Публикация от Дан Холмс, който пише в sql.dnhlms.com.
SQL Server Books Online (BOL), белите книги и много други източници ще ви покажат как и защо може да искате да актуализирате статистически данни за таблица или индекс. Въпреки това, вие получавате само един начин да оформите тези ценности. Ще ви покажа как можете да създадете статистическите данни точно както искате в рамките на 200-те налични стъпки.
Отказ от отговорност :Това работи за мен, защото познавам моето приложение, моята база данни и обичайните модели на работа и използване на приложенията на моя потребител. Въпреки това, той използва недокументирани команди и, ако се използва неправилно, може да направи приложението ви значително по-лошо.В нашето приложение потребителят на Scheduling редовно чете и записва данни, които представляват събития за утре и следващите няколко дни. Данните за днес и по-рано не се използват от Планировчика. Първото нещо сутринта, наборът от данни за утре започва от няколкостотин реда и до обяд може да бъде 1400 и повече. Следващата диаграма ще илюстрира броя на редовете. Тези данни са събрани сутринта в сряда, 18 ноември 2015 г. В исторически план можете да видите, че редовният брой редове е приблизително 1400, с изключение на дните през уикенда и следващия ден.
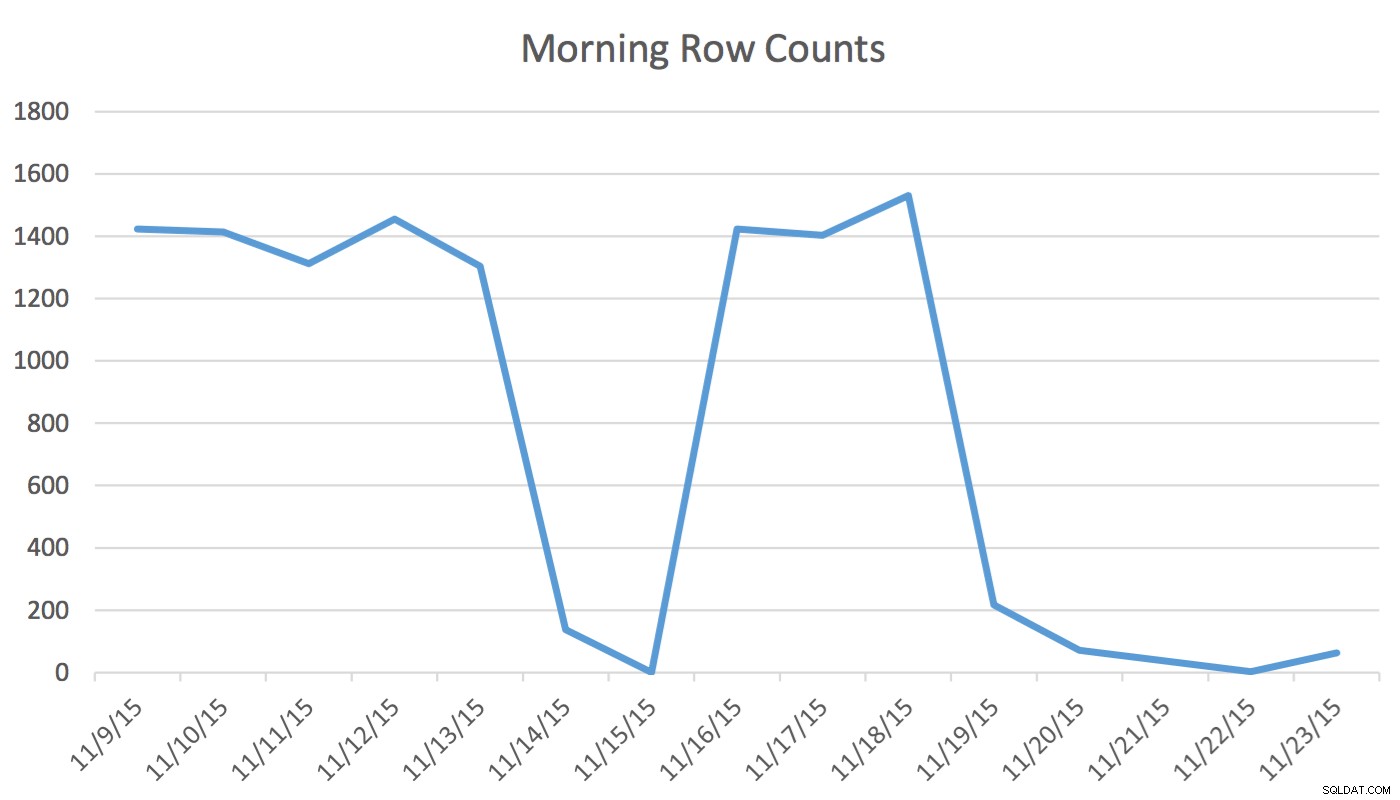
