Има много неща, които трябва да имате предвид, когато проектирате база данни и много малко от нас могат да си спомнят всеки ценен съвет и трик, който сме научили. И така, нека да разгледаме някои онлайн ресурси, които включват съвети за дизайн на база данни и най-добри практики. Докато вървим, ще споделя собствените си мнения относно представените идеи въз основа на моя опит в дизайна на база данни.
Очевидно тази статия не е изчерпателен списък, но се опитах да прегледам и коментирам напречно сечение от източници. Надяваме се, че ще намерите информацията, която най-добре отговаря на вашите нужди и цели.
Като странична бележка, бях изненадан да открия, че много статии, свързани с практиките за проектиране на бази данни, имат много малко примери; онлайн ресурсите, които прегледах за статията за грешки и грешки, имаха по-висок процент от тях. Тази липса е недостатък, защото примерите са изключително важни, за да се разбере идеята.
Съвети за база данни за опитни дизайнери
Първо, нека започнем с източници, включващи усъвършенствани съвети за дизайн на база данни и най-добри практики. Те са за дизайнери, които вече работят в моделирането на данни и са от известно време. Някои статии са насочени към по-средно ниво, но ако обсъждат разширени концепции, включих ги в този списък.
Указания за база данни (RDBMS/SQL)
от Стив Джаджасапутра | SOA, Java, разработка на софтуер – BlogSpot | 16 януари 2013 г.
Тази статия от г-н Джаджасапутра е доста впечатляваща:той изброява множество съвети за схемата, индексите и изгледите; той също така предоставя доста подробна конвенция за именуване. И неговите съвети продължават (и продължават). Широчината е впечатляваща, но примери почти няма. Някои от неговите точки може да се считат за спорни, но като цяло това е много солидна презентация.
По-специално, бях впечатлен, че той дава точно правило за използването на естествени срещу изкуствени (т.е. сурогатни или генерирани) първични ключове. Той поддържа това хубаво и просто, като уточнява, че трябва да предпочитаме естествен ключ, защото е смислен. Той също така предоставя насоки за най-доброто използване на изкуствен ключ – по-специално, когато естественият ключ не е уникален или когато трябва да промените стойността на естествения ключ. По собствените му думи:
Първо предпочитайте да използвате естествения ключ, тъй като е по-смислен и за да избегнете дублиране (използвайте повторно съществуваща колона). Но има случаи, когато имате нужда от изкуствен ключ:когато естественият ключ не е уникален (например имена) или ако трябва да промените стойността.Тъй като списъкът му със съвети е толкова дълъг, не мога да си представя да ги запомня всички. Но всеки раздел може да бъде препратен, когато работите върху дизайна на базата данни, производителността, съхранените процедури и версиите. Има и раздел за специфични за Oracle точки, които биха били полезни, ако работите с или планирате да поддържате Oracle.
Като цяло, това е много ценен и изчерпателен ресурс.
9 съвета за по-добър дизайн на база данни
от Джефри Едисън | Блог на Vertabelo | 22 септември 2015 г.
Тук ще се отдам на малко самореклама.
Тази статия от 9 съвета за по-добър дизайн на база данни се основава на моя опит като дизайнер и архитект. Намерих и допълнителни прозрения от проучването на най-добрите практики на други за проектиране на бази данни.
Моят списък представя някои от основните проблеми, които могат да възникнат при работа с модели на данни. Организирах съветите в реда, в който се появяват по време на жизнения цикъл на проекта (а не по важност или колко често се появяват), тъй като това би било най-полезно, поне според мен. Читателите могат да следват този контролен списък с най-добри практики през жизнения цикъл на проекта.
От статията:
За да перифразирам Ал Капоне (или Джон Ван Бюрен, син на 8-ия президент на САЩ), „тествайте рано, тествайте често“. По този начин вие следвате пътя на непрекъснатата интеграция. Тестването на ранен етап на разработка спестява време и пари. При тестването на базата данни целта трябва да бъде да се симулира производствена среда:„Един ден от живота на базата данни“. Какви обеми могат да се очакват? Какви взаимодействия с потребителите са вероятни? Обработват ли се граничните случаи?Като обърнах внимание на тези съвети, открих, че базите данни стават по-добре проектирани и по-стабилни. Въпреки че нито една от тези дейности няма да отнеме огромно количество време, всяка може да има огромно влияние върху качеството на вашия модел на данни.
