Въведение
Има две школи на мислене относно извършването на изчисления във вашата база данни:хора, които смятат, че това е страхотно, и хора, които грешат. Това не означава, че светът на функциите, съхранените процедури, генерирани или изчислени колони и тригери е всичко на слънце и рози! Тези инструменти далеч не са надеждни и необмислените имплементации могат да се представят лошо, да травмират своите поддържащи и много други, което до известна степен обяснява съществуването на противоречия.
Но базите данни по дефиниция са много добри в обработката и манипулирането на информация и повечето от тях предоставят същия контрол и мощност на своите потребители (SQLite и MS Access в по-малка степен). Външните програми за обработка на данни започват на заден крак, които трябва да изтеглят информация от базата данни, често в мрежа, преди да могат да направят нещо. И където програмите за бази данни могат да се възползват пълноценно от операциите на собствения набор, индексирането, временните таблици и други плодове от половин век еволюция на базата данни, външните програми с всякаква сложност са склонни да включват известно ниво на преоткриване на колелото. Така че защо да не поставите базата данни да работи?
Ето защо може да не искате да програмирате вашата база данни!
- Функционалността на базата данни има тенденция да става невидима – особено задейства. Тази слабост се мащабира приблизително с размера на екипите и/или приложенията, взаимодействащи с базата данни, тъй като по-малко хора помнят или са наясно с програмирането в базата данни. Документацията помага, но само толкова.
- SQL е език, специално създаден за манипулиране на набори от данни. Не е особено добър в неща, които не манипулират набори от данни, и е по-малко добър, колкото по-сложни стават тези други неща.
- Възможностите на RDBMS и SQL диалектите се различават. Обикновено генерираните колони се поддържат широко, но пренасянето на по-сложна логика на базата данни към други магазини отнема най-малко време и усилия.
- Надстройките на схемата на базата данни обикновено са по-натоварени от надстройките на приложенията. Бързо променящата се логика е най-добре да се поддържа другаде, въпреки че може да си струва да погледнете отново, след като нещата се стабилизират.
- Управлението на програми за бази данни не е толкова просто, колкото може да се надява. Много инструменти за миграция на схеми правят малко или нищо за организацията, което води до обширни различия и обременителни прегледи на кода (графиките на зависимостта на sqitch и преработката на отделни обекти го правят забележително изключение, а migra се стреми да заобиколи проблема изцяло). При тестването рамки като pgTAP и utPLSQL подобряват тестовете за интеграция на черна кутия, но също така представляват допълнителен ангажимент за поддръжка и поддръжка.
- С установена външна кодова база всяка структурна промяна обикновено е трудоемка и рискована.
От друга страна, за тези задачи, за които е подходящ, SQL предлага бързина, сбитост, издръжливост и възможност за „канонизиране“ на автоматизирани работни процеси. Моделирането на данни е нещо повече от закрепване на обекти като насекоми към картон и разликата между данни в движение и данни в покой е трудна. Почивката е наистина по-бавно движение в по-фин клас; информацията винаги тече от тук натам, а програмируемостта на базата данни е мощен инструмент за управление и насочване на тези потоци.
Някои машини за бази данни разделят разликата между SQL и други езици за програмиране, като приемат и тези други езици за програмиране. SQL Server поддържа функции, написани на всеки език на .NET Framework; Oracle има Java съхранени процедури; PostgreSQL позволява разширения с C и е програмируем от потребителя в Python, Perl и Tcl, с плъгини, добавящи шел скриптове, R, JavaScript и др. Завършвайки обичайните заподозрени, това е SQL или нищо за MySQL и MariaDB, MS Access е само програмируем във VBA, а SQLite изобщо не може да се програмира от потребителя.
Използването на не-SQL езици е опция, ако SQL не е подходящ за някаква задача или ако искате да използвате повторно друг код, но няма да ви заобиколи другите проблеми, които правят програмирането на база данни меч с много остриета. Ако не друго, прибягването до тях допълнително усложнява внедряването и оперативната съвместимост. Предупреждение:нека писателят се пази.
Функции срещу процедури
Както при други аспекти на внедряването на стандарта SQL, точните подробности варират малко от RDBMS до RDBMS. Като цяло:
- Функциите не могат да контролират транзакциите.
- Функциите връщат стойности; процедурите могат да променят параметри, обозначени
OUTилиINOUTкойто след това може да бъде прочетен в контекста на извикване, но никога не връща резултат (с изключение на SQL Server). - Функциите се извикват от SQL изрази, за да извършат някаква работа върху записите, които се извличат или съхраняват, докато процедурите са самостоятелни.