За Scheduler единствените уместни данни са следващите няколко дни. Това, което се случва днес и се случи вчера, не е от значение за неговата дейност. И така, как това причинява проблем? Тази таблица има 2 259 205 реда, което означава, че промяната в броя на редовете от сутрин до обяд няма да е достатъчна, за да задейства инициирана от SQL Server актуализация на статистиката. Освен това, ръчно планирано задание, което изгражда статистически данни с помощта на UPDATE STATISTICS попълва хистограмата с извадка от всички данни в таблицата, но може да не включва съответната информация. Тази делта на броя на редовете е достатъчна, за да промените плана. Въпреки това, без актуализация на статистиката и точна хистограма, планът няма да се промени към по-добро, тъй като данните се променят.
Съответна селекция на хистограмата за тази таблица от резервно копие от 4.11.2015 г. може да изглежда така:
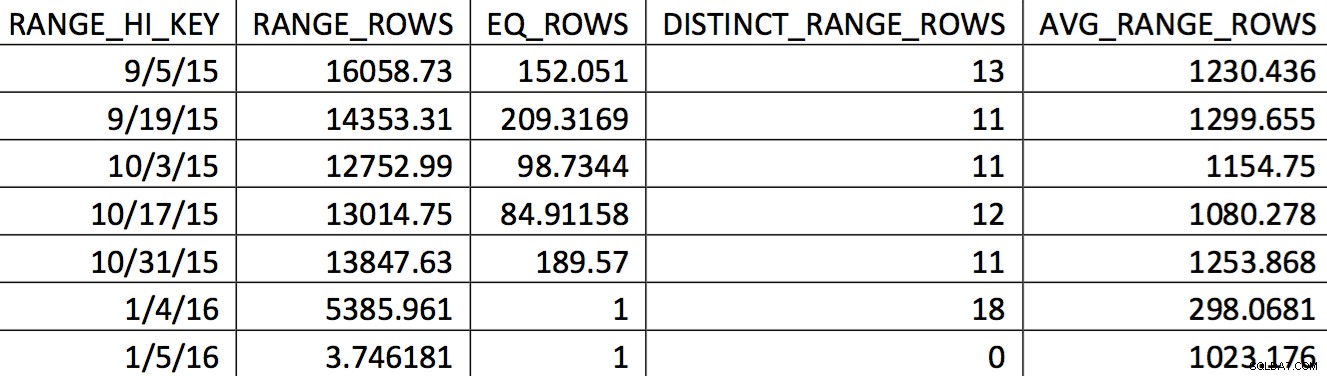
Стойностите, които представляват интерес, не са отразени точно в хистограмата. Това, което ще се използва за датата 5.11.2015 г., ще бъде високата стойност 04.01.2016 г. Въз основа на графиката, тази хистограма очевидно не е добър източник на информация за оптимизатора за датата, която ви интересува. Принудителното въвеждане на стойностите на употреба в хистограмата не е надеждно, така че как можете да направите това? Първият ми опит беше многократно да използвам WITH SAMPLE опция за UPDATE STATISTICS и потърсете хистограмата, докато стойностите, от които се нуждаех, не бъдат в хистограмата (усилие, описано подробно тук). В крайна сметка този подход се оказа ненадежден.
