Както всеки език за програмиране, T-SQL има своя дял от често срещани грешки и клопки, някои от които причиняват неправилни резултати, а други причиняват проблеми с производителността. В много от тези случаи има най-добри практики, които могат да ви помогнат да избегнете проблеми. Анкетирах колеги MVP на платформата за данни на Microsoft, питайки за грешките и подводните камъни, които виждат често или които просто намират за особено интересни, и най-добрите практики, които използват, за да ги избегнат. Имам много интересни случаи.
Много благодаря на Ерланд Сомарског, Аарон Бертран, Алехандро Меса, Умачандар Джаячандран (UC), Фабиано Невес Аморим, Милош Радивоевич, Саймън Сабин, Адам Мачаник, Томас Гросер и Чан Минг Ман за споделянето на вашите знания и опит!
Тази статия е първата от поредица по темата. Всяка статия се фокусира върху определена тема. Този месец се фокусирам върху грешки, клопки и най-добри практики, които са свързани с детерминизма. Детерминистичното изчисление е такова, което гарантирано ще даде повторяеми резултати при едни и същи входни данни. Има много грешки и клопки, които са резултат от използването на недетерминистични изчисления. В тази статия разглеждам последиците от използването на недетерминиран ред, недетерминирани функции, множество препратки към таблични изрази с недетерминистични изчисления и използването на CASE изрази и функцията NULLIF с недетерминистични изчисления.
Използвам примерната база данни TSQLV5 в много от примерите в тази серия.
Недетерминиран ред
Един често срещан източник за грешки в T-SQL е използването на недетерминиран ред. Тоест, когато вашата поръчка по списък не идентифицира уникално ред. Това може да бъде поръчване на презентация, поръчка на TOP/OFFSET-FETCH или поръчка на прозорец.
Вземете за пример класически сценарий за пейджинг, използващ филтъра OFFSET-FETCH. Трябва да направите заявка в таблицата Sales.Orders, връщайки една страница от 10 реда наведнъж, подредени по дата на поръчка, низходяща (първо най-новата). Ще използвам константи за елементите за отместване и извличане за простота, но обикновено те са изрази, които се основават на входни параметри.
Следната заявка (наречете я Заявка 1) връща първата страница от 10 най-нови поръчки:
ИЗПОЛЗВАЙТЕ TSQLV5; ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчка, custid ОТ Sales.Orders ПОРЪЧАЙТЕ ПО дата на поръчка DESC ОТМЕСТВАНЕ 0 РЕДА ИЗВЛЕЧВАНЕ СЛЕДВАЩИТЕ 10 РЕДА САМО;
Планът за заявка 1 е показан на фигура 1.
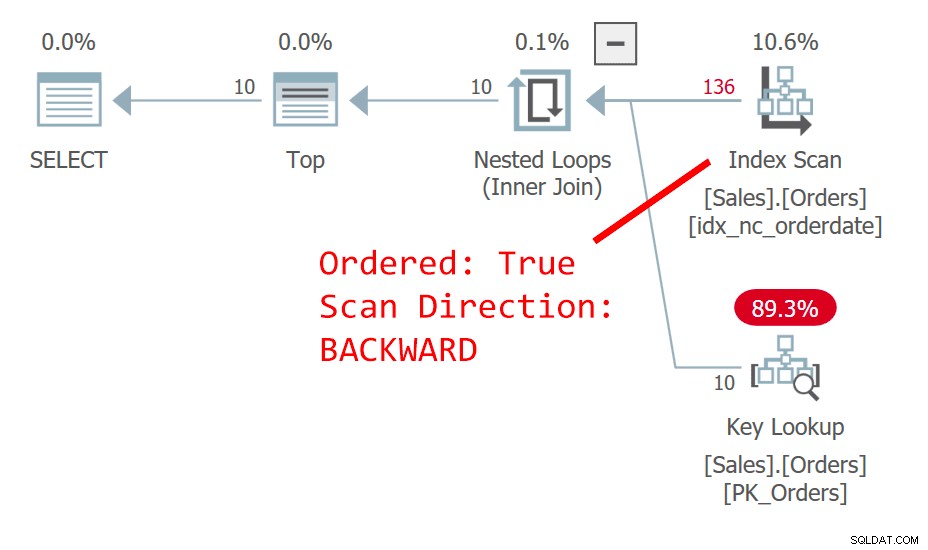 Фигура 1:План за заявка 1
Фигура 1:План за заявка 1
Заявката подрежда редовете по дата на поръчка, низходяща. Колоната с дата на поръчка не идентифицира уникално ред. Този недетерминистичен ред означава, че концептуално няма предпочитание между редовете с една и съща дата. В случай на връзки, това, което определя кой ред SQL Server ще предпочете, са неща като избор на план и разположение на физическите данни - а не нещо, на което можете да разчитате като повторяем. Планът на фигура 1 сканира индекса на датата на поръчка, подредена назад. Случва се така, че тази таблица има клъстериран индекс на orderid, а в клъстерирана таблица ключът на клъстерирания индекс се използва като локатор на редове в неклъстерирани индекси. Той всъщност се позиционира имплицитно като последен ключов елемент във всички неклъстерирани индекси, въпреки че теоретично SQL Server би могъл да го постави в индекса като включена колона. Така че, имплицитно, неклъстерираният индекс на дата на поръчка всъщност е дефиниран на (orderdate, orderid). Следователно, в нашето подредено обратно сканиране на индекса, между обвързани редове въз основа на датата на поръчка, се осъществява достъп до ред с по-висока стойност на порядъка преди ред с по-ниска стойност на порядъка. Тази заявка генерира следния изход:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 5-05-06-05-01-2019-05-2019-05-2019 80 *** 11068 2019-05-04 62
След това използвайте следната заявка (наречете я Заявка 2), за да получите втората страница от 10 реда:
ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчка, custid ОТ Продажби. Поръчки ПОРЪЧАЙТЕ ПО дата на поръчка DESC ОТМЕСТВАНЕ 10 РЕДА ИЗВЛЕЧВАНЕ СЛЕДВАЩИ 10 РЕДА САМО;
Планът за заявка е показан на фигура 2.
