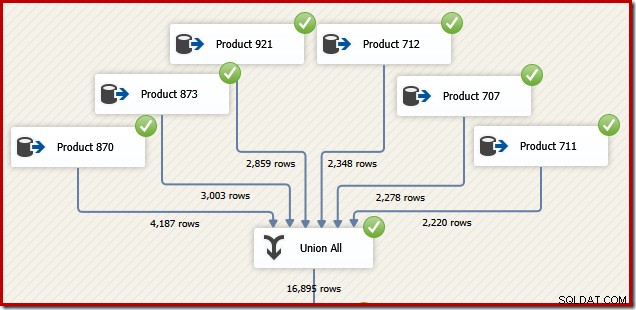
Сега си представете, че имаме нужда от крайния изход от този поток от данни в реда на идентификатор на транзакция. Една от опциите би била да добавите изричен компонент за сортиране след Union All:
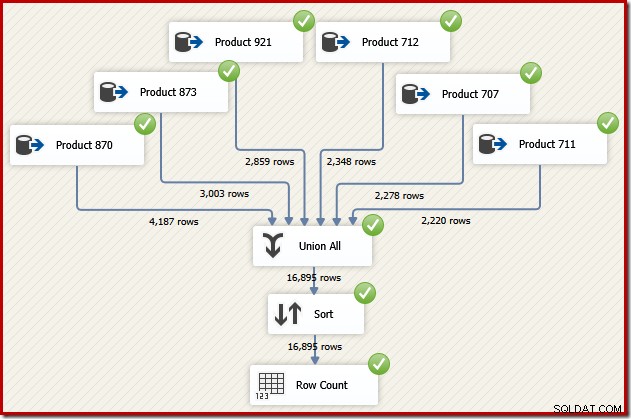
Това със сигурност ще свърши работа, но квалифициран и опитен дизайнер на SSIS ще разбере, че има по-добър вариант:прочетете изходните данни за всеки продукт в поръчката за ID на транзакция (използвайки индекса), след това използвайте операция за запазване на реда, за да комбинирате наборите .
В SSIS компонентът, който комбинира редове от два сортирани потока данни в един поток от сортирани данни, се нарича „Сливане“. Следва преработен поток от SSIS данни, който използва сливане за връщане на желаните редове в реда на идентификатор на транзакция:
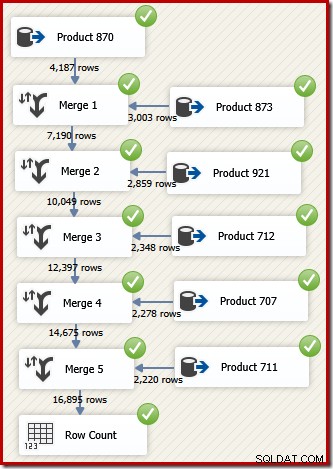
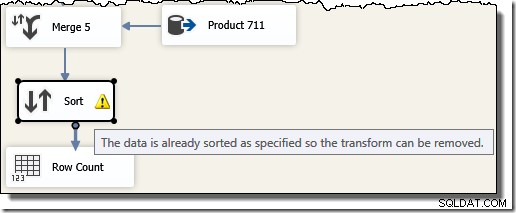
Обърнете внимание, че имаме нужда от пет отделни компонента за сливане, тъй като сливането е двоичен компонент, за разлика от компонента SSIS „Union All“, който беше n-ариен . Новият поток на сливане дава резултати в поръчка на идентификатор на транзакция, без да изисква скъп (и блокиращ) компонент за сортиране. Всъщност, ако се опитаме да добавим идентификатор за сортиране на транзакция след окончателното сливане, SSIS показва предупреждение, за да ни уведоми, че потокът вече е сортиран по желания начин:
Смисълът на примера за SSIS вече може да бъде разкрит. Вижте плана за изпълнение, избран от оптимизатора на заявки на SQL Server, когато го помолим да върне оригиналните резултати от T-SQL заявка в поръчка на ID на транзакция (чрез добавяне на клауза ORDER BY):
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
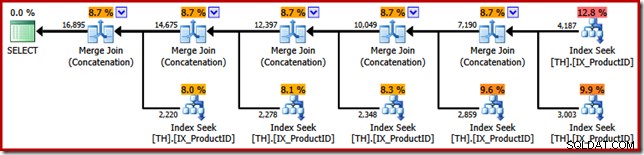
Приликите с пакета SSIS Merge са поразителни; дори до необходимостта от пет двоични оператора "Сливане". Единствената важна разлика е, че SSIS има отделни компоненти за „Обединяване при сливане“ и „Обединяване“, докато SQL Server използва един и същ основен оператор и за двете.
За да бъде ясно, операторите за свързване на сливане (Concatenation) в плана за изпълнение на SQL Server са не извършване на присъединяване; двигателят просто използва повторно един и същ физически оператор за реализиране на съюз за запазване на реда all.