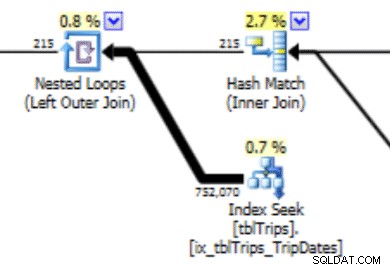
Тази хистограма може да доведе до план с този тип поведение. Подценяването на редовете води до присъединяване на вложен цикъл и търсене на индекс. Впоследствие показанията са по-високи, отколкото трябва да бъдат поради този избор на план. Това също ще има ефект върху продължителността на изявлението.
Това, което би работило много по-добре, е да създадете данните точно както искате и ето как да направите това.
Има неподдържана опция за UPDATE STATISTICS :STATS_STREAM . Това се използва от поддръжката на клиенти на Microsoft за експортиране и импортиране на статистически данни, за да могат да получат пресъздаден оптимизатор, без да имат всички данни в таблицата. Можем да използваме тази функция. Идеята е да създадем таблица, която имитира DDL на статистиката, която искаме да персонализираме. Съответните данни се добавят към таблицата. Статистическите данни се експортират и импортират в оригиналната таблица.
В този случай това е таблица с 200 реда дати, които не са NULL, и 1 ред, който включва стойностите NULL. Освен това в тази таблица има индекс, който съответства на индекса, който има лоши стойности на хистограмата.
Името на таблицата е tblTripsScheduled . Той има неклъстериран индекс на (id, TheTripDate) и клъстериран индекс на TheTripDate . Има няколко други колони, но само тези, които участват в индекса, са важни.
Създайте таблица (временна таблица, ако желаете), която имитира таблицата и индекса. Таблицата и индексът изглеждат така:
CREATE TABLE #tbltripsscheduled_cix_tripsscheduled(
id INT NOT NULL
, tripdate DATETIME NOT NULL
, PRIMARY KEY NONCLUSTERED(id, tripdate)
);
CREATE CLUSTERED INDEX thetripdate ON #tbltripsscheduled_cix_tripsscheduled(tripdate);
След това таблицата трябва да бъде попълнена с 200 реда данни, на които трябва да се базира статистиката. За моята ситуация това е от ден до следващите шестдесет дни. Миналите и след 60 дни се попълват с "произволен" избор на всеки 10 дни. (cnt стойността в CTE е стойност за отстраняване на грешки. Не играе роля в крайните резултати.) Низходящ ред за rn колоната гарантира, че са включени 60-те дни и след това възможно най-много от миналото.
DECLARE @date DATETIME = '20151104';
WITH tripdates
AS
(
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE NOT thetripdate BETWEEN @date AND @date
AND thetripdate < DATEADD(DAY, 60, @date) --only look 60 days out GROUP BY thetripdate
HAVING DATEDIFF(DAY, 0, thetripdate) % 10 = 0
UNION ALL
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE thetripdate BETWEEN @date AND DATEADD(DAY, 60, @date)
GROUP BY thetripdate
),
tripdate_top_200
AS
(
SELECT *
FROM
(
SELECT *, ROW_NUMBER() OVER(ORDER BY thetripdate DESC) rn
FROM tripdates
) td
WHERE rn <= 200
)
INSERT #tbltripsscheduled_cix_tripsscheduled (id, tripdate)
SELECT t.tripid, t.thetripdate
FROM tripdate_top_200 tp
INNER JOIN dbo.tbltripsscheduled t ON t.thetripdate = tp.thetripdate;
Нашата таблица вече е попълнена с всеки ред, който е ценен за потребителя днес, и селекция от исторически редове. Ако колоната TheTripdate беше нула, вмъкването би включвало и следното:
UNION ALL SELECT id, thetripdate FROM dbo.tbltripsscheduled WHERE thetripdate IS NULL;
След това актуализираме статистическите данни за индекса на нашата временна таблица.
UPDATE STATISTICS #tbltrips_IX_tbltrips_tripdates (tripdates) WITH FULLSCAN;
Сега експортирайте тези статистически данни във временна таблица. Таблицата изглежда така. Той съответства на изхода на DBCC SHOW_STATISTICS WITH HISTOGRAM .