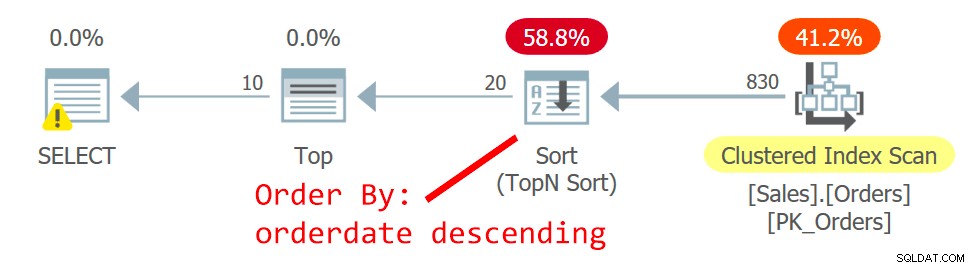
Фигура 2:План за заявка 2
Оптимизаторът избира различен план – единият сканира клъстерирания индекс по неподреден начин и използва TopN сортиране, за да подкрепи заявката на оператора Top за обработка на филтъра за извличане на отместване. Причината за промяната е, че планът на фигура 1 използва неклъстериран непокриващ индекс и колкото по-далеч е страницата, която преследвате, толкова повече търсения са необходими. С заявката за втора страница прехвърлихте повратната точка, която оправдава използването на индекса без покритие.
Въпреки че сканирането на клъстерирания индекс, което е дефинирано с orderid като ключ, е неподредено, механизмът за съхранение използва вътрешно сканиране на реда на индекса. Това е свързано с размера на индекса. До 64 страници механизмът за съхранение обикновено предпочита сканирането на реда на индекс пред сканирането на поръчката за разпределение. Дори ако индексът е бил по-голям, под нивото на изолация за четене и данните, които не са маркирани като само за четене, механизмът за съхранение използва сканиране на реда на индекса, за да избегне двойно четене и пропускане на редове в резултат на разделяне на страници, което се случва по време на сканиране. При дадените условия на практика между редове с една и съща дата този план осъществява достъп до ред с по-нисък идентификатор на поръчка преди такъв с по-висок идентификатор.
Тази заявка генерира следния изход:
orderid orderdate custid ----------- ---------- ----------- 11069 2019-05-04 80 *** 11064 2019 -05-01 71 11065 2019-05-01 46 11066 2019-05-01 89 11060 2019-04-30 27 11061 2019-04-30 32 11062 32 11062 11062 11062 32 11062 62 04-29 53 11058 2019-04-29 6
Обърнете внимание, че въпреки че основните данни не са се променили, в крайна сметка сте получили същата поръчка (с идентификатор на поръчката 11069), върната както на първата, така и на втората страница!
Надяваме се, че най-добрата практика тук е ясна. Добавете тайбрейк към вашата поръчка по списък, за да получите детерминирана поръчка. Например низходящ ред по дата на поръчка, низходящ ред по ред.
Опитайте отново да поискате първата страница, този път с детерминиран ред:
ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчка, custid ОТ Продажби. Поръчки ПОРЪЧАЙТЕ ПО дата на поръчка DESC, идентификатор на поръчката DESC ОТМЕСТВАНЕ 0 РЕДА ИЗВЛЕЧВАНЕ НА СЛЕДВАЩИТЕ 10 РЕДА САМО;
Получавате следния изход, гарантиран:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 5-05-06-05-01-2019-05-2019-05-2019 80 11068 2019-05-04 62
Поискайте втората страница:
ИЗБЕРЕТЕ orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 10 ROWS FETCH СЛЕДВАЩИТЕ 10 РЕДА САМО;
Получавате следния изход, гарантиран:
orderid orderdate custid ----------- ---------- ----------- 11067 2019-05-04 17 11066 2019-05- 01 89 11065 2019-05-01 46 11064 2019-05-01 71 11063 2019-04-30 37 11062 2019-04-30 66 11061 2019-05-01 09-2019-01-2019-01-2019 67 11058 2019-04-29 6
Докато няма промени в основните данни, гарантирано ще получите последователни страници без повторения или пропускане на редове между страниците.
По подобен начин, като използвате функции на прозорец като ROW_NUMBER с недетерминиран ред, можете да получите различни резултати за една и съща заявка в зависимост от формата на плана и действителния ред на достъп между връзките. Помислете за следната заявка (наречете я Заявка 3), която изпълнява заявката за първа страница с помощта на номера на редове (принуждавайки използването на индекса на датата на поръчка за илюстративни цели):
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders WITH (INDEX(idx_nc_orderdate)) ) SELECT orderid, orderdate, custid FROM C WHERE n BETWEWE И 10;
Планът за тази заявка е показан на Фигура 3:
Фигура 3:План за заявка 3
Тук имате много сходни условия с тези, които описах по-рано за заявка 1 с нейния план, който беше показан по-рано на фигура 1. Между редове с връзки в стойностите на датата на поръчка, този план осъществява достъп до ред с по-висока стойност на порядъка преди един с по-ниска поръчана стойност. Тази заявка генерира следния изход:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 5-05-06-05-01-2019-05-2019-05-2019 80 *** 11068 2019-05-04 62
След това стартирайте заявката отново (наречете я Query 4), като поискате първата страница, само че този път принудете използването на клъстерирания индекс PK_Orders:
С C AS ( ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчка, custid, ROW_NUMBER() НАД (ПОРЪЧКА ПО дата на поръчка DESC) КАТО n ОТ Продажби. Поръчки WITH (INDEX(PK_Orders)) ) ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчка, custid ОТ C КЪДЕ n МЕЖДУ 1 И 10;
Планът за тази заявка е показан на Фигура 4.