Надявам се, че списъкът ми със съвети е полезен за средно напреднали и напреднали дизайнери.
20 най-добри практики за проектиране на бази данни
от Кагдас Басаранер | Баланс на кода – BlogSpot | 24 юли 2011 г.
Г-н Басаранер ни представя интересен списък от 20 най-добри практики за проектиране на бази данни. Бих предпочел, ако беше групирал някои от тях; например, първите четири елемента могат да бъдат обхванати от „Използвайте конвенции за добро име“.
Освен това той заявява, че използването на синтетичен, генериран (целочислен) идентификатор като първичен ключ на всички таблици е най-добрата практика. Всъщност това все още е дискутирана тема, с аргументи за и против. Някои от най-добрите му практики са доста общи, като „За... системи за критици на мисия [sic] бази данни, използвайте услуги за възстановяване при бедствие и сигурност…“ Не съм съгласен с тази точка, но тя е на много високо ниво.
Положителната страна е, че тази статия беше една от малкото, които споменават използването на рамка за обектно-релационно картографиране (ORM). Някои коментиращи не са съгласни с това как е формулиран съветът, но се споменава поне използването на ORM рамка:
Използвайте ORM (обектно релационно картографиране) рамка (т.е. Hibernate, iBatis ...), ако кодът на приложението е достатъчно голям. Проблемите с производителността на ORM рамки могат да бъдат разрешени чрез подробни параметри на конфигурация.Все пак този списък можеше да бъде подобрен. Той трябва ясно да идентифицира точки, които са специфични само за някои системи за управление на бази данни (например SQL Server). Точни статистически данни относно производителността, евристичността или важността на отделянето на време за дизайн а не на поддръжка и препроектиране би било добре. Необходими бяха и повече примери, но това е проблем за повечето от тези статии.
Ако работите със SQL Server, обмисляте да използвате ORM рамка или имате нужда от списък със съвети с водещи символи, а не от дълга и подробна статия, тогава тази част е за вас.
(Забележка:тази статия се появи и на няколко други сайта, включително CodeBuild, Java Code Geeks и DZone.)
Основни принципи за проектиране на база данни. 10 неща, които абсолютно трябва да направите
от Мишел А. Пулет | SQL Server Pro | 1 март 2011 г.
Част от съветите на г-жа Пулет са доста стандартни и могат да бъдат намерени в много други ресурси, но има и няколко доста необичайни точки. Сред нейните общи точки тя насърчава използването на подтипове и супер-типове (с които съм силно съгласен), тъй като това отразява обектно-ориентирания дизайн и може лесно да бъде разбрано от разработчиците. От нейната статия:
Не се страхувайте да включите обекти на супертип и подтип във вашия дизайн в CDM и нататък. Подтиповете представляват класификации или категории на супертипа... Обектите се представят като подтипове, когато са необходими повече от една дума или фраза, за да се категоризира обектът.
Ако една категория има собствен живот, с отделни атрибути, които описват как изглежда и се държи категорията и отделни връзки с други обекти, тогава е време да извикате структурата на супертип/подтип . Ако не го направите, това ще попречи на пълното разбиране на данните и бизнес правилата, които управляват събирането на данни.
Някои от нейните коментари се позовават конкретно на MS SQL Server, дори ако коментарите всъщност са общи проблеми. Една основна точка, която г-жа Пулет прави, е много специфична за SQL Server:„Код за съхранение, който докосва данните на база данни като съхранена процедура“.
Това е добре, ако планирате да поддържате само една система за управление на база данни, като например SQL Server. Но за преносими реализации това не би било добър съвет. По принцип проектирам за преносимост към поне две системи за управление с различна езикова поддръжка на съхранените процедури. Затова бих избягвал тази практика.
Тази статия е най-полезна за хора, които разработват за SQL Server и се фокусират върху американския пазар (а не към международна система). Като американка, живееща в чужбина, обаче открих, че някои от нейните примери са малко твърде „ориентирани към САЩ“. Например, неамериканец може да не разбере какво е Zip+4 домейн е и следователно няма да има разбиране защо този домейн трябва да има характеристика NOT NULL.