CREATE TABLE #stats_with_stream
(
stream VARBINARY(MAX) NOT NULL
, rows INT NOT NULL
, pages INT NOT NULL
);
DBCC SHOW_STATISTICS има опция за експортиране на статистическите данни като поток. Това е потокът, който искаме. Този поток също е същият като UPDATE STATISTICS опция за поток използва. За да направите това:
INSERT INTO #stats_with_stream --SELECT * FROM #stats_with_stream
EXEC ('DBCC SHOW_STATISTICS (N''tempdb..#tbltripsscheduled_cix_tripsscheduled'', thetripdate)
WITH STATS_STREAM,NO_INFOMSGS'); Последната стъпка е да създадем SQL, който актуализира статистическите данни на нашата целева таблица, и след това да го изпълним.
DECLARE @sql NVARCHAR(MAX);
SET @sql = (SELECT 'UPDATE STATISTICS tbltripsscheduled(cix_tbltripsscheduled) WITH
STATS_STREAM = 0x' + CAST('' AS XML).value('xs:hexBinary(sql:column("stream"))',
'NVARCHAR(MAX)') FROM #stats_with_stream );
EXEC (@sql); В този момент сме заменили хистограмата с нашата специално изградена. Можете да проверите, като проверите хистограмата:
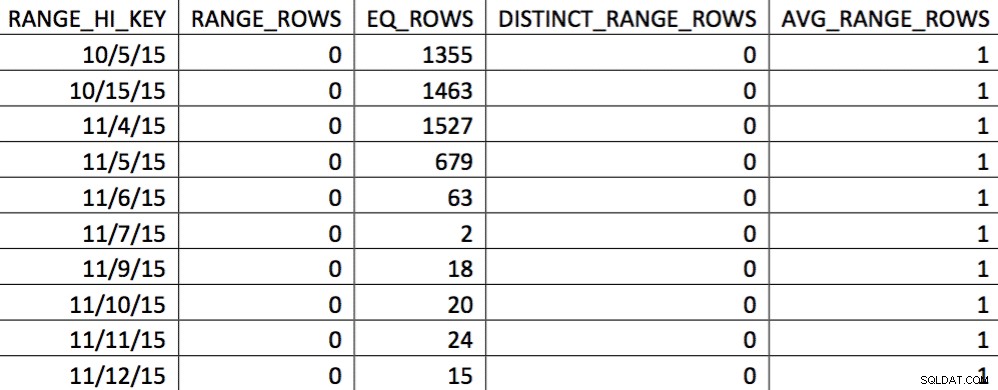
В тази селекция на данните за 11/4 са представени всички дни от 11/4 нататък, а историческите данни са представени и точни. Преразглеждайки частта от плана на заявката, показана по-рано, можете да видите, че оптимизаторът е направил по-добър избор въз основа на коригираните статистически данни:
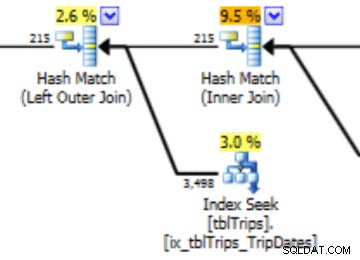
Има предимство за производителността на импортираните статистики. Разходите за изчисляване на статистиката са в "офлайн" таблица. Единственото време на престой за производствената таблица е продължителността на импортирането на поток.
Този процес използва недокументирани функции и изглежда, че може да бъде опасен, но не забравяйте, че има лесна отмяна:изявлението за статистика за актуализиране. Ако нещо се обърка, статистическите данни винаги могат да бъдат актуализирани с помощта на стандартен T-SQL.
Планирането на този код да се изпълнява редовно може значително да помогне на оптимизатора да изготви по-добри планове, като се има предвид набор от данни, който се променя в крайната точка, но не е достатъчно, за да задейства актуализация на статистиката.
Когато завърших първата чернова на тази статия, броят на редовете в таблицата в първата диаграма се промени от 217 на 717. Това е 300% промяна. Това е достатъчно, за да промени поведението на оптимизатора, но не е достатъчно, за да задейства актуализация на статистиката. Тази промяна на данните би оставила лош план. Този проблем е решен с описания тук процес.
Препратки:
- АКТУАЛИЗИРАНЕ НА СТАТИСТИКАТА (Книги онлайн)
- Бяла книга за статистиката за SQL 2008
- Търсене на повратна точка