Фигура 4:План за заявка 4
Този път имате много сходни условия с тези, които описах по-рано за Заявка 2 с нейния план, който беше показан по-рано на Фигура 2. Между редове с връзки в стойностите на датата на поръчка, този план осъществява достъп до ред с по-ниска стойност на поръчката преди един с по-висока порядкова стойност. Тази заявка генерира следния изход:
orderid orderdate custid ----------- ---------- ----------- 11074 2019-05-06 73 11075 2019-05- 06 68 11076 2019-05-06 9 11077 2019-05-06 65 11070 2019-05-05 44 11071 2019-05-05 46 11072 5-05-2019-05-2019-05-2019-05-2019 17 *** 11068 2019-05-04 62
Забележете, че двете изпълнения са дали различни резултати, въпреки че нищо не се е променило в основните данни.
Отново, най-добрата практика тук е проста – използвайте детерминиран ред, като добавите тайбрейк, както следва:
С C AS ( ИЗБЕРЕТЕ идентификатор на поръчка, дата на поръчка, custid, ROW_NUMBER() OVER(ORDER BY DESC, orderid DESC) КАТО n ОТ Sales.Orders ) SELECT orderid, orderdate, custid ОТ C, КЪДЕ n МЕЖДУ 1 И 10;Тази заявка генерира следния изход:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 5-05-06-05-01-2019-05-2019-05-2019 80 11068 2019-05-04 62Върнатият набор е гарантирано повторяем, независимо от формата на плана.
Вероятно си струва да се спомене, че тъй като тази заявка няма ред на представяне по клауза във външната заявка, тук няма гарантиран ред на представяне. Ако имате нужда от такава гаранция, трябва да добавите ред за представяне по клауза, както следва:
С C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n FROM Sales.Orders ) SELECT orderid, orderdate, custid ОТ C КЪДЕ n МЕЖДУ 1 И 10 ORDERBY n;Недетерминирани функции
Недетерминирана функция е функция, която при едни и същи входни данни може да върне различни резултати при различни изпълнения на функцията. Класически примери са SYSDATETIME, NEWID и RAND (когато се извиква без входно начало). Поведението на недетерминистичните функции в T-SQL може да бъде изненадващо за някои и може да доведе до грешки и клопки в някои случаи.
Много хора приемат, че когато извикате недетерминистична функция като част от заявка, функцията се оценява отделно за всеки ред. На практика повечето недетерминистични функции се оценяват веднъж на препратка в заявката. Разгледайте следната заявка като пример:
ИЗБЕРЕТЕ orderid, SYSDATETIME() КАТО dt, RAND() КАТО rnd ОТ Sales.Orders;Тъй като има само една препратка към всяка от недетерминистичните функции SYSDATETIME и RAND в заявката, всяка от тези функции се оценява само веднъж и резултатът й се повтаря във всички редове с резултати. Получих следния изход при изпълнение на тази заявка:
orderid dt rnd ----------- --------------------------- ------ ---------------- 11008 2019-02-04 17:03:07.9229177 0.962042872007464 11019 2019-02-04 17:03:07.9229177 0.962017 0.962017 0.962017 0.962017 0.962017 0.962017 07.9229177 0.962042872007464 11040 2019-02-04 17:03:07.9229177 0.962042872007464 11045 2019-02-04 17:03:07.9229177 0.962042872007464 11051 2019-02-04 17:03:07.9229177 0.962042872007464 11054 2019-02-04 17:03:07.9229177 0.962042872007464 11058 2019-02-04 17:03:07.9229177 0.962042872007464 11059 2019-02-04 17:03:07.9229177 0.962042872007464 11061 2019-02-04 17:03:07.9229177 0.962042872007464 ...Като пример, когато неразбирането на това поведение може да доведе до грешка, да предположим, че трябва да напишете заявка, която връща три произволни поръчки от таблицата Sales.Orders. Често срещан първоначален опит е да се използва ТОП заявка с подреждане въз основа на функцията RAND, като се смята, че функцията ще бъде оценявана отделно на ред, като така:
ИЗБЕРЕТЕ ТОП (3) идентификатор на поръчка ОТ Продажби. Поръчки ПОРЪЧАЙТЕ ПО RAND();На практика функцията се оценява само веднъж за цялата заявка; следователно всички редове получават един и същ резултат и подреждането е напълно незасегнато. Всъщност, ако проверите плана за тази заявка, няма да видите оператор за сортиране. Когато изпълнявах тази заявка няколко пъти, продължавах да получавам същия резултат:
orderid ----------- 11008 11019 11039Заявката всъщност е еквивалентна на такава без клауза ORDER BY, където подреждането на презентацията не е гарантирано. Така че технически подреждането е недетерминистично и теоретично различните изпълнения могат да доведат до различен ред и следователно до различен избор на горните 3 реда. Вероятността за това обаче е малка и не можете да мислите за това решение като за създаване на три произволни реда при всяко изпълнение.