За да илюстрирам това, направих модел на данни и за двата американски неамерикански адреса. Ще приемем, че нашият модел на данни може да изисква обектите да бъдат свързани с повече от един адрес:например един за таксуване, един за доставка. Първият адрес ще бъде свързан с метод на плащане; в този случай адресът ще се използва за проверка на правото ви да разрешите това плащане. Очевидно адресът за доставка е мястото, където поръчката ще бъде доставена.
Нека създадем американски адрес като част от модел на база данни по поръчка на клиента. (Забележка:това не е пълен модел, а пример за съхранение на поръчки на продукти.)
Wise Coders Solutions препоръчва дефиниране на отделни полета за номера на къщи и имена на улици и задаване на тези полета като NOT NULL; това би забранило всеки адрес, който няма номер на къща и име на улица. Но какво да кажем за хората, които използват пощенски кутии? Техните адреси обикновено се изписват като “PO Box 123”. Трябва ли да ги принудим да поставят номера на пощенската кутия като номер на къщата и “PO Box” като име на улицата? Не мисля така.
Вместо това ще използваме формуляр с „Адресен ред 1“ и „Адресен ред 2“. Няколко души оспориха използването на числа в имената на полета, но за мен това е доста очевидно решение. Освен това дефинирах максимална дължина на полетата (35 и 70 знака), които са типични за международните плащания.
Обърнете внимание, че дизайните в САЩ и извън САЩ имат поле за региони в рамките на дадена държава, но дизайнът на САЩ изисква включването на съкращение от 2 знака на държавата. Също така имайте предвид, че американският дизайн не позволява адреси в други държави.
Ако имате притеснения относно глобалното използване на вашата база данни, трябва да мислите глобално по време на фазата на проектиране. Подготвени ли са нашите бази данни за мултинационално използване на нашите приложения?
Уроците, извлечени от лошия дизайн на хранилище за данни
от Мишел А. Пулет | SQL Server Pro | 15 юни 2009 г.
Тази статия разглежда хранилището на данни (DWH) и някои от неговите проблеми с дизайна и внедряването. Има лек фокус върху SQL Server, но това е доста ортодоксален преглед на проектирането за съхранение на данни и бизнес разузнаване. Включването и създаването на удобни за потребителя интерфейси може да не са най-полезните съвети, но не съм несъгласен с тях – просто не мисля, че са част от дизайна на DWH.
Г-жа Пулет заявява, че процесът на извличане-преобразуване-зареждане (ETL) трябва да извършва проверки на качеството на данните и потенциално „чисти“ данни, докато има приемлив стандарт за качество на данните. Според мен това рискува да се създаде хранилище за данни, което не отразява правилно информацията, извлечена от изходната система. Почистването на данните трябва да се извършва в изходните системи. ETL трябва само да трансформира данните, така че да могат да бъдат заредени в хранилището за данни.
Положително е, че препоръката за рециклиране или създаване на ETL процедури за многократна употреба е много уместна. Освен това съм съгласен с г-жа Пулет относно мащабируемостта. Нейните коментари относно управлението на риска и спазването, особено Закона на Сарбейн-Оксли, изглеждат доста конкретни; Предполагам, че идват от нейната сфера на дейност.
И накрая, тя има хубав контролен списък с точки, свързани с размери, таблици с факти и избор на схеми по време на OLAP (онлайн аналитична обработка) дизайн. Те изглеждат много уместни по време на процеса на проектиране на база данни. Бих искал този списък да е по-дълъг, с повече подробности или примери, но бях щастлив, че бяха включени тези практически съвети.
11 важни правила за проектиране на бази данни, които следвам
от Шивпрасад Койрала | Проект за код | 25 февруари 2014 г.