Писане на планове за изпълнение в SQL Server
SSIS няма език за спецификация на потока от данни, нито оптимизатор, който да превърне такава спецификация в изпълнима задача за поток от данни. От дизайнера на пакети SSIS зависи да осъзнае, че е възможно обединяване, запазващо реда, да настрои свойствата на компонента (като ключове за сортиране) по подходящ начин, след което да сравни производителността. Това изисква повече усилия (и умения) от страна на дизайнера, но осигурява много фина степен на контрол.
Ситуацията в SQL Server е обратната:ние пишем спецификация на заявка използвайки езика T-SQL, след това зависи от оптимизатора на заявки, за да проучите опциите за внедряване и да изберете ефективна. Нямаме възможност да изградим директно план за изпълнение. През повечето време това е силно желателно:SQL Server без съмнение би бил доста по-малко популярен, ако всяка заявка изискваше да напишем пакет в стил SSIS.
Независимо от това (както беше обяснено в предишната ми публикация), избраният от оптимизатора план може да бъде чувствителен към T-SQL, използван за описване на желаните резултати. Повтаряйки примера от тази статия, бихме могли да напишем оригиналната T-SQL заявка, използвайки алтернативен синтаксис:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Тази заявка посочва точно същия набор от резултати, както преди, но оптимизаторът не взема предвид план за запазване на реда (сливане на конкатенация), като вместо това избира да сканира клъстерирания индекс (много по-малко ефективна опция):
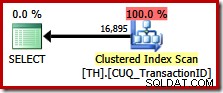
Използване на запазване на поръчките в SQL Server
Избягването на ненужно сортиране може да доведе до значително повишаване на ефективността, независимо дали говорим за SSIS или SQL Server. Постигането на тази цел може да бъде по-сложно и трудно в SQL Server, тъй като ние нямаме толкова фин контрол върху плана за изпълнение, но все още има неща, които можем да направим.
По-конкретно, разбирането как операторът за конкатенация на SQL Server Merge Join работи вътрешно може да ни помогне да продължим да пишем ясен, релационен T-SQL, като същевременно насърчи оптимизатора на заявки да обмисли опциите за обработка за запазване на реда (сливане), където е уместно.
Как работи конкатенацията на присъединяване при сливане

Редовното обединяване на сливане изисква и двата входа да бъдат сортирани на клавишите за свързване. От друга страна, конкатенацията на сливане на присъединяване просто обединява два вече подредени потока в един подреден поток – като такова няма присъединяване.
Това повдига въпроса:каква точно е запазената 'порядка'?
В SSIS трябва да зададем свойства на ключа за сортиране на входовете за сливане, за да дефинираме подреждането. SQL Server няма еквивалент на това. Отговорът на въпроса по-горе е малко сложен, така че ще го вземем стъпка по стъпка.
Помислете за следния пример, който изисква конкатенация при сливане на две неиндексирани хеп таблици (най-простият случай):
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (MERGE UNION);
Тези две таблици нямат индекси и няма клауза ORDER BY. Какъв ред ще „запази“ конкатенацията на обединяването на сливането? За да ви дадем момент да помислите върху това, нека първо да разгледаме плана за изпълнение, създаден за заявката по-горе във версии на SQL Server преди 2012:
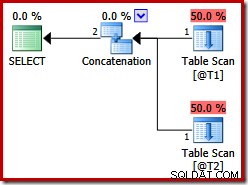
Няма конкатенация на присъединяване при сливане, въпреки подсказката за заявката:преди SQL Server 2012 този намек работи само с UNION, а не с UNION ALL. За да получим план с желания оператор за сливане, трябва да деактивираме изпълнението на логически UNION ALL (UNIA), използвайки физическия оператор Concatenation (CON). Моля, имайте предвид, че следното е недокументирано и не се поддържа за производствена употреба:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (QUERYRULEOFF UNIAtoCON);
Тази заявка произвежда същия план като SQL Server 2012 и 2014 само с намек за заявка MERGE UNION:
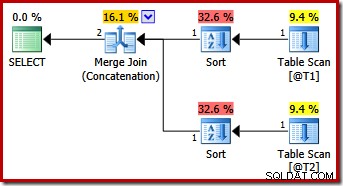
Може би неочаквано, планът за изпълнение включва изрично сортиране и на двата входа за сливането. Свойствата за сортиране са:
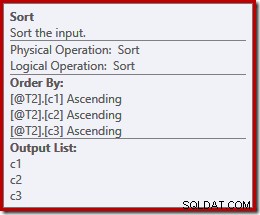
Има смисъл, че сливането, запазващо реда, изисква последователно подреждане на входа, но защо избра (c1, c2, c3) вместо, да речем, (c3, c1, c2) или (c2, c3, c1)? Като отправна точка входните данни за конкатенация за сливане се сортират в списъка с изходни проекции. Звездата за избор в заявката се разширява до (c1, c2, c3), така че това е избраният ред.