Изключение от правилото, че недетерминирана функция се извиква веднъж на препратка в заявката, е функцията NEWID, която връща глобално уникален идентификатор (GUID). Когато се използва в заявка, тази функция е извиква се отделно на ред. Следната заявка демонстрира това:
ИЗБЕРЕТЕ orderid, NEWID() КАТО mynewid ОТ Sales.Orders;Тази заявка генерира следния изход:
orderid mynewid ----------- ---------------------------------- -- 11008 D6417542-C78A-4A2D-9517-7BB0FCF3B932 11019 E2E46BF1-4FA6-4EF2-8328-18B86259AD5D 11039 2917D923-AC60-44F5-92D7-FF84E52250CC 11040 B6287B49-DAE7-4C6C-98A8-7DB8A879581C 11045 2E14D8F7-21E5-4039-BF7E -0A27D1A0E186 11051 FA0B7B3E-BA41-4D80-8581-782EB88836C0 11054 1E6146BB-FEE7-4FF4-A4A2-3243AA2CBF78 11058 49302EA9-0243-4502-B9D2-46D751E6EFA9 11059 F5BB7CB2-3B17-4D01-ABD2-04F3C5115FCF 11061 09E406CA-0251-423B-8DF5 -564E1257F93E ...Стойността на самата NEWID е доста случайна. Ако приложите функцията CHECKSUM върху нея, получавате целочислен резултат с още по-добро произволно разпределение. Така че един от начините да получите три произволни поръчки е да използвате TOP заявка с подреждане въз основа на CHECKSUM(NEWID()), като така:
ИЗБЕРЕТЕ ТОП (3) идентификатор на поръчката ОТ Продажби. Поръчки ПОРЪЧАЙТЕ ПО КОНТРОННА СУМА(NEWID());Изпълнете тази заявка многократно и забележете, че всеки път получавате различен набор от три произволни поръчки. Получих следния изход с едно изпълнение:
orderid ----------- 11031 10330 10962И следния изход в друго изпълнение:
orderid ----------- 10308 10885 10444Освен NEWID, какво ще стане, ако трябва да използвате недетерминирана функция като SYSDATETIME в заявка и трябва тя да бъде оценявана отделно на ред? Един от начините да се постигне това е да се използва дефинирана от потребителя функция (UDF), която извиква недетерминистичната функция, както следва:
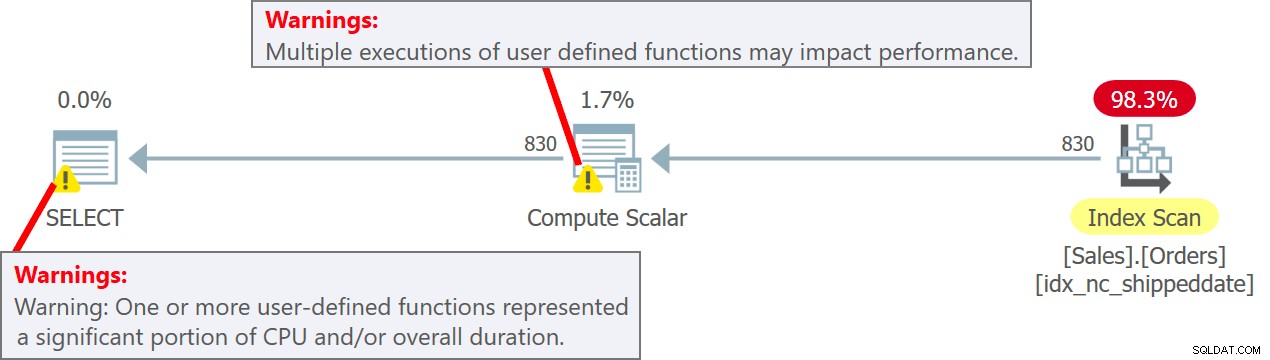
СЪЗДАВАНЕ ИЛИ ПРОМЕНЯНЕ НА ФУНКЦИЯ dbo.MySysDateTime() ВРЪЩА DATETIME2 КАТО НАЧАЛО ВРЪЩА SYSDATETIME(); КРАЙ; ОТПРАВИСлед това извиквате UDF в заявката така (наречете го Заявка 5):
ИЗБЕРЕТЕ orderid, dbo.MySysDateTime() КАТО mydt ОТ Sales.Orders;Този път UDF се изпълнява на ред. Трябва обаче да сте наясно, че има доста рязко наказание за производителност, свързано с изпълнението на UDF на ред. Освен това, извикването на скаларен T-SQL UDF е инхибитор на паралелизма.