Наистина харесвам разумните и ясни съвети в началото на тази статия. Концепции като „вземете предвид естеството на приложението“ и „разбийте данните си на логически части“ са на място. Това са важни помощни средства при създаването на вашия модел на данни. Както казва г-н Койрала:
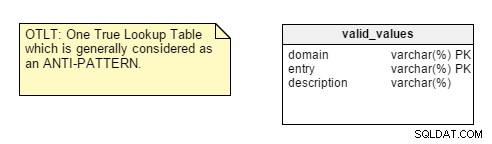
Когато стартирате дизайна на вашата база данни, първото нещо, което трябва да анализирате, е естеството на приложението, за което проектирате, дали е транзакционно или аналитично. Ще откриете, че много разработчици по подразбиране прилагат правила за нормализиране, без да мислят за естеството на приложението и след това по-късно се занимават с проблеми с производителността и персонализирането.Има обаче няколко точки, които ме оставят неубеден. Например вземете централизирането на двойки име-стойност в една таблица. Този дизайн на One True Lookup Table (OTLT) се обсъжда, но като цяло се счита за лоша практика или поне за анти-модел в дизайна. Аз съм на страната на анти-OTLT групата; тези таблици въвеждат множество въпроси. Можем да използваме аналогията за разработка на софтуер за използване на единичен изброител за представяне на всички възможни стойности на всички възможни константи като еквивалент на тази практика.
За да ви напомня, OTLT таблицата обикновено изглежда така, с записи от множество домейни, хвърлени в една и съща таблица. Съгласен съм с групата против OTLT; тези таблици въвеждат множество проблеми.
Освен това някои точки изглеждат малко езотерични, като „внимавайте за данни, разделени от разделители“. Въпреки че това е валидна точка, обикновено не мисля за нея, когато създавам нов модел на данни.
Г-н Койрала има няколко елемента за OLAP дизайн, които обикновено не се споменават в други списъци с най-добри практики. Неговото включване на дизайн на измерения и факти може да е полезно, но също така може да бъде опасно за начинаещи дизайнери.
Тази статия е интересна, ако преминавате от началото към по-усъвършенствано моделиране на данни. Това ще ви помогне да разгледате аналитичната спрямо транзакционната природа на бъдещите си модели.
Големи данни:Пет прости съвета за ефективност при проектиране на база данни
от Дейв Бълк | davebeulke.com | 19 март 2013 г.

Статията на г-н Beulke разглежда съвети за дизайн, фокусирани върху производителността. Той показва как да проверите за правилна нормализиране:нито твърде много, нито твърде малко. (Прекомерното нормализиране ще има отрицателно въздействие върху производителността на базата данни.)
Също така използването на естествени бизнес ключове вместо генерирани първични ключове е разумен съвет, когато искате да избегнете преобразуването от бизнес ключ към генериран идентификатор на ред за всеки достъп до база данни.
Използването на правилни стандарти за именуване и типове колони също е добър съвет. Въпросът за прекомерната употреба на колони с нулеви стойности е правилен:създаването на всички колони като nullable е грешка, но дефинирането на колона като nullable може да се наложи за конкретна бизнес функция. По собствените думи на автора:
Всички колони са NULL? В рамките на дефинициите на колоните на базата данни добрите домейни на данни, диапазони и стойности трябва да бъдат анализирани, оценени и прототипирани за бизнес приложението. Наличието на добри стойности по подразбиране, ограничен обхват от стойности и винаги стойност са най-добри за производителността и логиката на приложението. NULL колоните са добри само когато данните са неизвестни или все още нямат стойност. Данните за датата на смъртта на някого са класическият пример за колона с NULL, защото е неизвестна, освен ако вече не е мъртъв. Уверете се, че дизайнът на вашата база данни представлява данни, които са известни и използва само минимум NULL колони.Съветите на г-н Beulke са много солидни, дори и малко неоригинални. Бих искал повече елементи с големи данни – това е в крайна сметка заглавието на статията. В крайна сметка почувствах, че на статията липсва както дълбочина, така и широчина и няма примери, които да изяснят точките. Въпреки това той предлага ценни съвети, свързани с нормализирането и естествените ключове.
10 най-добри практики за проектиране на бази данни
от Ann All | Корпоративни приложения днес | 15 юли 2014 г.