Сортиране по списък с проекции за обединяване на изход
За да илюстрираме допълнително въпроса, можем сами да разширим избраната звезда (както трябва!), като изберем различен ред (c3, c2, c1), докато сме на това:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Сортовете сега се променят, за да съвпаднат (c3, c2, c1):
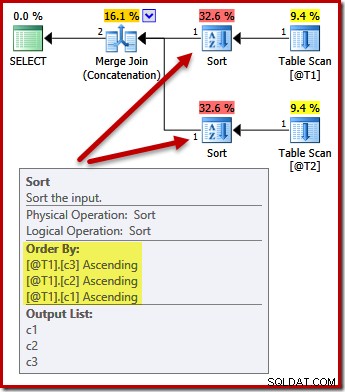
Отново заявката изход поръчката (ако приемем, че трябва да добавим някои данни към таблиците) не е гарантирана, че ще бъде сортирана, както е показано, тъй като нямаме клауза ORDER BY. Тези примери са предназначени просто да покажат как оптимизаторът избира първоначален входен ред за сортиране, при липса на друга причина за сортиране.
Противоречиви поръчки за сортиране
Сега помислете какво се случва, ако оставим списъка с проекции като (c3, c2, c1) и добавим изискване за подреждане на резултатите от заявката по (c1, c2, c3). Ще продължат ли входните данни за сливането да се сортират по (c3, c2, c1) със сортиране след сливане на (c1, c2, c3), за да удовлетворят ORDER BY?
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 ORDER BY c1, c2, c3 OPTION (MERGE UNION);
Не. Оптимизаторът е достатъчно умен, за да избегне сортирането два пъти:
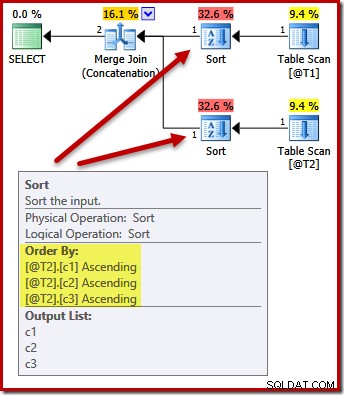
Сортирането на двата входа на (c1, c2, c3) е напълно приемливо за конкатенацията при сливане, така че не се изисква двойно сортиране.
Имайте предвид, че този план прави гарантира, че редът на резултатите ще бъде (c1, c2, c3). Планът изглежда по същия начин като предишните планове без ORDER BY, но не всички вътрешни подробности са представени във видими от потребителя планове за изпълнение.
Ефектът на уникалността
Когато избирате реда на сортиране за входните данни за сливане, оптимизаторът също се влияе от всички съществуващи гаранции за уникалност. Помислете за следния пример с пет колони, но обърнете внимание на различните редове на колони в операцията UNION ALL:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Планът за изпълнение включва сортиране на (c5, c1, c2, c4, c3) за таблица @T1 и (c5, c4, c3, c2, c1) за таблица @T2:
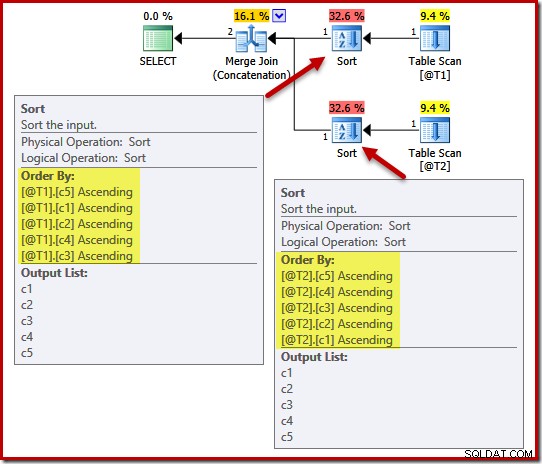
За да демонстрираме ефекта на уникалността върху тези сортове, ще добавим ограничение UNIQUE към колона c1 в таблица T1 и колона c4 в таблица T2:
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Въпросът за уникалността е, че оптимизаторът знае, че може да спре сортирането веднага щом срещне колона, която е гарантирано уникална. Сортирането по допълнителни колони, след като се срещне уникален ключ, няма да повлияе на крайния ред на сортиране по дефиниция.