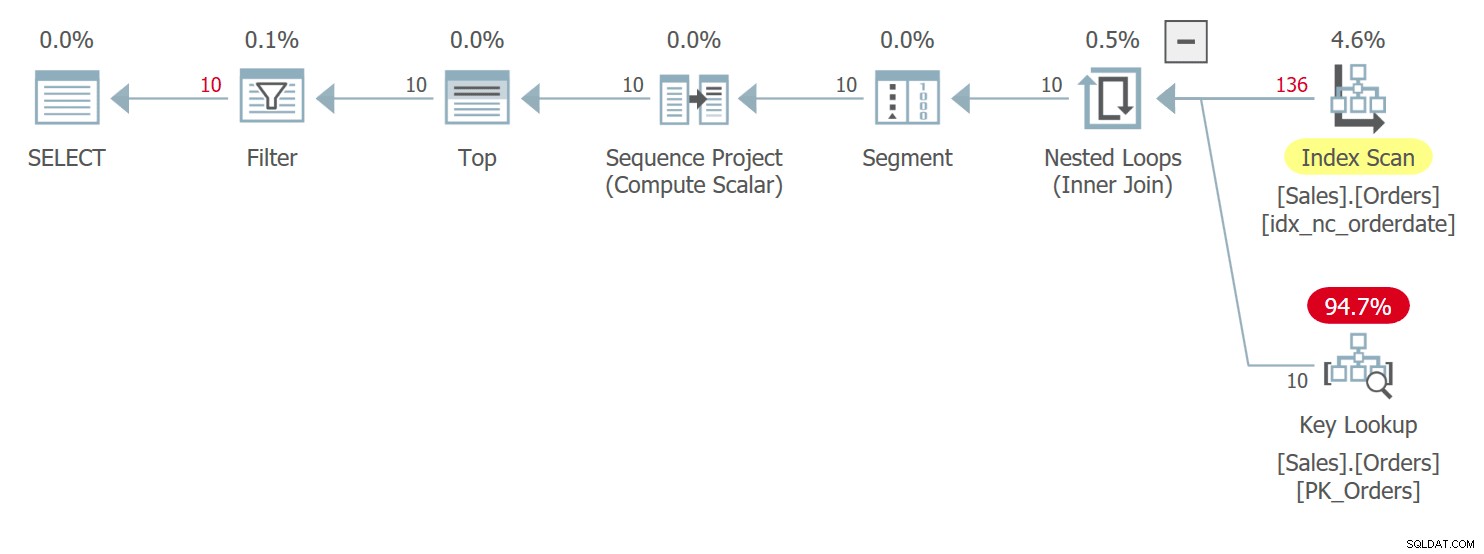
Планът за тази заявка е показан на Фигура 5.
Фигура 5:План за заявка 5Забележете в плана, че действително UDF се извиква за всеки ред източник в оператора Compute Scalar. Също така имайте предвид, че SentryOne Plan Explorer ви предупреждава за потенциалното увреждане на производителността, свързано с използването на UDF както в оператора Compute Scalar, така и в основния възел на плана.
Получих следния изход от изпълнението на тази заявка:
orderid mydt ----------- ------------------------------------ 11008 2019-02-04 17 :07:03.7221339 11019 2019-02-04 17:07:03.7221339 11039 2019-02-04 17:07:03.7221339 ... 10251 2019-02-04 17:07:03.7231315 10255 2019-02-04 17:07:03.7231315 10248 2019-02-04 17:07:03.7231315 ... 10416 2019-02-04 17:07:03.7241304 10420 2019-02-04 17:07:03.7241304 10421 2019-02-04 17:07:03.7241304 .. .Обърнете внимание, че изходните редове имат множество различни стойности за дата и час в колоната mydt.
Може да сте чували, че SQL Server 2019 адресира често срещания проблем с производителността, причинен от скаларните T-SQL UDF, чрез вграждане на такива функции. Въпреки това, UDF трябва да отговаря на списък с изисквания, за да бъде интегриран. Едно от изискванията е UDF да не извиква никаква недетерминирана вътрешна функция като SYSDATETIME. Причината за това изискване е, че може би сте създали UDF точно, за да получите изпълнение на ред. Ако UDF бъде вграден, основната недетерминистична функция ще се изпълни само веднъж за цялата заявка. Всъщност планът на фигура 5 е генериран в SQL Server 2019 и можете ясно да видите, че UDF не е вграден. Това се дължи на използването на недетерминираната функция SYSDATETIME. Можете да проверите дали UDF е вграден в SQL Server 2019, като потърсите атрибута is_inlineable в изгледа sys.sql_modules, както следва:
ИЗБЕРЕТЕ is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID(N'dbo.MySysDateTime');Този код генерира следния изход, който ви казва, че UDF MySysDateTime не е вграден:
is_inlineable ------------- 0За да демонстрирате UDF, който е вграден, ето дефиницията на UDF, наречена EndOfyear, която приема входна дата и връща съответната дата на края на годината:
СЪЗДАВАНЕ ИЛИ ПРОМЕНЯНЕ НА ФУНКЦИЯ dbo.EndOfYear(@dt КАТО ДАТА) ВРЪЩА ДАТАТА КАТО НАЧАЛНО ВРЪЩАНЕ DATEADD(година, DATEDIFF(година, '18991231', @dt), '18991231'); КРАЙ; ОТПРАВИТук не се използват недетерминирани функции, а кодът отговаря и на другите изисквания за вграждане. Можете да проверите дали UDF е вграден, като използвате следния код:
ИЗБЕРЕТЕ is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID(N'dbo.EndOfYear');Този код генерира следния изход:
is_inlineable ------------- 1Следната заявка (наречете я Заявка 6) използва UDF EndOfYear за филтриране на поръчки, които са били поставени на дата в края на годината:
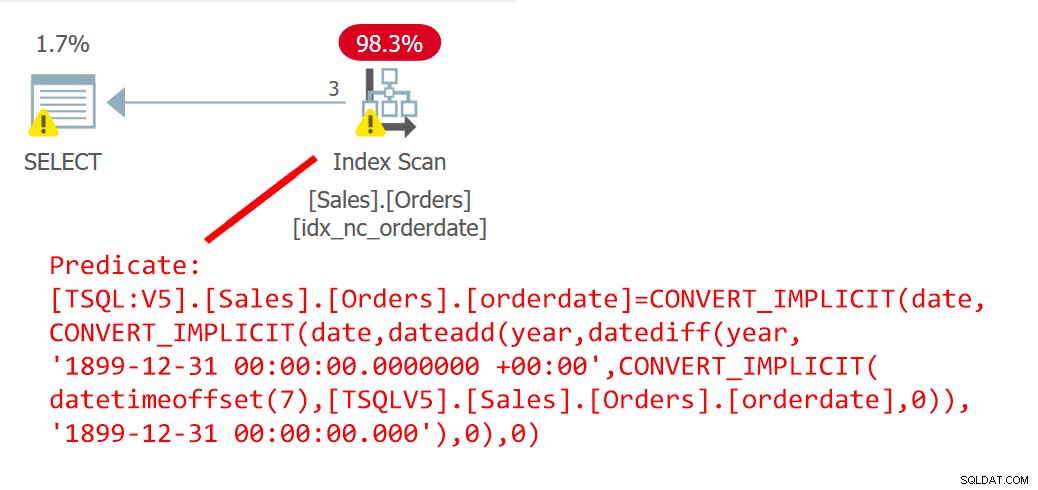
ИЗБЕРЕТЕ идентификатор на поръчка ОТ Sales.Orders WHERE orderdate =dbo.EndOfYear(orderdate);Планът за тази заявка е показан на фигура 6.