По-конкретно, MySQL също така забранява рекурсията и някои допълнителни SQL изрази във функциите. SQL Server забранява на функциите да променят данни, да изпълняват динамичен SQL и да обработват грешки. PostgreSQL изобщо не отделя съхранените процедури от функциите до 2017 г. с версия 11, така че функциите на Postgres могат да правят почти всичко, което процедурите могат, с изключение на контрола върху транзакциите.
И така, кое да използваме кога? Функциите са най-подходящи за логика, която прилага запис по запис, когато данните се съхраняват и извличат. По-сложните работни потоци, които се извикват сами и преместват данни вътрешно, са по-добри като процедури.
По подразбиране и генериране
Дори простите изчисления могат да създадат проблеми, ако се извършват достатъчно често или ако съществуват множество конкуриращи се реализации. Операциите върху стойности в един ред - мислете за преобразуване между метрични и имперски единици, умножаване на ставка по отработени часове за междинни суми на фактурата, изчисляване на площта на географски многоъгълник - могат да бъдат декларирани в дефиниция на таблица за справяне с един или друг проблем :
CREATE TABLE pythag ( a INT NOT NULL, b INT NOT NULL, c DOUBLE PRECISION NOT NULL GENERATED ALWAYS AS (sqrt(pow(a, 2) + pow(b, 2))) STORED);
Повечето RDBMS предлагат избор между "съхранени" и "виртуални" генерирани колони. В първия случай стойността се изчислява и съхранява, когато редът се вмъкне или актуализира. Това е единствената опция с PostgreSQL от версия 12 и MS Access. Виртуалните генерирани колони се изчисляват при запитване като в изгледи, така че те не заемат място, но ще се преизчисляват по-често. И двата вида са строго ограничени:стойностите не могат да зависят от информация извън реда, към който принадлежат, не могат да се актуализират и отделните RDBMS могат да имат още по-специфични ограничения. PostgreSQL, например, забранява разделянето на таблица в генерирана колона.
Генерираните колони са специализиран инструмент. По-често всичко, което е необходимо, е по подразбиране, в случай че стойността не е предоставена при вмъкване. Функции като now() се показват често като колони по подразбиране, но повечето бази данни позволяват персонализирани, както и вградени функции (с изключение на MySQL, където само current_timestamp може да е стойност по подразбиране).
Нека вземем доста сухия, но прост пример за номер на партида във формат YYYYXXX, където първите четири цифри представляват текущата година, а последните три - нарастващ брояч:първата партида, произведена тази година, е 2020001, втората 2020002 и т.н. . Няма тип по подразбиране или вградена функция, която да генерира стойност като тази, но дефинирана от потребителя функция може да номерира всяка партида
CREATE SEQUENCE lot_counter;CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN date_part('year', now())::TEXT || lpad(nextval('lot_counter'::REGCLASS)::TEXT, 2, '0');END;$$LANGUAGE plpgsql;CREATE TABLE lots ( lot_number TEXT NOT NULL DEFAULT next_lot_number () PRIMARY KEY, current_quantity INT NOT NULL DEFAULT 0, target_quantity INT NOT NULL, created_at TIMESTAMPTZ NOT NULL DEFAULT now(), completed_at TIMESTAMPTZ, CHECK (target_quantity > 0));
Референтни данни във функции
Подходът на последователността по-горе има една важна слабост (и lot_counter ще продължи да има същата стойност като на 31 декември. Има повече от един начин да проследите колко партиди са били създадени за една година, и чрез заявка за lots самият next_lot_number функцията може да гарантира правилна стойност след изтичане на годината.
CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN ( SELECT date_part('year', now())::TEXT || lpad((count(*) + 1)::TEXT, 2, '0') FROM lots WHERE date_part('year', created_at) = date_part('year', now()) );END;$$LANGUAGE plpgsql;ALTER TABLE lots ALTER COLUMN lot_number SET DEFAULT next_lot_number();
Работни потоци
Дори функцията с един оператор има решаващо предимство пред външния код:изпълнението никога не напуска безопасността на ACID гаранциите на базата данни. Сравнете next_lot_number по-горе към възможностите на клиентско приложение или дори ръчен процес, изпълняващ
Съхранените програми с множество оператори отварят огромно пространство от възможности, тъй като SQL включва всички инструменти, необходими за писане на процедурен код, от обработка на изключения до точки за запис (това е дори Тюринг в комплект с функции на прозореца и общи изрази на таблици!). Цели работни потоци за обработка на данни могат да се извършват в базата данни, като се сведе до минимум излагането на други области на системата и се елиминират отнемащи време връщане между базата данни и други домейни.
Толкова голяма част от софтуерната архитектура като цяло е свързана с управлението и изолирането на сложността, предотвратявайки нейното разпространение през границите между подсистемите. Ако някой повече или по-малко сложен работен процес включва изтегляне на данни в бекенд на приложение, скрипт или cron задание, усвояване и добавяне към него и съхраняване на резултата - време е да попитате какво наистина налага да се изхвърлите извън базата данни.