Десетте най-добри практики за проектиране на бази данни всъщност са представени като серия от слайдове. Г-жа All включва информация от опитни разработчици, като Майкъл Блаха. Той насърчава повторното използване на вашите най-добри практики и модели. Те са разбрани и доказани и в това отношение са за предпочитане пред моделите на данни, които трябва да бъдат създадени от нулата. От статията на г-жа Ол:
Например, често извършвам обратен инженеринг на бази данни – бази данни на приложение, което трябва да бъде заменено, както и бази данни на свързани приложения. Тези съществуващи бази данни често нямат наличен модел на данни. Но моделът на данни е имплицитен в схемата на базата данни и може да бъде поне частично извлечен с техники за обратно инженерство на база данни. ... Има изпитани и верни представяния на данни, които често се срещат и не е необходимо да се пресъздават от нулата.Това е кратко слайдшоу, което дизайнерите на модели на данни могат бързо да сканират и да съберат съветите, които резонират с тях. За мен съветът за повторна употреба е един от любимите ми.
Най-добри практики за база данни
от Cunningham &Cunningham, Inc.
Тези най-добри практики започнаха добре, но след това стигнаха до някои лепкави проблеми. Не съм убеден, че предлаганите съвети винаги са подходящи.
Положителната страна е, че има много хубави описания на противоречиви „най-добри практики“, като винаги използване на автоматично генерирани сурогатни ключове и използване или избягване на съхранени процедури. Като пример:
Предишен автор написа:„По принцип избягвайте първичните ключове, които имат значение. Имената не са уникални и много привидно уникални идентификатори, като номера на социалното осигуряване, всъщност не са, поради проблеми с надеждността на данните в реалния свят.“ Накратко, това е препоръка винаги да имате автоматично генериран (обикновено числов) SurrogateKey вместо базиран на домейн LogicalKey. Това е доста приятен отговор на сложен проблем, въпреки че е такъв, който ще бъде достатъчен в редица случаи и е най-малкото за предпочитане пред това да нямате PrimaryKey изобщо.(Бележка на автора:Не успях да намеря този „предишен автор“, когато търсих тези две изречения в Google.)
Предоставена е и връзка към обобщена статия за основните аргументи от всяка страна на дебата за автоматичните ключове срещу ключовете за домейн.
От друга страна открих съветите за „разделяне на операционна система, данни и влизане на различни физически дискове“ и „използване на RAID“ за малко загадъчни. Не ме разбирайте погрешно – това вероятно е добър съвет при някои обстоятелства, но не бих го включил в списъка си с Топ 20.
Съвети за проектиране на база данни
от Wise Coders
В тази колекция има няколко уникални и интересни съвета, като например препоръка за затваряне на транзакции възможно най-скоро.
Въпреки това, не съм напълно съгласен с всички съвети за дизайн тук. Например:
Да предположим поле „Състояние“ със стойности „Активно“, „Неактивно“ и „Неактивно“. Можете да запишете стойността като пълно име, но това може да бъде неефективно. Съхраняването на изброяване или char(1) с възможни стойности „a“, „i“, „d“, например, ще използва по-малко място в базата данни.Това е най-малкото противоречиво – други източници препоръчват да не се използват „тайни кодове“ като този. Вместо това използвайте отделна таблица, за да съхранявате тези кодове на състоянието.
Освен това статистическите данни, свързани със съвети за ефективност, са съмнителни и в статията няма примери.
Положително е, че това е хубав кратък списък със съвети, които трябва да бъдат достъпни за междинни моделисти на бази данни.
Ресурси за начинаещи дизайнери на бази данни
Сега нека разгледаме няколко статии за тези, които тепърва започват да проектират база данни.
Основите на добрия дизайн на бази данни в уеб разработката
от Кайла Найт | Onextrapixel.com | 17 март 2011 г.
Тук ставаме малко по-напреднали, със съвети, вариращи от функционалност до инструменти за моделиране.
Г-жа Найт ни превежда през въведение в дизайна на база данни. Нейната статия е интересна, защото набляга на бази данни за уеб разработка. Въпреки това нейните точки са доста универсални и могат да бъдат приложени към дизайна на база данни в много ситуации.