Фигура 6:План за заявка 6Планът ясно показва, че СДС се е вградил.
Таблични изрази, недетерминизъм и множество препратки
Както споменахме, недетерминирани функции като SYSDATETIME се извикват веднъж на препратка в заявка. Но какво ще стане, ако посочите такава функция веднъж в заявка в табличен израз като CTE и след това имате външна заявка с множество препратки към CTE? Много хора не осъзнават, че всяка препратка към табличния израз се разширява отделно и вграденият код води до множество препратки към основната недетерминистична функция. С функция като SYSDATETIME, в зависимост от точното време на всяко от изпълненията, можете да получите различен резултат за всяко. Някои хора намират това поведение за изненадващо.
Това може да се илюстрира със следния код:
ДЕКЛАРИРАНЕ @i КАТО INT =1, @rc КАТО INT =NULL; ДОКАТО 1 =1 ЗАПОЧВА; С C1 AS ( ИЗБЕРЕТЕ SYSDATETIME() КАТО dt ), C2 AS ( ИЗБЕРЕТЕ dt ОТ C1 UNION SELECT dt ОТ C1 ) SELECT @rc =COUNT(*) ОТ C2; IF @rc> 1 BREAK; SET @i +=1; КРАЙ; ИЗБЕРЕТЕ @rc AS различни стойности, @i AS итерации;Ако и двете препратки към C1 в заявката в C2 представляват едно и също нещо, този код би довел до безкраен цикъл. Въпреки това, тъй като двете препратки се разширяват поотделно, когато времето е такова, че всяко извикване се извършва в различен интервал от 100 наносекунди (прецизността на стойността на резултата), обединението води до два реда и кодът трябва да се раздели от цикъл. Изпълнете този код и се уверете сами. Всъщност след няколко повторения се счупва. Получих следния резултат при едно от изпълненията:
итерации на различни стойности -------------- ----------- 2 448Най-добрата практика е да избягвате използването на таблични изрази като CTE и изгледи, когато вътрешната заявка използва недетерминистични изчисления, а външната заявка се препраща към табличния израз многократно. Това, разбира се, освен ако не разберете последствията и не сте ОК с тях. Алтернативните опции могат да бъдат да запазите резултата от вътрешната заявка, да речем във временна таблица, и след това да направите заявка във временната таблица произволен брой пъти, от който се нуждаете.
За да демонстрирате примери, при които неспазването на най-добрите практики може да ви създаде проблеми, да предположим, че трябва да напишете заявка, която сдвоява служителите от таблицата HR.Employees на случаен принцип. Измисляте следната заявка (наречете я заявка 7), за да се справите със задачата:
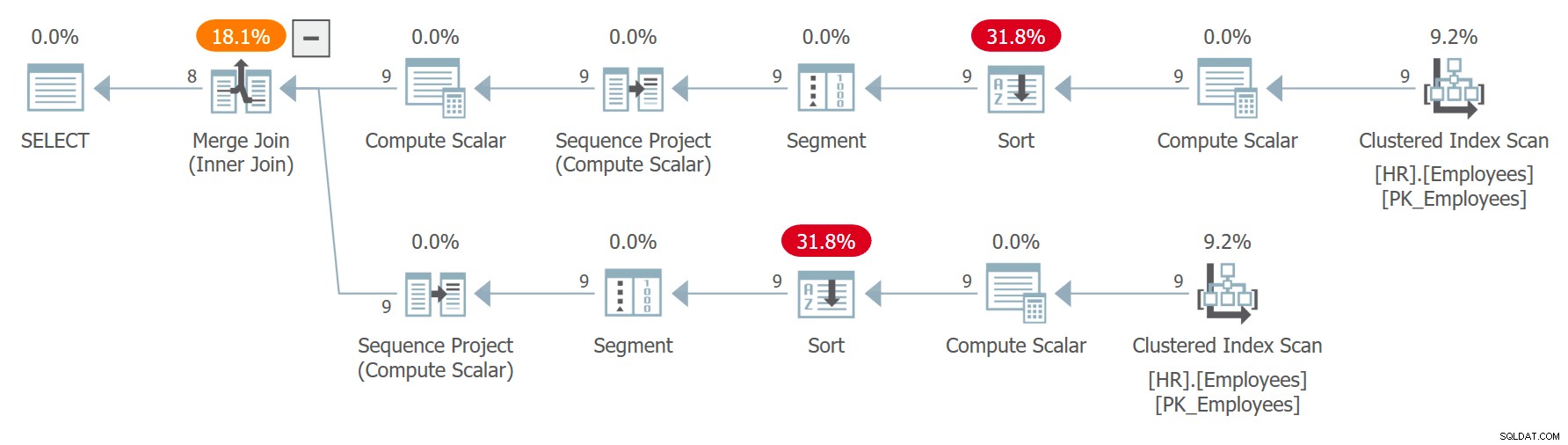
С C AS ( ИЗБЕРЕТЕ empid, собствено име, фамилия, ROW_NUMBER() НАД(ПОРЪЧКА ПО КОНТРОЛНА СУМА(НОВИД())) КАТО n ОТ HR.Служители ) ИЗБЕРЕТЕ C1.empid КАТО empid1, C1.firstname КАТО първо име1, C1. фамилия КАТО фамилия1, C2.empid КАТО empid2, C2.firstname КАТО първо име2, C2.фамилия КАТО фамилия2 ОТ C КАТО C1 ВЪТРЕШНО ПРИЕДИНЕНИЕ C КАТО C2 НА C1.n =C2.n + 1;Планът за тази заявка е показан на Фигура 7.