С ограниченията UNIQUE на място, оптимизаторът може да опрости списъка за сортиране (c5, c1, c2, c4, c3) за T1 до (c5, c1), тъй като c1 е уникален. По подобен начин списъкът за сортиране (c5, c4, c3, c2, c1) за T2 е опростен до (c5, c4), тъй като c4 е ключ:
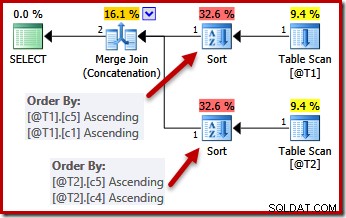
Паралелизъм
Опростяването поради уникален ключ не е перфектно реализирано. В паралелен план потоците се разделят така, че всички редове за един и същи екземпляр на обединяването да се окажат в една и съща нишка. Това разделяне на набор от данни се основава на колоните за сливане и не е опростено от наличието на ключ.
Следният скрипт използва неподдържан флаг за проследяване 8649 за генериране на паралелен план за предишната заявка (която в противен случай е непроменена):
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION, QUERYTRACEON 8649);
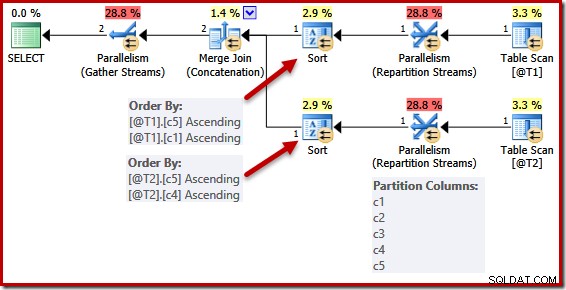
Списъците за сортиране са опростени както преди, но операторите на потоците за преразпределение все още разделят всички колони. Ако това опростяване се прилагаше последователно, операторите за преразпределение също биха работили само върху (c5, c1) и (c5, c4).
Проблеми с неуникални индекси
Начинът, по който оптимизаторът разсъждава относно изискванията за сортиране за конкатенация при сливане, може да доведе до ненужни проблеми при сортиране, както показва следващият пример:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Разглеждайки заявката и наличните индекси, бихме очаквали план за изпълнение, който извършва подредено сканиране на клъстерираните индекси, използвайки конкатенация на обединяване при сливане, за да се избегне необходимостта от каквото и да е сортиране. Това очакване е напълно оправдано, тъй като клъстерираните индекси осигуряват реда, посочен в клаузата ORDER BY. За съжаление, планът, който всъщност получаваме, включва два вида:
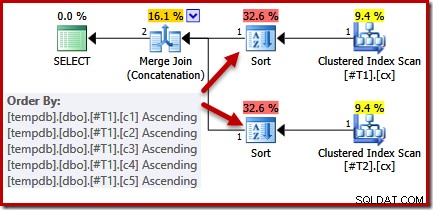
Няма основателна причина за тези сортове, те се появяват само защото логиката на оптимизатора на заявки е несъвършена. Списъкът с изходни колони за сливане (c1, c2, c3, c4, c5) е надмножество на ORDER BY, но няма уникални ключ за опростяване на този списък. В резултат на тази празнина в разсъжденията на оптимизатора той стига до заключението, че сливането изисква входните данни да бъдат сортирани по (c1, c2, c3, c4, c5).
Можем да проверим този анализ, като модифицираме скрипта, за да направим един от клъстерираните индекси уникален:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Планът за изпълнение вече има само сортиране над таблицата с неуникален индекс:
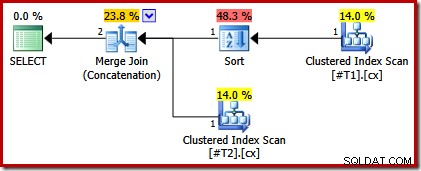
Ако сега направим и двете клъстерирани индекси са уникални, не се появяват сортове:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE UNIQUE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1; DROP TABLE #T1, #T2;
С уникални и двата индекса, първоначалните списъци за сортиране при сливане могат да бъдат опростени само до колона c1. След това опростеният списък съвпада точно с клаузата ORDER BY, така че не са необходими сортировки в крайния план:
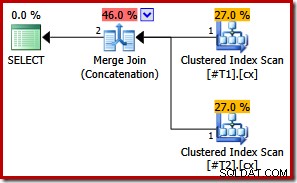
Забележете, че дори не се нуждаем от намек за заявка в този последен пример, за да получим оптималния план за изпълнение.
Последни мисли
Елиминирането на сортове в план за изпълнение може да бъде трудно. В някои случаи може да бъде толкова просто, колкото промяна на съществуващ индекс (или предоставяне на нов), за да се доставят редове в необходимия ред. Оптимизаторът на заявки върши разумна работа като цяло, когато са налични подходящи индекси.
В (много) други случаи обаче избягването на сортиране може да изисква много по-задълбочено разбиране на машината за изпълнение, оптимизатора на заявки и самите оператори на план. Избягването на сортиране несъмнено е усъвършенствана тема за настройка на заявките, но и невероятно възнаграждаваща, когато всичко е наред.