Както бе споменато по-горе, това е област, в която разликите между RDBMS вкусовете и SQL диалектите излизат на преден план. Функция или процедура, разработена за една база данни, вероятно няма да се изпълнява в друга без промени, независимо дали това замества TOP на SQL Server за стандартен LIMIT клауза или напълно преработка как се съхранява временното състояние в корпоративна миграция на Oracle към PostgreSQL. Канонизирането на работните ви потоци в SQL също ви ангажира с текущата ви платформа и диалект по-задълбочено от почти всеки друг избор, който можете да направите.
Изчисления в заявки
Досега разглеждахме използването на функции за съхраняване и модифициране на данни, независимо дали са свързани с дефиниции на таблици или управляващи работни потоци с няколко таблици. В известен смисъл това е по-мощната употреба, за която могат да бъдат използвани, но функциите имат място и при извличането на данни. Много инструменти, които вече може да използвате във вашите заявки, са внедрени като функции от стандартни вградени модули като count към разширения като jsonb_build_object на Postgres , ST_SnapToGrid на PostGIS , и още. Разбира се, тъй като те са по-тясно интегрирани със самата база данни, те са написани предимно на езици, различни от SQL (напр. C в случая на PostgreSQL и PostGIS).
Ако често се оказвате (или смятате, че може да се окажете) да се нуждаете от извличане на данни и след това да извършите някаква операция върху всеки запис, преди да е наистина готови, вместо това помислете за трансформирането им на излизане от базата данни! Прогнозиране на определен брой работни дни след дата? Генериране на разлика между два JSONB полета? На практика всяко изчисление, което зависи само от информацията, която заявявате, може да се извърши в SQL. И това, което се прави в базата данни – стига да се осъществява последователен достъп – е канонично, що се отнася до всичко, изградено върху базата данни.
Трябва да се каже:ако работите с бекенд на приложение, неговият инструментариум за достъп до данни може да ограничи колко пробег получавате от увеличаването на резултатите от заявките с функции. Повечето такива библиотеки могат да изпълняват произволен SQL, но тези, които генерират общи SQL изрази, базирани на класове на модела, могат или не позволяват персонализиране на заявка SELECT списъци. Генерираните колони или изгледи могат да бъдат отговор тук.
Задействания и последици
Функциите и процедурите са достатъчно спорни сред дизайнерите на бази данни и потребителите, но нещата наистина излитане с тригери. Тригерът дефинира автоматично действие, обикновено процедура (SQLite позволява само един израз), което да бъде изпълнено преди, след или вместо друго действие.
Иницииращото действие обикновено е вмъкване, актуализиране или изтриване в таблица и процедурата за задействане обикновено може да бъде настроена да се изпълнява или за всеки запис, или за израза като цяло. SQL Server също така позволява тригери на обновяеми изгледи, най-вече като начин за налагане на по-подробни мерки за сигурност; и той, PostgreSQL и Oracle предлагат някаква форма на събитие или
Често срещано нискорисково използване за тригери е като изключително мощно ограничение, предотвратяващо съхраняването на невалидни данни. Във всички основни релационни бази данни само първични и външни ключове и UNIQUE ограниченията могат да оценяват информация извън записа на кандидата. Не е възможно да се декларира в дефиниция на таблица, че например само две партиди могат да бъдат създадени за един месец - и най-простото решение за база данни и код е уязвимо към подобно състояние на състезание като подхода count-then-set за lot_number по-горе. За да наложите всяко друго ограничение, което включва цялата таблица или други таблици, имате нужда от
CREATE FUNCTION enforce_monthly_lot_limit () RETURNS TRIGGERAS $$DECLARE current_count BIGINT;BEGIN SELECT count(*) INTO current_count FROM lots WHERE date_trunc('month', created_at) = date_trunc('month', NEW.created_at); IF current_count >= 2 THEN RAISE EXCEPTION 'Two lots already created this month'; END IF; RETURN NEW;END;$$LANGUAGE plpgsql;CREATE TRIGGER monthly_lot_limitBEFORE INSERT ON lotsFOR EACH ROWEXECUTE PROCEDURE enforce_monthly_lot_limit();
След като започнете да изпълнявате lots само по себе си може да бъде последната операция на задействане, инициирано от вмъкване в orders , без човешки потребител или бекенд на приложение, упълномощен да пише в lots директно. Или като items се добавят към партида, тригер там може да се справи с актуализирането на current_quantity , и стартирайте друг процес, когато достигне target_quantity .