Фигура 7:План за заявка 7Забележете, че двете препратки към C се разширяват поотделно и номерата на редовете се изчисляват независимо за всяка препратка, подредена чрез независимо извикване на израза CHECKSUM(NEWID()). Това означава, че един и същ служител няма гаранция, че ще получи същия номер на ред в двете разширени препратки. Ако служител получи номер на ред x в C1 и ред номер x – 1 в C2, заявката ще сдвои служителя със себе си. Например получих следния резултат при едно от изпълненията:
empid1 име1 фамилия1 empid2 име2 фамилия2 ----------- ---------- -------------------- ----------- ---------- -------------------- 3 Джуди Лю 6 Пол Сурс 9 Патриша Дойл *** 9 Патриша Дойл *** 5 Свен Мортенсен 4 Яел Пелед 6 Пол Сурс 8 Мария Камерън 8 Мария Камерън 5 Свен Мортенсен 2 Дон Фънк *** 2 Дон Фънк *** 4 Яел Пелед 3 Джуди Лю 7 Ръсел Кинг ** * 7 Ръсел Кинг ***Забележете, че тук има три случая на самодвойки. Това е по-лесно да се види чрез добавяне на филтър към външната заявка, която специално търси самостоятелни двойки, като така:
С C AS ( ИЗБЕРЕТЕ empid, собствено име, фамилия, ROW_NUMBER() НАД(ПОРЪЧКА ПО КОНТРОЛНА СУМА(НОВИД())) КАТО n ОТ HR.Служители ) ИЗБЕРЕТЕ C1.empid КАТО empid1, C1.firstname КАТО първо име1, C1. фамилия КАТО фамилия1, C2.empid КАТО empid2, C2.firstname КАТО първо име2, C2.фамилия КАТО фамилия2 ОТ C КАТО C1 ВЪТРЕШНО ПРИСЪЕДИНЕНИЕ C КАТО C2 НА C1.n =C2.n + 1 КЪДЕ C1.empid =C2.empid;Може да се наложи да изпълните тази заявка няколко пъти, за да видите проблема. Ето пример за резултата, който получих при едно от изпълненията:
empid1 име1 фамилия1 empid2 име2 фамилия2 ----------- ---------- -------------------- ----------- ---------- -------------------- 5 Свен Мортенсен 5 Свен Мортенсен 2 Дон Фънк 2 Дон ФънкСледвайки най-добрата практика, един от начините за решаване на този проблем е да запазите резултата от вътрешната заявка във временна таблица и след това да направите заявка за множество екземпляри на временната таблица, ако е необходимо.
Друг пример илюстрира грешки, които могат да бъдат резултат от използването на недетерминиран ред и множество препратки към табличен израз. Да предположим, че трябва да направите заявка в таблицата Sales.Orders и за да направите анализ на тенденцията, искате да сдвоите всяка поръчка със следващата въз основа на подреждането по дата на поръчка. Вашето решение трябва да е съвместимо с пред-SQL Server 2012 системи, което означава, че не можете да използвате очевидните LAG/LEAD функции. Решавате да използвате CTE, който изчислява номера на редове, за да позиционирате редове въз основа на подреждането по дата на поръчка и след това да присъедините два екземпляра на CTE, сдвоявайки поръчки въз основа на отместване от 1 между номерата на редовете, като така (наречете тази заявка 8):
С C AS ( SELECT *, ROW_NUMBER() НАД (ПОРЪЧКА ПО дата на поръчка DESC) КАТО n ОТ Sales.Orders ) ИЗБЕРЕТЕ C1.orderid КАТО orderid1, C1.orderdate КАТО дата на поръчка1, C1.custid КАТО custid1, C2.orderid КАТО orderid2, C2.orderdate КАТО дата на поръчка2 ОТ C КАТО C1 ЛЯВО ВЪНШНО ПРИСЪЕДИНЕНИЕ C КАТО C2 НА C1.n =C2.n + 1;Планът за тази заявка е показан на Фигура 8.