Статията започва с молба да мислим широко за функционалността, а не само за базата данни:
Мислете извън базата данни. Опитайте се да помислите какво ще трябва да направи уебсайтът. Например, ако е необходим уебсайт за членство, първият инстинкт може да бъде да започнете да мислите за всички данни, които всеки потребител ще трябва да съхранява. Забравете, това е за по-късно. По-скоро запишете, че потребителите и тяхната информация ще трябва да се съхраняват в базата данни и какво друго? Какво ще трябва да правят тези членове на сайта? Ще правят ли публикации, ще качват ли файлове или снимки или ще изпращат съобщения? Тогава базата данни ще се нуждае от място за файлове/снимки, публикации и съобщения.Оттам г-жа Найт отвежда читателя в инструментите за проектиране на база данни и стъпките, включени в процеса. Нейната статия дава примери и връзки към други ресурси.
Мисля, че тази статия би била чудесно въведение за начинаещи дизайнери на бази данни и би трябвало да работи добре с Geek Girl’s серия.
Проучване на съвети за дизайн на база данни
от Дъг Лоу | За манекени
Списъкът на г-н Лоу „Манекени“ е широка серия от основни съвети за дизайн. Можете да намерите много от тях другаде, но е полезно да ги имате на едно място. Няма да намерите нищо уникално или силно противоречиво, освен препоръка за използване на съхранени процедури. Винаги поставям под съмнение това силно твърдение, тъй като съм много загрижен за преносимостта на модела на данни за множество DBM системи.
Ето един от съветите за здравия разум на г-н Лоу:
Избягвайте полета с имена като CustomerType, където стойността на полето е една от няколкото константи, които не са дефинирани другаде в базата данни, като R за търговия на дребно или W за търговия на едро. Днес може да имате само тези два типа клиенти, но нуждите на приложението може да се променят в бъдеще, изисквайки трети тип клиенти.Тези препоръки са най-подходящи при работа със SQL Server.
Пет прости съвета за проектиране на база данни
от Ламонт Адамс | TechRepublic | 25 юни 2001 г.
Ключовата дума за този ресурс е „прост“. Можете да намерите тази информация, с повече обяснения и примери, в други статии.
Въпреки това съветът на г-н Адамс за „Вземете ключовете на потребителя“ е интересен момент, който рядко се споменава на други места. Той продължава:
Когато решавате кое поле или полета да използвате като ключове в таблица, винаги имайте предвид полетата, които потребителите ще редактират. Обикновено е лоша идея да изберете поле за редактиране от потребителя като ключ.Значението на г-н Адамс е, че трябва да вземете предвид потенциалното изискване на потребителя да редактира полета, когато решавате кои полета да използвате като ключове. Бих искал повече обяснения относно алтернативи, като например синтетични/генерирани ключове, но концепцията е добра.
Не съм съгласен с последната точка. Той препоръчва „фактор на измисляне“ за всяка таблица, която проектирате:
Не е много по-лошо от това да откриете или да бъдете информирани, че във вашата „завършена“ база данни липсва поле за важна информация. В една компания, в която работех, това беше толкова често срещано явление, че започнахме да наричаме „замръзването на бази данни“ като „замръзване на бази данни“.Според мен това е основно „добавяне на няколко допълнителни текстови полета в края“. Това изглежда противоречи на някои от другите съвети на г-н Адамс, по-специално тези относно разбирането на бизнес нуждите и използването на смислени имена. Тези допълнителни полета за измисляне просто ще се наричат нещо като „екстра1“ или „екстра2“. Каква е тяхната бизнес нужда? И как са тези смислени имена? Макар че харесвам повечето от неговите дизайнерски съвети, този „фактор на измисляне“ не е нещо, към което се придържам.
Дизайн на база данни:Почетни споменавания
Очевидно има и други статии, които описват съвети за проектиране на база данни и най-добри практики. Можете да намерите допълнителни материали в следните връзки:
Проектиране на релационна база данни:Пример за най-добри практики | от Digital Ethos | 24 декември 2012 г.
Най-добри практики за проектиране на схеми на база данни (начинаещи) | от Джим Мърфи | 28 март 2011 г.
Най-добри ИТ практики:Проектиране на база данни | от Университета на Небраска – Линкълн
Ресурси за проектиране на онлайн бази данни:Къде бихте отишли?
Както споменахме, този списък определено не е предназначен да бъде изчерпателен преглед на всяка статия за дизайн на база данни в Интернет. По-скоро сме идентифицирали няколко статии, които смятаме за полезни или които имат конкретен фокус, който може да ви бъде полезен.
Моля, не се колебайте да препоръчате допълнителни статии.