Тригерите и функциите могат да се изпълняват на нивото на достъп на техния дефинер (в PostgreSQL, SECURITY DEFINER декларация до LANGUAGE на функция ), което дава на иначе ограничените потребители властта да инициират по-широкообхватни процеси – и прави валидирането и тестването на тези процеси още по-важни.
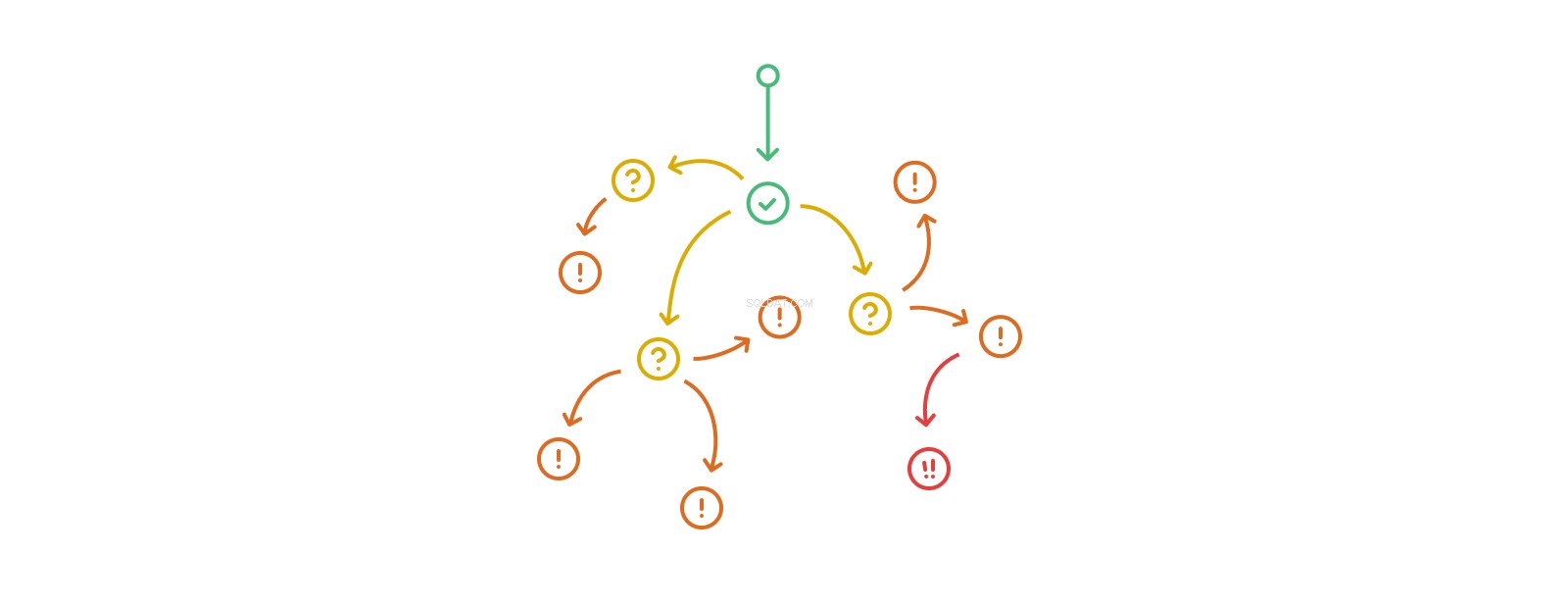
Стекът за обаждания задействане-действие-тригер-действие може да стане произволно дълъг, въпреки че истинската рекурсия под формата на многократна промяна на едни и същи таблици или записи във всеки такъв поток е незаконна на някои платформи и по-общо е лоша идея при почти всички обстоятелства. Влагането на задействания бързо изпреварва способността ни да разберем неговата степен и ефекти. Базите данни, които активно използват вложени тригери, започват да се отклоняват от сферата на сложното към тази на комплекса, като стават трудни или невъзможни за анализиране, отстраняване на грешки и прогнозиране.
Практическа програмируемост
Изчисленията в базата данни не са просто по-бързи и по-сбити изрази:те елиминират неяснотите и задават стандарти. Примерите по-горе освобождават потребителите на база данни от необходимостта да изчисляват сами номера на партиди или от притеснения за случайно създаване на повече партиди, отколкото могат да се справят. Специално разработчиците на приложения често са били обучени да мислят за базите данни като за „тъпо хранилище“, осигуряващо само структура и постоянство и по този начин могат да се окажат – или по-лошо, да не осъзнаят, че са – тромаво артикулират извън базата данни какво биха могли да направят по-ефективно в SQL.
Програмируемостта е несправедливо пренебрегвана характеристика на релационните бази данни. Съществуват причини да го избягвате и повече, за да ограничите използването му, но функциите, процедурите и тригерите са мощни инструменти за ограничаване на сложността, която вашият модел на данни налага върху системите, в които е вграден.