Фигура 8:План за заявка 8
Подреждането на номера на редове не е детерминирано, тъй като датата на поръчката не е уникална. Обърнете внимание, че двете препратки към CTE се разширяват отделно. Любопитното е, че тъй като заявката търси различно подмножество от колони от всеки един от екземплярите, оптимизаторът решава да използва различен индекс във всеки случай. В един случай той използва подредено обратно сканиране на индекса на датата на поръчката, като ефективно сканира редове със същата дата въз основа на низходящ ред на orderid. В другия случай той сканира клъстерирания индекс, подреден е false и след това сортира, но ефективно между редове със същата дата, той осъществява достъп до редовете във възходящ ред. Това се дължи на подобни разсъждения, които предоставих в раздела за недетерминистичен ред по-рано. Това може да доведе до един и същи ред да получи номер на ред x в един екземпляр и ред номер x – 1 в другия екземпляр. В такъв случай присъединяването в крайна сметка ще съпостави поръчка със себе си, вместо със следващата, както би трябвало.
Получих следния резултат при изпълнение на тази заявка:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ---------- ---------- 11074 2019-05-06 73 NULL NULL 11075 2019-05-06 68 11077 2019-05-06 11076 2019-05-06 9 11076 11076 5-07 *** 2019-05-06 65 11075 2019-05-06 11070 2019-05-05 44 11074 2019-05-06 11071 2019-05-05 46 11073 11073 11073 11073 102 02 02 05 *** ...Наблюдавайте съвпаденията в резултата. Отново проблемът може да бъде идентифициран по-лесно чрез добавяне на филтър, който търси самосъвпадения, както следва:
С C AS ( SELECT *, ROW_NUMBER() НАД (ПОРЪЧКА ПО дата на поръчка DESC) КАТО n ОТ Sales.Orders ) ИЗБЕРЕТЕ C1.orderid КАТО orderid1, C1.orderdate КАТО дата на поръчка1, C1.custid КАТО custid1, C2.orderid КАТО orderid2, C2.orderdate КАТО дата на поръчка2 ОТ C КАТО C1 ЛЯВО ВЪНШНО ПРИСЪЕДИНЕНИЕ C КАТО C2 НА C1.n =C2.n + 1 КЪДЕ C1.orderid =C2.orderid;Получих следния изход от тази заявка:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ---------- ---------- 11076 2019-05-06 9 11076 2019-05-06 11072 2019-05-05 20 11072 2019-05-05 11062 2019-04-31-10-60 60 11052 2019-04-27 34 11052 2019-04-27 11042 2019-04-22 15 11042 2019-04-22 ...Най-добрата практика тук е да се уверите, че използвате уникален ред, за да гарантирате детерминизъм, като добавите тайбрейк като orderid към клаузата за поръчка на прозореца. Така че, въпреки че имате множество препратки към един и същ CTE, номерата на редовете ще бъдат еднакви и в двата. Ако искате да избегнете повторението на изчисленията, можете също да помислите за запазване на резултата от вътрешната заявка, но тогава трябва да вземете предвид допълнителните разходи за такава работа.
CASE/NULLIF и недетерминирани функции
Когато имате множество препратки към недетерминирана функция в заявка, всяка препратка се оценява отделно. Това, което може да бъде изненадващо и дори да доведе до грешки е, че понякога пишете една препратка, но имплицитно тя се преобразува в множество препратки. Такава е ситуацията с някои употреби на CASE израза и функцията IIF.
Помислете за следния пример:
ИЗБЕРЕТЕ СЛУЧАЙ ABS(КОНТРОЛНА СУМА(НОВИД())) % 2 КОГАТО 0 СЛЕД 'ЧЕТНО' КОГАТО 1 СЛЕД 'Нечетно' КРАЙ;Тук резултатът от тествания израз е неотрицателна стойност, така че очевидно трябва да бъде или четно, или нечетно. Не може да бъде нито четно, нито нечетно. However, if you run this code enough times, you will sometimes get a NULL indicating that the implied ELSE NULL clause of the CASE expression was activated. The reason for this is that the above expression translates to the following:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN 'Even' WHEN ABS(CHECKSUM(NEWID())) % 2 =1 THEN 'Odd' ELSE NULL END;In the converted expression there are two separate references to the tested expression that generates a random nonnegative value, and each gets evaluated separately. One possible path is that the first evaluation produces an odd number, the second produces an even number, and then the ELSE NULL clause is activated.
Here’s a very similar situation with the NULLIF function:
SELECT NULLIF(ABS(CHECKSUM(NEWID())) % 2, 0);This expression generates a random nonnegative value, and is supposed to return 1 when it’s odd, and NULL otherwise. It’s never supposed to return 0 since in such a case the 0 is supposed to be replaced with a NULL. Run it a few times and you will see that in some cases you get a 0. The reason for this is that the above expression internally translates to the following one:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN NULL ELSE ABS(CHECKSUM(NEWID())) % 2 END;A possible path is that the first WHEN clause generates a random odd value, so the ELSE clause is activated, and the ELSE clause generates a random even value so the % 2 calculation results in a 0.
In both cases this behavior is standard, so the bug is more in the eyes of the beholder based on your expectations and your choice of how to write the code. The best practice in both cases is to persist the result of the original calculation and then interact with the persisted result. If it’s a single value, store the result in a variable first. If you’re querying tables, first persist the result of the nondeterministic calculation in a column in a temporary table, and then apply the CASE/IIF logic in the query against the temporary table.
Заключение
This article is the first in a series about T-SQL bugs, pitfalls and best practices, and is the result of discussions with fellow Microsoft Data Platform MVPs who shared their experiences. This time I focused on bugs and pitfalls that resulted from using nondeterministic order and nondeterministic calculations. In future articles I’ll continue with other themes. If you have bugs and pitfalls that you often stumble into, or that you find as particularly interesting, please do share!